


Model generatif memasuki era "masa nyata"?
Menggunakan gambar rajah Vincentian dan gambar rajah Tusheng bukan lagi perkara baharu. Walau bagaimanapun, dalam proses menggunakan alat ini, kami mendapati ia sering berjalan perlahan, menyebabkan kami menunggu seketika untuk mendapatkan hasil yang dijana
Tetapi baru-baru ini, model yang dipanggil "LCM" telah mengubah keadaan ini, malah ia juga Able untuk mencapai penjanaan gambar berterusan masa nyata. Model Konsistensi khemah (model konsistensi terpendam), dibangunkan oleh Penyelidikan Maklumat Silang Universiti Tsinghua Dibina oleh penyelidik di institut itu. Sebelum keluaran model ini, model resapan terpendam (LDM) seperti Resapan Stabil sangat lambat dijana disebabkan oleh kerumitan pengiraan proses persampelan berulang. Melalui beberapa kaedah inovatif, LCM boleh menjana imej resolusi tinggi dengan hanya beberapa langkah inferens. Menurut statistik, LCM boleh meningkatkan kecekapan model graf Vincentian arus perdana sebanyak 5-10 kali, jadi ia boleh menunjukkan kesan masa nyata.

Sila klik pautan berikut untuk melihat kertas kerja: https://arxiv.org/pdf/2310.04378.pdf
Alamat projek: https://github.com/luosiallen/latent-consistency-model
Kandungan telah dilihat lebih daripada sejuta kali dalam masa satu bulan selepas ia diterbitkan, dan pengarang juga dijemput untuk menggunakan model dan demonstrasi LCM yang baru dibangunkan pada berbilang platform seperti Hugging Face, Replicate, dan Puyuan. Antaranya, model LCM telah dimuat turun lebih daripada 200,000 kali pada platform Hugging Face, dan bilangan panggilan API dalam talian pada platform Replicate telah melebihi 540,000 kali Atas dasar ini, pasukan penyelidik seterusnya mencadangkan LCM- LoRa. Kaedah ini boleh memindahkan keupayaan pensampelan pantas LCM kepada model LoRA lain tanpa sebarang latihan tambahan. Ini memberikan penyelesaian langsung dan berkesan kepada pelbagai gaya model yang telah wujud dalam komuniti sumber terbuka
Atas dasar ini, pasukan penyelidik seterusnya mencadangkan LCM- LoRa. Kaedah ini boleh memindahkan keupayaan pensampelan pantas LCM kepada model LoRA lain tanpa sebarang latihan tambahan. Ini memberikan penyelesaian langsung dan berkesan kepada pelbagai gaya model yang telah wujud dalam komuniti sumber terbuka

Kandungan yang perlu ditulis semula ialah: Sumber imej: https://twitter.com/ javilopen/status/1724398708052414748
kod kami telah terbuka sepenuhnya. LCM, dan mendedahkan fail berat model dan demonstrasi dalam talian yang diperoleh melalui penyulingan dalaman berdasarkan model pra-latihan seperti SD-v1.5 dan SDXL. Selain itu, pasukan Hugging Face telah menyepadukan model konsistensi berpotensi ke dalam repositori rasmi peresap, dan mengemas kini rangka kerja kod LCM dan LCM-LoRA yang berkaitan dalam dua versi rasmi v0.22.0 dan v0.23.0 berturut-turut, memberikan pemahaman tentang potensi model ketekalan. Sokongan yang baik untuk model ketekalan. Model yang diterbitkan di Hugging Face menduduki tempat pertama dalam senarai populariti hari ini, menjadi model Wenshengtu paling popular di semua platform dan model ketiga paling popular dalam semua kategori
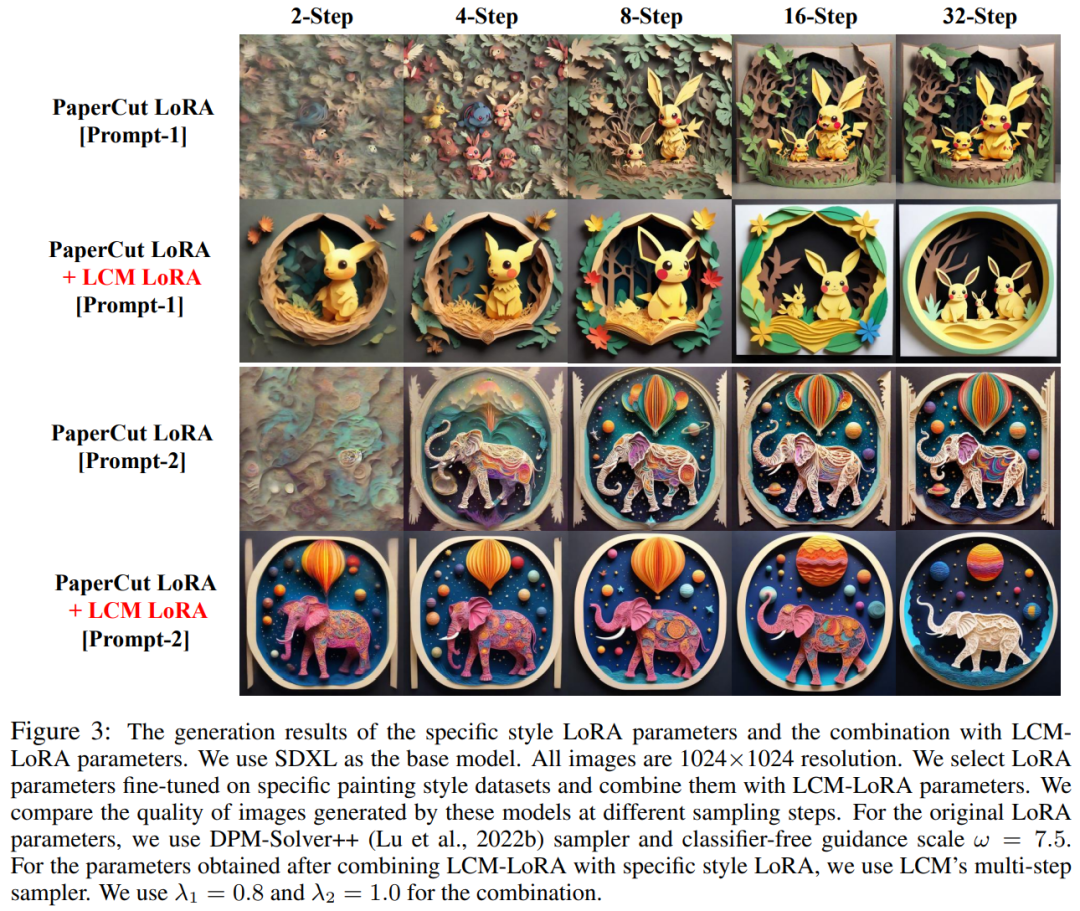
Seterusnya, kami akan memperkenalkan dua hasil penyelidikan LCM dan LCM-LoRA masing-masing. LCM: Hasilkan imej resolusi tinggi dengan hanya beberapa langkah inferens Dalam era AIGC, model graf Vincentian berasaskan model resapan termasuk Stable Diffusion dan DALL-E 3 telah mendapat perhatian meluas. Model resapan menghasilkan imej berkualiti tinggi dengan menambahkan hingar pada data latihan dan kemudian membalikkan proses tersebut. Walau bagaimanapun, model resapan memerlukan pensampelan berbilang langkah untuk menghasilkan imej, yang merupakan proses yang agak perlahan dan meningkatkan kos inferens. Masalah pensampelan berbilang langkah yang perlahan adalah halangan utama apabila menggunakan model sedemikian. Model Konsistensi (CM) yang dicadangkan oleh Dr Song Yang OpenAI tahun ini memberikan idea untuk menyelesaikan masalah di atas. Telah dinyatakan bahawa model ketekalan direka bentuk untuk mempunyai keupayaan untuk dijana dalam satu langkah, menunjukkan potensi besar untuk mempercepatkan penjanaan model resapan. Walau bagaimanapun, memandangkan model ketekalan terhad kepada penjanaan imej tanpa syarat, banyak aplikasi praktikal termasuk imej Vincentian, imej yang dijana graf, dll. masih tidak dapat menikmati potensi kelebihan model ini. Latent Consistency Model (LCM) dilahirkan untuk menyelesaikan masalah di atas. Model ketekalan terpendam menyokong tugas penjanaan imej bagi keadaan tertentu, dan menggabungkan pengekodan terpendam, panduan bebas pengelas dan banyak teknologi lain yang digunakan secara meluas dalam model resapan, mempercepatkan proses denoising bersyarat dan menyediakan banyak aplikasi praktikal satu laluan. Butiran Teknikal LCM Secara khusus, model ketekalan pendam mentafsirkan masalah penyahnosan model resapan sebagai proses menyelesaikan persamaan pembezaan biasa aliran kemungkinan bertambah yang ditunjukkan di bawah. Kecekapan penyelesaian boleh dipertingkatkan dengan menambah baik model resapan tradisional. Kaedah tradisional menggunakan lelaran berangka untuk menyelesaikan persamaan pembezaan biasa, tetapi walaupun dengan penyelesai yang lebih tepat, ketepatan setiap langkah adalah terhad, dan memerlukan kira-kira 10 lelaran untuk mendapatkan hasil yang memuaskan Berbeza daripada penyelesaian lelaran tradisional bagi pembezaan biasa persamaan , model ketekalan pendam memerlukan penyelesaian satu langkah kepada persamaan pembezaan biasa secara langsung, meramalkan penyelesaian akhir persamaan, dan secara teori boleh menjana gambar dalam satu langkah Untuk melatih model ketekalan terpendam , kajian ini mencadangkan bahawa ia boleh Memperhalus parameter model resapan terlatih (contohnya, resapan stabil) untuk mencapai penjanaan model pantas dengan penggunaan sumber yang minimum. Proses penyulingan ini adalah berdasarkan pengoptimuman fungsi kehilangan konsistensi yang dicadangkan oleh Dr Song Yang. Untuk mendapatkan prestasi yang lebih baik dan mengurangkan overhed pengiraan pada tugas graf Vincentian, kertas kerja ini mencadangkan tiga teknologi utama: Kandungan ditulis semula: (1) Dengan menggunakan pengekod auto terlatih, imej asal dikodkan menjadi Perwakilan terpendam dalam ruang. untuk mengurangkan maklumat berlebihan semasa memampatkan gambar dan menjadikan gambar lebih konsisten dari segi semantik (2) Suling panduan tanpa pengelas sebagai parameter input model ke dalam model ketekalan terpendam, dan nikmati tanpa kelas Walaupun panduan pengelas membawa ketekalan teks imej yang lebih baik, kerana amplitud panduan bebas pengelas disuling ke dalam model ketekalan terpendam sebagai parameter input, ia boleh mengurangkan overhed pengiraan yang diperlukan semasa inferens (3) Menggunakan strategi langkau untuk mengira kehilangan konsistensi sangat mempercepatkan proses penyulingan; model konsistensi yang berpotensi. Pseudokod algoritma penyulingan model ketekalan pendam ditunjukkan dalam rajah di bawah. Hasil kualitatif dan kuantitatif menunjukkan bahawa model konsistensi terpendam mempunyai keupayaan untuk menjana imej berkualiti tinggi dengan cepat. Model ini boleh menjana imej berkualiti tinggi dalam 1 hingga 4 langkah. Dengan membandingkan masa inferens sebenar dan penunjuk kualiti penjanaan FID, dapat dilihat bahawa berbanding penyelesai DPM++, salah satu pensampel sedia ada terpantas, model ketekalan berpotensi boleh mempercepatkan masa inferens sebenar sebanyak kira-kira 4 kali sambil mengekalkan kualiti generasi yang sama . Berdasarkan model ketekalan, pasukan pengarang kemudiannya menerbitkan laporan Teknikal mereka tentang LCM-LoRA. Memandangkan proses penyulingan model ketekalan pendam boleh dianggap sebagai proses penalaan halus untuk model pra-latihan asal, teknik penalaan halus yang cekap seperti LoRA boleh digunakan untuk melatih model ketekalan pendam. Terima kasih kepada penjimatan sumber yang dibawa oleh teknologi LoRA, pasukan penulis menjalankan penyulingan pada model SDXL dengan bilangan parameter terbesar dalam siri Stable Diffusion, dan berjaya memperoleh konsensus yang berpotensi yang boleh dijana dalam beberapa langkah yang setanding dengan berpuluh-puluh langkah SDXL. Dalam pengenalan kertas kerja, kajian menunjukkan bahawa walaupun model resapan terpendam (LDM) telah berjaya menghasilkan imej teks dan imej lukisan garisan, proses pensampelan terbalik yang perlahan mengehadkan aplikasi masa nyata dan memberi kesan kepada pengalaman pengguna . Model sumber terbuka semasa dan teknologi pecutan masih belum dapat mencapai penjanaan masa nyata pada GPU gred pengguna biasa secara amnya dibahagikan kepada dua kategori: kategori pertama melibatkan penyelesai ODE lanjutan, seperti DDIM, DPMSolver dan DPM-Solver++. dan Mempercepatkan proses penjanaan. Kategori kedua melibatkan penyulingan LDM untuk memudahkan fungsinya. ODE - Solver mengurangkan langkah inferens tetapi masih memerlukan overhed pengiraan yang ketara, terutamanya apabila menggunakan panduan tanpa pengelas. Sementara itu, kaedah penyulingan seperti Guided-Distill, walaupun menjanjikan, menghadapi batasan praktikal kerana keperluan pengiraan intensif mereka. Mencari keseimbangan antara kelajuan dan kualiti imej yang dijana LDM kekal sebagai cabaran dalam bidang ini. Baru-baru ini, diilhamkan oleh Model Konsistensi (CM), Model Konsistensi Terpendam (LCM) muncul sebagai penyelesaian kepada masalah pensampelan perlahan dalam penjanaan imej. LCM menganggap proses resapan belakang sebagai masalah ODE (PF-ODE) aliran kebarangkalian yang dipertingkatkan. Model jenis ini secara inovatif meramalkan penyelesaian dalam ruang terpendam tanpa memerlukan penyelesaian berulang melalui penyelesai ODE berangka. Hasilnya, ia membolehkan sintesis imej beresolusi tinggi yang cekap dengan hanya 1 hingga 4 langkah inferens. Selain itu, LCM juga menunjukkan prestasi yang baik dari segi kecekapan penyulingan, dan hanya mengambil masa 32 jam latihan dengan A100 untuk melengkapkan inferens bagi langkah terkecil Atas dasar ini, kaedah yang dipanggil penalaan halus konsisten terpendam (LCF) telah dibangunkan. , yang boleh memperhalusi LCM pra-latihan tanpa bermula daripada model resapan guru. Untuk set data khusus, seperti anime, foto sebenar atau set data imej fantasi, langkah tambahan diperlukan, seperti penyulingan LDM pra-latihan ke dalam LCM menggunakan Penyulingan Konsisten Terpendam (LCD) atau penalaan halus LCM secara langsung menggunakan LCF. Walau bagaimanapun, latihan tambahan ini mungkin menghalang penggunaan pantas LCM pada set data yang berbeza, yang menimbulkan persoalan utama: sama ada inferens yang pantas dan bebas latihan boleh dicapai pada set data tersuai Untuk menjawab soalan di atas, Para penyelidik mencadangkan LCM-LoRA. LCM-LoRA ialah modul pecutan tanpa latihan am yang boleh dipalamkan terus ke dalam pelbagai model diperhalusi Stable-Diffusion (SD) atau SD LoRA untuk menyokong inferens pantas dengan langkah minimum. Berbanding dengan penyelesai ODE (PF-ODE) aliran kemungkinan berangka awal seperti DDIM, DPM-Solver dan DPM-Solver++, LCM-LoRA mewakili kelas baharu modul penyelesai PF-ODE berdasarkan rangkaian saraf. Ia menunjukkan keupayaan generalisasi yang kukuh merentas pelbagai model SD yang diperhalusi dan plot gambaran keseluruhan LoRA LCM-LoRA. Dengan memperkenalkan LoRA ke dalam proses penyulingan LCM, kajian ini telah mengurangkan overhed memori penyulingan dengan ketara, yang membolehkan mereka menggunakan sumber terhad untuk melatih model yang lebih besar seperti SDXL dan SSD-1B. Lebih penting lagi, parameter LoRA (vektor pecutan) yang diperolehi melalui latihan LCM-LoRA boleh digabungkan secara langsung dengan parameter LoRA lain (style vetcor) yang diperoleh melalui penalaan halus pada set data gaya tertentu. Tanpa sebarang latihan, model yang diperolehi oleh gabungan linear vektor pecutan dan gaya vetcor boleh menghasilkan imej gaya lukisan tertentu dengan langkah pensampelan yang minimum. Secara amnya, model ketekalan pendam dilatih menggunakan kaedah penyulingan berpandu satu peringkat, yang menggunakan ruang pendam model autoenkoder terlatih sebelum penyulingan terbimbing ke dalam LCM. Proses ini melibatkan penambahan ODE aliran kebarangkalian, yang boleh kita anggap sebagai formula matematik yang memastikan sampel yang dijana mengikut trajektori yang menghasilkan imej berkualiti tinggi. Perlu dinyatakan bahawa fokus penyulingan adalah untuk mengekalkan kesetiaan trajektori ini sambil mengurangkan dengan ketara bilangan langkah pensampelan yang diperlukan. Algoritma 1 menyediakan pseudokod untuk LCD. LoRA mengemas kini matriks berat pra-latihan dengan menggunakan penguraian peringkat rendah. Khususnya, diberikan matriks berat h mewakili vektor keluaran Daripada formula (1), boleh diperhatikan bahawa dengan menguraikan matriks parameter lengkap kepada hasil dua rendah-. matriks kedudukan, LoRA dengan ketara Mengurangkan bilangan parameter boleh dilatih, sekali gus mengurangkan penggunaan memori. Jadual di bawah membandingkan jumlah bilangan parameter dalam model penuh dengan parameter boleh dilatih apabila menggunakan teknologi LoRA. Jelas sekali, dengan menggabungkan teknologi LoRA dalam proses penyulingan LCM, bilangan parameter yang boleh dilatih dikurangkan dengan ketara, dengan berkesan mengurangkan keperluan memori untuk latihan. Kajian ini menunjukkan melalui satu siri eksperimen bahawa paradigma LCD boleh disesuaikan dengan baik kepada model yang lebih besar seperti SDXL dan SSD-1B Hasil penjanaan model yang berbeza ditunjukkan dalam Rajah 2. Penulis mendapati menggunakan teknologi LoRA dapat meningkatkan kecekapan proses penyulingan Beliau juga mendapati parameter LoRA yang diperolehi melalui latihan boleh digunakan sebagai modul pecutan am yang boleh digabungkan terus dengan parameter LoRA yang lain . Seperti yang ditunjukkan dalam Rajah 1 di atas, pasukan pengarang mendapati bahawa dengan hanya menggabungkan "parameter gaya" secara linear yang diperolehi melalui penalaan halus pada set data gaya tertentu dan "parameter pecutan" yang diperoleh melalui penyulingan konsisten terpendam, adalah mungkin untuk mendapatkan kedua-duanya. keupayaan penjanaan pantas dan gaya khusus. Model ketekalan terpendam baharu. Penemuan ini memberikan rangsangan kuat kepada sejumlah besar model sumber terbuka yang telah wujud dalam komuniti sumber terbuka sedia ada, membolehkan model ini menikmati kesan pecutan yang dibawa oleh model konsisten terpendam tanpa sebarang latihan tambahan. menunjukkan kesan penjanaan model baharu selepas menggunakan kaedah ini untuk menambah baik model "gaya potong kertas", seperti yang ditunjukkan dalam rajah di bawah Ringkasnya, LCM-LoRA ialah model untuk Stable-Diffusion (SD ) Modul pecutan tanpa latihan universal. Ia berfungsi sebagai modul penyelesai berasaskan rangkaian neural yang tersendiri dan cekap untuk meramalkan penyelesaian kepada PF-ODE, membolehkan inferens pantas dengan langkah minimum pada pelbagai model SD yang diperhalusi dan SD LoRA. Sebilangan besar eksperimen penjanaan teks-ke-imej telah membuktikan keupayaan generalisasi yang kukuh dan keunggulan LCM-LoRA Pengenalan pasukan Pengarang kertas kerja semuanya dari Universiti Tsinghua, dan dua pengarang bersama ialah Luo Simian dan Tan Yiqin. Luo Simian ialah pelajar sarjana tahun kedua di Jabatan Sains Komputer dan Teknologi di Universiti Tsinghua, dan penyelianya ialah Profesor Zhao Xing. Beliau lulus dari Sekolah Data Besar Universiti Fudan dengan ijazah sarjana muda. Arah penyelidikannya ialah model generatif berbilang modal Dia berminat dengan model resapan, model konsisten dan pecutan AIGC, dan komited untuk membangunkan model generasi akan datang. Sebelum ini, beliau menerbitkan banyak kertas kerja sebagai pengarang pertama di persidangan teratas seperti ICCV dan NeurIPS Tan Yiqin ialah pelajar sarjana tahun kedua di Universiti Tsinghua, dan penyelianya ialah Encik Huang Longbo. Sebagai sarjana, beliau belajar di Jabatan Kejuruteraan Elektronik di Universiti Tsinghua. Minat penyelidikannya terutamanya meliputi pembelajaran pengukuhan mendalam dan model penyebaran. Dalam penyelidikan terdahulu, beliau menerbitkan beberapa kertas berprofil tinggi sebagai pengarang pertama di persidangan akademik seperti ICLR, dan memberikan laporan lisan Perlu disebut bahawa salah seorang daripada keduanya adalah seorang guru dari Sekolah Perubatan Li Jian Di peringkat lanjutan. kelas teori komputer, idea LCM telah dicadangkan dan akhirnya dibentangkan sebagai projek kursus akhir. Antara tiga pengajar, Li Jian dan Huang Longbo ialah profesor bersekutu Institut Maklumat Antara Disiplin Tsinghua, dan Zhao Xing ialah penolong profesor Institut Maklumat Antara Disiplin Tsinghua. Baris pertama (dari kiri ke kanan): Luo Simian, Tan Yiqin. Baris kedua (dari kiri ke kanan): Huang Longbo, Li Jian, Zhao Xing. 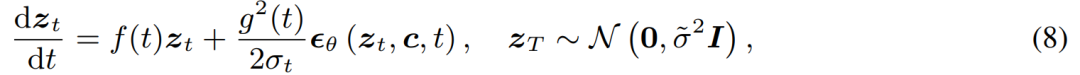


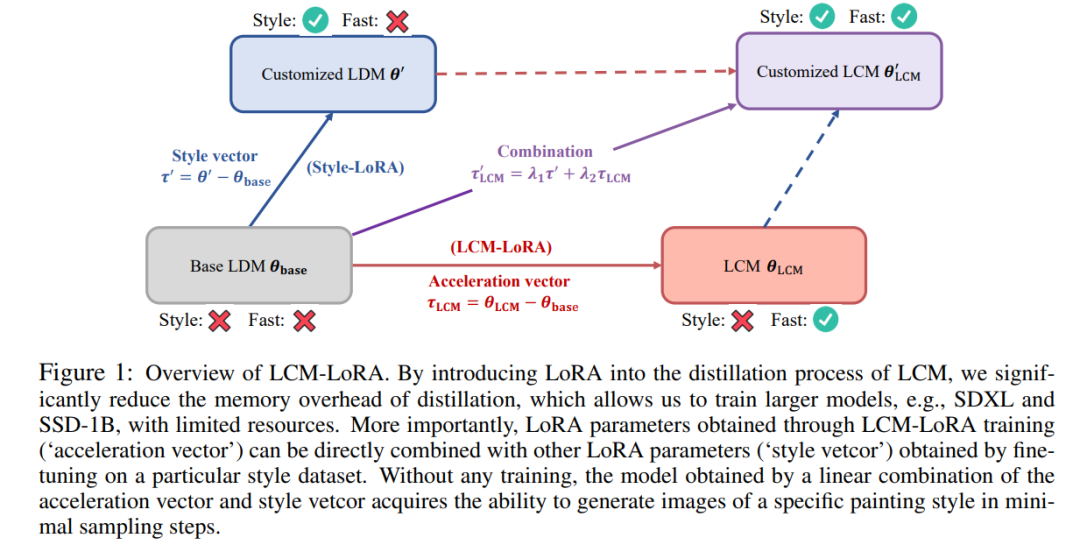
 Memandangkan proses penyulingan LCM dilakukan pada parameter model resapan pra-latihan, kita boleh menganggap penyulingan konsisten terpendam sebagai proses penalaan halus model resapan, supaya kita boleh menggunakan beberapa parameter yang cekap. kaedah penalaan, seperti LoRa.
Memandangkan proses penyulingan LCM dilakukan pada parameter model resapan pra-latihan, kita boleh menganggap penyulingan konsisten terpendam sebagai proses penalaan halus model resapan, supaya kita boleh menggunakan beberapa parameter yang cekap. kaedah penalaan, seperti LoRa. 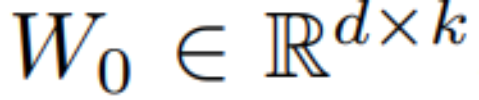 , kaedah kemas kininya dinyatakan sebagai
, kaedah kemas kininya dinyatakan sebagai 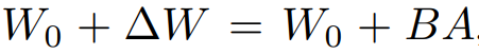 , di mana
, di mana 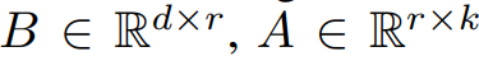 , semasa proses latihan, W_0 kekal tidak berubah, dan kemas kini kecerunan hanya digunakan pada dua parameter A dan B. Oleh itu untuk input x, perubahan perambatan ke hadapan dinyatakan sebagai:
, semasa proses latihan, W_0 kekal tidak berubah, dan kemas kini kecerunan hanya digunakan pada dua parameter A dan B. Oleh itu untuk input x, perubahan perambatan ke hadapan dinyatakan sebagai: 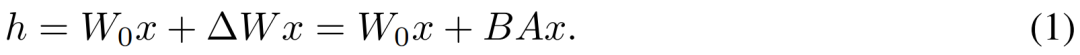



Atas ialah kandungan terperinci Kelajuan imej masa nyata meningkat 5-10 kali ganda, Tsinghua LCM/LCM-LoRA menjadi popular, dengan lebih sejuta tontonan dan lebih 200,000 muat turun. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menangani lag komputer yang perlahan dan tindak balas yang perlahan
Bagaimana untuk menangani lag komputer yang perlahan dan tindak balas yang perlahan
 midownload
midownload
 koleksi kod html
koleksi kod html
 Apakah hos maya php percuma di luar negara?
Apakah hos maya php percuma di luar negara?
 Bagaimana untuk memulihkan fail yang dipadam sepenuhnya pada komputer
Bagaimana untuk memulihkan fail yang dipadam sepenuhnya pada komputer
 Perkataan hilang selepas menaip
Perkataan hilang selepas menaip
 Apakah aplikasi Internet of Things?
Apakah aplikasi Internet of Things?
 Bagaimana untuk mencetuskan acara penekan kekunci
Bagaimana untuk mencetuskan acara penekan kekunci








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



