


Anda mungkin pernah mendengar pendapat tajam berikut:
1 Jika anda mengikuti laluan teknikal NVIDIA, anda mungkin tidak akan dapat mengejar NVIDIA.
2 DSA mungkin berpeluang untuk mengejar NVIDIA, tetapi keadaan semasa ialah DSA di ambang kepupusan dan tidak ada harapan lagi
Sebaliknya, kita semua tahu bahawa model besar sekarang. di barisan hadapan, dan ramai orang dalam industri ingin membuat Cip model besar, terdapat juga ramai orang yang ingin melabur dalam cip model besar.
Tetapi apakah kunci kepada reka bentuk cip model besar Semua orang nampaknya tahu kepentingan lebar jalur yang besar dan memori yang besar, tetapi bagaimanakah cip itu dibuat berbeza daripada NVIDIA?
Dengan soalan, artikel ini cuba memberi anda sedikit inspirasi.
Artikel yang berdasarkan pendapat selalunya kelihatan formalistik. Kita boleh menggambarkannya melalui contoh seni bina
SambaNova Systems dikenali sebagai salah satu daripada sepuluh syarikat unicorn terbaik di Amerika Syarikat. Pada April 2021, syarikat itu menerima pelaburan Siri D AS$678 juta yang diketuai oleh SoftBank, dengan penilaian mencecah AS$5 bilion, menjadikannya sebuah syarikat super unicorn. Sebelum ini, pelabur SambaNova termasuk dana modal teroka terkemuka dunia seperti Google Ventures, Intel Capital, SK dan Samsung Catalytic Fund. Jadi, apakah perkara yang mengganggu yang dilakukan oleh syarikat super unicorn ini yang telah menarik minat institusi pelaburan terkemuka dunia? Dengan memerhatikan bahan promosi awal mereka, kita dapati bahawa SambaNova telah memilih laluan pembangunan yang berbeza daripada NVIDIA gergasi AI
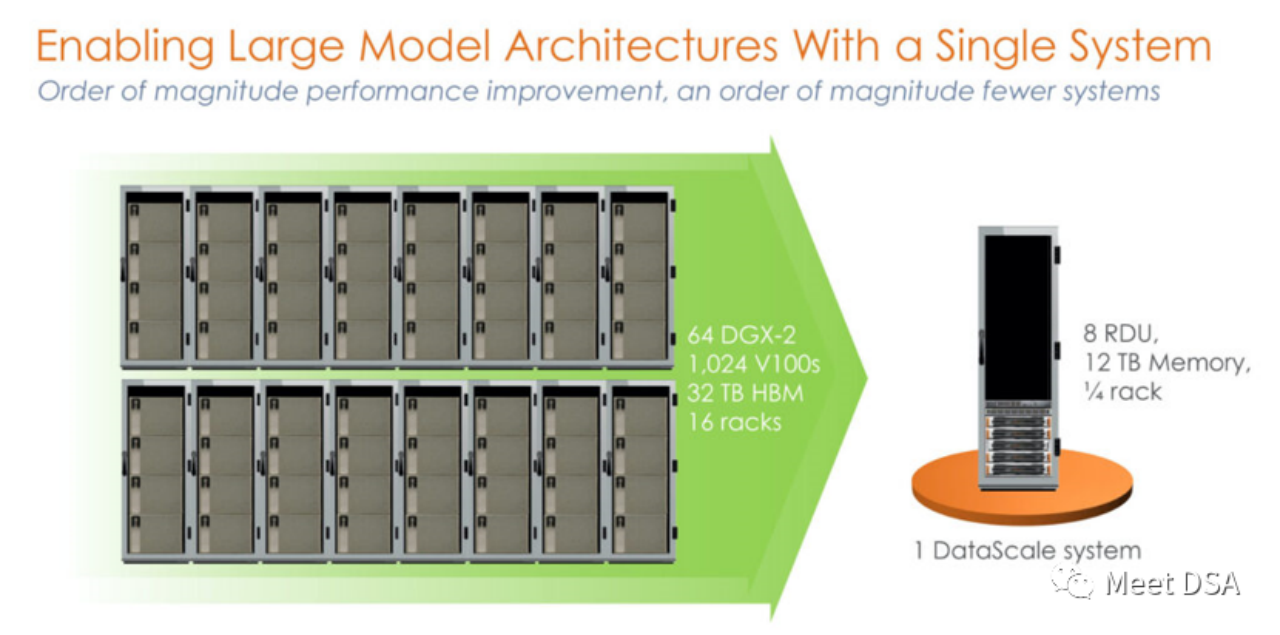
Bukankah ia agak mengejutkan? Kluster 1024 V100 yang dibina dengan kuasa yang tidak pernah berlaku sebelum ini pada platform NVIDIA sebenarnya bersamaan dengan mesin tunggal daripada SambaNova? ! Ini adalah produk generasi pertama, mesin 8 kad yang berdiri sendiri berdasarkan SN10 RDU.
Sesetengah orang mungkin mengatakan bahawa perbandingan ini tidak adil Bukankah NVIDIA mempunyai DGX A100 Mungkin SambaNova sendiri telah menyedarinya, dan produk generasi kedua SN30 telah ditukar kepada ini:

DGX A100 mempunyai pengkomputeran. kuasa 5 petaFLOPS , DataScale generasi kedua SambaNova juga mempunyai kuasa pengkomputeran sebanyak 5 petaFLOPS. Perbandingan memori 320GB HBM vs 8TB DDR4 (editor meneka bahawa dia mungkin telah salah menulis artikel, ia sepatutnya 3TB * 8).
Cip generasi kedua sebenarnya adalah versi Die-to-Die bagi SN10 RDU. Penunjuk seni bina SN10 RDU ialah: 320TFLOPS@BF16, 320M SRAM, 1.5T DDR4. SN30 RDU digandakan berdasarkan ini, seperti yang diterangkan di bawah:
“Cip ini mempunyai 640 unit pengiraan corak dengan lebih daripada 320 teraflop pengiraan pada ketepatan titik terapung BF16 dan juga mempunyai 640 unit memori corak dengan 320 MB SRAM pada cip dan 150 TB/saat lebar jalur memori pada cip Setiap pemproses SN10 juga dapat menangani 1.5 TB memori tambahan DDR4." "Dengan Cardinal SN30 RDU, kapasiti RDU digandakan, dan sebabnya adalah dua kali ganda. bahawa SambaNova mereka bentuk seni binanya untuk menggunakan pembungkusan berbilang mati dari permulaan, dan dalam kes ini SambaNova menggandakan kapasiti mesin DataScalenya dengan menjejalkan dua RDU baharu – apa yang kami duga ialah dua SN10 yang diubah suai dengan perubahan mikroarkitektur kepada menyokong model asas besar yang lebih baik – menjadi satu kompleks yang dipanggil SN30 Setiap soket dalam sistem DataScale kini mempunyai dua kali kapasiti pengiraan, dua kali ganda kapasiti memori tempatan dan dua kali lebar jalur memori bagi mesin generasi pertama.”
Key. mata diekstrak:Jalur lebar yang besar dan kapasiti besar hanya boleh dipilih daripada dua pilihan NVIDIA memilih HBM lebar jalur besar, manakala SambaNova memilih DDR4 berkapasiti besar. Dari segi keputusan prestasi, SambaNova menang.
Jika anda bertukar kepada DGX H100, walaupun anda bertukar kepada teknologi berketepatan rendah seperti FP8, anda hanya boleh mengecilkan jurang.
“Walaupun DGX-H100 menawarkan 3X prestasi pada pengiraan titik terapung 16-bit daripada DGX-A100, ia tidak akan menutup jurang dengan sistem SambaNova Walau bagaimanapun, dengan ketepatan data FP8 yang lebih rendah, Nvidia mungkin dapat menutup jurang prestasi; tidak jelas berapa banyak ketepatan yang akan dikorbankan dengan beralih kepada data dan pemprosesan ketepatan yang lebih rendah.”
Jika seseorang boleh mencapai kesan sedemikian, bukankah ia merupakan penyelesaian cip besar yang sempurna? Dan ia juga boleh terus menghadapi saingan daripada NVIDIA!
(Mungkin anda akan mengatakan bahawa CPU Grace juga boleh disambungkan ke LPDDR, yang membantu untuk meningkatkan kapasiti. Sebaliknya, bagaimana SambaNova melihat perkara ini: Grace hanyalah pengawal memori yang besar, tetapi ia hanya boleh membawa 512GB kepada Hopper. daripada DRAM, dan SN30 mempunyai 3TB DRAM
Kami pernah bergurau bahawa CPU Arm "Grace" Nvidia hanyalah pengawal memori yang berlebihan untuk GPU Hopper, dan dalam banyak kes ia sebenarnya hanyalah pengawal memori. Dan GPU Hopper dalam setiap pakej cip super Grace-Hopper hanya mempunyai maksimum 512GB memori Ini masih jauh kurang daripada 3TB memori yang disediakan oleh SambaNova setiap slot mungkin kena berhati-hati
tu
Xia He, tuan Huawei, baru-baru ini membuat spekulasi bahawa kelemahan empayar NVIDIA mungkin terletak pada kos setiap GB dari perspektif kos Dia mencadangkan susunan memori DDR murah untuk input/output dalaman berskala besar mungkin memberi impak revolusioner pada NVIDIA
(Sambungan://m.sbmmt.com/link/617974172720b96de92525536de581fa)
Dan seorang lagi ahli Zhihu, Mackler yang mengkaji, DSA. $/GBps (pergerakan data), HBM lebih menjimatkan kos kerana walaupun LLM mempunyai permintaan yang agak besar untuk kapasiti memori, ia juga mempunyai permintaan yang besar untuk lebar jalur memori. Latihan memerlukan sejumlah besar parameter yang perlu ditukar dalam DRAM . . pertimbangan teras!
Tetapi menurut pandangan Mackler, keperluan lebar jalur yang besar untuk pemindahan data juga menjadi masalah. Jadi bagaimana SambaNova menyelesaikannya?Anda perlu lebih memahami ciri-ciri seni bina RDU Sebenarnya, ia mudah difahami:
A ialah paradigma pertukaran data dalam seni bina GPU tradisional. cip DRAM untuk bertukar data Pertukaran bolak-balik Ini sepatutnya lebih mudah untuk memahami bahawa ia menduduki sejumlah besar lebar jalur DDR. B ialah apa yang boleh dicapai oleh seni bina SambaNova Semasa proses pengiraan model, sebahagian besar pergerakan data disimpan pada cip, dan tidak perlu berulang-alik ke DRAM untuk pertukaran. Oleh itu,
Jika anda boleh mencapai kesan seperti B, masalah memilih antara lebar jalur besar dan kapasiti besar, anda boleh memilih kapasiti besar dengan selamat. Ini adalah seperti petikan berikut:
“Persoalan yang kami ada ialah ini: Apakah yang lebih penting dalam seni bina memori hibrid yang menyokong model asas, kapasiti memori atau lebar jalur memori Anda tidak boleh mempunyai kedua-duanya berdasarkan teknologi memori tunggal? mana-mana seni bina, dan walaupun anda mempunyai gabungan kenangan yang pantas dan kurus serta lambat dan gemuk, di mana Nvidia dan SambaNova melukis garis adalah berbeza.”
Menghadapi NVIDIA yang berkuasa, kami bukan tanpa harapan! Walau bagaimanapun, mengikuti strategi GPGPU NVIDIA mungkin tidak dapat dilaksanakan. Nampaknya idea yang betul untuk cip besar ialah menggunakan DRAM kos rendah Dengan spesifikasi kuasa pengkomputeran yang sama, prestasi boleh mencapai lebih daripada 6 kali ganda daripada NVIDIA.
Bagaimanakah seni bina RDU/DataFlow SambaNova mencapai kesan B? Atau adakah cara lain untuk mencapai kesan yang serupa dengan B? Kami akan berkongsi dengan anda lain kali. Rakan-rakan yang berminat, sila teruskan memberi perhatian kepada kemas kini kami
Bahan bacaan lanjutan:
[1]https://sambanova.ai/blog/a-new- state-of-the-art-in-nlp-beyond-gpus/
[2]https://www.nextplatform.com/2022/09/17/sambanova-doubles-up-chips-to-chase -ai- foundation-models/
[3]https://hc33.hotchips.org/assets/program/conference/day2/SambaNova%20HotChips%202021%20Aug%2023%20v1.pdf
4]《MELATIH MODEL BAHASA BESAR DENGAN CEKAP DENGAN KESEPARAAN DAN ALIRAN DATA》[5]//m.sbmmt.com/link/617974172720b96de92525536de581family sepuluh ialah: [6]https ://www. php.cn/link/a56ee48e5c142c26cf645b2cc23d78fc
Atas ialah kandungan terperinci Bagaimanakah DSA mengatasi GPU NVIDIA di sudut?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyalin jadual Excel untuk menjadikannya saiz yang sama dengan yang asal
Bagaimana untuk menyalin jadual Excel untuk menjadikannya saiz yang sama dengan yang asal
 Cara menggunakan suis Java
Cara menggunakan suis Java
 Bagaimana untuk membaca fail teks dalam html
Bagaimana untuk membaca fail teks dalam html
 jquery mengesahkan
jquery mengesahkan
 Penggunaan item dalam python
Penggunaan item dalam python
 Bagaimana untuk menyelesaikan ralat http 503
Bagaimana untuk menyelesaikan ralat http 503
 Pengenalan kepada hubungan antara php dan front-end
Pengenalan kepada hubungan antara php dan front-end
 Pengenalan kepada kegunaan pengaturcaraan python
Pengenalan kepada kegunaan pengaturcaraan python








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



