


Dengan perkembangan pesat dan aplikasi model berskala besar, kepentingan Embedding, yang merupakan komponen asas teras model berskala besar, telah menjadi semakin menonjol. Model vektor semantik Cina-Inggeris sumber terbuka dan tersedia secara komersial BGE (BAAI General Embedding) yang dikeluarkan oleh Syarikat Zhiyuan sebulan yang lalu telah menarik perhatian meluas dalam komuniti, dan telah dimuat turun ratusan ribu kali pada platform Hugging Face. Pada masa ini, BGE telah melancarkan versi 1.5 secara berulang-ulang dan mengumumkan berbilang kemas kini. Antaranya, BGE telah membuka sumber terbuka 300 juta data latihan berskala besar buat kali pertama, menyediakan komuniti bantuan dalam melatih model serupa dan mempromosikan pembangunan teknologi dalam bidang ini
cina dan data Bahasa Inggeris
Kecemerlangan BGE Keupayaannya sebahagian besarnya berpunca daripada data latihan berskala besar dan pelbagai. Sebelum ini, rakan industri jarang mengeluarkan set data yang serupa. Dalam kemas kini ini, Zhiyuan membuka data latihan BGE kepada komuniti buat kali pertama, meletakkan asas untuk pembangunan lanjut jenis teknologi ini.
Set data MTP yang dikeluarkan kali ini terdiri daripada sejumlah 300 juta pasangan teks berkaitan bahasa Cina dan Inggeris. Antaranya, terdapat 100 juta rekod dalam bahasa Cina dan 200 juta rekod dalam bahasa Inggeris. Sumber data termasuk Wudao Corpora, Pile, DuReader, Sentence Transformer dan korporat lain. Diperolehi selepas pensampelan, pengekstrakan dan pembersihan yang diperlukan
Untuk butiran, sila rujuk Hab Data: https://data.baai.ac.cn
MTP ialah set data pasangan teks berkaitan Cina-Inggeris sumber terbuka terbesar setakat ini, menyediakan asas penting untuk melatih model vektor semantik Cina dan Inggeris.
Berdasarkan maklum balas komuniti, BGE telah dioptimumkan lagi berdasarkan versi 1.0nya untuk menjadikan prestasinya lebih stabil dan cemerlang. Kandungan peningkatan khusus adalah seperti berikut:
Perlu dinyatakan bahawa baru-baru ini, Zhiyuan dan Hugging Face mengeluarkan laporan teknikal, yang mencadangkan menggunakan C-Pack untuk meningkatkan model vektor semantik universal Cina.
"C-Pack: Packaged Resources To Advance General Chinese Embedding"
Pautan: https://arxiv.org/pdf/2309.07597.pdf
mendapat populariti tinggi dalam komuniti BGE telah menarik perhatian komuniti pembangun model besar sejak dikeluarkan Pada masa ini, Hugging Face telah dimuat turun ratusan ribu kali, dan telah disepadukan dan digunakan oleh projek sumber terbuka yang terkenal seperti LangChain, LangChain-Chachat, llama_index, dsb.
Pegawai Langchain, pengasas bersama dan Ketua Pegawai Eksekutif LangChain Harrison Chase, pengasas Deep trading Yam Peleg dan pengaruh komuniti lain menyatakan kebimbangan mengenai BGE.
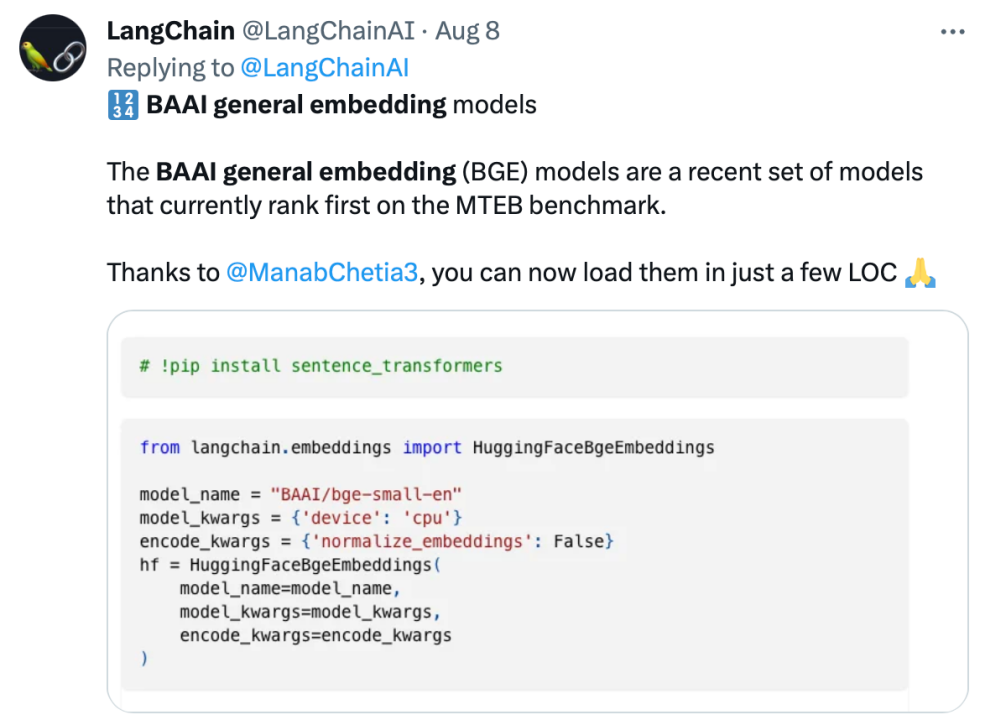
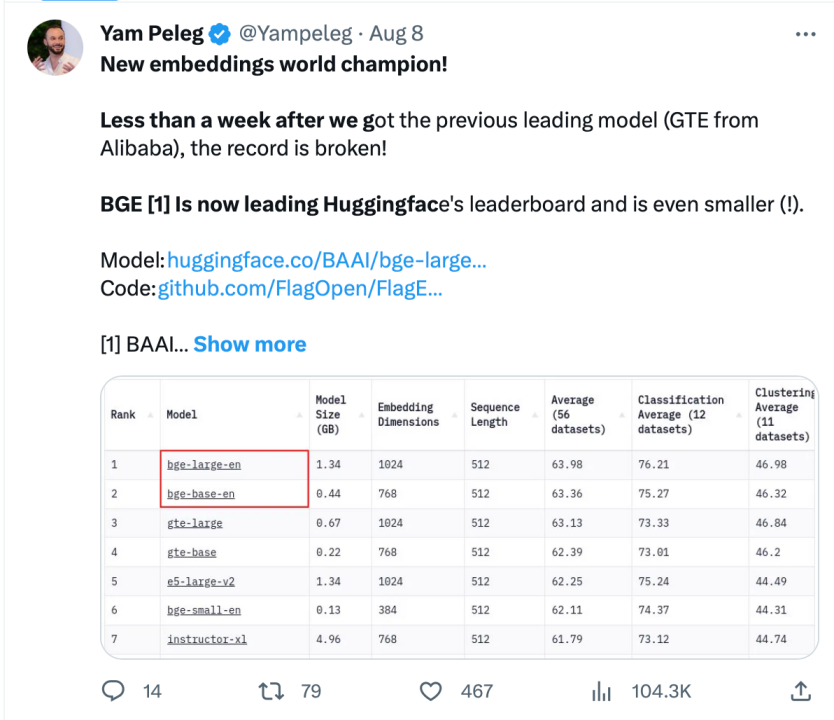
Mematuhi sumber terbuka dan keterbukaan, mempromosikan inovasi kolaboratif, sistem pembangunan teknologi model besar Sumber Pintar FlagOpen BGE telah menambah bahagian FlagEmbedding baharu, memfokuskan pada teknologi dan model Benamkan adalah salah satu BGE berprofil tinggi projek sumber terbuka. FlagOpen komited untuk membina infrastruktur teknologi kecerdasan buatan dalam era model besar, dan akan terus membuka teknologi tindanan penuh model besar yang lebih lengkap kepada akademia dan industri pada masa hadapan
Atas ialah kandungan terperinci Zhiyuan membuka 300 juta data latihan model vektor semantik, dan model BGE terus dikemas kini secara berulang.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Koleksi arahan komputer yang biasa digunakan
Koleksi arahan komputer yang biasa digunakan
 win10 menyambung ke pencetak kongsi
win10 menyambung ke pencetak kongsi
 Bagaimana untuk menjadi kawan rapat di TikTok
Bagaimana untuk menjadi kawan rapat di TikTok
 Perisian pemulihan data percuma
Perisian pemulihan data percuma
 Apakah fungsi pembinaan laman web?
Apakah fungsi pembinaan laman web?
 Bagaimana untuk mewakili nombor negatif dalam binari
Bagaimana untuk mewakili nombor negatif dalam binari
 python mengkonfigurasi pembolehubah persekitaran
python mengkonfigurasi pembolehubah persekitaran
 Bagaimana untuk membuka fail html WeChat
Bagaimana untuk membuka fail html WeChat








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



