


Baru-baru ini, kelajuan kertas baharu diterbitkan begitu pantas sehingga saya rasa seperti tidak boleh membacanya. Dapat dilihat bahawa gabungan model besar berbilang modal untuk bahasa dan visi telah menjadi konsensus industri Artikel tentang UniPad ini lebih representatif, dengan input berbilang modal dan model asas pra-terlatih model seperti dunia, manakala. mudah untuk dikembangkan kepada pelbagai aplikasi penglihatan tradisional. Ia juga menyelesaikan masalah menggunakan kaedah pra-latihan model bahasa besar pada adegan 3D, sekali gus menyediakan kemungkinan model besar asas persepsi yang bersatu.
UniPAD ialah kaedah pembelajaran diselia sendiri berdasarkan pemaparan MAE dan 3D Ia boleh melatih model asas dengan prestasi cemerlang dan kemudian memperhalusi dan melatih tugas hiliran pada model, seperti anggaran kedalaman, pengesanan objek dan pembahagian. Kajian ini mereka bentuk kaedah perwakilan ruang 3D bersatu yang boleh disepadukan dengan mudah ke dalam rangka kerja 2D dan 3D, menunjukkan fleksibiliti yang lebih besar dan konsisten dengan kedudukan model asas
Apakah hubungan antara teknologi pengekodan auto bertopeng dan teknologi pemaparan boleh dibezakan 3D? Ringkasnya: Pengekodan auto bertopeng adalah untuk memanfaatkan keupayaan latihan penyeliaan sendiri Autoencoder dan teknologi pemaparan adalah untuk mengira fungsi kehilangan antara imej yang dijana dan imej asal dan menjalankan latihan yang diselia. Jadi logiknya masih sangat jelas.
Artikel ini menggunakan kaedah pra-latihan model asas, dan kemudian memperhalusi kaedah pengesanan hiliran dan kaedah segmentasi. Kaedah ini juga boleh membantu memahami cara model besar semasa berfungsi dengan tugas hiliran.
Nampaknya maklumat masa tidak digabungkan. Lagipun, NuScenes NDS of Pure Vision 50.2 pada masa ini masih lebih lemah berbanding dengan kaedah pengesanan masa (StreamPETR, Sparse4D, dll.). Oleh itu, kaedah 4D MAE juga patut dicuba Malah, GAIA-1 telah pun menyebut idea yang sama.
Bagaimana dengan jumlah pengiraan dan penggunaan memori?
UniPAD secara tersirat mengekodkan maklumat spatial 3D Ini terutamanya diilhamkan oleh pengekodan auto topeng (MAE, VoxelMAE, dsb.). untuk membina semula struktur bentuk 3D yang berterusan di tempat kejadian dan ciri penampilan kompleksnya pada satah 2D.
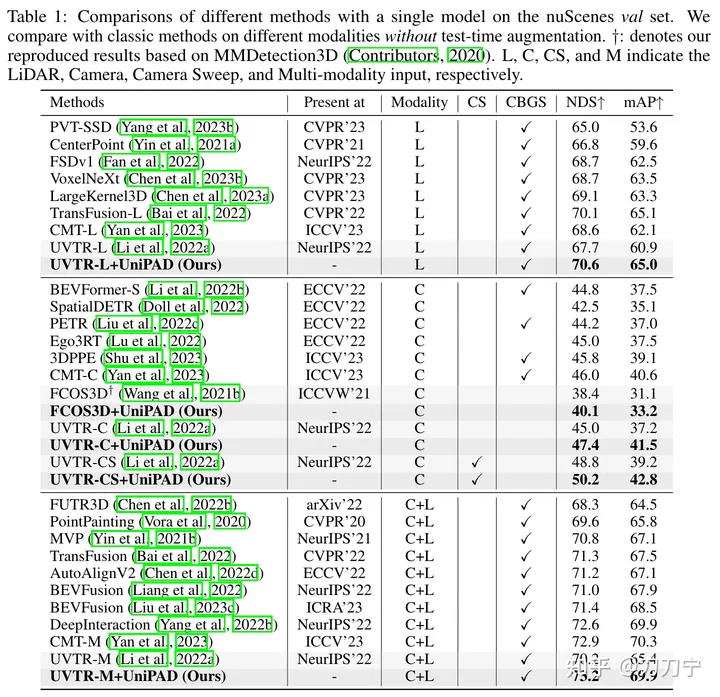
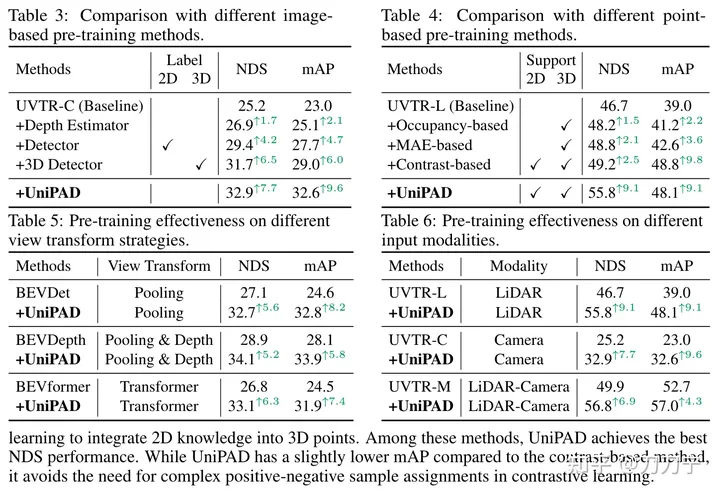
Keputusan percubaan kami membuktikan sepenuhnya keunggulan UniPAD. Berbanding dengan garis dasar gabungan lidar, kamera dan lidar-kamera tradisional, NDS UniPAD bertambah baik masing-masing sebanyak 9.1, 7.7 dan 6.9. Terutama, pada set pengesahan nuScenes, saluran paip pra-latihan kami mencapai NDS sebanyak 73.2 sambil mencapai skor mIoU sebanyak 79.4 pada tugas pembahagian semantik 3D, mencapai hasil terbaik berbanding kaedah sebelumnya
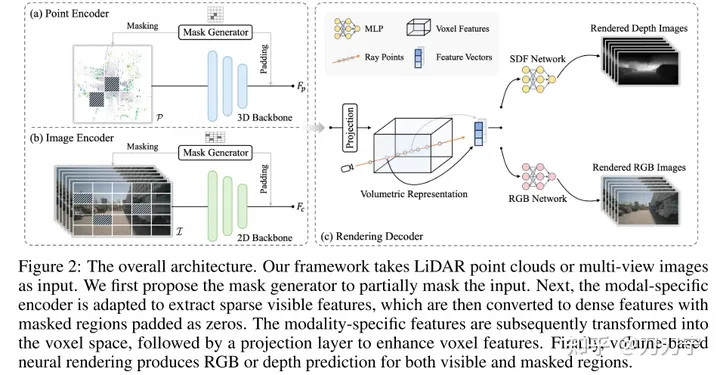 Keseluruhan seni bina. Rangka kerja mengambil LiDar dan imej berbilang tangkapan sebagai input, dan data berbilang modal ini diisi dengan sifar melalui Penjana Topeng. Benam bertopeng ditukar kepada ruang voxel dan teknik pemaparan digunakan untuk menjana RGB atau ramalan kedalaman dalam ruang 3D ini. Pada masa ini, imej asal yang tidak dikaburkan oleh topeng boleh digunakan sebagai data yang dijana untuk pembelajaran diselia.
Keseluruhan seni bina. Rangka kerja mengambil LiDar dan imej berbilang tangkapan sebagai input, dan data berbilang modal ini diisi dengan sifar melalui Penjana Topeng. Benam bertopeng ditukar kepada ruang voxel dan teknik pemaparan digunakan untuk menjana RGB atau ramalan kedalaman dalam ruang 3D ini. Pada masa ini, imej asal yang tidak dikaburkan oleh topeng boleh digunakan sebagai data yang dijana untuk pembelajaran diselia.
Kami mewakili pemandangan sebagai SDF (medan fungsi jarak yang ditandatangani tersirat), apabila input ialah koordinat 3D bagi titik pensampelan P (kedalaman yang sepadan di sepanjang sinar D) dan F (pembenaman ciri boleh diekstrak daripada perwakilan volumetrik oleh interpolasi trilinear), SDF boleh dianggap sebagai MLP untuk meramalkan nilai SDF bagi titik pensampelan. Di sini F boleh difahami sebagai kod pengekodan di mana titik P terletak. Kemudian output diperoleh: N (kondisikan medan warna pada permukaan normal) dan H (vektor ciri geometri Pada masa ini, RGB titik persampelan 3D boleh diperolehi melalui MLP dengan P, D, F, N). , H sebagai nilai input dan nilai kedalaman, dan kemudian letakkan titik pensampelan 3D ke ruang 2D melalui sinar untuk mendapatkan hasil pemaparan. Kaedah menggunakan Ray di sini pada asasnya sama dengan Nerf.
Kaedah pemaparan juga perlu mengoptimumkan penggunaan memori, yang tidak disenaraikan di sini. Namun, isu ini adalah isu pelaksanaan yang lebih kritikal. Intipati kaedah
Mask dan rendering adalah untuk melatih model pra-latihan Model pra-latihan boleh dilatih berdasarkan topeng yang diramalkan, walaupun tanpa cawangan berikutnya. Kerja model pra-latihan seterusnya menjana ramalan RGB dan kedalaman melalui cawangan yang berbeza, dan memperhalusi tugas seperti pengesanan sasaran/segmentasi semantik untuk mencapai keupayaan pasang dan main
Kehilangan. fungsi tidak kompleks.


Atas ialah kandungan terperinci UniPAD: Mod pra-latihan pemanduan autonomi universal! Pelbagai tugas persepsi boleh disokong. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 kekunci pintasan pr
kekunci pintasan pr
 Syiling naga inskripsi Bitcoin
Syiling naga inskripsi Bitcoin
 Bagaimana untuk membuka fail html WeChat
Bagaimana untuk membuka fail html WeChat
 Keperluan konfigurasi minimum untuk sistem win10
Keperluan konfigurasi minimum untuk sistem win10
 Bagaimana untuk mewakili nombor negatif dalam binari
Bagaimana untuk mewakili nombor negatif dalam binari
 Bagaimana untuk membeli Ripple di China
Bagaimana untuk membeli Ripple di China
 Cara membaca data excel dalam html
Cara membaca data excel dalam html
 Bagaimana untuk membuka kebenaran skop
Bagaimana untuk membuka kebenaran skop








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



