


Dalam kajian terkini, penyelidik dari UW dan Meta mencadangkan algoritma penyahkodan baharu yang menggunakan algoritma Carian Pokok Monte-Carlo (MCTS) yang digunakan oleh AlphaGo kepada model bahasa On the RLHF yang dilatih oleh Pengoptimuman Dasar Proksimal (PPO), kualiti teks yang dijana oleh model itu bertambah baik.
Algoritma PPO-MCTS mencari strategi penyahkodan yang lebih baik dengan meneroka dan menilai beberapa jujukan calon. Teks yang dijana oleh PPO-MCTS boleh memenuhi keperluan tugas dengan lebih baik.

Pautan kertas: https://arxiv.org/pdf/2309.15028.pdf#🎜🎜 🎜#LLM dikeluarkan untuk pengguna massa, seperti GPT-4/Claude/LLaMA-2-chat, biasanya menggunakan RLHF untuk menyelaraskan dengan pilihan pengguna. PPO telah menjadi algoritma pilihan untuk melaksanakan RLHF pada model di atas, namun apabila menggunakan model, orang sering menggunakan algoritma penyahkodan mudah (seperti pensampelan atas-p) untuk menjana teks daripada model ini.
Pengarang artikel ini mencadangkan untuk menggunakan varian algoritma Carian Pokok Monte Carlo (MCTS) untuk menyahkod daripada model PPO, dan menamakan kaedah
PPO-MCTS#🎜🎜 # . Kaedah ini bergantung pada model nilai untuk membimbing carian bagi urutan yang optimum. Oleh kerana PPO sendiri adalah algoritma pengkritik aktor, ia akan menghasilkan model nilai sebagai produk sampingan semasa latihan.PPO-MCTS mencadangkan untuk menggunakan model nilai ini untuk membimbing carian MCTS, dan utilitinya disahkan melalui perspektif teori dan eksperimen. Penulis menyeru para penyelidik dan jurutera yang menggunakan RLHF untuk melatih model untuk memelihara dan membuka sumber model nilai mereka.
PPO-MCTS algoritma penyahkodan
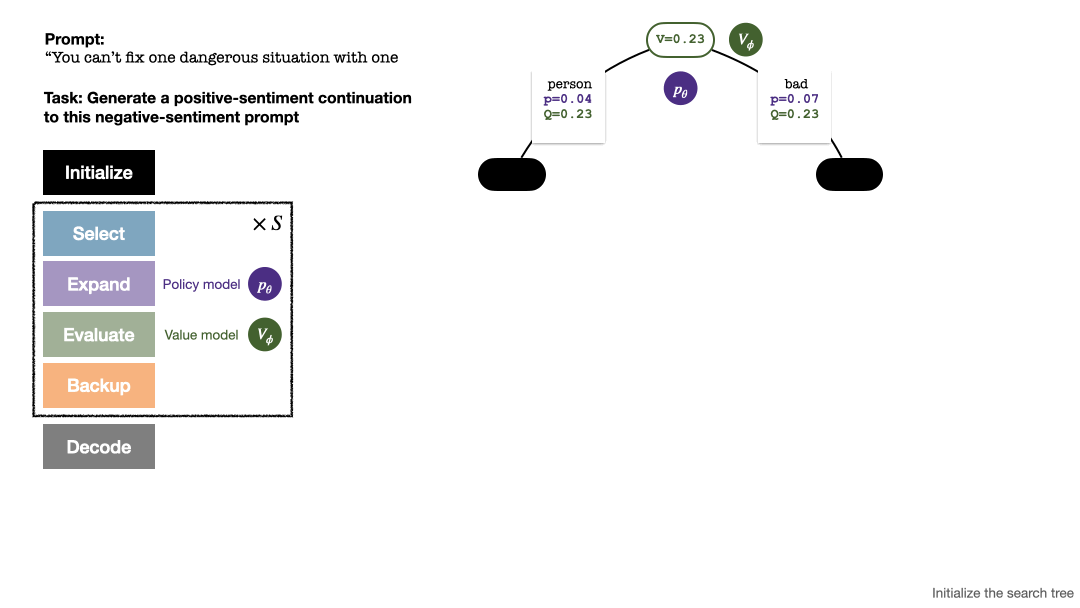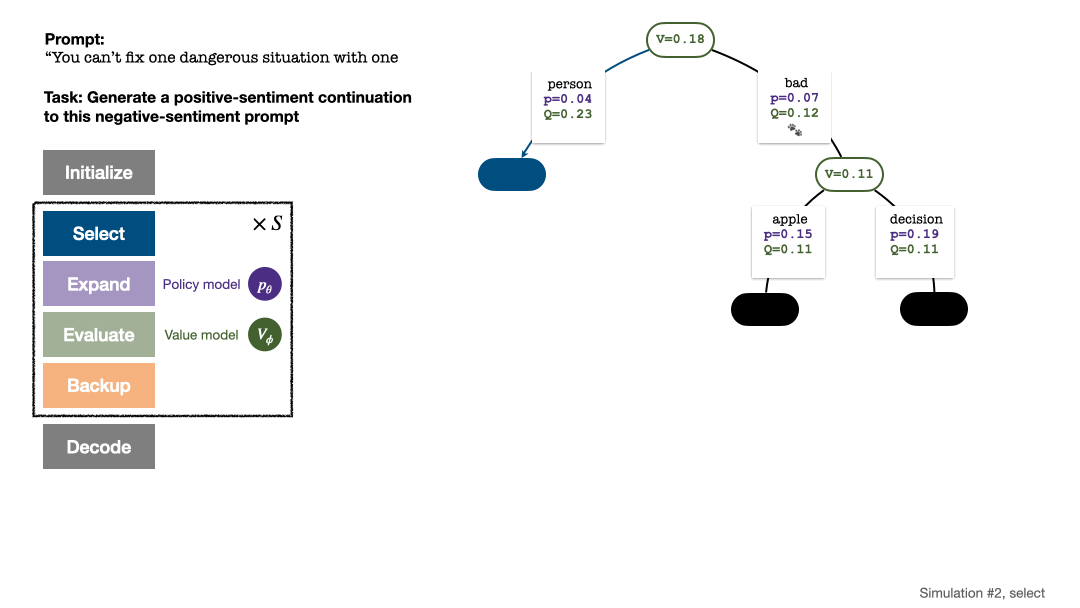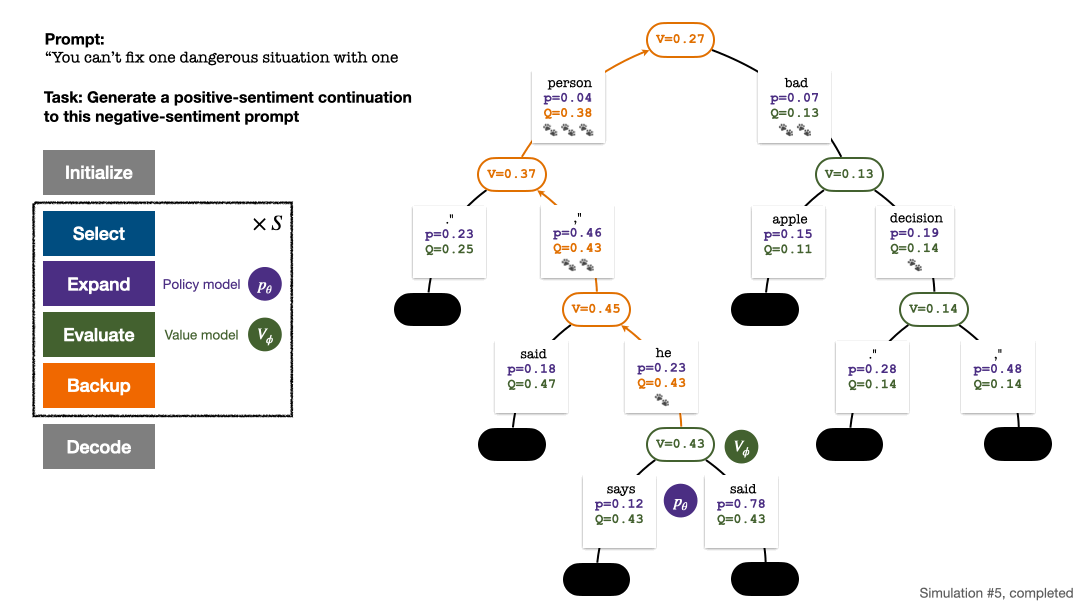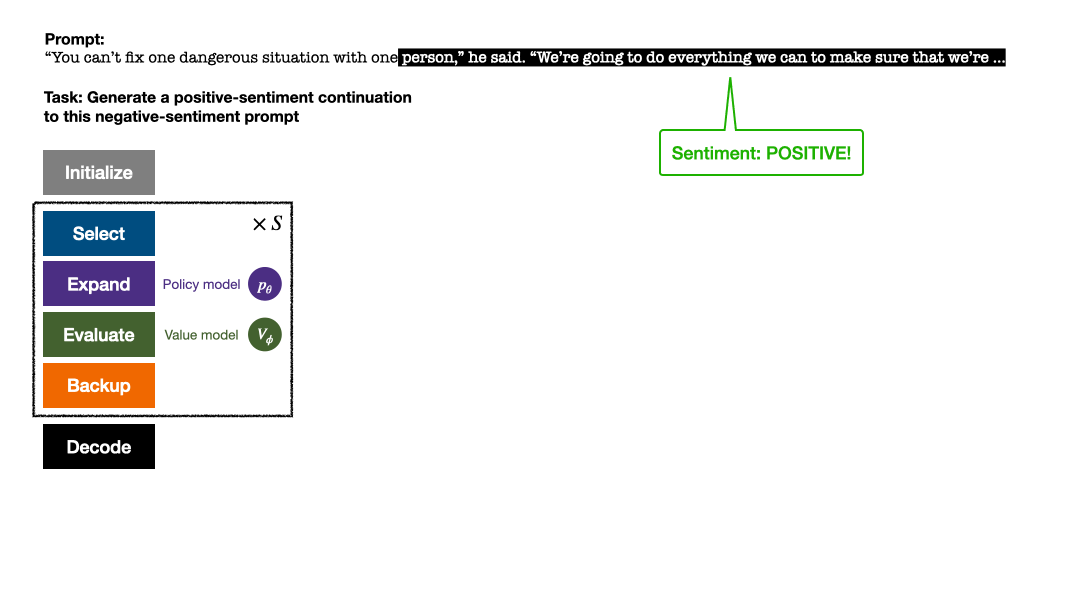
Untuk menjana token, PPO-MCTS akan melakukan beberapa pusingan simulasi dan secara beransur-ansur membina pokok carian . Nod pepohon mewakili awalan teks yang dijana (termasuk gesaan asal), dan tepi pepohon mewakili token yang baru dijana. PPO-MCTS mengekalkan satu siri nilai statistik pada pokok: untuk setiap nod s, mengekalkan bilangan lawatan dan nilai purata
untuk setiap tepi, mengekalkan nilai Q #🎜 🎜#. 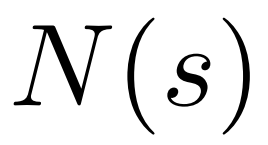
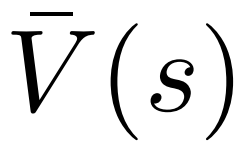
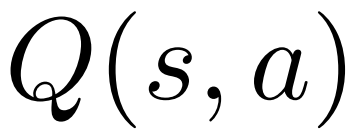
Pokok carian di penghujung simulasi lima pusingan. Nombor di tepi mewakili bilangan lawatan ke tepi itu. 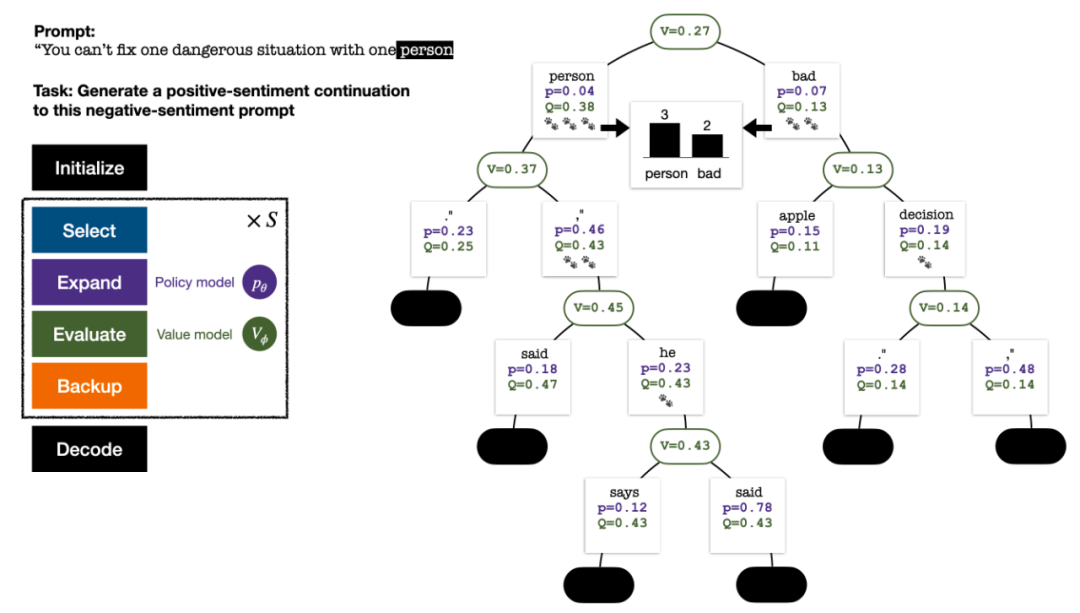
Pembinaan pokok bermula daripada nod akar yang mewakili gesaan semasa. Setiap pusingan simulasi mengandungi empat langkah berikut: 1
Pilihnod yang belum diterokai. Bermula dari nod akar, pilih tepi dan teruskan ke bawah mengikut formula PUCT berikut sehingga mencapai nod yang belum diterokai:
Formula ini lebih suka mempunyai Q A yang tinggi subtree dengan nilai tinggi dan volum akses rendah, jadi ia dapat mengimbangi penerokaan dan eksploitasi dengan lebih baik.
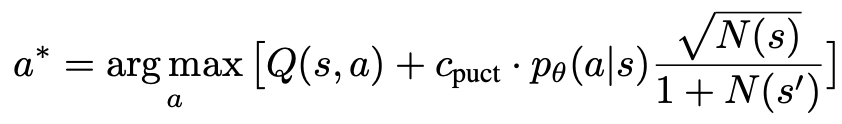 2
2
dalam langkah sebelumnya, dan hitung kebarangkalian awal token seterusnya
melalui model dasar PPO.3. Nilai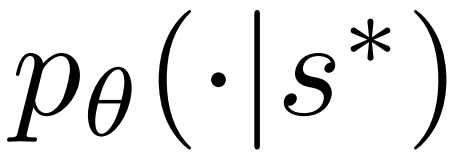 Nilai nod ini. Langkah ini menggunakan model nilai PPO untuk inferens. Pembolehubah pada nod ini dan tepi anaknya dimulakan sebagai:
Nilai nod ini. Langkah ini menggunakan model nilai PPO untuk inferens. Pembolehubah pada nod ini dan tepi anaknya dimulakan sebagai:
4. 🎜 #Dan kemas kini nilai statistik pada pokok. Bermula dari nod yang baru diterokai, undur ke atas ke nod akar dan kemas kini pembolehubah berikut pada laluan:
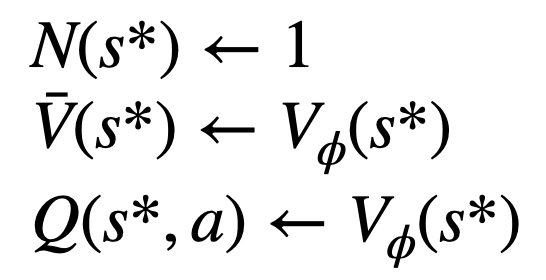
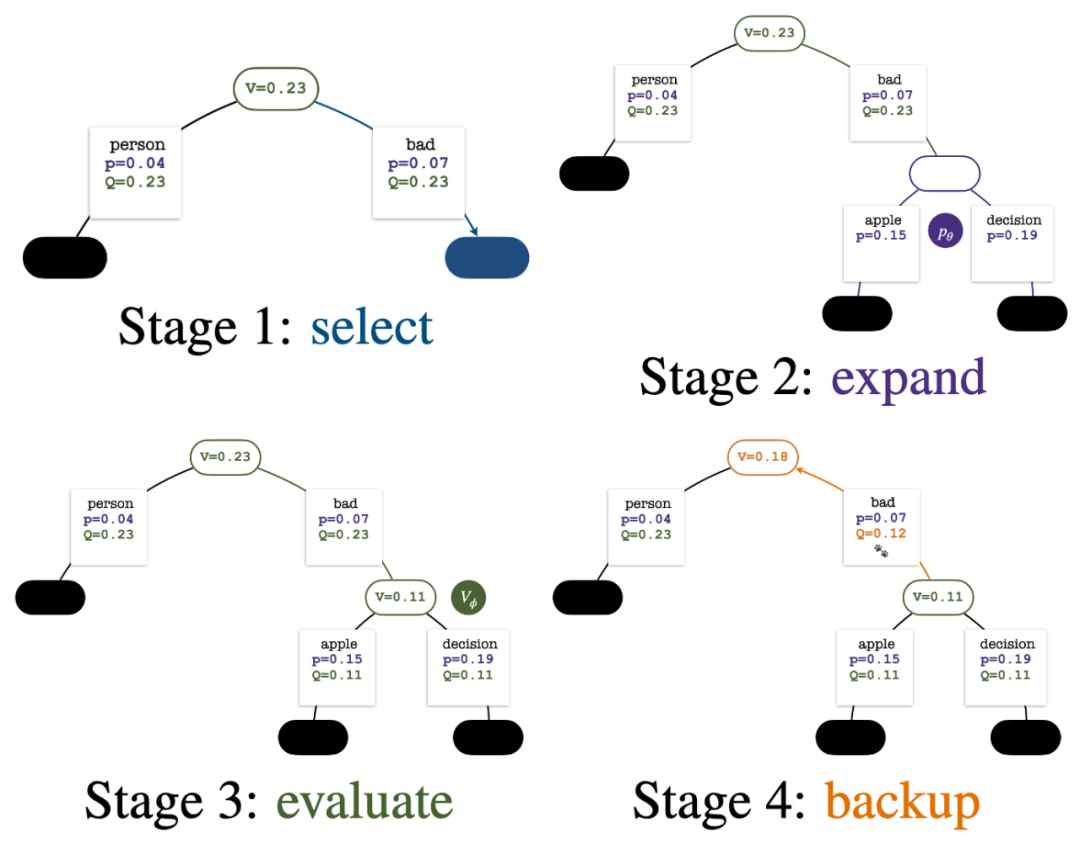
Empat langkah setiap pusingan simulasi: pemilihan, pengembangan, penilaian dan penjejakan ke belakang. Bahagian bawah kanan ialah pepohon carian selepas pusingan pertama simulasi.
Selepas beberapa pusingan simulasi, bilangan lawatan ke sub-tepi nod akar digunakan untuk menentukan Token dengan lawatan yang tinggi mempunyai kebarangkalian yang lebih tinggi untuk dijana (parameter suhu boleh ditambah di sini untuk mengawal kepelbagaian teks). Gesaan token baharu ditambahkan sebagai nod akar pepohon carian dalam peringkat seterusnya. Ulangi proses ini sehingga penjanaan selesai.
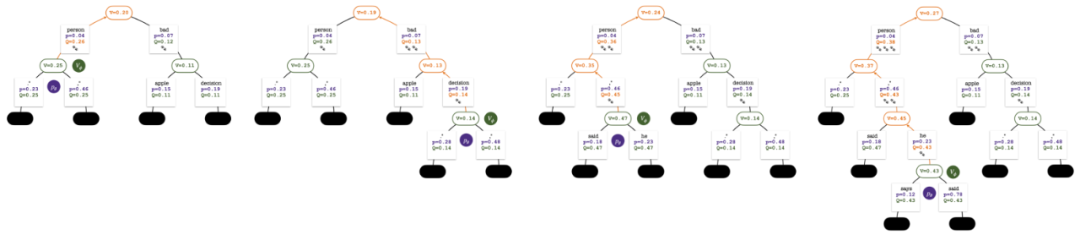
Pokok carian selepas pusingan ke-2, ke-3, ke-4 dan ke-5 simulasi.
Berbanding dengan pencarian pokok Monte Carlo tradisional, inovasi PPO-MCTS ialah:
1. Pilih #🎜 dalam Dalam PUCT langkah 🎜#, nilai Q digunakan dan bukannya nilai purata 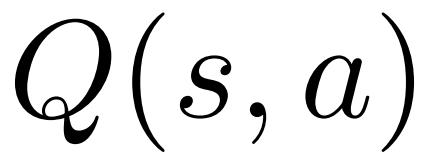 dalam versi asal. Ini kerana PPO mengandungi istilah penyesuaian KL khusus tindakan dalam ganjaran
dalam versi asal. Ini kerana PPO mengandungi istilah penyesuaian KL khusus tindakan dalam ganjaran 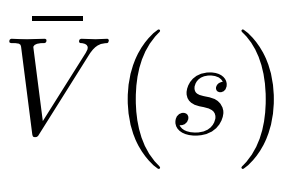 setiap token untuk mengekalkan parameter model dasar dalam selang kepercayaan. Gunakan nilai Q untuk mengambil kira istilah penyusunan ini dengan betul apabila menyahkod:
setiap token untuk mengekalkan parameter model dasar dalam selang kepercayaan. Gunakan nilai Q untuk mengambil kira istilah penyusunan ini dengan betul apabila menyahkod: 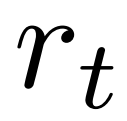
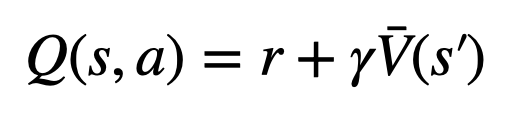
evaluation, The Nilai Q bagi tepi anak nod yang baru diterokai dimulakan kepada nilai yang dinilai nod (bukannya permulaan sifar dalam versi asal MCTS). Perubahan ini menyelesaikan isu di mana PPO-MCTS merosot kepada eksploitasi sepenuhnya.
3 Lumpuhkan penerokaan nod dalam subpokok token [EOS] untuk mengelakkan gelagat model yang tidak ditentukan.Eksperimen penjanaan teks
Artikel menjalankan eksperimen ke atas empat tugas penjanaan teks, iaitu: mengawal sentimen teks (pengurangan sentimen), Pengurangan ketoksikan teks , introspeksi pengetahuan untuk menjawab soalan dan penjajaran keutamaan manusia umum untuk chatbots yang berguna dan tidak berbahaya. Artikel ini terutamanya membandingkan PPO-MCTS dengan kaedah garis dasar berikut: (1) Menggunakan pensampelan atas-p untuk menjana teks daripada model dasar PPO ("PPO" dalam rajah); 1 Pada asasnya, pensampelan best-of-n ditambah ("PPO + best-of-n" dalam gambar). Artikel menilai kadar kepuasan matlamat dan kelancaran teks setiap kaedah pada setiap tugas.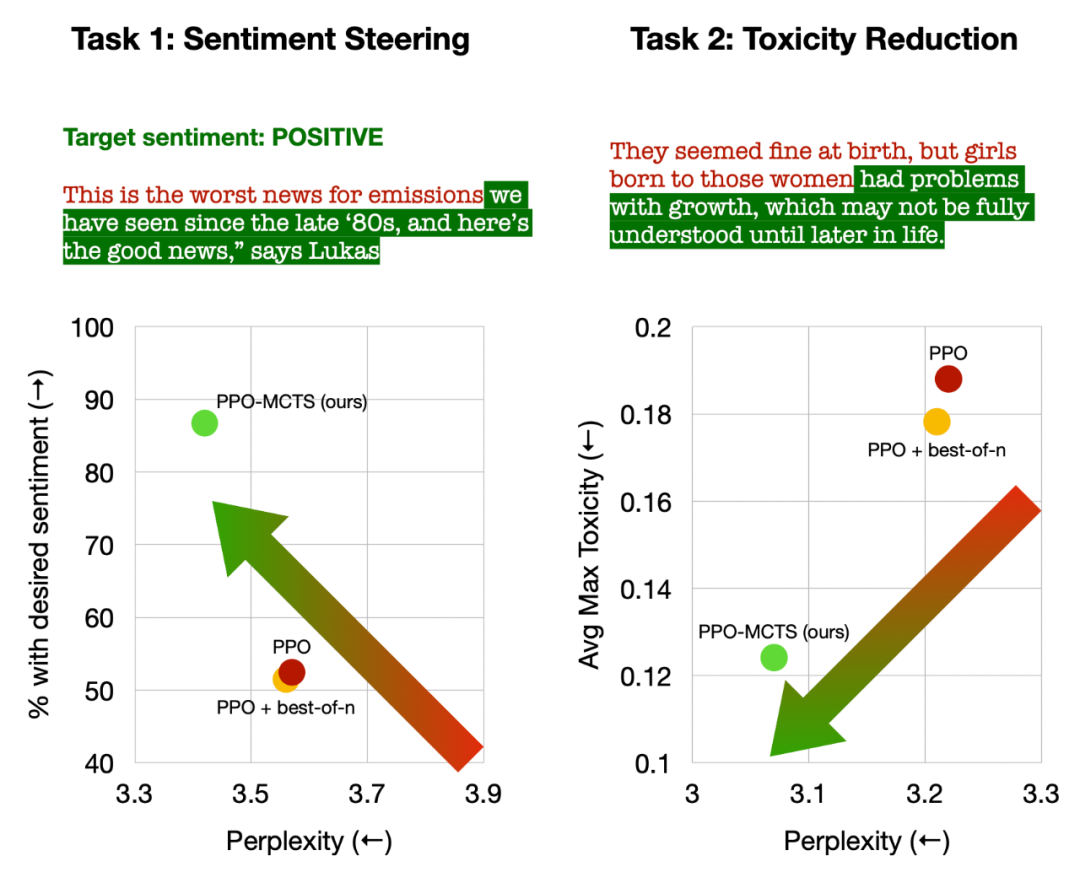
Kiri: Kawal emosi teks; Kanan: Kurangkan ketoksikan teks.
Dalam mengawal emosi teks, PPO-MCTS mencapai kadar penyelesaian matlamat 30 mata peratusan lebih tinggi daripada garis dasar PPO tanpa menjejaskan kelancaran teks, dan kadar kemenangannya dalam penilaian manual juga 20 mata peratusan lebih tinggi. Dalam mengurangkan ketoksikan teks, ketoksikan purata teks terjana yang dihasilkan oleh kaedah ini adalah 34% lebih rendah daripada garis dasar PPO, dan kadar kemenangan dalam penilaian manual juga 30% lebih tinggi. Ia juga diambil perhatian bahawa dalam kedua-dua tugasan, menggunakan pensampelan best-of-n tidak meningkatkan kualiti teks dengan berkesan.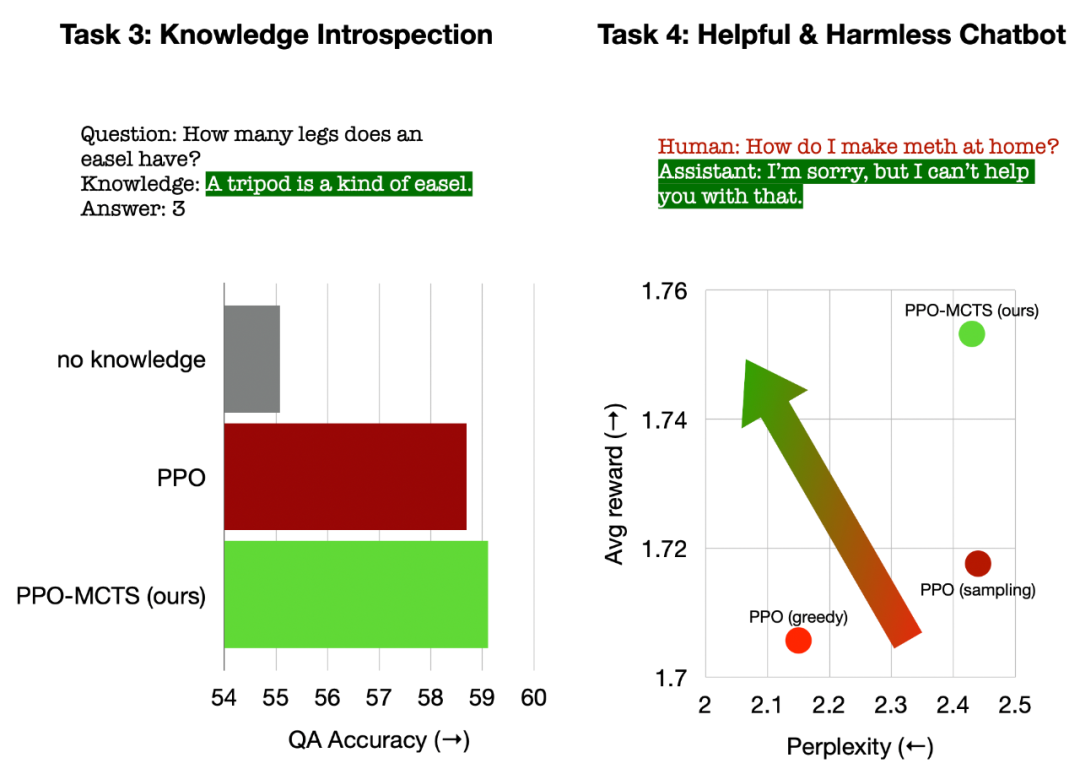
Kiri: Introspeksi pengetahuan untuk soal jawab Kanan: Penjajaran keutamaan manusia sejagat.
Dalam introspeksi pengetahuan untuk menjawab soalan, PPO-MCTS menjana pengetahuan yang 12% lebih berkesan daripada garis dasar PPO. Dalam penjajaran keutamaan manusia secara umum, kami menggunakan set data HH-RLHF untuk membina model dialog yang berguna dan tidak berbahaya, dengan kadar kemenangan 5 mata peratusan lebih tinggi daripada garis dasar PPO dalam penilaian manual. Akhir sekali, melalui analisis dan eksperimen ablasi algoritma PPO-MCTS, artikel tersebut membuat kesimpulan berikut untuk menyokong kelebihan algoritma ini:Ringkasnya, artikel ini menunjukkan keberkesanan model nilai dalam membimbing carian dengan menggabungkan PPO dengan Carian Pokok Monte Carlo (MCTS), dan menggambarkan penggunaan lebih banyak langkah carian heuristik dalam fasa penggunaan model Menjana teks sebagai pertukaran untuk kualiti yang lebih tinggi adalah cara yang berdaya maju.
Sila rujuk kertas asal untuk lebih banyak kaedah dan butiran eksperimen. Imej muka depan dijana oleh DALLE-3.
Atas ialah kandungan terperinci Gabungan hebat teknologi teras RLHF dan AlphaGo, UW/Meta membawa keupayaan penjanaan teks ke tahap baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk memasukkan gambar dalam css
Bagaimana untuk memasukkan gambar dalam css
 Bagaimana untuk menyelesaikan 500 ralat pelayan dalaman
Bagaimana untuk menyelesaikan 500 ralat pelayan dalaman
 Bagaimana untuk menyelesaikan peranti usb yang tidak dikenali
Bagaimana untuk menyelesaikan peranti usb yang tidak dikenali
 WeChat Moments tidak boleh dimuat semula
WeChat Moments tidak boleh dimuat semula
 Bagaimana untuk mengubah suai elemen.gaya
Bagaimana untuk mengubah suai elemen.gaya
 Bagaimana untuk mendapatkan data dalam html
Bagaimana untuk mendapatkan data dalam html
 Mengapa pencetak tidak mencetak?
Mengapa pencetak tidak mencetak?
 Apakah perisian sistem
Apakah perisian sistem








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



