


Dalam beberapa tahun kebelakangan ini, pra-latihan visual pada data dunia sebenar berskala besar telah mencapai kemajuan yang ketara, menunjukkan potensi besar dalam pembelajaran robot berasaskan pemerhatian piksel. Walau bagaimanapun, kajian ini berbeza dari segi data pra-latihan, kaedah dan model. Oleh itu, jenis data, kaedah dan model pralatihan yang manakah boleh membantu kawalan robot dengan lebih baik masih menjadi persoalan terbuka
Berdasarkan ini, penyelidik dari pasukan Penyelidikan ByteDance bermula daripada set data pra-latihan, seni bina model dan The tiga perspektif asas kaedah latihan mengkaji secara menyeluruh kesan strategi pra-latihan visual ke atas tugas pengendalian robot, dan menyediakan beberapa keputusan eksperimen penting yang bermanfaat kepada pembelajaran robot. Selain itu, mereka mencadangkan skim pra-latihan visi untuk pengendalian robot yang dipanggil Vi-PRoM, yang menggabungkan pembelajaran penyeliaan kendiri dan pembelajaran diselia. Yang pertama menggunakan pembelajaran kontrastif untuk mendapatkan corak terpendam daripada data tidak berlabel berskala besar, manakala yang kedua bertujuan untuk mempelajari semantik visual dan perubahan dinamik temporal. Sebilangan besar eksperimen operasi robot yang dijalankan dalam pelbagai persekitaran simulasi dan robot sebenar telah membuktikan keunggulan penyelesaian ini.

Data pra-latihan
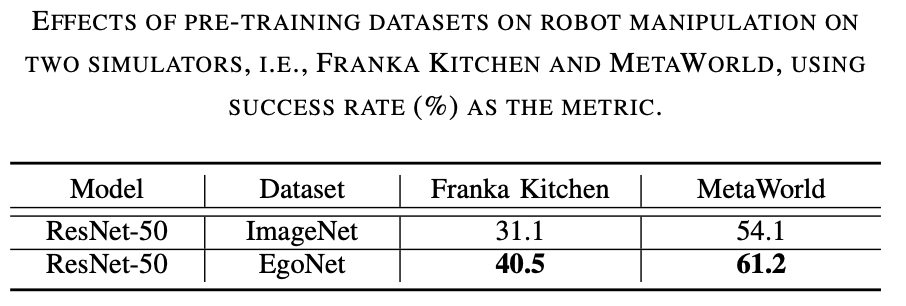
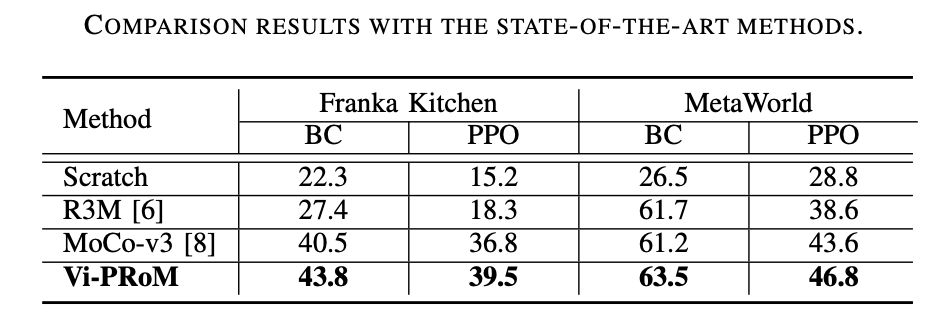
lebih berkuasa daripada ImageNet. Pralatih pengekod visual pada set data yang berbeza (iaitu, ImageNet dan EgoNet) melalui kaedah pembelajaran kontrastif dan perhatikan prestasinya dalam tugasan manipulasi robot. Seperti yang dapat dilihat daripada Jadual 1 di bawah, model yang telah dilatih pada EgoNet mencapai prestasi yang lebih baik pada tugas pengendalian robot. Jelas sekali, robot lebih suka pengetahuan interaktif dan hubungan temporal yang terkandung dalam video dari segi tugas pengendalian. Selain itu, imej semula jadi yang egosentrik dalam EgoNet mempunyai konteks yang lebih global tentang dunia, yang bermaksud ciri visual yang lebih kaya boleh dipelajari
Struktur model
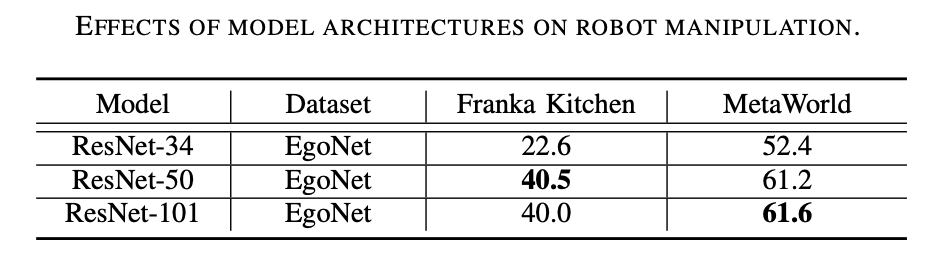
ResNet-50 berprestasi lebih baik. Seperti yang dapat dilihat daripada Jadual 2 di bawah, ResNet-50 dan ResNet-101 berprestasi lebih baik daripada ResNet-34 pada tugasan manipulasi robot. Tambahan pula, prestasi tidak bertambah baik apabila model meningkat daripada ResNet-50 kepada ResNet-101. . di bawah, MoCo-v3 berprestasi baik pada ImageNet dan data EgoNet adalah lebih baik daripada MAE pada semua set, yang membuktikan bahawa pembelajaran kontrastif adalah lebih berkesan daripada pemodelan imej topeng Selain itu, semantik visual yang diperoleh melalui pembelajaran kontrastif adalah lebih penting untuk pengendalian robot daripada maklumat struktur yang dipelajari melalui pemodelan imej topeng. Kandungan yang ditulis semula: Pembelajaran kontrastif adalah kaedah pra-latihan yang diutamakan. Seperti yang dapat dilihat daripada Jadual 3, MoCo-v3 mengatasi MAE pada kedua-dua set data ImageNet dan EgoNet, menunjukkan bahawa pembelajaran kontrastif adalah lebih berkesan daripada pemodelan imej topeng. Di samping itu, semantik visual yang diperolehi melalui pembelajaran kontrastif adalah lebih penting untuk operasi robot berbanding maklumat struktur yang dipelajari melalui pemodelan imej topeng
Pengenalan kepada algoritmaBerdasarkan penerokaan di atas, kajian ini mencadangkan Penyelesaian pra-latihan visi untuk operasi robot (Vi-PRoM). Penyelesaian ini mengekstrak perwakilan visual yang komprehensif bagi operasi robot dengan pra-latihan ResNet-50 pada set data EgoNet. Khususnya, kami mula-mula menggunakan pembelajaran kontrastif untuk mendapatkan corak interaksi antara orang dan objek daripada set data EgoNet melalui penyeliaan kendiri. Kemudian, dua objektif pembelajaran tambahan, iaitu ramalan semantik visual dan ramalan dinamik temporal, dicadangkan untuk memperkayakan lagi perwakilan pengekod. Rajah di bawah menunjukkan proses asas Vi-PROM. Terutama, kajian ini tidak memerlukan pelabelan manual untuk mempelajari semantik visual dan dinamik temporal
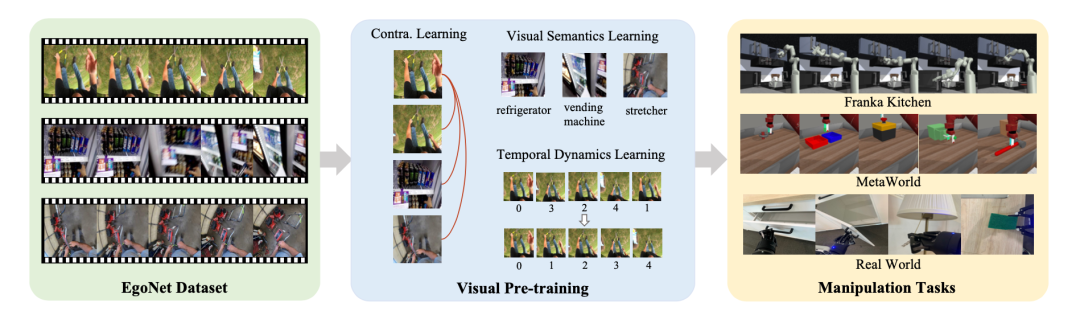
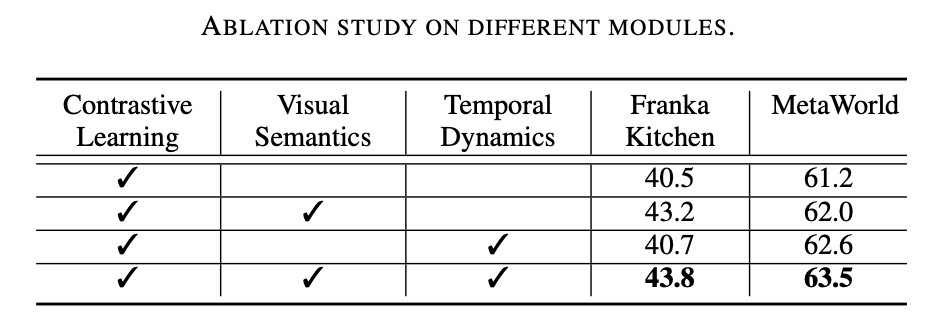
Kerja penyelidikan ini menjalankan eksperimen yang meluas pada dua persekitaran simulasi (Franka Kitchen dan MetaWorld). Keputusan eksperimen menunjukkan bahawa skim pra-latihan yang dicadangkan mengatasi kaedah terkini dalam pengendalian robot. Keputusan eksperimen ablasi ditunjukkan dalam jadual di bawah, yang dapat membuktikan kepentingan pembelajaran semantik visual dan pembelajaran dinamik temporal untuk pengendalian robot. Tambahan pula, apabila kedua-dua sasaran pembelajaran tidak hadir, kadar kejayaan Vi-PRoM menurun dengan ketara, menunjukkan keberkesanan kerjasama antara pembelajaran semantik visual dan pembelajaran dinamik temporal.
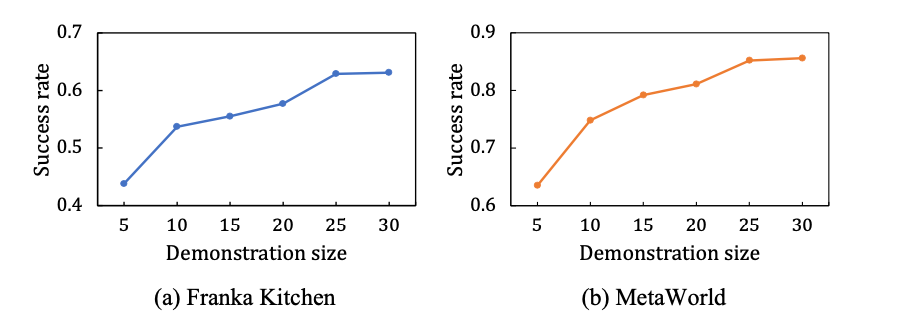
Karya ini juga mengkaji kebolehskalaan Vi-PRoM. Seperti yang ditunjukkan dalam rajah di bawah di sebelah kiri, dalam persekitaran simulasi Franka Kitchen dan MetaWorld, kadar kejayaan Vi-PRoM semakin bertambah baik apabila saiz data demo meningkat. Selepas latihan mengenai set data demonstrasi pakar yang lebih besar, model Vi-PRoM menunjukkan kebolehskalaannya pada tugas manipulasi robot.

Disebabkan keupayaan perwakilan visual Vi-PRoM yang berkuasa, robot sebenar boleh berjaya membuka laci dan pintu kabinet
hasil eksperimen Dapur
dapat dilihat PRoM Ia mempunyai kadar kejayaan yang lebih tinggi dan tahap penyelesaian tindakan yang lebih tinggi daripada R3M dalam lima tugasan.

 R3M:
R3M: 



 Vi-PROM:
Vi-PROM: 


Di MetaWorld, prestasi yang baik telah dipelajari kerana perwakilan visual Vi- PRoM Ciri semantik dan dinamik, ia boleh digunakan dengan lebih baik untuk ramalan tindakan, jadi berbanding R3M, Vi-PRoM memerlukan lebih sedikit langkah untuk menyelesaikan operasi. 🎜🎜🎜🎜R3M: 🎜🎜

Vi-PROM:


Atas ialah kandungan terperinci Tajuk yang ditulis semula: Byte melancarkan program pra-latihan visual Vi-PRoM untuk meningkatkan kadar dan kesan kejayaan operasi robot. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



