


Minggu ini, Persidangan Antarabangsa mengenai Penglihatan Komputer (ICCV) dibuka di Paris, Perancis.

Sebagai persidangan akademik terbaik dunia dalam bidang visi komputer, ICCV diadakan setiap dua tahun.
Seperti CVPR, populariti ICCV telah mencapai tahap tertinggi baharu.
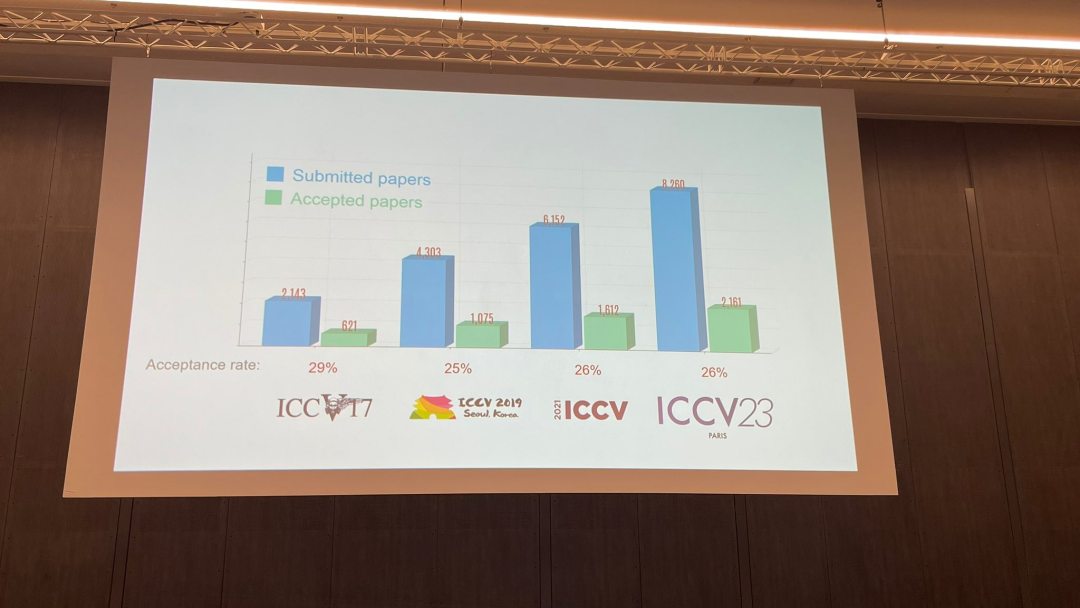
Pada majlis perasmian hari ini, ICCV secara rasmi mengumumkan data kertas tahun ini: jumlah penyerahan kepada ICCV tahun ini mencapai 8,068, di mana 2,160 telah diterima, dengan kadar penerimaan 26.8%, lebih tinggi sedikit daripada ICCV 2021 sebelumnya Kadar penerimaan ialah 25.9%
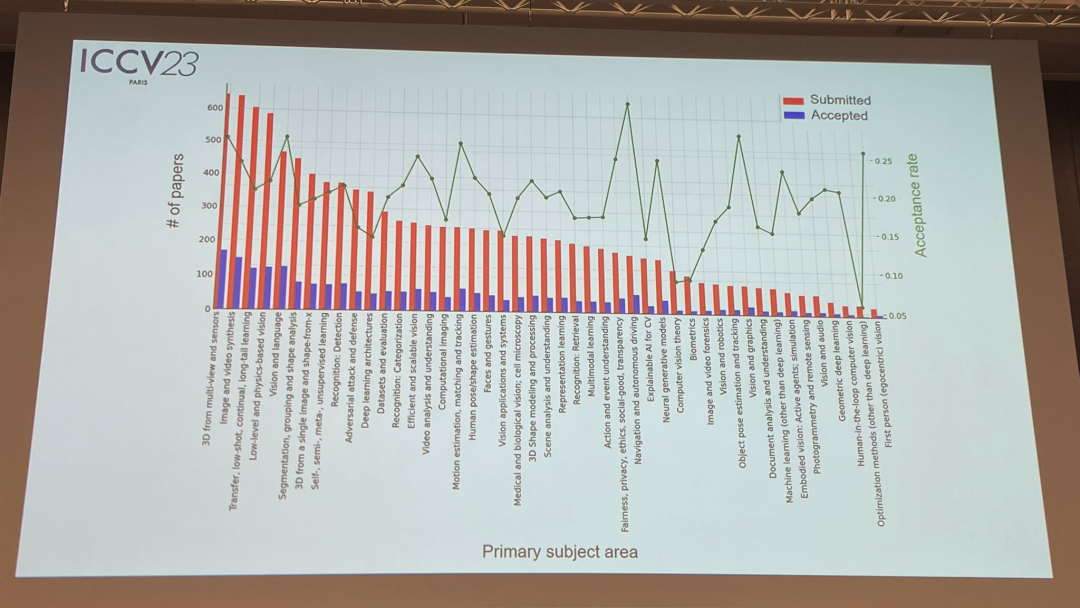
Mengenai topik kertas, pegawai itu juga mengeluarkan data yang berkaitan: Teknologi 3D dengan pelbagai perspektif dan sensor adalah yang paling popular
, dalam kebanyakan majlis perasmian hari ini bahagian penting Ia adalah untuk mengumumkan maklumat pemenang. Sekarang, mari kita dedahkan kertas terbaik, pencalonan kertas terbaik dan kertas pelajar terbaik satu demi satu
Sebanyak dua kertas memenangi kertas terbaik tahun ini (Hadiah Marr).
Artikel pertama adalah daripada seorang penyelidik di Universiti Toronto.

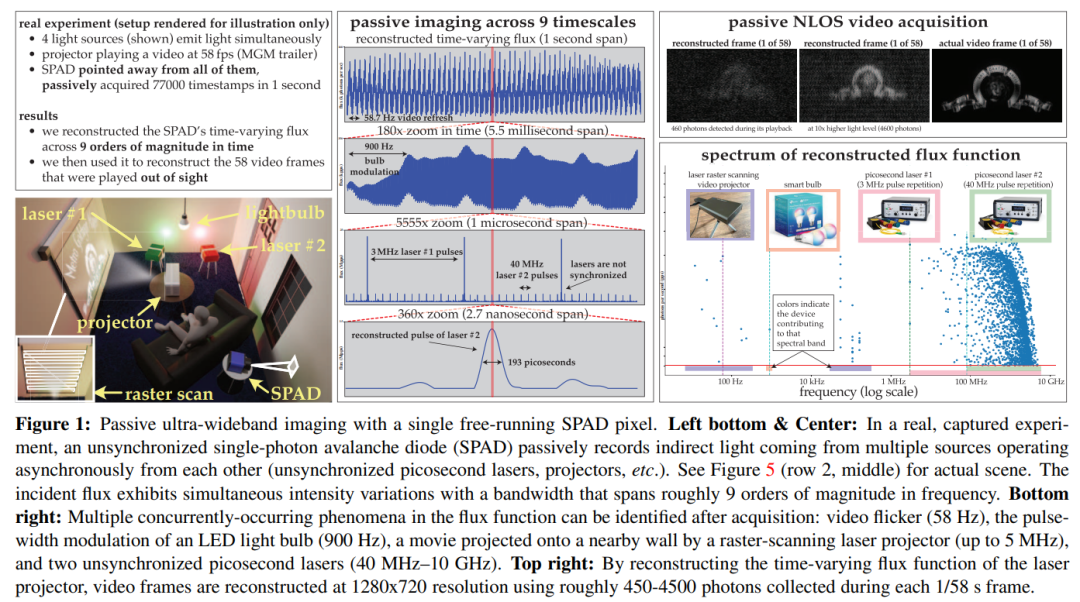
Kertas ini menggunakan teori ini untuk menunjukkan bahawa kamera SPAD yang berjalan bebas pasif mempunyai lebar jalur frekuensi yang boleh dicapai di bawah keadaan fluks rendah yang boleh menjangkau seluruh julat DC hingga 31 GHz. Pada masa yang sama, kertas kerja ini juga memperoleh algoritma pembinaan semula fluks domain Fourier yang baru dan memastikan model hingar bagi algoritma ini masih berkesan pada kiraan foton yang sangat rendah atau masa mati yang tidak boleh diabaikan
ditunjukkan melalui eksperimen Potensi ini mekanisme pengimejan tak segerak ialah: (1) pengimejan adegan yang disinari secara serentak oleh sumber cahaya (seperti mentol lampu, projektor, laser berdenyut berbilang) beroperasi pada kelajuan yang berbeza, tanpa memerlukan penyegerakan (2) mencapai pasif bukan barisan; penglihatan Pemerolehan video; (3) Rakam video jalur lebar ultra dan kemudian mainkannya semula pada 30 Hz untuk menunjukkan pergerakan harian, atau mainkannya semula satu bilion kali lebih perlahan untuk menunjukkan perambatan cahaya itu sendiri

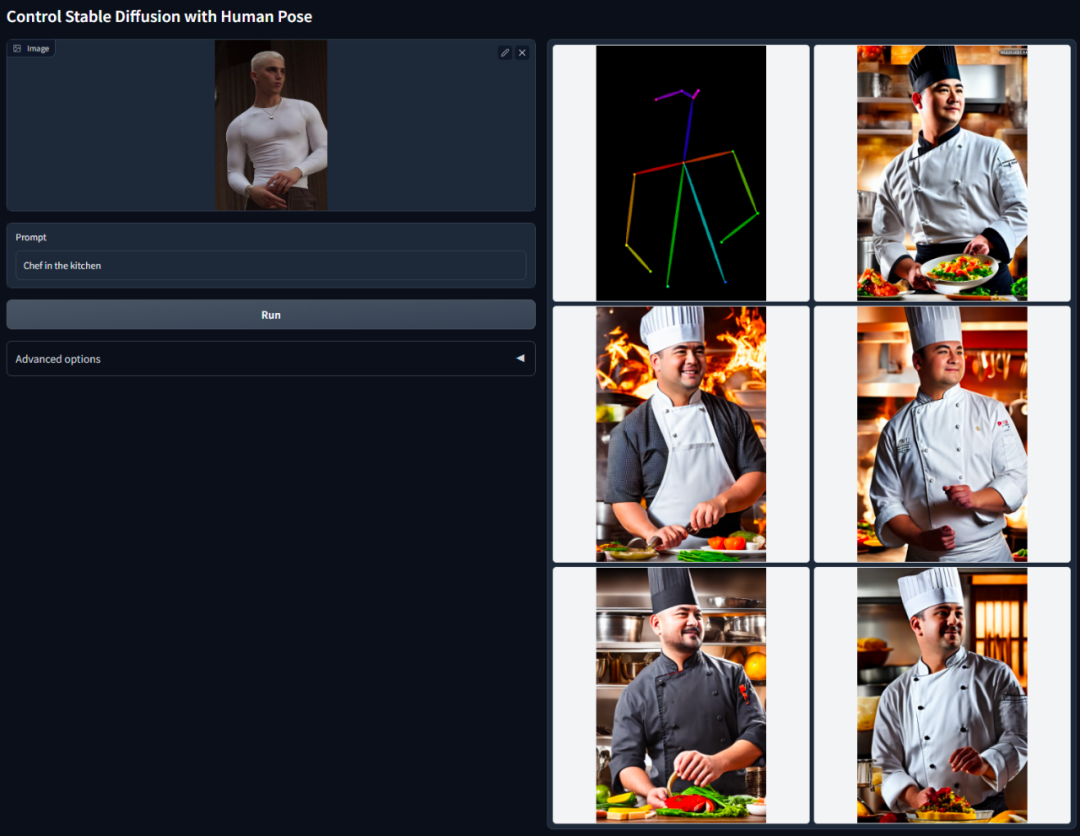
Idea teras ControlNet adalah untuk menambah beberapa syarat tambahan pada perihalan teks untuk mengawal model resapan (seperti Resapan Stabil), dengan itu mengawal pose watak, kedalaman, struktur gambar dan maklumat lain imej yang dihasilkan dengan lebih baik.
Syarat tambahan di sini ialah input dalam bentuk imej Model boleh melakukan pengesanan tepi Canny, pengesanan kedalaman, segmentasi semantik, pengesanan garis transformasi Hough, pengesanan tepi bersarang keseluruhan (HED) dan postur manusia berdasarkan ini. pengecaman input, dsb., dan kemudian simpan maklumat ini dalam imej yang dijana. Menggunakan model ini, kami boleh menukar terus lukisan garisan atau grafiti kepada imej berwarna penuh, menjana imej dengan struktur kedalaman yang sama, dsb., dan mengoptimumkan penjanaan tangan watak melalui mata kunci tangan.
Sila rujuk laporan "Pengurangan dimensi AI mencecah pelukis manusia, graf Vincentian diperkenalkan ke ControlNet, dan maklumat kedalaman dan tepi digunakan semula sepenuhnya" oleh Heart of the Machine untuk pengenalan yang lebih terperinci
Pada April tahun ini, Meta mengeluarkan model kecerdasan buatan yang dipanggil "Segment Everything (SAM)", yang boleh menjana topeng untuk objek dalam mana-mana imej atau video Ini telah membuat penyelidik dalam bidang komputer vision Saya sangat terkejut, malah ada yang berkata "Computer vision no longer exists"
Kini, kertas yang dinanti-nantikan ini telah dicalonkan untuk kertas terbaik.

Yang pertama ialah pembahagian interaktif, yang boleh digunakan untuk membahagikan mana-mana kelas objek tetapi memerlukan manusia untuk membimbing kaedah dengan menapis topeng secara berulang. Yang kedua ialah pembahagian automatik, yang boleh digunakan untuk membahagikan kategori objek khusus yang dipratentukan (seperti kucing atau kerusi), tetapi memerlukan sejumlah besar objek beranotasi secara manual untuk latihan (seperti beribu-ribu atau bahkan berpuluh-puluh ribu contoh kucing tersegmen) . Walau bagaimanapun, kedua-dua kaedah ini tidak menyediakan kaedah segmentasi universal dan automatik sepenuhnya
SAM yang dicadangkan oleh Meta meringkaskan kedua-dua kaedah ini dengan baik. Ia adalah model tunggal yang boleh melakukan pembahagian interaktif dan pembahagian automatik dengan mudah. Antara muka pantas model membolehkan pengguna menggunakannya dengan cara yang fleksibel, dengan hanya mereka bentuk gesaan yang betul untuk model (klik, pilihan kotak, teks, dll.), pelbagai tugas pembahagian boleh dicapai
Untuk meringkaskan , ciri ini Membolehkan SAM menyesuaikan diri dengan tugas dan medan baharu. Fleksibiliti ini unik dalam bidang pembahagian imej
Untuk butiran, sila rujuk laporan Jantung Mesin: "CV Tidak Wujud?" Meta mengeluarkan model AI "split everything", CV mungkin menyambut detik GPT-3》
Penyelidikan ini telah disiapkan bersama oleh penyelidik dari Cornell University, Google Research dan UC Berkeley , pengarang pertama ialah Qianqian Wang, pelajar kedoktoran dari Cornell Tech. Mereka bersama-sama mencadangkan OmniMotion, perwakilan gerakan yang lengkap dan konsisten di peringkat global, dan mencadangkan kaedah pengoptimuman masa ujian baharu untuk melaksanakan anggaran gerakan yang tepat dan lengkap bagi setiap piksel dalam video.

penglihatan komputer ,Terdapat dua kaedah anggaran gerakan yang biasa digunakan: ,penjejakan ciri jarang dan aliran optik padat. Walau bagaimanapun, kedua-dua kaedah mempunyai kekurangannya sendiri Penjejakan ciri jarang tidak boleh memodelkan pergerakan semua piksel padat aliran optik tidak dapat menangkap trajektori gerakan untuk masa yang lama.
🎜OmniMotion yang dicadangkan dalam penyelidikan ini menggunakan volum kanonik kuasi-3D untuk mewakili video dan menjejaki setiap piksel melalui bijection antara ruang tempatan dan ruang kanonik. Perwakilan ini membolehkan konsistensi global, membolehkan penjejakan gerakan walaupun objek tertutup, dan memodelkan sebarang gabungan gerakan kamera dan objek. Kajian ini secara eksperimen menunjukkan bahawa kaedah yang dicadangkan dengan ketara mengatasi kaedah SOTA sedia ada. 🎜🎜Sila rujuk laporan Heart of Machine "Algoritma video "menjejaki segala-galanya" yang menjejaki setiap piksel pada bila-bila masa, di mana-mana sahaja, dan tidak takut oklusi ada di sini" untuk pengenalan yang lebih terperinci
Selain anugerah ini- memenangi kertas kerja, ICCV tahun ini juga Terdapat banyak kertas cemerlang lain yang patut diberi perhatian anda. Di bawah ialah senarai awal 17 kertas pemenang

Atas ialah kandungan terperinci ICCV 2023 mengumumkan pemenang kertas popular seperti ControlNet dan 'Split Everything'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



