Model bahasa berskala besar telah menunjukkan keupayaan penaakulan yang mengejutkan dalam pemprosesan bahasa semula jadi, tetapi mekanisme asasnya masih belum jelas. Dengan aplikasi meluas model bahasa berskala besar, menjelaskan mekanisme pengendalian model adalah penting untuk keselamatan aplikasi, had prestasi dan impak sosial yang boleh dikawal. Baru-baru ini, banyak institusi penyelidikan di China dan Amerika Syarikat (Institut Teknologi New Jersey, Universiti Johns Hopkins, Universiti Wake Forest, Universiti Georgia, Universiti Shanghai Jiao Tong, Baidu, dll.) bersama-sama mengeluarkan kebolehtafsiran model besar teknologi Kajian ini mengkaji secara menyeluruh teknologi kebolehtafsiran model penalaan halus tradisional dan model yang sangat besar berasaskan dorongan, dan membincangkan kriteria penilaian dan cabaran penyelidikan masa depan untuk tafsiran model. 
- Pautan kertas: https://arxiv.org/abs/2309.01029
- Pautan Github: https://github.com/hy-zhao23/Explainability-Lasnguage
Apakah kesukaran untuk mentafsir model besar? Kenapa susah nak terangkan model besar? Prestasi menakjubkan model bahasa besar pada tugas pemprosesan bahasa semula jadi telah menarik perhatian meluas daripada masyarakat. Pada masa yang sama, cara menerangkan prestasi menakjubkan model besar merentas tugasan adalah salah satu cabaran mendesak yang dihadapi oleh ahli akademik. Berbeza daripada pembelajaran mesin tradisional atau model pembelajaran mendalam, seni bina model ultra-besar dan bahan pembelajaran besar-besaran membolehkan model besar mempunyai keupayaan penaakulan dan generalisasi yang kuat. Beberapa kesukaran utama dalam menyediakan kebolehtafsiran untuk model bahasa besar (LLM) termasuk:
- Kerumitan model tinggi. Berbeza daripada model pembelajaran mendalam atau model pembelajaran mesin statistik tradisional sebelum era LLM, model LLM berskala besar dan mengandungi berbilion-bilion parameter Perwakilan dalaman dan proses penaakulannya sangat kompleks, dan sukar untuk menerangkan output khusus mereka.
- Kebergantungan data yang kuat. LLM bergantung pada korpus teks berskala besar semasa proses latihan Bias, ralat, dsb. dalam data latihan ini boleh menjejaskan model, tetapi sukar untuk menilai sepenuhnya kesan kualiti data latihan pada model.
- Sifat kotak hitam. Kami biasanya menganggap LLM sebagai model kotak hitam, walaupun untuk model sumber terbuka seperti Llama-2. Sukar untuk kita menilai secara eksplisit rantaian penaakulan dalaman dan proses membuat keputusan. Kita hanya boleh menganalisisnya berdasarkan input dan output, yang menyukarkan kebolehtafsiran.
- Ketidakpastian output. Output LLM selalunya tidak pasti, dan output yang berbeza mungkin dihasilkan untuk input yang sama, yang juga meningkatkan kesukaran kebolehtafsiran.
- Penunjuk penilaian yang tidak mencukupi. Penunjuk penilaian automatik semasa sistem dialog tidak mencukupi untuk mencerminkan sepenuhnya kebolehtafsiran model, dan lebih banyak penunjuk penilaian yang menganggap pemahaman manusia diperlukan.
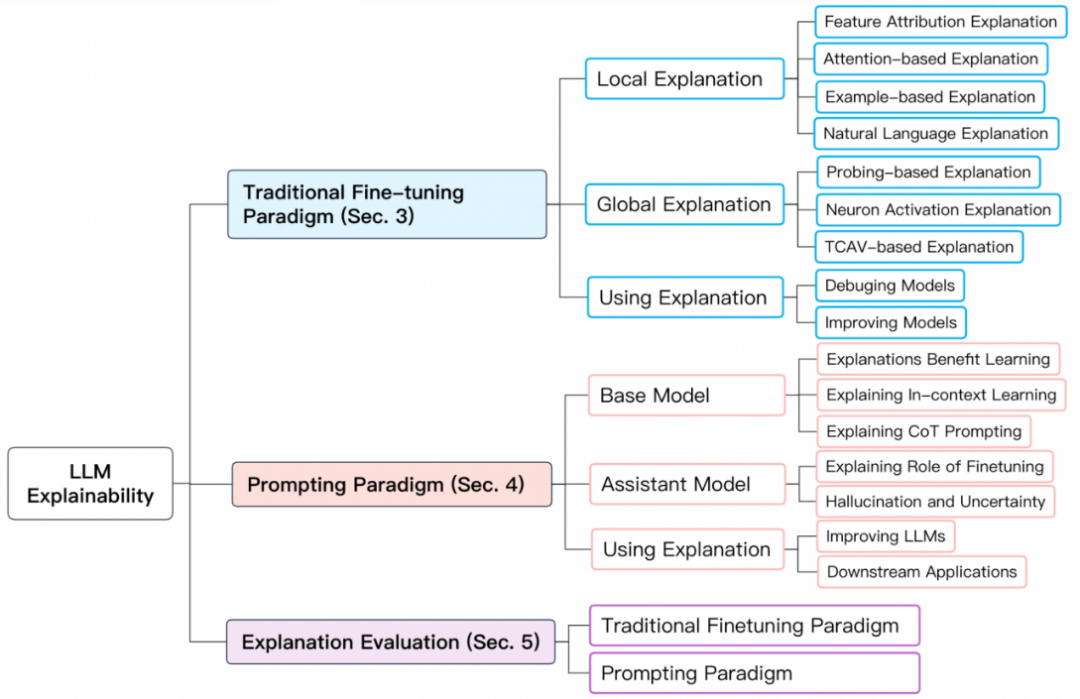
Paradigma latihan model besarUntuk meringkaskan kebolehtafsiran model besar dengan lebih baik, kami membahagikan dua jenis latihan di atas pada tahap BERMS1 dan model besar. ) Paradigma penalaan halus tradisional; 2) Paradigma berasaskan dorongan.
Paradigma penalaan halus tradisional Untuk paradigma penalaan halus tradisional, mula-mula pralatih model bahasa asas pada pustaka domain yang lebih besar dan tidak berlabel, kemudian gunakannya teks daripada, Lakukan penalaan halus pada set data berlabel. Model biasa seperti BERT, RoBERTa, ELECTRA, DeBERTa, dsb.
paradigma berasaskan doronganparadigma berasaskan dorongan mencapai pembelajaran sifar atau beberapa pukulan dengan menggunakan gesaan. Seperti paradigma penalaan halus tradisional, model asas perlu dilatih terlebih dahulu. Walau bagaimanapun, penalaan halus berdasarkan paradigma dorongan biasanya dilaksanakan dengan penalaan arahan dan pembelajaran peneguhan daripada maklum balas manusia (RLHF). Model biasa seperti GPT-3.5, GPT 4, Claude, LLaMA-2-Chat, Alpaca, Vicuna, dsb. Proses latihan adalah seperti berikut:
 Penjelasan model berdasarkan paradigma penalaan halus tradisional Penjelasan model berdasarkan denda tradisional paradigma penalaan Ini termasuk penjelasan ramalan individu (penjelasan tempatan) dan penjelasan komponen tahap struktur model seperti neuron, lapisan rangkaian, dan lain-lain (penjelasan global). #🎜##🎜##🎜🎜🎜##🎜🎜🎜
Penjelasan model berdasarkan paradigma penalaan halus tradisional Penjelasan model berdasarkan denda tradisional paradigma penalaan Ini termasuk penjelasan ramalan individu (penjelasan tempatan) dan penjelasan komponen tahap struktur model seperti neuron, lapisan rangkaian, dan lain-lain (penjelasan global). #🎜##🎜##🎜🎜🎜##🎜🎜🎜
Penjelasan setempat menerangkan ramalan sampel tunggal. Kaedah penjelasannya termasuk atribusi ciri, penjelasan berasaskan perhatian, penjelasan berasaskan contoh, dan penjelasan bahasa semula jadi.
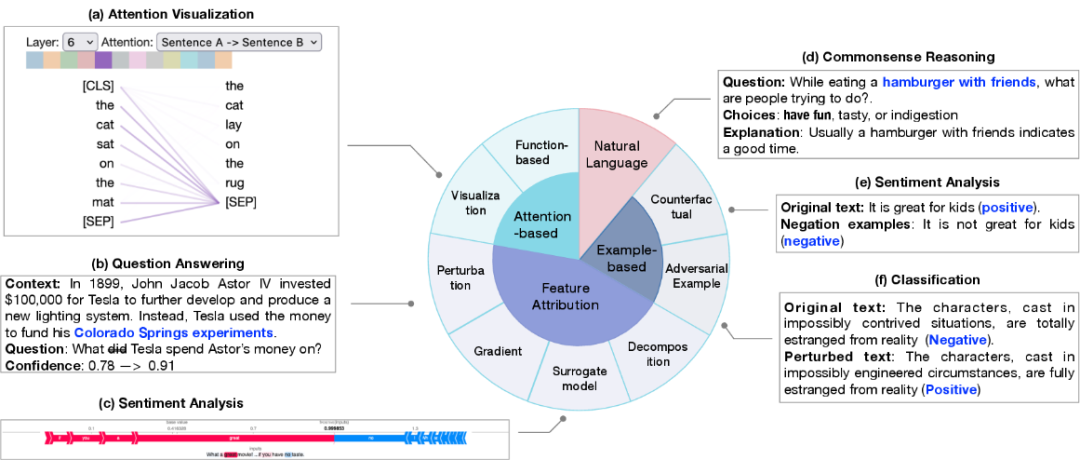 1 Tujuan atribusi ciri adalah untuk mengukur korelasi antara setiap ciri input (cth. perkataan, frasa, julat teks) dan ramalan model . Kaedah atribusi ciri boleh dibahagikan kepada:
1 Tujuan atribusi ciri adalah untuk mengukur korelasi antara setiap ciri input (cth. perkataan, frasa, julat teks) dan ramalan model . Kaedah atribusi ciri boleh dibahagikan kepada:
2. Penjelasan berasaskan perhatian: Perhatian sering digunakan sebagai cara untuk memfokus pada bahagian input yang paling relevan, jadi perhatian boleh mempelajari maklumat yang relevan yang boleh digunakan untuk menjelaskan ramalan. Kaedah tafsiran berkaitan perhatian yang biasa termasuk:
- Teknologi visualisasi perhatian, yang secara intuitif memerhati perubahan dalam skor perhatian pada skala yang berbeza
- tafsiran berasaskan fungsi, seperti mengeluarkan kesan separa yang berbeza. Walau bagaimanapun, penggunaan perhatian sebagai perspektif penyelidikan masih menjadi kontroversi dalam komuniti akademik.
3. Penjelasan berasaskan sampel mengesan dan menerangkan model dari perspektif kes individu, yang kebanyakannya dibahagikan kepada: sampel lawan dan sampel kontrafaktual. Sampel -sampel yang dijana adalah data yang dihasilkan untuk ciri -ciri model yang sangat sensitif terhadap perubahan kecil. membawa kepada ramalan yang berbeza oleh model. Sampel kontrafaktual diperoleh dengan mengubah bentuk teks seperti penolakan, yang biasanya merupakan ujian keupayaan inferens sebab model.
- 4. Penjelasan bahasa semula jadi menggunakan teks asal dan penjelasan berlabel manual untuk latihan model, supaya model boleh menjana penjelasan bahasa semula jadi tentang proses membuat keputusan model.
Penjelasan global
Penjelasan global bertujuan untuk memberikan pemahaman yang lebih tinggi tentang mekanisme kerja model besar daripada peringkat model termasuk neuron, lapisan tersembunyi dan. Ia terutamanya meneroka pengetahuan semantik yang dipelajari dalam komponen rangkaian yang berbeza. Tafsiran berasaskan probe Teknologi tafsiran probe adalah berdasarkan pengesanan pengelas Ia melatih pengelas cetek pada model pra-latihan atau model yang telah ditala halus, dan kemudian menilainya pada set data tahan, supaya. Pengelas dapat mengenal pasti ciri bahasa atau kebolehan penaakulan. Pengaktifan neuron Analisis pengaktifan neuron tradisional hanya mempertimbangkan sebahagian daripada neuron penting, dan kemudian mempelajari hubungan antara neuron dan ciri semantik. Baru-baru ini, GPT-4 juga telah digunakan untuk menerangkan neuron Daripada memilih beberapa neuron untuk penjelasan, GPT-4 boleh digunakan untuk menerangkan semua neuron.
-
Tafsiran berasaskan konsep memetakan input kepada set konsep dan kemudian menerangkan model dengan mengukur kepentingan konsep kepada ramalan.
-
Penjelasan model berdasarkan paradigma dorongan
Penjelasan model berdasarkan paradigma dorongan memerlukan penjelasan berasingan tentang model asas dan model penolong untuk model yang dibilkan laluan. Isu yang diterokai terutamanya termasuk: faedah menyediakan penjelasan untuk model tentang pembelajaran beberapa pukulan memahami sumber pembelajaran beberapa pukulan dan keupayaan rantaian pemikiran. Penjelasan model asas
Faedah penjelasan untuk pembelajaran model Terokai sama ada penerangan berguna untuk pembelajaran model dalam kes pembelajaran beberapa pukulan.
Pembelajaran kontekstual Terokai mekanisme pembelajaran kontekstual dalam model besar, dan bezakan perbezaan antara pembelajaran kontekstual dalam model besar dan model sederhana.
-
Gesaan rantaian berfikir Terokai sebab dorongan rantaian berfikir meningkatkan prestasi model.
-
Penjelasan model penolong
Peranan model Penolong penalaan halus biasanya dilatih dan dilatih semula melalui pengetahuan am dan penyeliaan. pembelajaran. Tahap di mana pengetahuan model pembantu terutamanya berasal masih perlu dikaji.
Ilusi dan Ketidakpastian Ketepatan dan kredibiliti ramalan model besar masih menjadi isu penting dalam penyelidikan semasa. Walaupun keupayaan inferens berkuasa model besar, keputusan mereka sering mengalami maklumat salah dan halusinasi. Ketidakpastian dalam ramalan ini membawa cabaran besar kepada aplikasinya yang meluas.
Penilaian penjelasan model
Penunjuk penilaian penjelasan model termasuk kebolehpercayaan, kesetiaan, kestabilan dan keteguhan. Kertas kerja ini terutamanya bercakap tentang dua dimensi yang prihatin secara meluas: 1) rasional kepada manusia; 2) kesetiaan kepada logik dalaman model.
Penilaian penjelasan model penalaan halus tradisional terutamanya tertumpu pada penjelasan tempatan. Kebolehpercayaan selalunya memerlukan penilaian pengukuran tafsiran model berbanding tafsiran beranotasi manusia terhadap piawaian yang direka bentuk. Kesetiaan memberi lebih perhatian kepada prestasi penunjuk kuantitatif Memandangkan penunjuk yang berbeza memfokuskan pada aspek model atau data yang berbeza, masih terdapat kekurangan piawaian bersatu untuk mengukur kesetiaan. Penilaian berdasarkan tafsiran model yang mendorong memerlukan penyelidikan lanjut.
Cabaran penyelidikan masa depan 1. Kekurangan penjelasan yang sah dan betul. Cabaran datang dari dua aspek: 1) kekurangan piawaian untuk mereka bentuk penjelasan yang berkesan 2) kekurangan penjelasan yang berkesan menyebabkan kekurangan sokongan untuk penilaian penjelasan. 2. Asal-usul fenomena kemunculan tidak diketahui. Penerokaan keupayaan kemunculan model besar boleh dijalankan dari perspektif model dan data masing-masing Dari perspektif model, 1) struktur model yang menyebabkan fenomena kemunculan; 2) skala model minimum kerumitan yang mempunyai prestasi unggul dalam tugasan merentas bahasa. Dari perspektif data, 1) subset data yang menentukan ramalan khusus; 2) hubungan antara kebolehan yang muncul dan latihan model dan pencemaran data; latihan dan penalaan halus. 3. Perbezaan antara paradigma penalaan halus dan paradigma dorongan. Prestasi yang berbeza bagi pengedaran dalam dan luar pengedaran bermakna kaedah penaakulan yang berbeza. 1) Perbezaan dalam paradigma penaakulan apabila data berada dalam taburan 2) Sumber perbezaan dalam keteguhan model apabila data diedarkan secara berbeza. 4. Masalah pembelajaran pintasan untuk model besar. Di bawah kedua-dua paradigma tersebut, masalah pembelajaran pintasan model wujud dalam aspek yang berbeza. Walaupun model besar mempunyai sumber data yang banyak, masalah pembelajaran pintasan agak berkurangan. Menjelaskan mekanisme pembentukan pembelajaran pintasan dan mencadangkan penyelesaian masih penting untuk generalisasi model. 5. Masalah redundansi modul perhatian wujud secara meluas dalam kedua-dua paradigma Kajian redundansi perhatian boleh memberikan penyelesaian untuk teknologi pemampatan model. 6. Kebolehtafsiran model besar adalah penting untuk mengawal model dan mengehadkan kesan negatif model. Seperti berat sebelah, ketidakadilan, pencemaran maklumat, manipulasi sosial dan isu-isu lain. Membina model AI yang boleh dijelaskan dengan berkesan boleh mengelakkan masalah di atas dan membentuk sistem kecerdasan buatan yang beretika. Atas ialah kandungan terperinci Menganalisis kebolehtafsiran model besar: ulasan mendedahkan kebenaran dan menjawab keraguan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Kaedah pemindahan pangkalan data MySQL
Kaedah pemindahan pangkalan data MySQL
 Penyelesaian kepada masalah bahawa fail exe tidak boleh dibuka dalam sistem win10
Penyelesaian kepada masalah bahawa fail exe tidak boleh dibuka dalam sistem win10
 Bagaimana untuk menggunakan fungsi cetakan dalam python
Bagaimana untuk menggunakan fungsi cetakan dalam python
 Adakah HONOR Huawei?
Adakah HONOR Huawei?
 Bagaimana untuk memulihkan fail yang dikosongkan daripada Recycle Bin
Bagaimana untuk memulihkan fail yang dikosongkan daripada Recycle Bin
 tutorial fleksibel
tutorial fleksibel
 cakera sistem win10 diduduki 100%
cakera sistem win10 diduduki 100%
 penggunaan fungsi parseint
penggunaan fungsi parseint





















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



