


Penemuan yang mengejutkan: Model besar mempunyai kelemahan yang serius dalam potongan pengetahuan.
Kandungan yang perlu ditulis semula ialah: Rajah 1: GPT/4 muncul pada pengetahuan perbandingan Salah, tetapi anda boleh mendapatkan jawapan yang betul melalui rantaian pemikiran
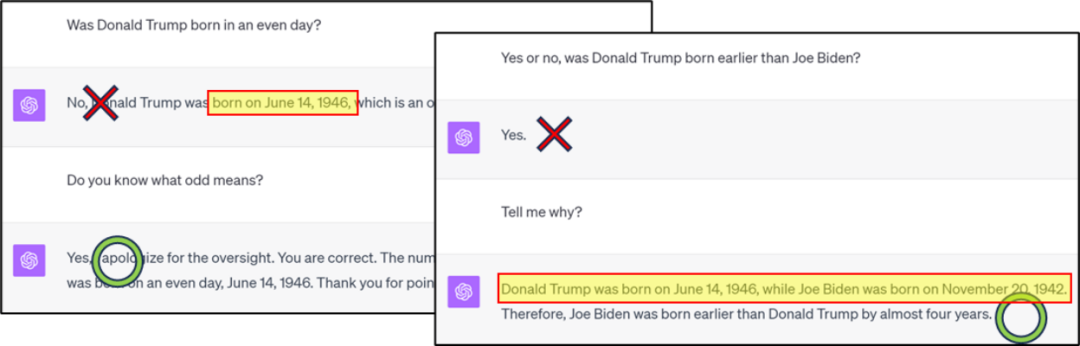
#🎜🎜🎜 #Perlu ditulis semula Kandungannya ialah: Rajah 2: Contoh ralat carian terbalik pengetahuan GPT4 : Walaupun GPT4 boleh menjawab dengan betul "Bilakah hari lahir seseorang dan "Adakah nombor tertentu adalah nombor genap?", apabila menggabungkan kedua-duanya, nombor itu ketepatan hanya 50% tanpa Rantaian Pemikiran (CoT). Apabila membandingkan hari lahir selebriti dari 1900-1910, persembahan itu juga hampir dengan tekaan buta. Penyelidikan terbaru oleh Zhu Zeyuan (MetaAI) dan Li Yuanzhi (MBZUAI) " Fizik Model Bahasa Bahagian 3.2: Potongan Pengetahuan (Manipulasi)" memfokuskan kepada isu di atas.
Sila klik pautan berikut untuk melihat kertas: https://arxiv.org/abs/2309.14402 #🎜🎜 soalan pertama, masalah seperti Rajah 1/2/3, adakah ingatan GPT4 tentang hari lahir orang tidak cukup tepat (nisbah mampatan tidak mencukupi, kehilangan latihan tidak cukup rendah), atau adakah ia tidak mendalami pemahamannya pariti melalui penalaan halus? Adakah mungkin untuk memperhalusi GPT4 supaya ia boleh menggabungkan pengetahuan sedia ada dalam model untuk menjana pengetahuan baharu seperti "pariti hari jadi" dan terus menjawab soalan berkaitan tanpa bergantung pada CoT? Memandangkan kami tidak mengetahui set data latihan GPT4, penalaan halus tidak boleh dilakukan. Oleh itu, penulis mencadangkan untuk menggunakan set latihan yang boleh dikawal untuk mengkaji lebih lanjut keupayaan "pengurangan pengetahuan" model bahasa. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 #Rajah 4: Model pra-latihan seperti GPT4, kerana data Internet yang tidak terkawal, sukar untuk menjadi data Internet. sukar menjadi sukar Tentukan sama ada situasi B/C/D berlaku Satu set data biografi peribadi. Setiap biografi termasuk nama orang itu serta enam sifat: tarikh lahir, tempat lahir, jurusan kolej, nama kolej, tempat bekerja dan tempat kerja. Contohnya:
#🎜🎜 soalan pertama, masalah seperti Rajah 1/2/3, adakah ingatan GPT4 tentang hari lahir orang tidak cukup tepat (nisbah mampatan tidak mencukupi, kehilangan latihan tidak cukup rendah), atau adakah ia tidak mendalami pemahamannya pariti melalui penalaan halus? Adakah mungkin untuk memperhalusi GPT4 supaya ia boleh menggabungkan pengetahuan sedia ada dalam model untuk menjana pengetahuan baharu seperti "pariti hari jadi" dan terus menjawab soalan berkaitan tanpa bergantung pada CoT? Memandangkan kami tidak mengetahui set data latihan GPT4, penalaan halus tidak boleh dilakukan. Oleh itu, penulis mencadangkan untuk menggunakan set latihan yang boleh dikawal untuk mengkaji lebih lanjut keupayaan "pengurangan pengetahuan" model bahasa. #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 #Rajah 4: Model pra-latihan seperti GPT4, kerana data Internet yang tidak terkawal, sukar untuk menjadi data Internet. sukar menjadi sukar Tentukan sama ada situasi B/C/D berlaku Satu set data biografi peribadi. Setiap biografi termasuk nama orang itu serta enam sifat: tarikh lahir, tempat lahir, jurusan kolej, nama kolej, tempat bekerja dan tempat kerja. Contohnya:
 walaupun ia hanyalah transformasi/gabungan mudah pengetahuan yang telah dikuasai oleh model.
walaupun ia hanyalah transformasi/gabungan mudah pengetahuan yang telah dikuasai oleh model. . eksperimen
Sebagai contoh Rajah 5, penulis mendapati bahawa walaupun model itu boleh menjawab dengan tepat hari lahir setiap orang selepas pralatihan (kadar ketepatan hampir 100%), ia perlu diperhalusi untuk menjawab "Adakah bulan kelahiran xxx adalah nombor genap?" dan mencapai ketepatan 75 % - jangan lupa tekaan buta mempunyai kadar ketepatan 50% - memerlukan sekurang-kurangnya 10,000 sampel penalaan halus. Sebagai perbandingan, jika model boleh melengkapkan gabungan pengetahuan "hari jadi" dan "pariti" dengan betul, maka menurut teori pembelajaran mesin tradisional, model hanya perlu belajar untuk mengklasifikasikan 12 bulan, dan biasanya kira-kira 100 sampel sudah mencukupi! Begitu juga, walaupun model telah dilatih terlebih dahulu, ia boleh menjawab dengan tepat jurusan semua orang (sebanyak 100 jurusan berbeza), tetapi walaupun menggunakan 50,000 sampel penalaan halus, biarkan model membandingkan "Mana satu yang lebih baik, jurusan Anya atau Sabrina's major" ", kadar ketepatan hanya 53.9%, yang hampir bersamaan dengan meneka Walau bagaimanapun, apabila kita menggunakan model penalaan halus CoT untuk mempelajari ayat "Bulan kelahiran Anya ialah Oktober, jadi ia adalah nombor genap". model menentukan bulan kelahiran pada set ujian Ketepatan pariti bulanan bertambah baik dengan ketara (lihat lajur "CoT untuk ujian" dalam Rajah 5) Pengarang juga cuba mencampurkan jawapan CoT dan bukan CoT dalam latihan penalaan halus. data, dan mendapati model menunjukkan prestasi yang lebih baik pada set ujian apabila tidak menggunakan CoT Kadar ketepatan masih sangat rendah (lihat lajur "ujian tanpa CoT" dalam Rajah 5). Ini menunjukkan bahawa walaupun data penalaan halus CoT yang mencukupi ditambah, model masih tidak boleh belajar untuk "berfikir di dalam kepala" dan terus melaporkan jawapannya
Hasil ini menunjukkan bahawa
Untuk model bahasa, amat sukar untuk melaksanakan pengetahuan mudah operasi! Model itu mesti menulis titik pengetahuan dan kemudian melakukan pengiraan Ia tidak boleh dikendalikan secara langsung dalam otak seperti manusia Walaupun selepas penalaan yang mencukupi, ia tidak akan membantu. Cabaran dalam Pencarian Pengetahuan SongsangPenyelidikan juga mendapati model bahasa semula jadi tidak boleh menggunakan pengetahuan yang dipelajari melalui carian terbalik. Walaupun ia boleh menjawab semua maklumat tentang seseorang, ia tidak dapat menentukan nama orang itu berdasarkan maklumat ini Pengarang bereksperimen dengan GPT3.5/4 dan mendapati mereka berprestasi lemah dalam pengekstrakan pengetahuan terbalik (lihat Rajah 6). Walau bagaimanapun, kerana kami tidak dapat menentukan set data latihan GPT3.5/4, ini tidak membuktikan bahawa semua model bahasa mempunyai masalah ini
Rajah 6: Perbandingan carian pengetahuan hadapan/balik dalam GPT3.5/ 4 . Kerja "Kutukan Terbalik" kami yang dilaporkan sebelum ini (arxiv 2309.12288) juga memerhati fenomena ini pada model besar sedia ada
 Pengarang menggunakan set data biografi yang disebutkan di atas untuk menjalankan kajian yang lebih mendalam tentang ujian terkawal keupayaan carian pengetahuan terbalik model. Memandangkan nama semua biografi berada di awal perenggan, penulis mereka 10 soalan pengekstrakan maklumat terbalik, seperti:
Pengarang menggunakan set data biografi yang disebutkan di atas untuk menjalankan kajian yang lebih mendalam tentang ujian terkawal keupayaan carian pengetahuan terbalik model. Memandangkan nama semua biografi berada di awal perenggan, penulis mereka 10 soalan pengekstrakan maklumat terbalik, seperti: Adakah anda tahu nama orang yang dilahirkan di Princeton, New Jersey pada 2 Oktober 1996? "Sila beritahu saya nama orang yang belajar Komunikasi di MIT, dilahirkan pada 2 Oktober 1996 di Princeton, NJ, dan bekerja di Meta Platforms di Menlo Park, CA?"
Perlu teruskan Kandungan yang ditulis semula ialah: Rajah 7: Percubaan terkawal pada set data biografi selebriti Pengarang mengesahkan bahawa walaupun model itu mencapai pemampatan pengetahuan tanpa kerugian dan peningkatan pengetahuan yang mencukupi, dan boleh mengekstrak pengetahuan ini hampir 100% dengan betul, dalam After fine -penalaan, model masih tidak dapat melakukan carian terbalik pengetahuan, dan ketepatannya hampir sifar (lihat Rajah 7). Walau bagaimanapun, sebaik sahaja pengetahuan songsang muncul terus dalam set pra-latihan, ketepatan carian terbalik serta-merta melonjak.
Pengarang mengesahkan bahawa walaupun model itu mencapai pemampatan pengetahuan tanpa kerugian dan peningkatan pengetahuan yang mencukupi, dan boleh mengekstrak pengetahuan ini hampir 100% dengan betul, dalam After fine -penalaan, model masih tidak dapat melakukan carian terbalik pengetahuan, dan ketepatannya hampir sifar (lihat Rajah 7). Walau bagaimanapun, sebaik sahaja pengetahuan songsang muncul terus dalam set pra-latihan, ketepatan carian terbalik serta-merta melonjak. Ringkasnya, hanya apabila pengetahuan songsang dimasukkan secara langsung dalam data pralatihan, model boleh menjawab soalan songsang melalui penalaan halus - tetapi ini sebenarnya menipu, kerana jika pengetahuan itu telah terbalik, ia tidak akan " carian ilmu terbalik” lagi. Jika set pra-latihan hanya mengandungi pengetahuan ke hadapan, model tidak dapat menguasai kebolehan menjawab soalan secara terbalik melalui penalaan halus. Oleh itu, menggunakan model bahasa untuk pengindeksan pengetahuan (pangkalan data pengetahuan) pada masa ini kelihatan mustahil. Selain itu, sesetengah orang mungkin berpendapat bahawa "carian pengetahuan terbalik" di atas gagal kerana model bahasa autoregresif (seperti GPT) adalah sehala. Walau bagaimanapun, pada hakikatnya, model bahasa dua hala (seperti BERT) menunjukkan prestasi yang lebih teruk pada pengekstrakan pengetahuan malah gagal pada pengekstrakan hadapan. Bagi pembaca yang berminat, boleh rujuk maklumat terperinci dalam kertas
Atas ialah kandungan terperinci Model bahasa mempunyai kelemahan utama, dan pengurangan pengetahuan ternyata menjadi masalah yang telah lama wujud. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penjelasan terperinci arahan nohup
Penjelasan terperinci arahan nohup
 Bagaimana untuk membeli dan menjual Bitcoin di okex
Bagaimana untuk membeli dan menjual Bitcoin di okex
 Sebab mengapa phpstudy tidak boleh dibuka
Sebab mengapa phpstudy tidak boleh dibuka
 Penggunaan fungsi urlencode
Penggunaan fungsi urlencode
 Berapakah nilai Dimensity 9000 bersamaan dengan Snapdragon?
Berapakah nilai Dimensity 9000 bersamaan dengan Snapdragon?
 Cara menyediakan Douyin untuk menghalang semua orang daripada melihat hasil kerja
Cara menyediakan Douyin untuk menghalang semua orang daripada melihat hasil kerja
 sql dalam penggunaan operator
sql dalam penggunaan operator
 Apakah saiz kertas a5
Apakah saiz kertas a5








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



