


Bagaimanakah model bahasa dipengaruhi oleh senarai kosa kata yang berbeza? Bagaimana untuk mengimbangi kesan ini?
Dalam percubaan baru-baru ini, penyelidik telah melatih dan memperhalusi 16 model bahasa dengan korpus yang berbeza. Percubaan ini menggunakan NanoGPT, seni bina berskala kecil (berdasarkan GPT-2 SMALL), dan melatih sejumlah 12 model. Konfigurasi seni bina rangkaian NanoGPT ialah: 12 kepala perhatian, 12 lapisan transformer, dimensi benam perkataan ialah 768, dan kira-kira 400,000 lelaran (kira-kira 10 zaman) telah dilakukan. Kemudian 4 model telah dilatih pada GPT-2 MEDIUM Seni bina GPT-2 MEDIUM telah ditetapkan kepada 16 kepala perhatian, 24 lapisan transformer, dimensi embedding perkataan ialah 1024, dan 600,000 lelaran telah dilakukan. Semua model telah dilatih terlebih dahulu menggunakan set data NanoGPT dan OpenWebText. Dari segi penalaan halus, para penyelidik menggunakan set data arahan yang disediakan oleh baize-chatbot dan menambah tambahan 20,000 dan 500,000 entri "kamus" masing-masing kepada kedua-dua jenis model
Pada masa hadapan, penyelidik merancang untuk mengeluarkan kod dan Model pra-latihan, model penalaan arahan dan set data penalaan halus
Walau bagaimanapun, disebabkan kekurangan penaja GPU (ini adalah projek sumber terbuka percuma), untuk mengurangkan kos, penyelidik tidak meneruskan teruskan, walaupun masih ada usaha untuk menambah baik lagi ruang kandungan penyelidikan. Dalam peringkat pra-latihan, 16 model ini perlu dijalankan pada 8 GPU selama 147 hari (satu GPU perlu digunakan selama 1,176 hari), dengan kos AS$8,000
Hasil penyelidikan boleh diringkaskan sebagai:
Mengikut keputusan eksperimen, keputusan englishcode-32000-consistent adalah yang terbaik. Walau bagaimanapun, seperti yang dinyatakan di atas, apabila menggunakan TokenMonster di mana satu token sepadan dengan berbilang perkataan, terdapat pertukaran antara ketepatan SMLQA (Ground Truth) dan nisbah perkataan, yang meningkatkan kecerunan lengkung pembelajaran. Para penyelidik yakin bahawa dengan memaksa 80% daripada token sepadan dengan satu perkataan dan 20% daripada token sepadan dengan berbilang perkataan, pertukaran ini boleh diminimumkan dan perbendaharaan kata "terbaik kedua-dua dunia" boleh dicapai. Para penyelidik percaya bahawa kaedah ini mempunyai prestasi yang sama seperti senarai kosa kata satu perkataan, sambil meningkatkan nisbah perkataan sebanyak kira-kira 50%.
Maksud ayat ini ialah kecacatan dan kerumitan dalam kata segmenter mempunyai kesan yang lebih besar terhadap keupayaan model untuk mempelajari fakta berbanding keupayaan bahasanya
Fenomena ini merupakan penemuan yang menarik semasa proses latihan. masuk akal untuk memikirkan cara latihan model berfungsi. Pengkaji tidak mempunyai bukti untuk membenarkan alasannya. Tetapi pada asasnya, kerana kefasihan bahasa lebih mudah untuk diperbetulkan semasa penyebaran balik daripada fakta bahasa (yang sangat halus dan bergantung konteks), ini bermakna bahawa sebarang peningkatan dalam kecekapan tokenizer akan menjadi kurang konsisten daripada fakta bahasa Tanpa mengira jantina , akan terdapat kesan riak yang secara langsung diterjemahkan kepada kesetiaan maklumat yang dipertingkatkan, seperti yang dilihat dalam penanda aras SMLQA (Ground Truth). Ringkasnya: tokenizer yang lebih baik ialah model yang lebih realistik, tetapi tidak semestinya model yang lebih lancar. Sebaliknya: model dengan tokenizer yang tidak cekap masih boleh belajar menulis dengan lancar, tetapi kos tambahan kelancaran mengurangkan kredibiliti model.
Sebelum menjalankan ujian ini, penyelidik percaya bahawa 32000 adalah saiz perbendaharaan kata yang optimum, dan keputusan eksperimen juga mengesahkan ini. Prestasi model seimbang 50256 hanya 1% lebih baik daripada model seimbang 32000 pada penanda aras SMLQA (Ground Truth), tetapi saiz model meningkat sebanyak 13%. Untuk membuktikan dengan jelas sudut pandangan ini, dalam pelbagai model berdasarkan MEDIUM, artikel ini menjalankan eksperimen dengan membahagikan perbendaharaan kata kepada 24000, 32000, 50256 dan 100256 perkataan
Para penyelidik menguji TokenMonster dan menguji tiga mod pengoptimuman khusus: seimbang, konsisten dan ketat. Mod pengoptimuman yang berbeza akan mempengaruhi cara tanda baca dan kod huruf besar digabungkan dengan token perkataan. Para penyelidik pada mulanya meramalkan bahawa mod konsisten akan berprestasi lebih baik (kerana ia kurang kompleks), walaupun nisbah perkataan (iaitu, nisbah aksara kepada token) akan lebih rendah sedikit
Hasil eksperimen seolah-olah mengesahkan sangkaan di atas , tetapi penyelidik juga memerhati Terdapat beberapa fenomena. Pertama, mod konsisten nampaknya berprestasi kira-kira 5% lebih baik daripada mod seimbang pada penanda aras SMLQA (Ground Truth). Walau bagaimanapun, mod konsisten menunjukkan prestasi yang lebih teruk (28%) pada penanda aras SQuAD (Pengekstrakan Data). Walau bagaimanapun, penanda aras SQuAD mempamerkan ketidakpastian yang besar (larian berulang memberikan hasil yang berbeza) dan tidak meyakinkan. Para penyelidik tidak menguji penumpuan antara seimbang dan konsisten, jadi ini mungkin bermakna corak konsisten lebih mudah dipelajari. Malah, konsisten mungkin melakukan lebih baik pada SQuAD (pengekstrakan data) kerana SQuAD lebih sukar untuk dipelajari dan kurang berkemungkinan menghasilkan halusinasi.
Ini adalah penemuan yang menarik, kerana ini bermakna tiada masalah yang jelas dengan menggabungkan tanda baca dan perkataan menjadi satu token. Setakat ini, semua tokenizer lain berhujah bahawa tanda baca harus dipisahkan daripada huruf, tetapi seperti yang anda boleh lihat daripada keputusan di sini, perkataan dan tanda baca boleh digabungkan menjadi satu token tanpa kehilangan prestasi yang ketara. Ini juga disahkan oleh 50256-consistent-oneword, gabungan yang berprestasi setanding dengan 50256-strict-oneword-nocapcode dan mengatasi p50k_base. 50256-consistent-oneword menggabungkan tanda baca mudah dengan perkataan token (yang mana dua gabungan lain tidak).
Selepas mendayakan mod ketat kod cap, ia akan mempunyai kesan negatif yang jelas. Pada SMLQA, skor 50256-strict-oneword-nocapcode 21.2 dan pada SQuAD skor 23.8, manakala skor 50256-strict-oneword masing-masing 16.8 dan 20.0. Alasannya adalah jelas: mod pengoptimuman yang ketat menghalang penggabungan kod cap dan token perkataan, menyebabkan lebih banyak token diperlukan untuk mewakili teks yang sama, mengakibatkan pengurangan 8% dalam nisbah perkataan. Malah, strict-nocapcode lebih serupa dengan konsisten daripada mod ketat. Dalam pelbagai penunjuk, 50256-consistent-oneword dan 50256-strict-oneword-nocapcode hampir sama
Dalam kebanyakan kes, penyelidik membuat kesimpulan bahawa model ini berguna untuk mempelajari makna token yang mengandungi tanda baca dan perkataan Tidak terlalu sukar . Iaitu, model ketekalan mempunyai ketepatan tatabahasa yang lebih tinggi dan ralat tatabahasa yang lebih sedikit daripada model seimbang. Dengan mengambil kira semua perkara, penyelidik mengesyorkan agar semua orang menggunakan mod konsisten. Mod ketat hanya boleh digunakan dengan capcode dilumpuhkan
Seperti yang dinyatakan di atas, mod konsisten mempunyai ketepatan sintaks yang lebih tinggi (kurang ralat sintaks) daripada mod seimbang ). Ini ditunjukkan dalam korelasi negatif yang sangat sedikit antara nisbah perkataan dan tatabahasa, seperti yang ditunjukkan dalam rajah di bawah. Selain itu, perkara yang paling penting ialah hasil sintaks untuk tokenizer GPT-2 dan tiktoken p50k_base adalah mengerikan (masing-masing) berbanding dengan 50256-strict-oneword-nocapcode (98.6% dan 98.4%) dan 97.5% TokenMonster. . Para penyelidik pada mulanya menyangka ia hanya kebetulan, tetapi beberapa persampelan menghasilkan julat keputusan yang sama. Tidak jelas apa puncanya.
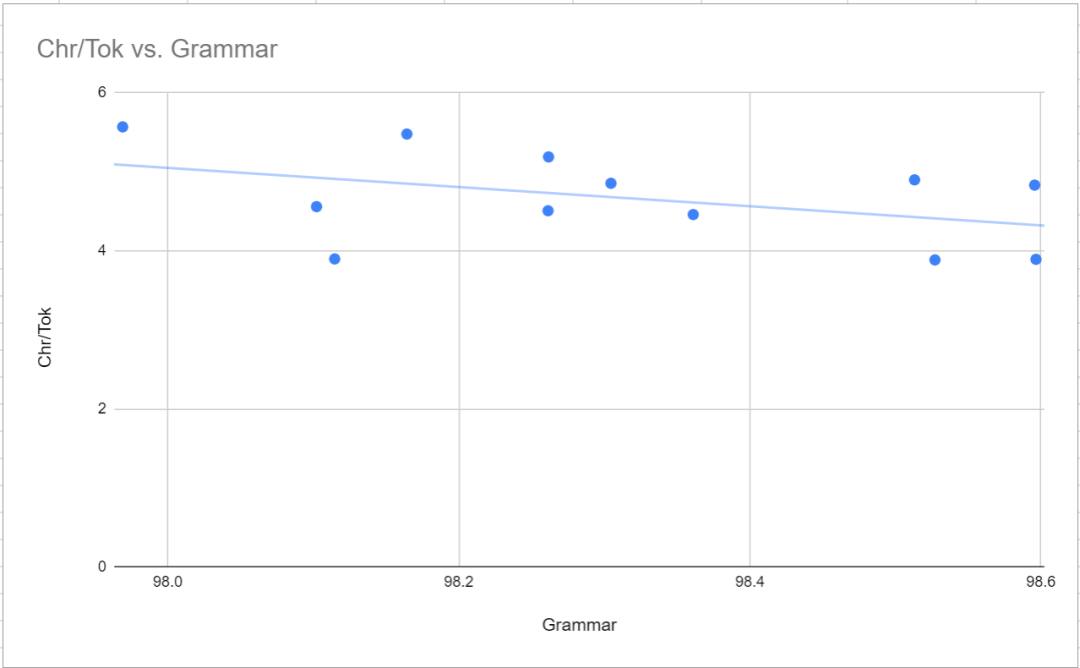
MTLD digunakan untuk mewakili kepelbagaian linguistik teks sampel yang dijana. Ia nampaknya berkait rapat dengan parameter n_embed dan bukan dengan ciri seperti saiz perbendaharaan kata, mod pengoptimuman atau bilangan maksimum perkataan bagi setiap token. Ini amat ketara dalam model 6000-seimbang (n_embd ialah 864) dan model 8000-konsisten (n_embd ialah 900)
Antara model sederhana, p50k_base mempunyai MTLD tertinggi pada 43.85, tetapi syntax juga mempunyai skor terendah. . Sebab untuk ini tidak jelas, tetapi para penyelidik membuat spekulasi bahawa pemilihan data latihan mungkin agak pelik.
Tujuan penanda aras SQuAD adalah untuk menilai keupayaan model untuk mengekstrak data daripada sekeping teks. Kaedah khusus adalah untuk menyediakan perenggan teks dan bertanya soalan, memerlukan jawapan mesti ditemui dalam perenggan teks. Keputusan ujian tidak begitu bermakna, tiada corak atau korelasi yang jelas, dan ia tidak dipengaruhi oleh parameter keseluruhan model. Malah, model 8000-seimbang dengan 91 juta parameter mendapat markah lebih tinggi dalam SQuAD berbanding model 50256-konsisten-satu perkataan dengan 354 juta parameter. Sebabnya mungkin kerana contoh gaya ini tidak mencukupi atau terdapat terlalu banyak pasangan soalan-jawapan dalam set data penalaan halus. Atau mungkin ini hanyalah penanda aras yang kurang ideal
Penanda aras SMLQA menguji "nilai kebenaran" dengan bertanya soalan akal dengan jawapan objektif, seperti "Ibu negara Jakarta yang mana?" dan "Siapa yang menulis buku Harry Potter?"
Perlu diperhatikan bahawa dalam ujian penanda aras ini, kedua-dua tokenizer rujukan, GPT-2 Tokenizer dan p50k_base, menunjukkan prestasi yang sangat baik. Para penyelidik pada mulanya menyangka mereka telah membuang masa berbulan-bulan dan beribu-ribu dolar, tetapi ternyata tiktoken berprestasi lebih baik daripada TokenMonster. Walau bagaimanapun, ternyata masalah itu berkaitan dengan bilangan perkataan yang sepadan dengan setiap token. Ini amat jelas dalam model "Sederhana" (SEDERHANA), seperti yang ditunjukkan dalam rajah di bawah
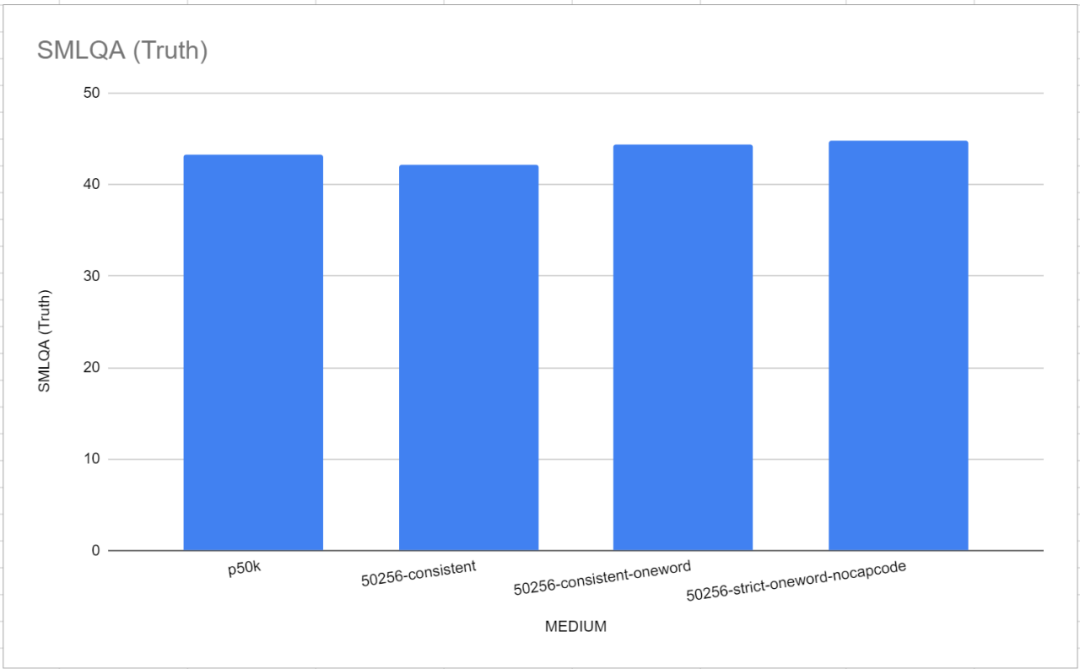
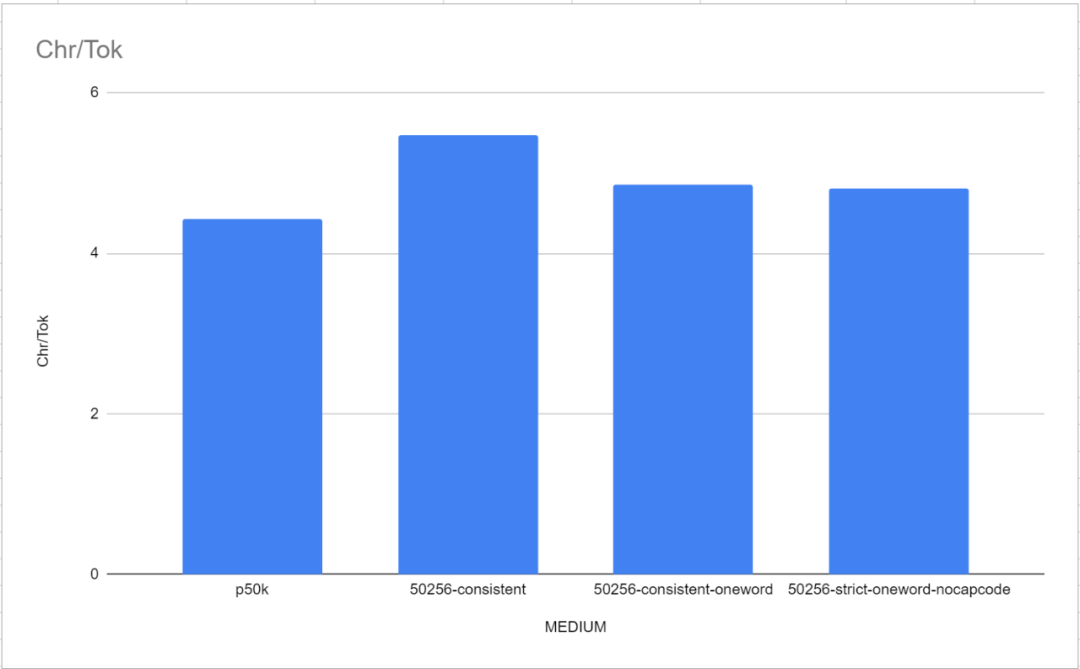 Prestasi perbendaharaan kata satu perkataan adalah lebih baik sedikit daripada lalai TokenMonster setiap token sepadan dengan berbilang senarai kosa kata perkataan.
Prestasi perbendaharaan kata satu perkataan adalah lebih baik sedikit daripada lalai TokenMonster setiap token sepadan dengan berbilang senarai kosa kata perkataan.
Satu lagi pemerhatian penting ialah apabila saiz perbendaharaan kata di bawah 32,000, saiz perbendaharaan kata akan secara langsung mempengaruhi nilai sebenar, walaupun jika parameter n_embd model dilaraskan untuk mengimbangi pengurangan saiz model. Ini berlawanan dengan intuitif kerana penyelidik pada asalnya berpendapat bahawa 16000-seimbang dengan n_embd 864 (parameter 121.34 juta) dan 8000-konsisten dengan n_embd 900 (parameter 123.86 juta) akan lebih baik daripada 50256-embd daripada 7 meter 121,34 juta). Walau bagaimanapun, kedua-dua model "dilaraskan" menerima masa latihan yang sama, yang mengakibatkan masa pra-latihan yang jauh lebih sedikit (walaupun masa yang sama)
Para penyelidik melatih 12 model pada seni bina NanoGPT lalai. Seni bina adalah berdasarkan seni bina GPT-2 dengan 12 kepala perhatian dan 12 lapisan, dan saiz parameter pembenaman ialah 768. Tiada satu pun daripada model ini telah mencapai keadaan penumpuan Secara ringkasnya, mereka tidak mencapai keupayaan pembelajaran maksimum mereka. Model ini telah dilatih untuk 400,000 lelaran, tetapi nampaknya 600,000 lelaran diperlukan untuk mencapai keupayaan pembelajaran maksimum. Sebab untuk situasi ini adalah mudah, satu masalah belanjawan, dan satu lagi adalah ketidakpastian titik penumpuan
Hasil model kecil:
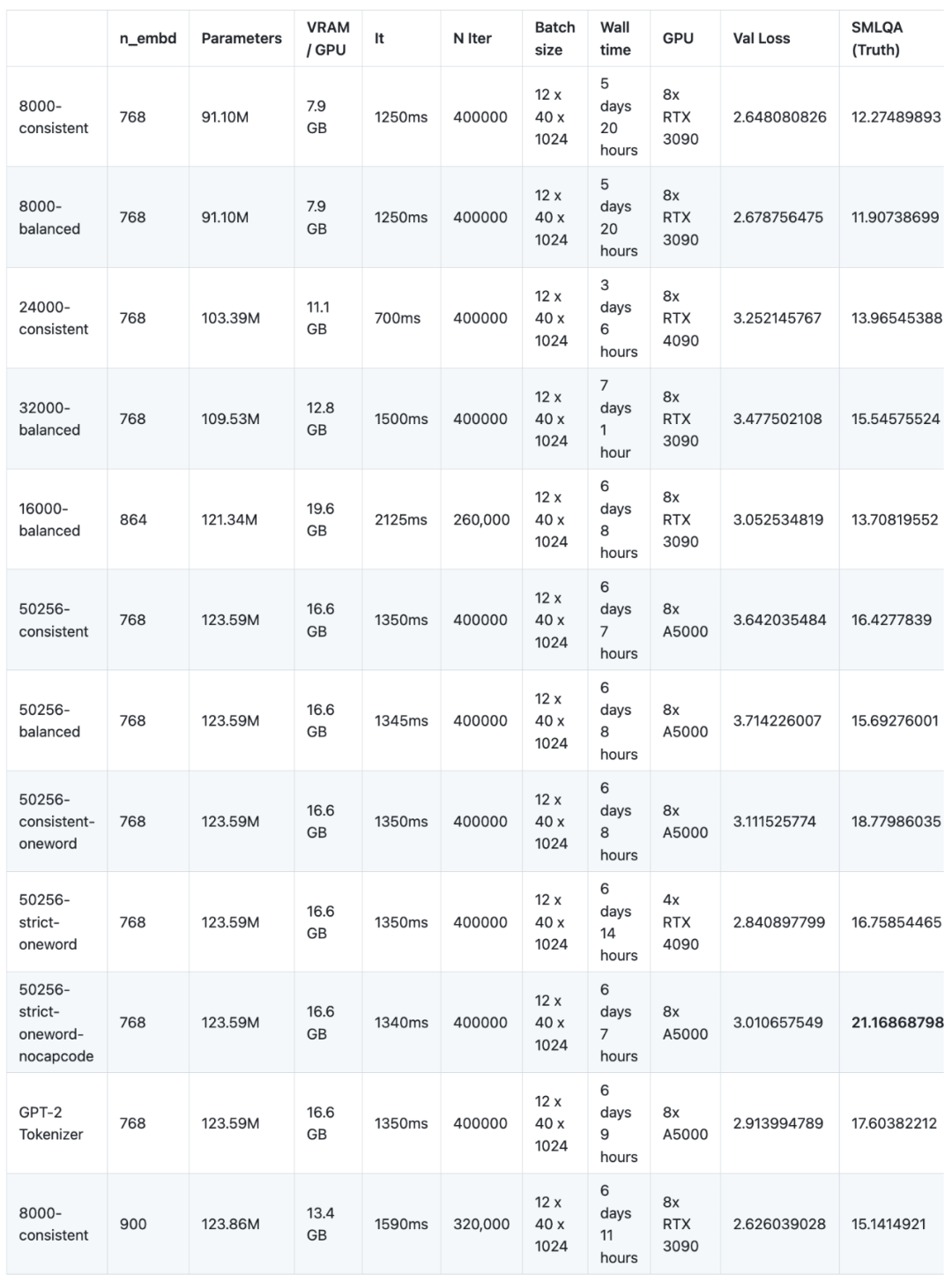
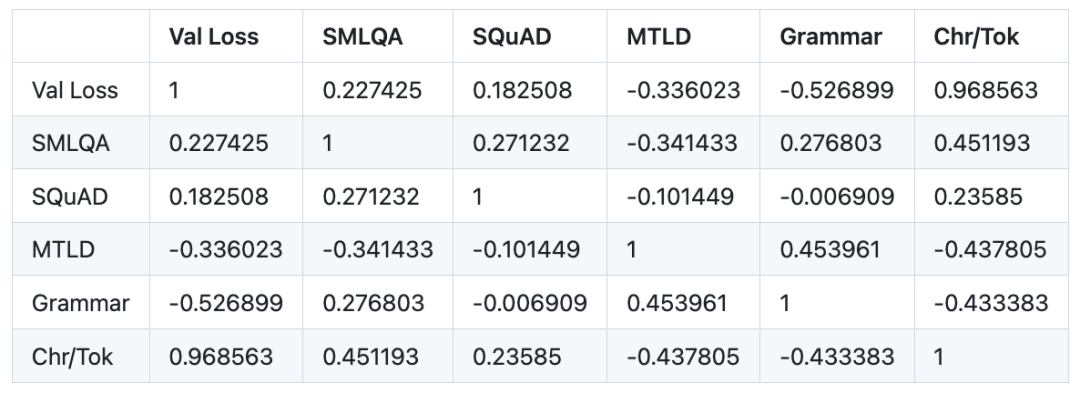
Korelasi Pearson model kecil:
Kesimpulan model kecil:
Isi yang ditulis semula: Tahap perbendaharaan kata yang optimum dicapai apabila saiz kosa kata adalah 32,000. Dalam peringkat perbendaharaan kata meningkat daripada 8,000 kepada 32,000, meningkatkan perbendaharaan kata meningkatkan ketepatan model. Walau bagaimanapun, apabila saiz perbendaharaan kata meningkat daripada 32,000 kepada 50,257, jumlah parameter model juga meningkat dengan sewajarnya, tetapi peningkatan ketepatan hanya 1%. Selepas melebihi 32,000, keuntungan menurun dengan cepat
Reka bentuk tokenizer yang lemah akan memberi kesan pada ketepatan model, tetapi bukan pada ketepatan tatabahasa atau kepelbagaian bahasa. Prestasi pada penanda aras ground-truth untuk tokenizer dengan peraturan tatabahasa yang lebih kompleks (seperti token yang sepadan dengan berbilang perkataan, gabungan perkataan dan tanda baca, token pengekodan kod huruf besar dan jumlah pengurangan kosa kata) dalam julat parameter 90 juta hingga 125 juta Lemah. Walau bagaimanapun, reka bentuk tokenizer yang canggih ini tidak mempunyai kesan yang signifikan secara statistik terhadap kepelbagaian linguistik atau ketepatan tatabahasa teks yang dihasilkan. Malah model padat, seperti model dengan 90 juta parameter, boleh mengeksploitasi penanda yang lebih kompleks dengan berkesan. Perbendaharaan kata yang lebih kompleks mengambil masa yang lebih lama untuk dipelajari, mengurangkan masa yang diperlukan untuk memperoleh maklumat yang berkaitan dengan fakta asas. Memandangkan tiada model ini telah dilatih sepenuhnya, potensi untuk latihan lanjutan untuk menutup jurang prestasi masih dapat dilihat
Ditulis semula dalam bahasa Cina: 3. Kehilangan pengesahan bukan metrik yang sah untuk membandingkan model menggunakan tokenizer yang berbeza. Kehilangan pengesahan mempunyai korelasi yang sangat kuat (0.97 korelasi Pearson) dengan nisbah perkataan (bilangan purata aksara setiap token) untuk tokenizer yang diberikan. Untuk membandingkan nilai kerugian antara tokenizer, mungkin lebih berkesan untuk mengukur kerugian berbanding aksara berbanding token, kerana nilai kerugian adalah berkadar dengan purata bilangan aksara yang sepadan dengan setiap token
4 tidak sesuai sebagai Metrik penilaian untuk model bahasa kerana model bahasa ini dilatih untuk menjana respons panjang berubah-ubah (penyiapan ditunjukkan oleh penanda akhir teks). Ini kerana semakin panjang urutan teks, semakin berat penalti formula F1. Markah F1 cenderung menghasilkan model tindak balas yang lebih pendek
Semua model (bermula dari parameter 90M) serta semua tokenizer yang diuji (bersaiz antara 8000 hingga 50257) menunjukkan bahawa mereka boleh menghasilkan koheren tatabahasa Keupayaan untuk menjawab. Walaupun jawapan ini selalunya tidak betul atau ilusi, semuanya agak koheren dan menunjukkan pemahaman tentang latar belakang kontekstual
Kepelbagaian leksikal dan ketepatan tatabahasa teks yang dijana meningkat dengan ketara apabila saiz benam meningkat dan mempunyai korelasi negatif sedikit dengan perkataan nisbah. Ini bermakna perbendaharaan kata dengan nisbah perkataan-ke-perkataan yang lebih besar akan menjadikan pembelajaran kepelbagaian tatabahasa dan leksikal lebih sukar sedikit
7 Apabila melaraskan saiz parameter model, nisbah perkataan-ke-perkataan adalah berkaitan dengan SMLQA (Ground Kebenaran) atau SQuAD (Pengekstrakan Maklumat) ) Tiada korelasi yang signifikan secara statistik antara penanda aras. Ini bermakna bahawa tokenizer dengan nisbah perkataan-ke-perkataan yang lebih tinggi tidak akan memberi kesan negatif kepada prestasi model.
Berbanding dengan yang "seimbang", kategori "konsisten" nampaknya menunjukkan prestasi yang lebih baik sedikit pada penanda aras SMLQA (Ground Truth), tetapi jauh lebih teruk pada penanda aras SQuAD (Pengekstrakan Maklumat). Walaupun lebih banyak data diperlukan untuk mengesahkan perkara ini
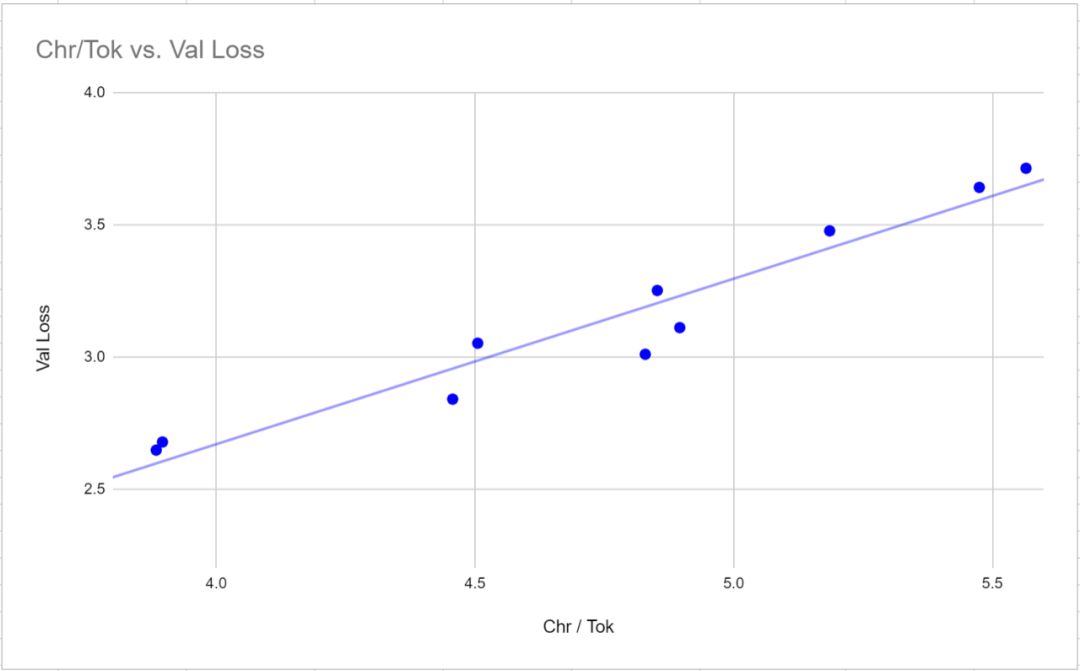
Selepas latihan dan menanda aras model kecil itu mendapati bahawa penyelidik telah mengkaji dengan jelas, keputusan yang diukur mencerminkan kelajuan pembelajaran model dan bukannya keupayaan pembelajaran model. Di samping itu, penyelidik tidak mengoptimumkan potensi pengkomputeran GPU kerana parameter NanoGPT lalai telah digunakan. Untuk menyelesaikan masalah ini, penyelidik memilih untuk menggunakan tokenizer dengan 50257 token dan model bahasa sederhana untuk mengkaji empat varian. Para penyelidik melaraskan saiz kelompok daripada 12 kepada 36 dan mengurangkan saiz blok daripada 1024 kepada 256 untuk memastikan penggunaan sepenuhnya keupayaan VRAM GPU 24GB. Kemudian 600,000 lelaran dilakukan dan bukannya 400,000 seperti dalam model yang lebih kecil. Pralatihan untuk setiap model mengambil masa purata lebih daripada 18 hari, tiga kali ganda daripada 6 hari yang diperlukan untuk model yang lebih kecil.
Melatih model kepada penumpuan mengurangkan dengan ketara perbezaan prestasi antara perbendaharaan kata yang lebih mudah dan lebih kompleks. Keputusan penanda aras SMLQA (Ground Truth) dan SQuAD (Data Extraction) adalah sangat hampir. Perbezaan utama ialah 50256-konsisten mempunyai kelebihan nisbah perkataan 23.5% lebih tinggi daripada p50k_base. Walau bagaimanapun, untuk perbendaharaan kata dengan berbilang perkataan setiap token, kos prestasi nilai kebenaran adalah lebih kecil, tetapi ini boleh diselesaikan menggunakan kaedah yang saya bincangkan di bahagian atas halaman. Keputusan model dalam
:
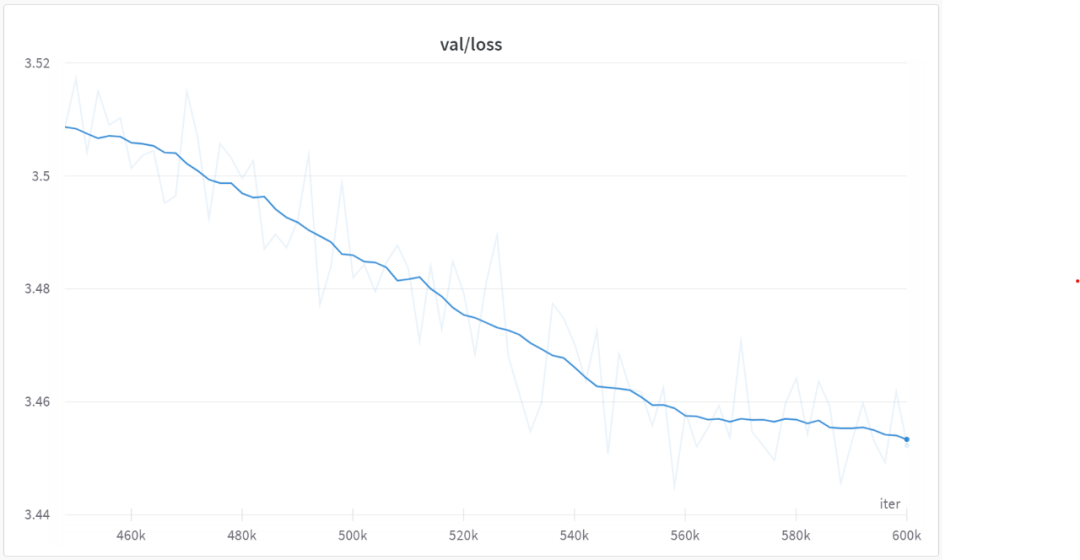
Selepas 560000 lelaran, semua model mula menumpu, seperti yang ditunjukkan dalam rajah di bawah:
Di peringkat seterusnya, kami akan menggunakan englishcode-32000-consistent untuk melatih dan menanda aras model MEDIUM. Kosa kata ini mempunyai 80% token perkataan dan 20% token berbilang perkataan
Atas ialah kandungan terperinci Meneroka kesan pemilihan perbendaharaan kata pada latihan model bahasa: Satu kajian terobosan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pengenalan kepada maksud tetingkap muat turun awan
Pengenalan kepada maksud tetingkap muat turun awan
 Penyelesaian kepada penetapan vscode antara muka Cina tidak berkuat kuasa
Penyelesaian kepada penetapan vscode antara muka Cina tidak berkuat kuasa
 Bagaimana untuk menutup port 135 445
Bagaimana untuk menutup port 135 445
 Mengapakah pemacu keras mudah alih begitu lambat dibuka?
Mengapakah pemacu keras mudah alih begitu lambat dibuka?
 Bagaimana untuk menggunakan split dalam python
Bagaimana untuk menggunakan split dalam python
 skrin telefon bimbit tft
skrin telefon bimbit tft
 Bagaimana untuk mengubah saiz gambar dalam ps
Bagaimana untuk mengubah saiz gambar dalam ps
 0x80070057 penyelesaian ralat parameter
0x80070057 penyelesaian ralat parameter








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



