


Artikel ini menyelidiki aspek praktikal model bahasa yang besar (LLMS), yang memberi tumpuan kepada Codex dan InstructGPT sebagai contoh utama. Ia adalah yang ketiga dalam satu siri meneroka model GPT, membina perbincangan sebelumnya tentang pra-latihan dan skala.

Artikel ini menyoroti dua cabaran penalaan utama: menyesuaikan diri dengan modaliti baru (seperti penyesuaian Codex kepada penjanaan kod) dan menyelaraskan model dengan keutamaan manusia (seperti yang ditunjukkan oleh InstructGPT). Kedua -duanya memerlukan pertimbangan yang teliti terhadap pengumpulan data, seni bina model, fungsi objektif, dan metrik penilaian.
codex: penalaan halus untuk penjanaan kod
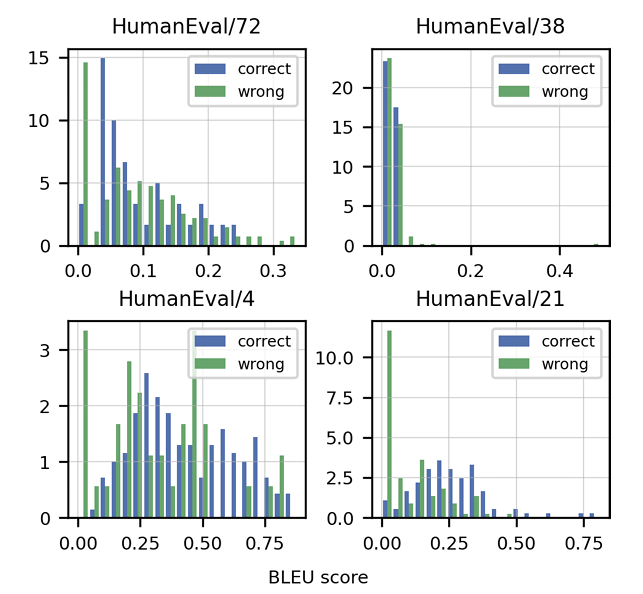
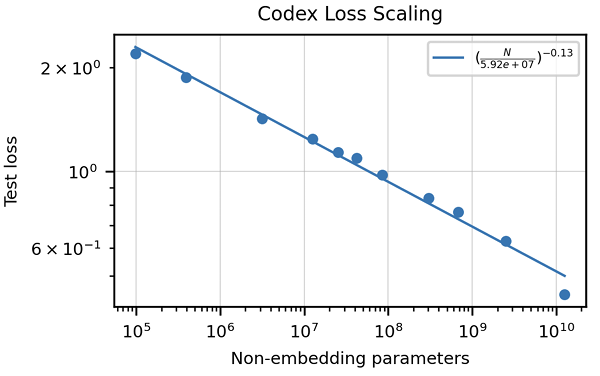
Artikel ini menekankan kekurangan metrik tradisional seperti skor BLEU untuk menilai penjanaan kod. Ia memperkenalkan "ketepatan fungsi" dan metriklulus@k , menawarkan kaedah penilaian yang lebih mantap. Penciptaan dataset manusia, yang terdiri daripada masalah pengaturcaraan bertulis tangan dengan ujian unit, juga diserlahkan. Strategi pembersihan data khusus untuk kod dibincangkan, bersama -sama dengan kepentingan menyesuaikan tokenizers untuk mengendalikan ciri -ciri unik bahasa pengaturcaraan (mis., Pengekodan Whitespace). Artikel ini membentangkan hasil yang menunjukkan prestasi unggul Codex berbanding GPT-3 pada HumanEval dan meneroka kesan saiz model dan suhu pada prestasi.


 instructgpt dan chatgpt: sejajar dengan keutamaan manusia
instructgpt dan chatgpt: sejajar dengan keutamaan manusia
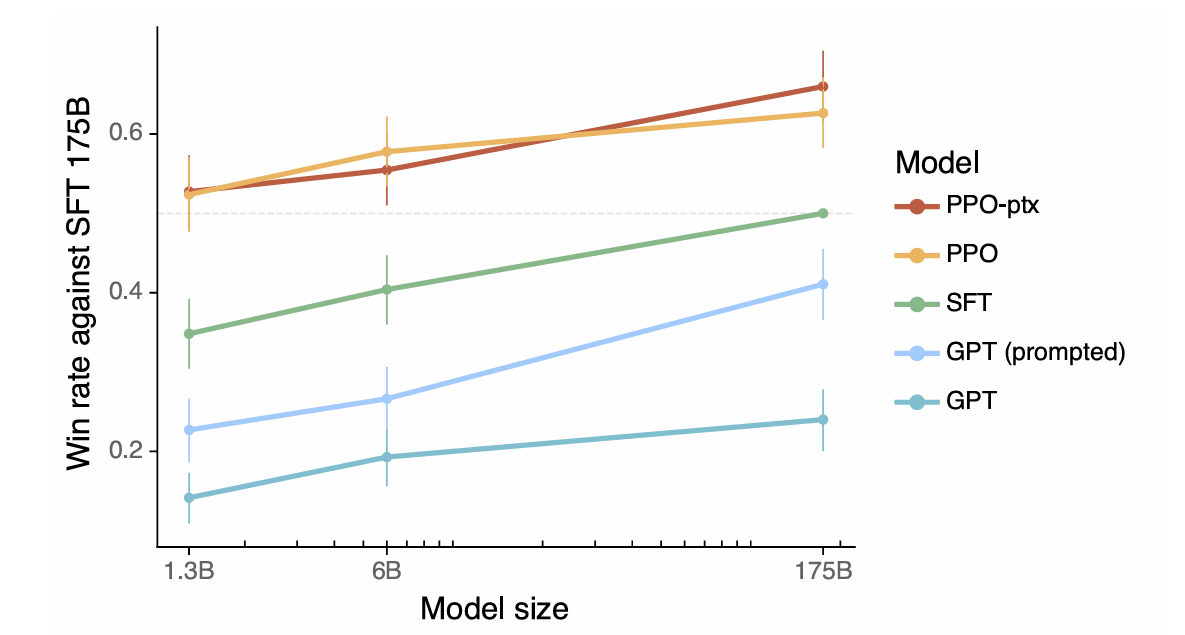
Artikel ini mentakrifkan penjajaran sebagai model yang mempamerkan membantu, kejujuran, dan tidak berbahaya. Ia menerangkan bagaimana kualiti ini diterjemahkan ke dalam aspek yang boleh diukur seperti arahan berikut, kadar halusinasi, dan kecenderungan/ketoksikan. Penggunaan pembelajaran tetulang dari maklum balas manusia (RLHF) terperinci, menggariskan tiga peringkat: mengumpul maklum balas manusia, melatih model ganjaran, dan mengoptimumkan dasar menggunakan pengoptimuman dasar proksimal (PPO). Artikel ini menekankan pentingnya kawalan kualiti data dalam proses pengumpulan maklum balas manusia. Keputusan yang mempamerkan penjajaran InstructGPT yang lebih baik, halusinasi yang dikurangkan, dan pengurangan regresi prestasi dibentangkan.
 Ringkasan dan Amalan Terbaik
Ringkasan dan Amalan Terbaik
Artikel ini menyimpulkan dengan meringkaskan pertimbangan utama untuk LLM yang baik, termasuk menentukan tingkah laku yang diingini, menilai prestasi, mengumpul dan membersihkan data, menyesuaikan seni bina model, dan mengurangkan potensi akibat negatif. Ia menggalakkan pertimbangan penalaan hiperparameter yang teliti dan menekankan sifat berulang proses penalaan halus.
Atas ialah kandungan terperinci Memahami evolusi chatgpt: Bahagian 3- Wawasan dari Codex dan InstructGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk memperlahankan video di Douyin
Bagaimana untuk memperlahankan video di Douyin
 Bagaimana untuk mencipta folder baharu dalam pycharm
Bagaimana untuk mencipta folder baharu dalam pycharm
 Apakah perisian pejabat
Apakah perisian pejabat
 Bagaimana untuk mengubah saiz gambar dalam ps
Bagaimana untuk mengubah saiz gambar dalam ps
 Bagaimana untuk menyelesaikan masalah akses ditolak semasa boot Windows 10
Bagaimana untuk menyelesaikan masalah akses ditolak semasa boot Windows 10
 Prestasi mikrokomputer terutamanya bergantung kepada
Prestasi mikrokomputer terutamanya bergantung kepada
 Perbezaan antara a++ dan ++a
Perbezaan antara a++ dan ++a
 Cara menggunakan fungsi datediff
Cara menggunakan fungsi datediff








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



