


Kandungan yang dijana AI telah menjadi salah satu topik paling hangat dalam bidang kecerdasan buatan semasa dan mewakili teknologi termaju dalam bidang ini. Dalam beberapa tahun kebelakangan ini, dengan keluaran teknologi baharu seperti Stable Diffusion, DALL-E3, dan ControlNet, bidang penjanaan dan penyuntingan imej AI telah mencapai kesan visual yang menakjubkan, dan telah mendapat perhatian dan perbincangan meluas dalam kedua-dua akademik dan industri. Kebanyakan kaedah ini adalah berdasarkan model resapan, yang merupakan kunci kepada keupayaan mereka untuk mencapai penjanaan terkawal yang berkuasa, penjanaan fotorealistik dan kepelbagaian.
Walau bagaimanapun, berbanding dengan imej statik yang ringkas, video mempunyai maklumat semantik yang lebih kaya dan perubahan dinamik. Video boleh menunjukkan evolusi dinamik objek fizikal, jadi keperluan dan cabaran dalam bidang penjanaan dan penyuntingan video adalah lebih kompleks. Walaupun dalam bidang ini, penyelidikan mengenai penjanaan video sentiasa menghadapi kesukaran kerana keterbatasan dalam data beranotasi dan sumber pengkomputeran, beberapa kerja penyelidikan yang mewakili, seperti Make-A-Video, Imagen Video dan Gen-2, telah pun bermula secara beransur-ansur kedudukan dominan.
Kerja-kerja penyelidikan ini menerajui hala tuju pembangunan teknologi penjanaan dan penyuntingan video. Data penyelidikan menunjukkan bahawa sejak 2022, kerja penyelidikan tentang model penyebaran pada tugasan video telah menunjukkan pertumbuhan yang meletup. Trend ini bukan sahaja mencerminkan populariti model penyebaran video dalam akademik dan industri, tetapi juga menyerlahkan keperluan mendesak untuk penyelidik dalam bidang ini untuk terus membuat penemuan dan inovasi dalam teknologi penjanaan video.
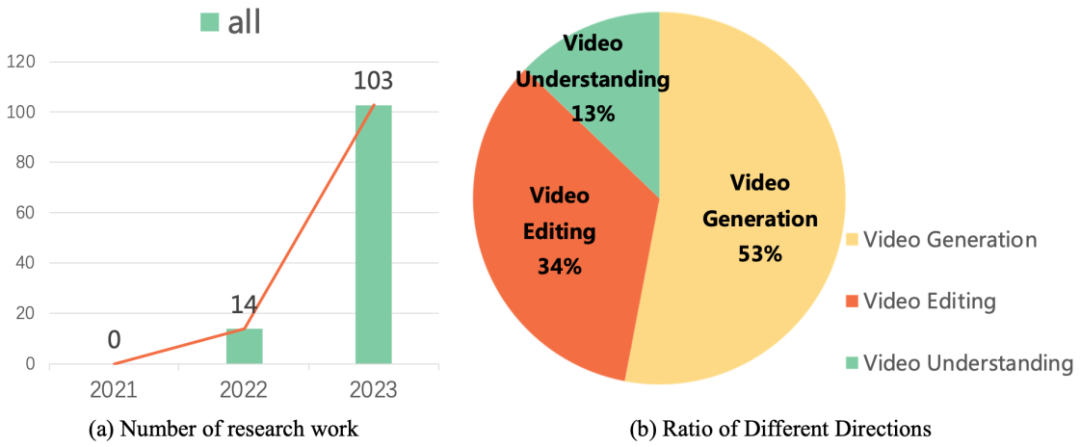
Baru-baru ini, Makmal Visi dan Pembelajaran Universiti Fudan, bersama-sama dengan Microsoft, Huawei dan institusi akademik lain, mengeluarkan ulasan pertama kerja model penyebaran pada tugasan video, menyusun aplikasi secara sistematik model resapan dalam penjanaan video, video Hasil akademik termaju dalam penyuntingan dan pemahaman video.

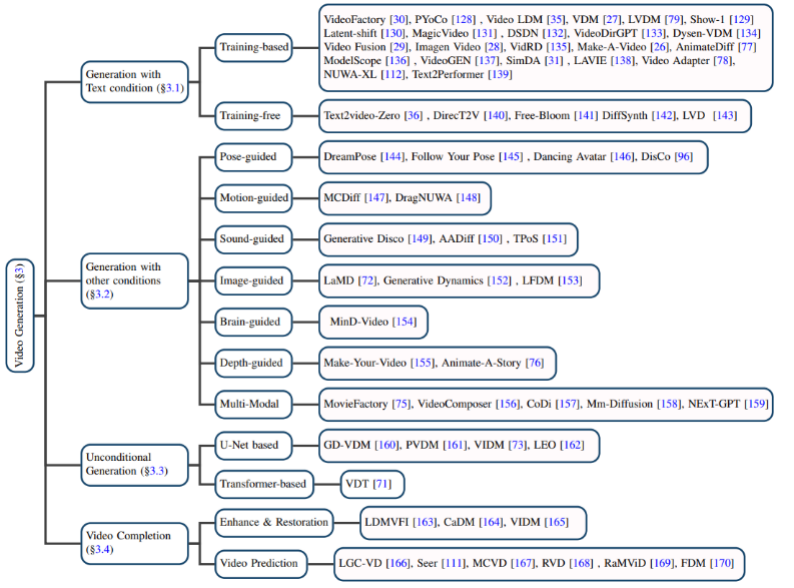
Penjanaan video berasaskan teks: Penjanaan video dengan bahasa semula jadi sebagai input adalah salah satu tugasan yang paling penting dalam bidang ini. Penulis terlebih dahulu menyemak hasil penyelidikan dalam bidang ini sebelum model resapan dicadangkan, dan kemudian masing-masing memperkenalkan model penjanaan teks-video berasaskan latihan dan tanpa latihan.

Animasi salji musim sejuk perayaan percutian pokok Krismas.
Penjanaan video berdasarkan syarat lain: Kerja penjanaan video di kawasan khusus. Pengarang mengklasifikasikannya berdasarkan syarat berikut: pose (berpandukan pose), aksi (berpandukan gerakan), bunyi (berpandukan bunyi), imej (berpandukan imej), peta kedalaman (berpandukan kedalaman), dsb. Generasi Video Lunconditional: Tugas ini merujuk kepada penjanaan video tanpa syarat input dalam bidang tertentu. berasaskan dan model generatif berasaskan Transformer.
 Penyiapan video:
Penyiapan video:
Terutamanya termasuk peningkatan dan pemulihan video, ramalan video dan tugasan lain.

Set data: Set data yang digunakan dalam tugas penjanaan video boleh dibahagikan kepada dua kategori berikut:
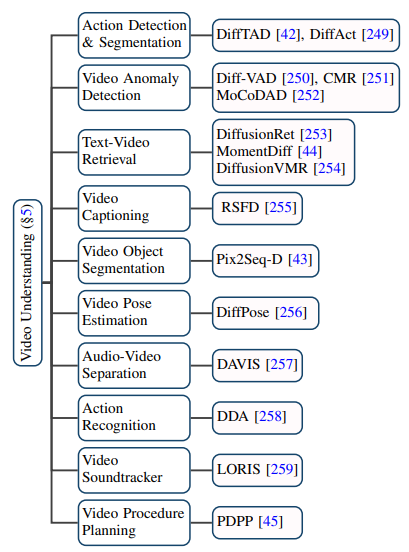
1.Peringkat kapsyen: Setiap video mempunyai maklumat perihalan teks yang terakhir dan maklumat perihalan teks terakhir yang paling mewakili ialah set data WebVid10M.2. Peringkat kategori: Video hanya mempunyai label klasifikasi tetapi tiada maklumat perihalan teks pada masa ini ialah set data yang paling biasa digunakan untuk tugas seperti penjanaan video dan ramalan video. Kompetisi penunjuk dan hasil penilaian: Petunjuk penilaian yang dihasilkan oleh video terutamanya dibahagikan kepada petunjuk penilaian peringkat kualiti dan petunjuk penilaian peringkat kuantitatif. pemarkahan, manakala kuantitatif Penunjuk penilaian pada peringkat imej boleh dibahagikan kepada: 1 Penunjuk penilaian peringkat imej: Video terdiri daripada satu siri bingkai imej, jadi kaedah penilaian peringkat imej pada asasnya merujuk kepada. penunjuk penilaian model T2I. 2. Penunjuk penilaian peringkat video: Berbanding dengan penunjuk penilaian peringkat imej, yang lebih berat sebelah terhadap pengukuran bingkai demi bingkai, penunjuk penilaian peringkat video boleh mengukur aspek seperti koheren temporal video yang dihasilkan. Selain itu, penulis juga membuat perbandingan mendatar penunjuk penilaian model generatif yang disebutkan di atas set data penanda aras. Baik menyikat melalui banyak kajian, penulis mendapati bahawa matlamat utama tugas penyuntingan video adalah untuk mencapai: 1. Bingkai video yang diedit hendaklah konsisten dalam kandungan dengan video asal. 2. Penjajaran: Video yang diedit perlu diselaraskan dengan syarat input. 3. Kualiti tinggi: Video yang diedit hendaklah koheren dan berkualiti tinggi. Suntingan video berasaskan teks: Memandangkan skala terhad data teks-video sedia ada, kebanyakan tugas penyuntingan video berasaskan teks semasa cenderung menggunakan model T2I yang telah terlatih dan menyelesaikan bingkai video berdasarkan isu keselarasan ini dan ketidakselarasan semantik. Penulis selanjutnya membahagikan tugas-tugas tersebut kepada kaedah berasaskan latihan, tanpa latihan dan kaedah tala sekali pukulan, dan meringkaskannya masing-masing. Penyuntingan video berdasarkan syarat lain: Dengan kemunculan era model besar, sebagai tambahan kepada maklumat bahasa semula jadi yang paling langsung sebagai penyuntingan video bersyarat, ia terdiri daripada arahan, bunyi, tindakan, pengeditan video berbilang mod dengan status dan syarat lain sebagai syarat yang semakin mendapat perhatian, dan pengarang juga telah mengklasifikasikan dan menyusun kerja yang sepadan. Pengeditan video dalam bidang khusus tertentu: Sesetengah kerja memfokuskan kepada keperluan untuk penyesuaian khas tugas penyuntingan video dalam kawasan tertentu, seperti mewarna video, menyunting video potret, dsb. Aplikasi model resapan dalam medan video telah jauh melangkaui penjanaan video tradisional dan tugasan penyuntingan juga telah menunjukkan potensi besar dalam tugas pemahaman video. Dengan menjejaki kertas canggih, penulis meringkaskan 10 senario aplikasi sedia ada seperti pembahagian temporal video, pengesanan anomali video, pembahagian objek video, pengambilan video teks dan pengecaman tindakan. Semakan ini secara komprehensif dan teliti meringkaskan penyelidikan terkini tentang tugasan video dalam model penyebaran dalam era AIGC Menurut objek penyelidikan dan ciri teknikal, lebih daripada seratus karya canggih dikelaskan dan diringkaskan Model-model ini dibandingkan pada beberapa tanda aras klasik. Selain itu, model resapan juga mempunyai beberapa hala tuju dan cabaran penyelidikan baharu dalam bidang tugasan video, seperti: 1 Pengumpulan set data teks-video berskala besar: Kejayaan model T2I tidak dapat dipisahkan daripada ratusan daripada berjuta-juta kualiti tinggi Begitu juga, model T2V juga memerlukan sejumlah besar data teks-video beresolusi tinggi tanpa tera air sebagai sokongan. 2 Latihan dan inferens yang cekap: Berbanding dengan data imej, data video adalah berskala besar, dan kuasa pengkomputeran yang diperlukan dalam peringkat latihan dan inferens juga telah meningkat secara eksponen Latihan yang cekap dan algoritma inferens boleh mengurangkan kos. 3. Penanda aras dan penunjuk penilaian yang boleh dipercayai: Penunjuk penilaian sedia ada dalam medan video sering mengukur perbezaan pengedaran antara video yang dijana dan video asal, tetapi gagal untuk mengukur sepenuhnya kualiti video yang dijana. Pada masa yang sama, ujian pengguna masih merupakan salah satu kaedah penilaian yang penting Memandangkan ia memerlukan banyak tenaga kerja dan sangat subjektif, terdapat keperluan mendesak untuk penunjuk penilaian yang lebih objektif dan komprehensif. 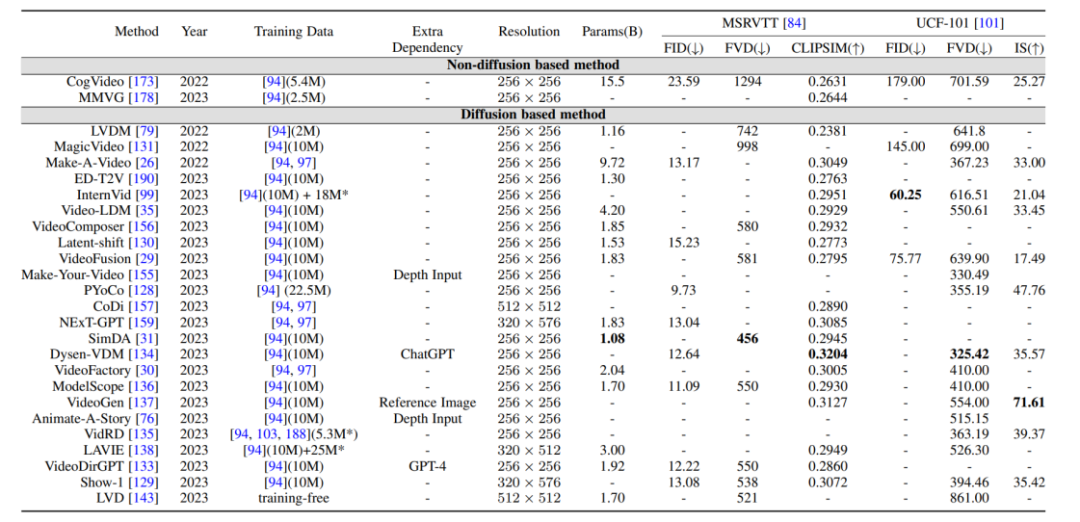
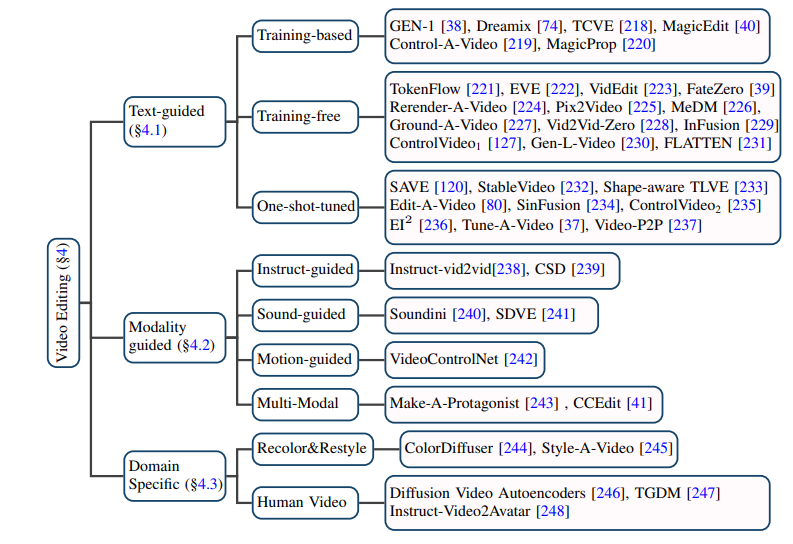
Video penyuntingan


Pemahaman Video
Masa Depan dan Ringkasan
Atas ialah kandungan terperinci Model penyebaran video dalam era AIGC, Fudan dan pasukan lain mengeluarkan ulasan pertama di lapangan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 penggunaan fungsi fungsi
penggunaan fungsi fungsi
 Bagaimana untuk melihat prosedur tersimpan dalam MySQL
Bagaimana untuk melihat prosedur tersimpan dalam MySQL
 Bagaimana untuk menyemak rekod panggilan yang dipadamkan
Bagaimana untuk menyemak rekod panggilan yang dipadamkan
 Perbezaan antara sisipan sebelum dan sebelum
Perbezaan antara sisipan sebelum dan sebelum
 Bahasa apakah yang biasanya digunakan untuk menulis vscode?
Bahasa apakah yang biasanya digunakan untuk menulis vscode?
 Bagaimana untuk menukar nef kepada format jpg
Bagaimana untuk menukar nef kepada format jpg
 Kedudukan sepuluh pertukaran mata wang digital teratas
Kedudukan sepuluh pertukaran mata wang digital teratas
 Apakah teras sistem pangkalan data?
Apakah teras sistem pangkalan data?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



