


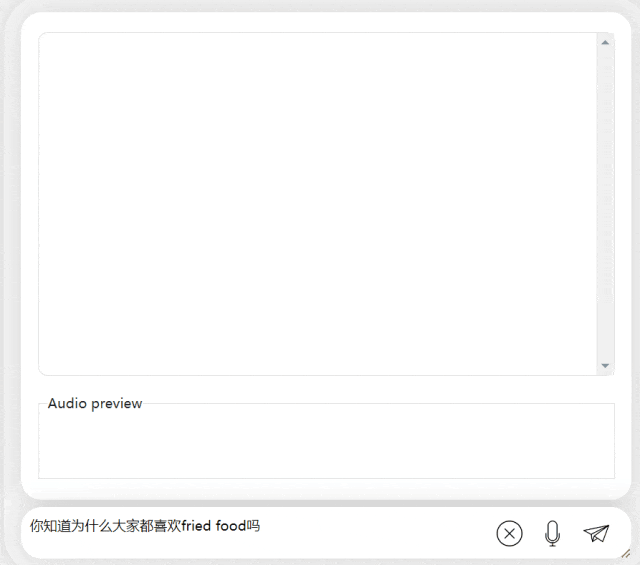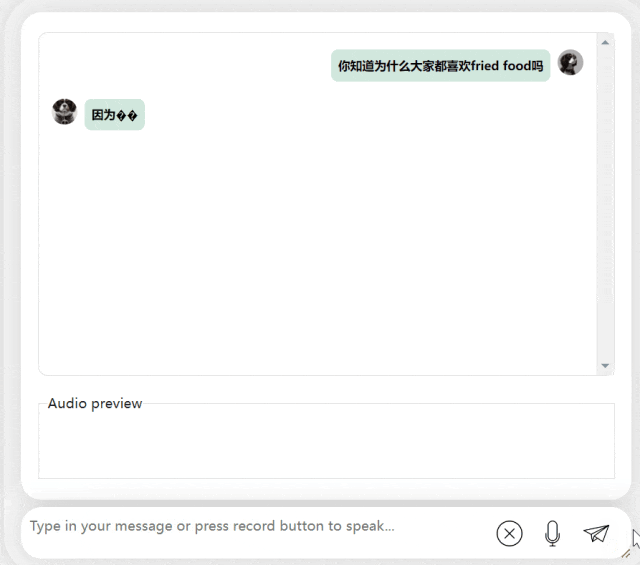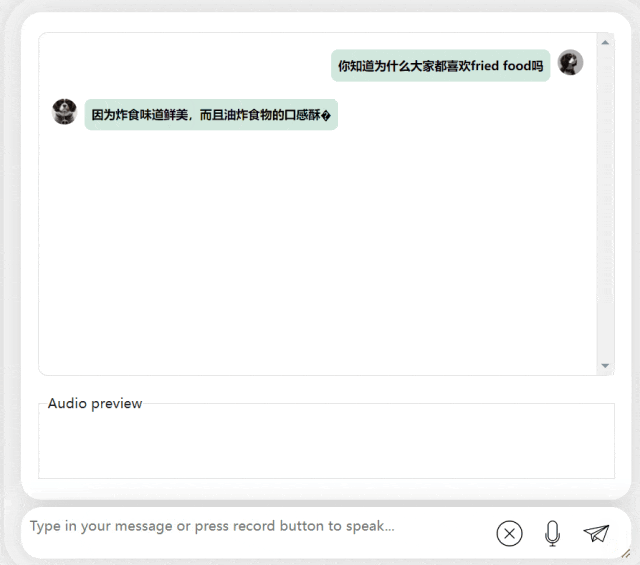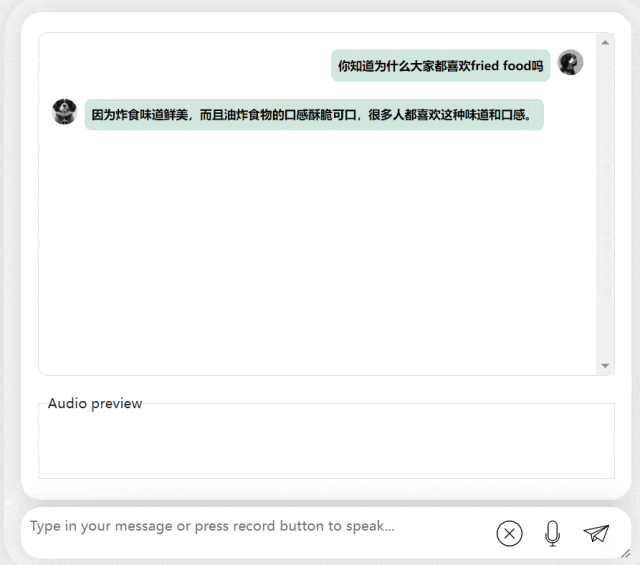
Model besar sumber terbuka dialog suara dwibahasa Cina-Inggeris yang pertama ada di sini!
Dalam beberapa hari lepas, kertas mengenai model berbilang modal teks ucapan yang besar telah muncul di arXiv, dan nama syarikat model besar Kai-fu Lee 01.ai - 01.ai - adalah antara syarikat yang terkenal.
 Picture
Picture
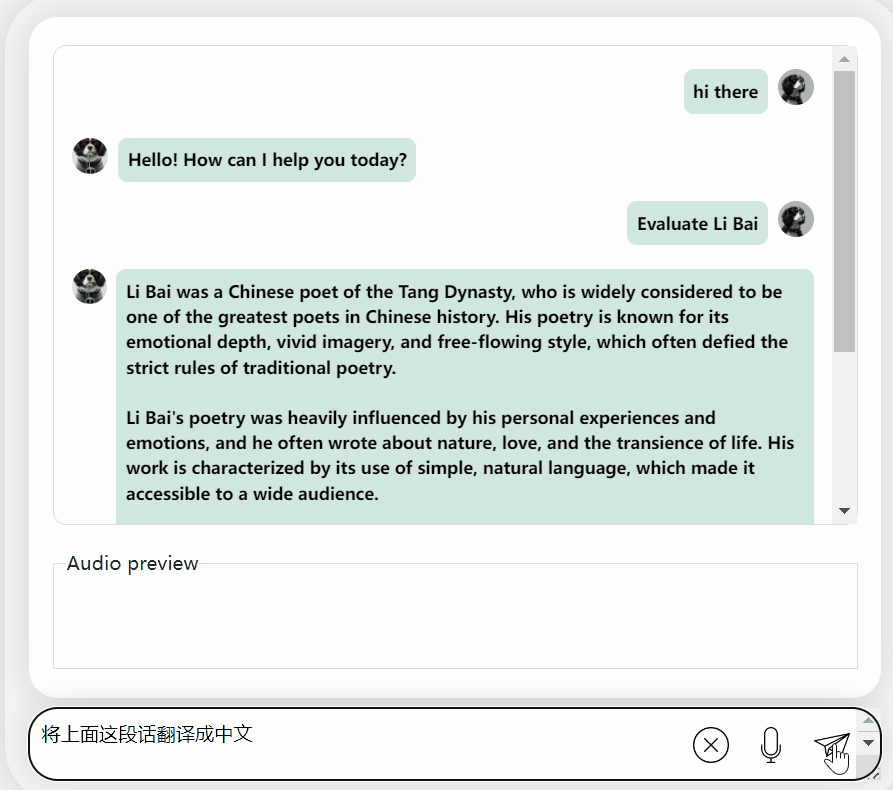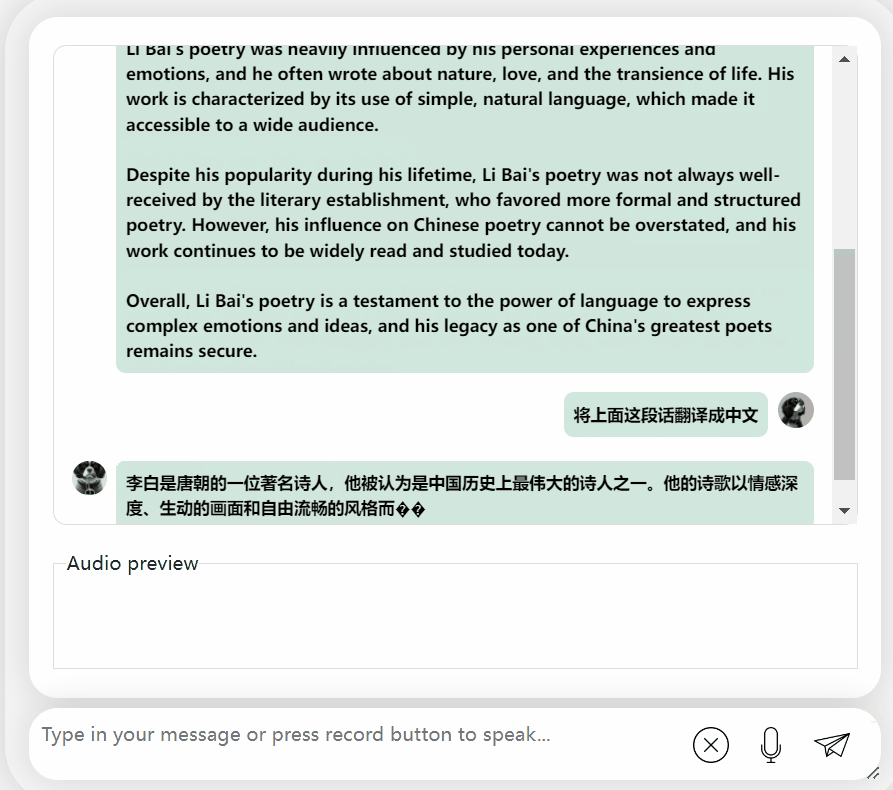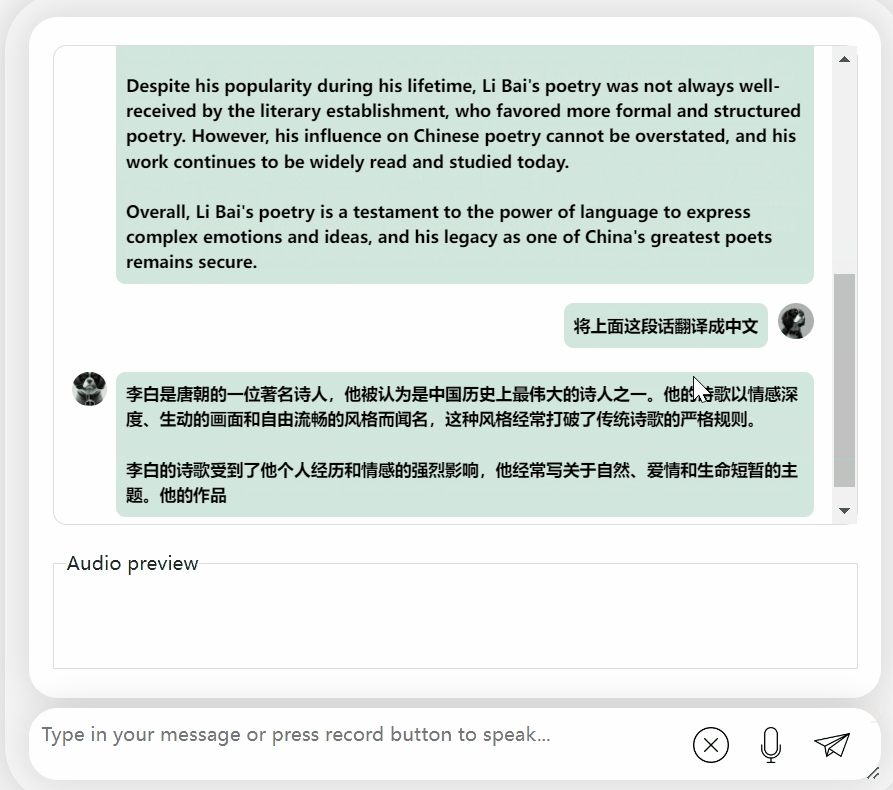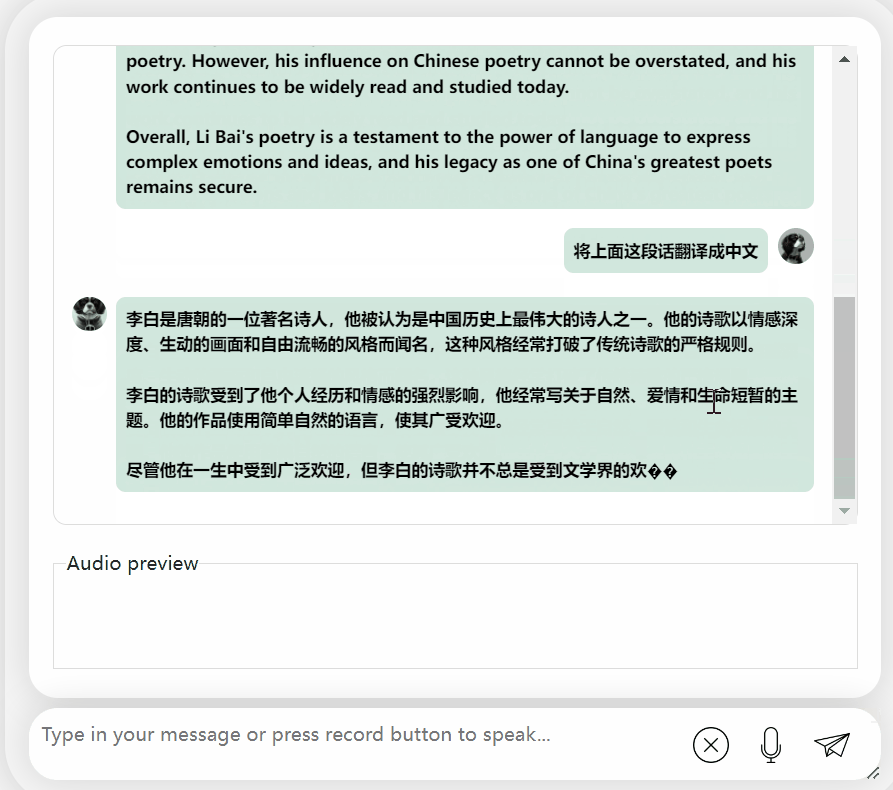
Kertas kerja ini memperkenalkan model perbualan dwibahasa Cina-Inggeris yang boleh didapati secara komersial dipanggil LLaSM. Model ini bukan sahaja menyokong rakaman dan input teks, tetapi juga dapat merealisasikan fungsi "beregu hibrid"
 gambar
gambar
Penyelidikan menunjukkan bahawa "sembang suara" adalah cara interaksi yang lebih mudah dan semula jadi antara AI dan orang. , bukan hanya melalui input Teks
menggunakan model besar, malah ada netizen yang sudah membayangkan senario "menulis kod sambil baring dan bercakap".
 Pictures
Pictures
Penyelidikan ini telah disiapkan bersama oleh LinkSoul.AI, Universiti Peking dan 01Wanwu Ia kini menjadi sumber terbuka dan boleh dicuba terus dalam Huugian
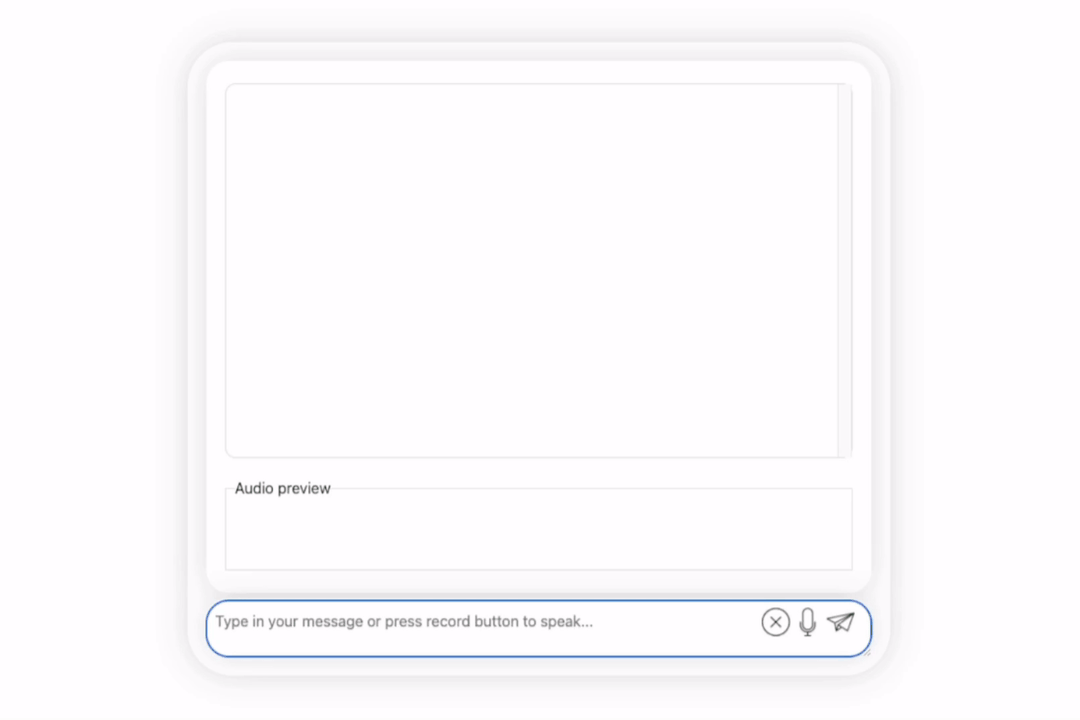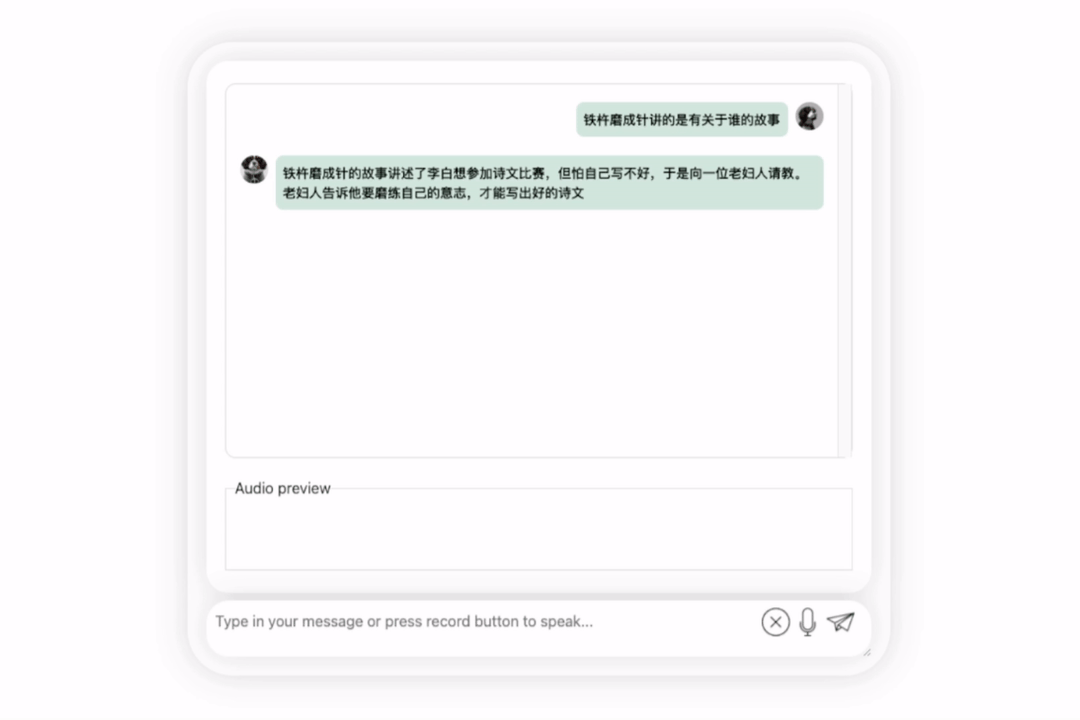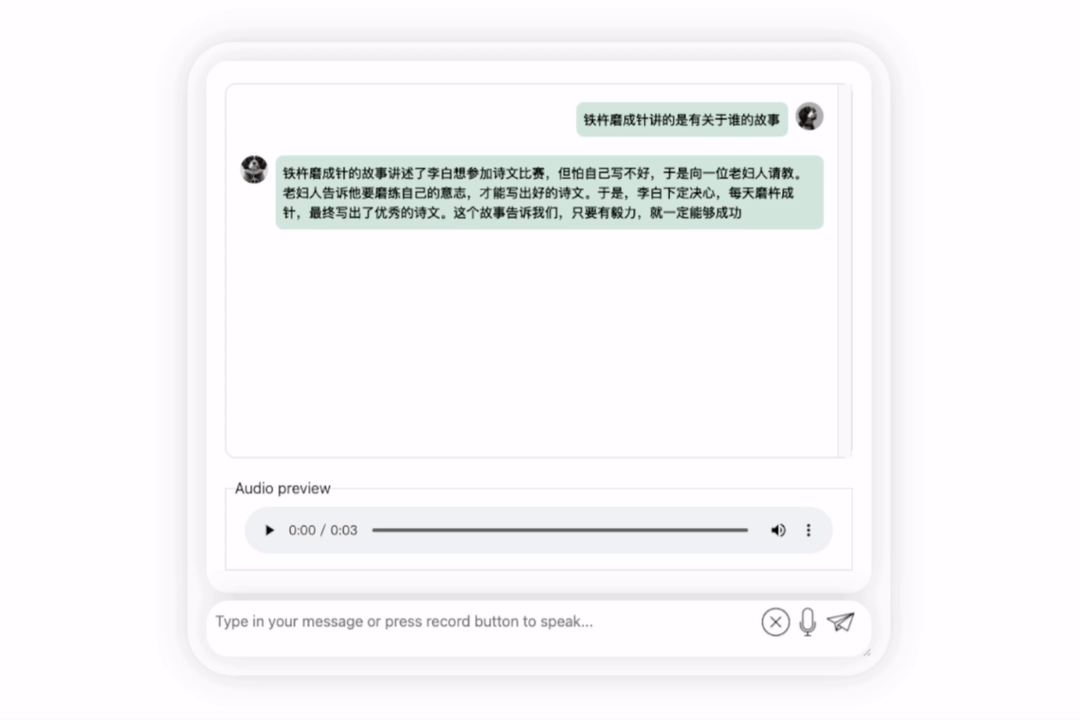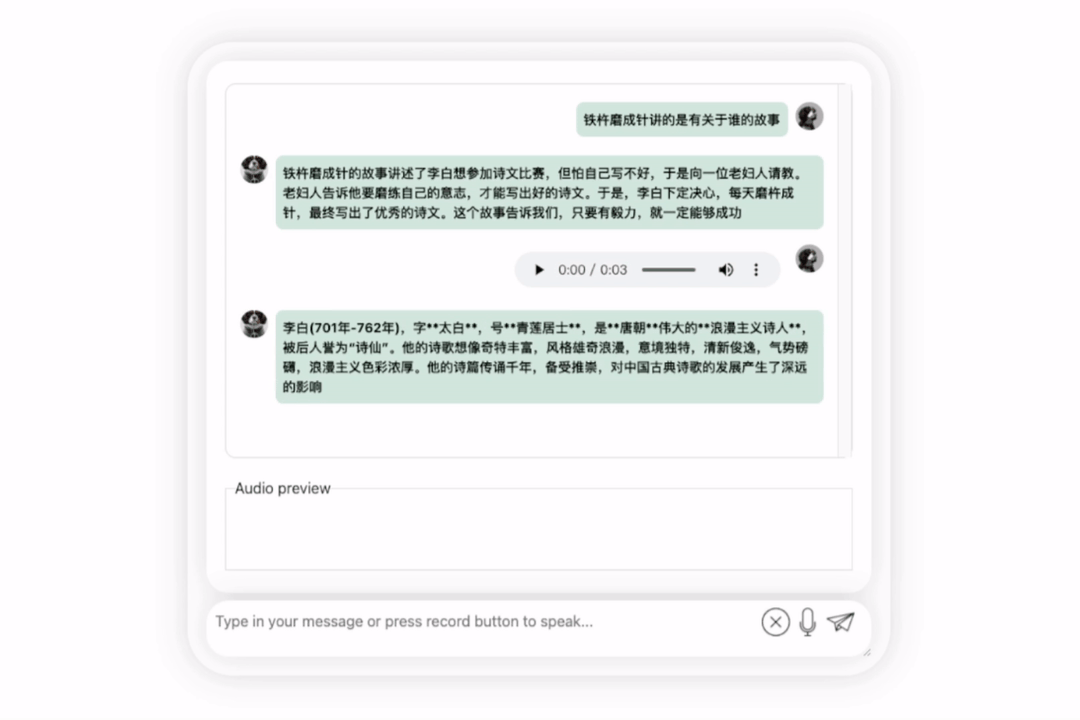
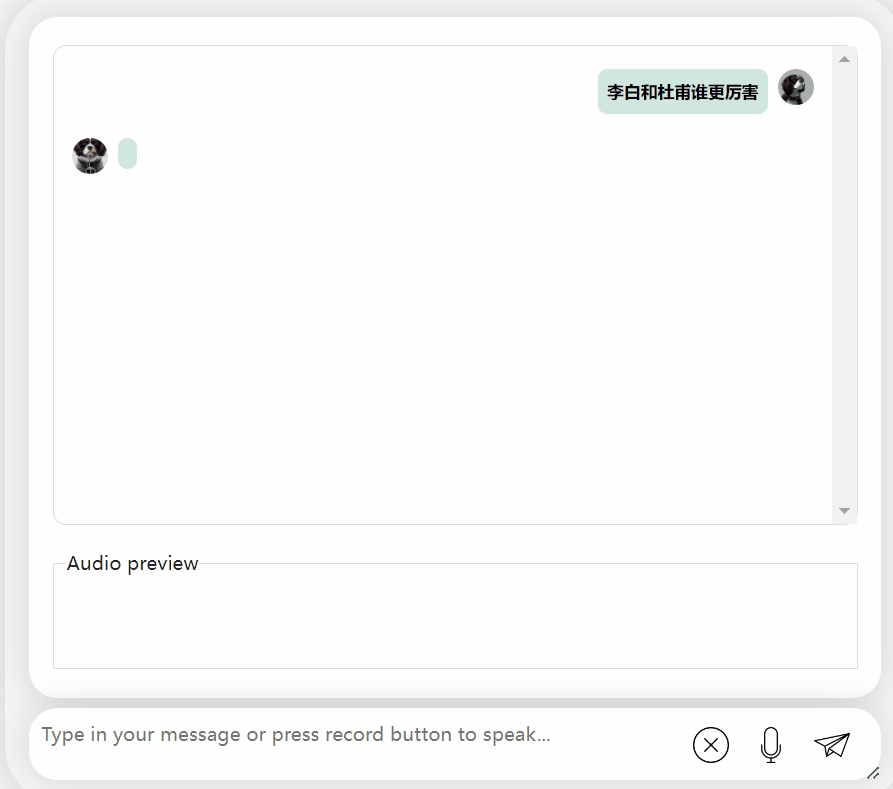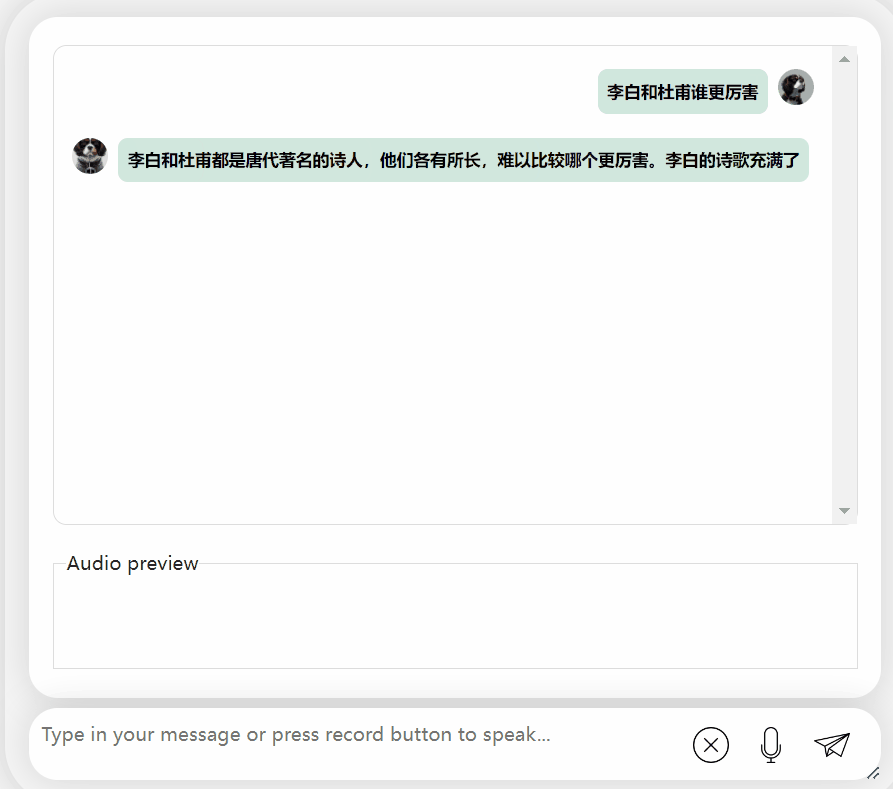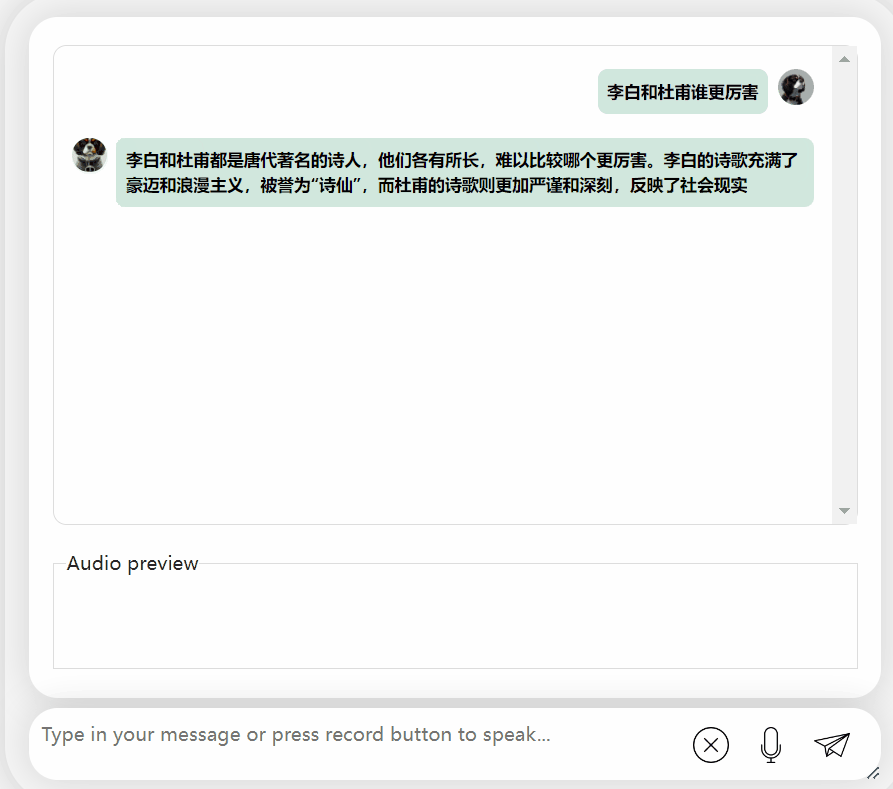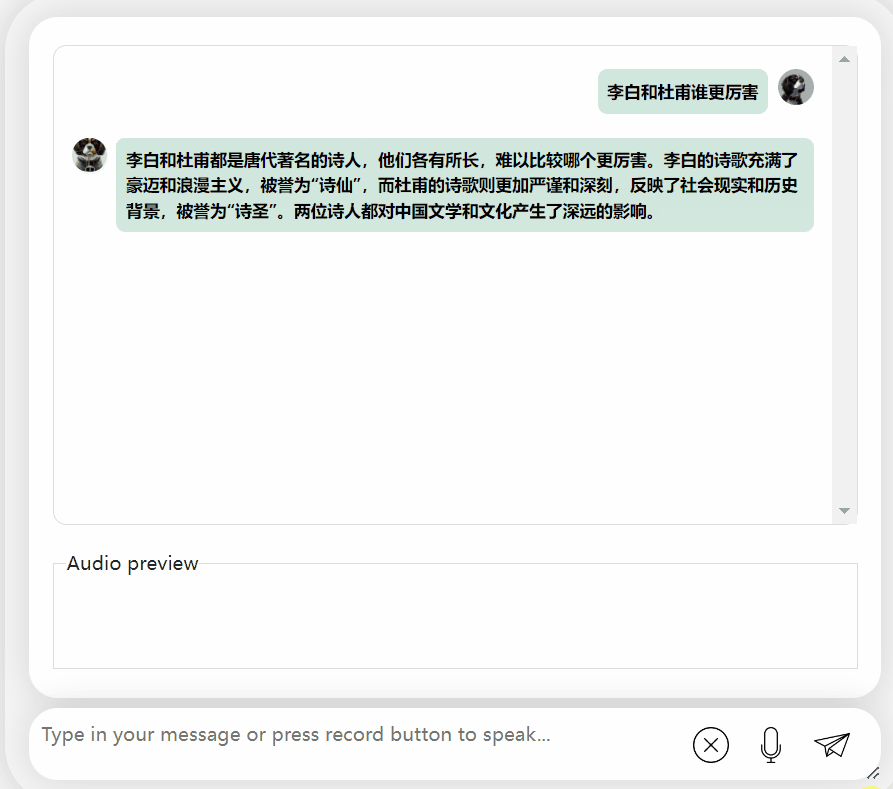
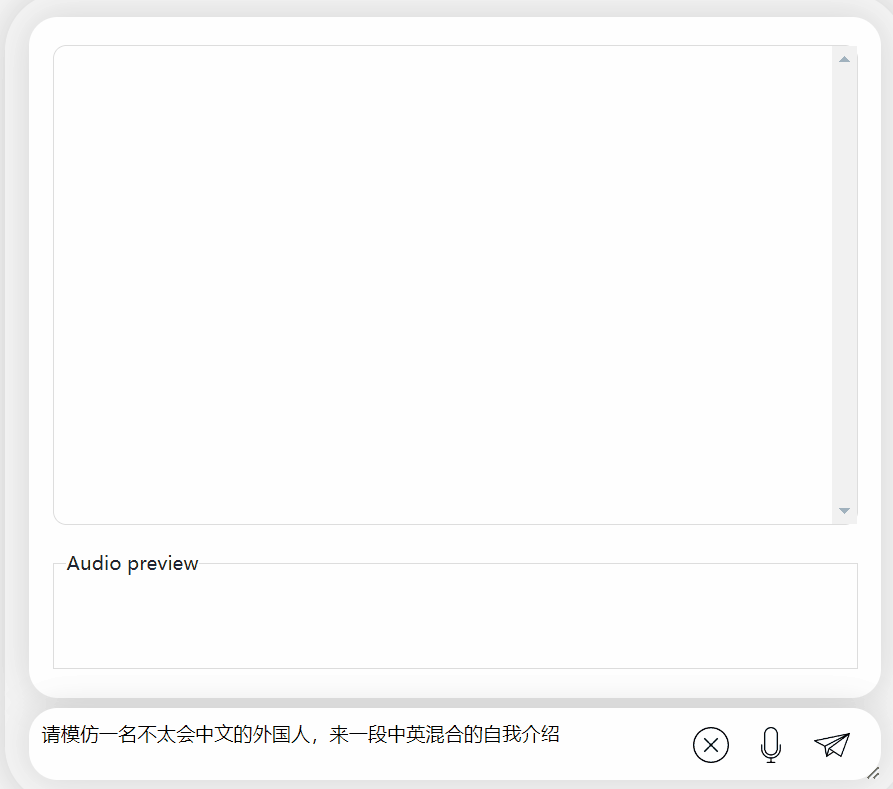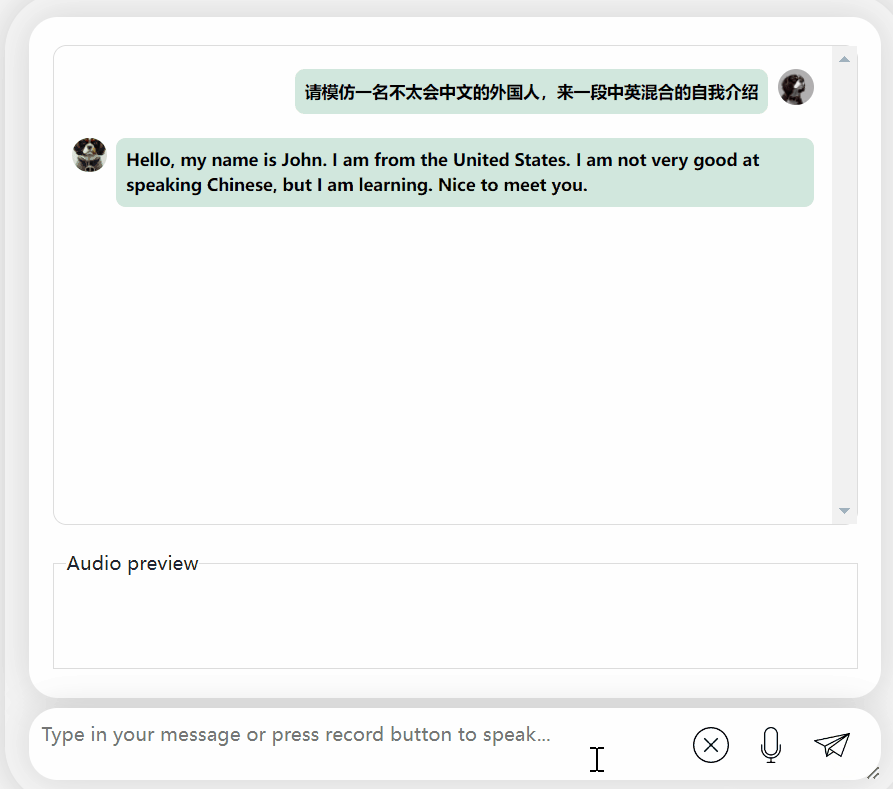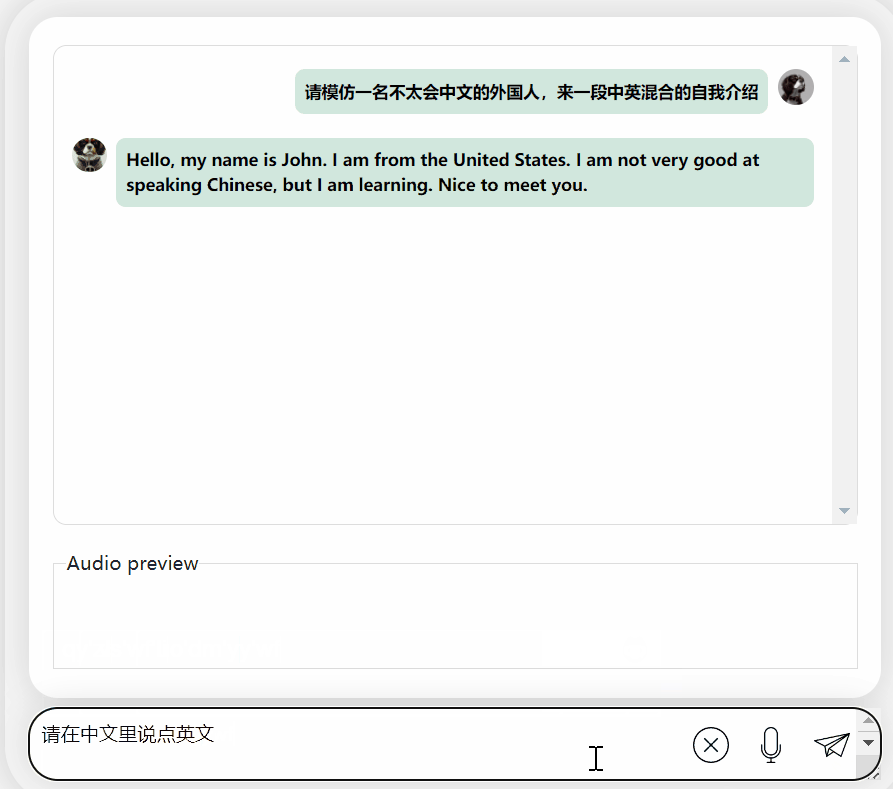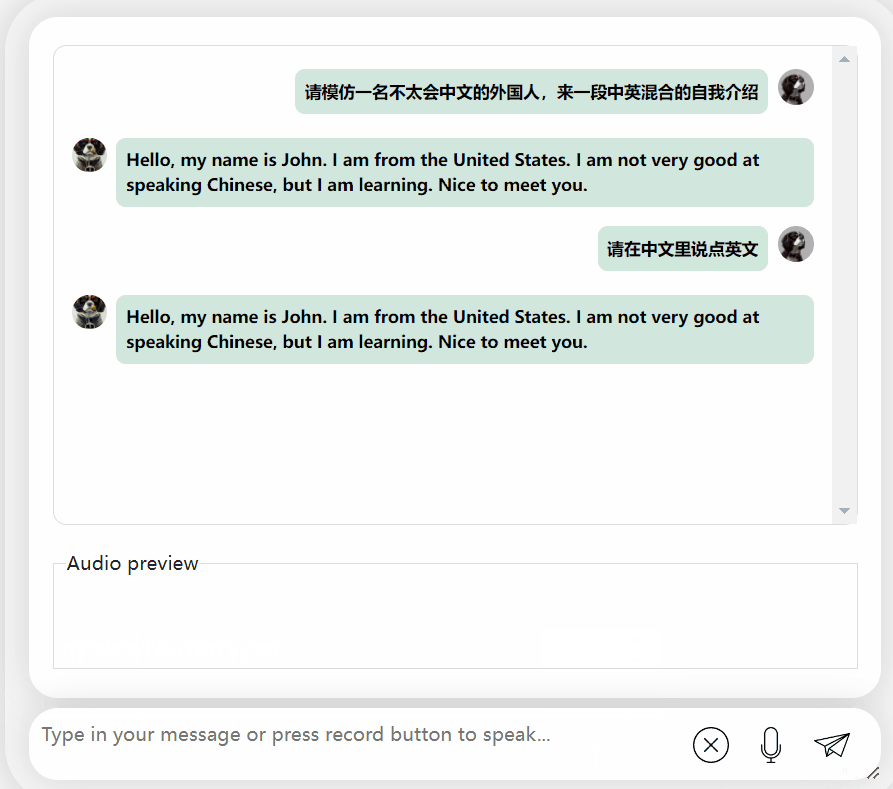
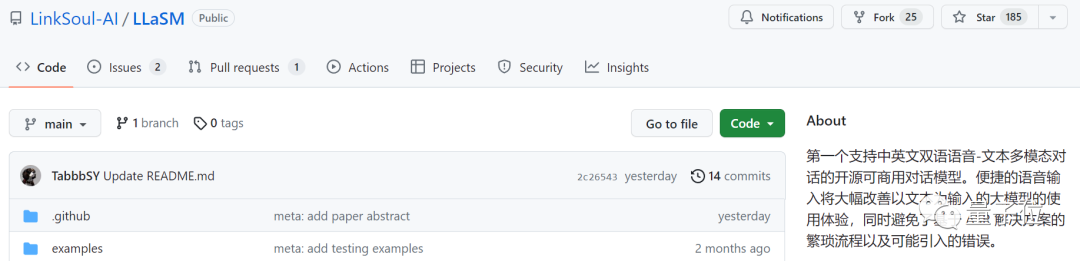 Lihatlah bagaimana berkesan
Lihatlah bagaimana berkesan
 Gambar
Gambar
 Gambar
Gambar
 Gambar
Gambar
 gambar
gambar
 Pictures
Pictures
 Gambar
Gambar
Secara keseluruhannya, apabila berhadapan dengan soalan atau permintaan yang bercampur dalam bahasa Cina dan Inggeris, keupayaan output model masih tidak begitu baik.
Tetapi jika dipisahkan, keupayaannya untuk menyatakan bahasa Cina dan Inggeris masih bagus.
Jadi, bagaimanakah model sedemikian dilaksanakan?
Berdasarkan percubaan, LLaSM mempunyai dua ciri utama: satu adalah untuk menyokong input bahasa Cina dan Inggeris, dan satu lagi ialah input dwi suara dan teks.
Untuk mencapai dua perkara ini, kami perlu membuat beberapa pelarasan pada data seni bina dan latihan masing-masing.
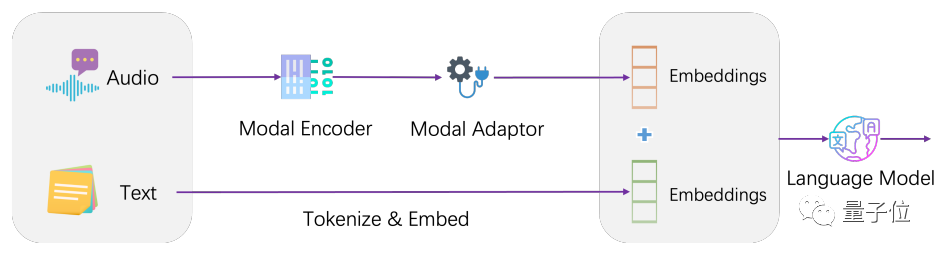
Secara seni bina, LLaSM menyepadukan model pengecaman pertuturan semasa dan model bahasa besar.
LLaSM terdiri daripada tiga bahagian, termasuk model pengecaman pertuturan automatik Whisper, penyesuai modal dan model besar LLaMA.
Dalam proses ini, Whisper bertanggungjawab untuk menerima input pertuturan asal dan mengeluarkan perwakilan vektor bagi ciri pertuturan. Peranan penyesuai modal adalah untuk menjajarkan benam pertuturan dan teks. LLaMA bertanggungjawab untuk memahami arahan input suara dan teks serta menjana balasan
 gambar
gambar
Latihan model dibahagikan kepada dua peringkat. Peringkat pertama adalah untuk melatih penyesuai modaliti, di mana pengekod dan model besar dibekukan, membolehkan model mempelajari penjajaran pertuturan dan teks. Peringkat kedua adalah untuk membekukan pengekod, melatih penyesuai modal dan model besar untuk meningkatkan keupayaan dialog berbilang mod model Pada data latihan, penyelidik menyusun koleksi 199,000 dialog dan 508,000 sampel teks pertuturan -Audio-Arahan.
Antara 508,000 sampel teks pertuturan, 80,000 adalah sampel pertuturan bahasa Cina, manakala 428,000 adalah sampel pertuturan bahasa Inggeris
Para penyelidik terutamanya berdasarkan set data seperti WizardLM, ShareGPT dan GPT-4-LLM, melalui teks Ucapan-kepada- teknologi menjana paket suara untuk set data ini sambil menapis perbualan yang tidak sah.
Pictures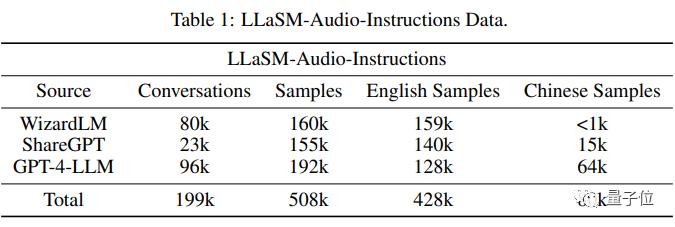 Ini adalah arahan teks suara bahasa Cina dan Inggeris terbesar pada masa ini, tetapi ia masih sedang diselesaikan, menurut penyelidik, ia akan menjadi sumber terbuka selepas ia diselesaikan.
Ini adalah arahan teks suara bahasa Cina dan Inggeris terbesar pada masa ini, tetapi ia masih sedang diselesaikan, menurut penyelidik, ia akan menjadi sumber terbuka selepas ia diselesaikan.
Namun, buat masa ini tiada perbandingan kesan keluaran kertas kerja ini dengan model pertuturan atau model teks yang lain
Pengenalan kepada pengarang
Pengarang bersama Yu Shu dan Siwei Dong kedua-duanya berasal dari LinkSoul.AI dan pernah bekerja di Institut Penyelidikan Kepintaran Buatan Beijing Zhiyuan.
LinkSoul.AI ialah syarikat permulaan AI yang sebelum ini telah melancarkan model bahasa Cina besar Llama 2 sumber terbuka pertama.
Pictures Sebagai sebuah syarikat model besar yang dimiliki oleh Kai-fu Lee, Zero One dan One World turut menyumbang kepada penyelidikan ini. Halaman Muka Memeluk pengarang Wenhao Huang menunjukkan bahawa dia lulus dari Universiti Fudan.
Sebagai sebuah syarikat model besar yang dimiliki oleh Kai-fu Lee, Zero One dan One World turut menyumbang kepada penyelidikan ini. Halaman Muka Memeluk pengarang Wenhao Huang menunjukkan bahawa dia lulus dari Universiti Fudan.
Gambar Alamat kertas:
Alamat kertas:
//m.sbmmt.com/link/47c917b09f2bc64b2916c0824c715923
.php alamat /bcd 0049c35799cdf57d06eaf2eb3cff6
Atas ialah kandungan terperinci Model dialog suara berskala besar baharu dilancarkan di China: diketuai oleh Kai-Fu Lee, dengan penyertaan daripada Zero One and All, menyokong dwibahasa Cina dan Inggeris serta pelbagai mod, sumber terbuka dan tersedia secara komersial. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



