


Kami memasuki era baharu AI yang didorong oleh Model Bahasa Besar (LLM) memainkan peranan yang semakin penting dalam pelbagai aplikasi seperti perkhidmatan pelanggan, pembantu maya, penciptaan kandungan, bantuan pengaturcaraan, dll.
Walau bagaimanapun, apabila skala LLM terus berkembang, penggunaan sumber yang diperlukan untuk menjalankan model besar juga semakin meningkat, menyebabkan operasinya menjadi lebih perlahan dan lebih perlahan, yang membawa cabaran besar kepada pembangun aplikasi AI.
Untuk tujuan ini, Intel baru-baru ini melancarkan perpustakaan sumber terbuka model besar yang dipanggil BigDL-LLM[1], yang boleh membantu pembangun dan penyelidik AI mempercepatkan pengoptimuman model bahasa besar pada platform Intel ® dan menambah baik Pengalaman menggunakan model bahasa besar pada platform Intel ® .

Berikut menunjukkan 33 bilion parameter model bahasa besar Vicuna-33b-v1.3[2] yang dipercepatkan menggunakan BigDL-LLM pada mesin yang dilengkapi dengan Intel® Xeon8® Xeon
8®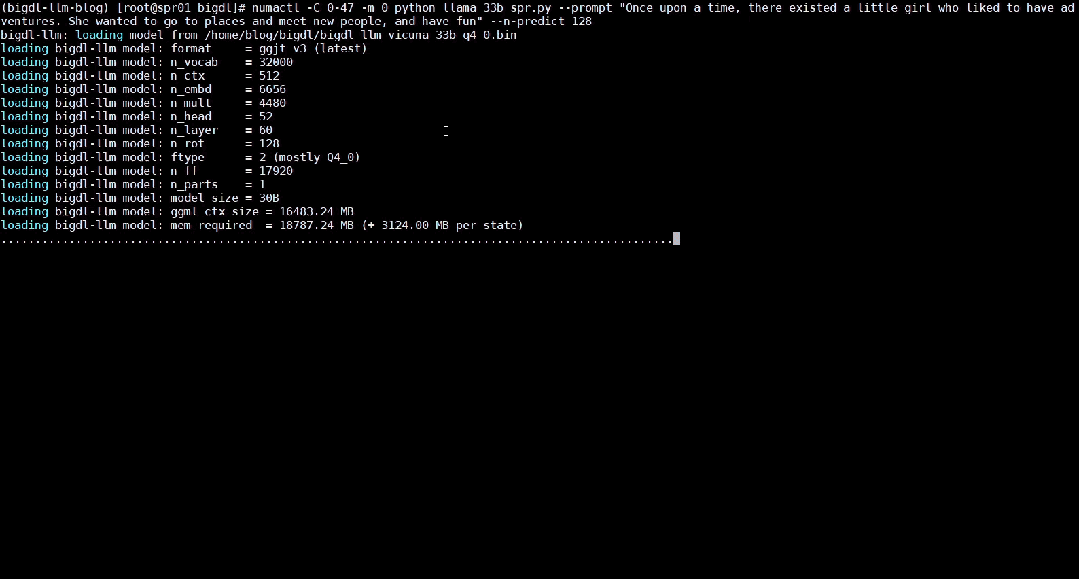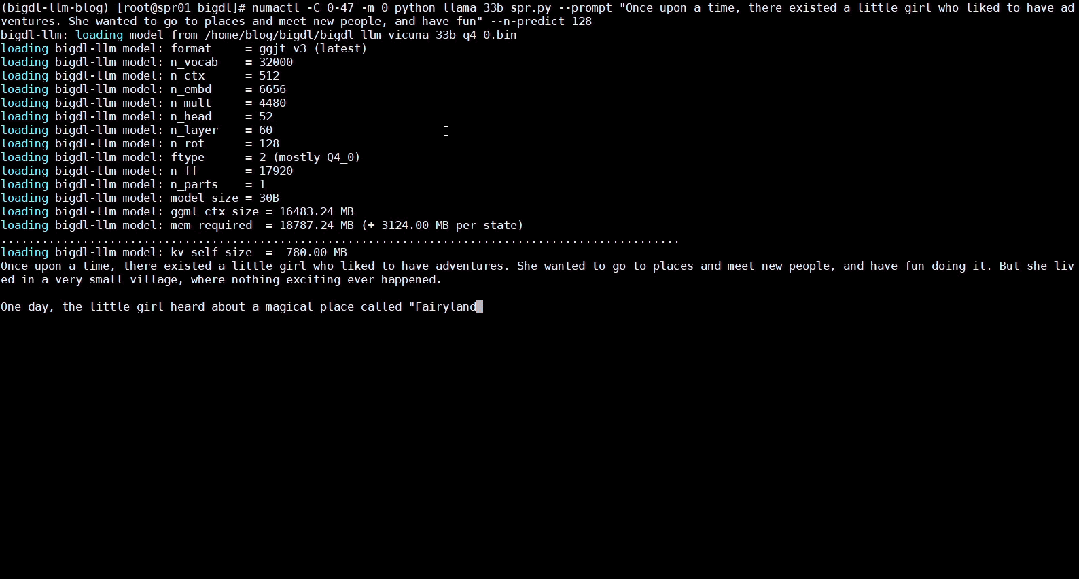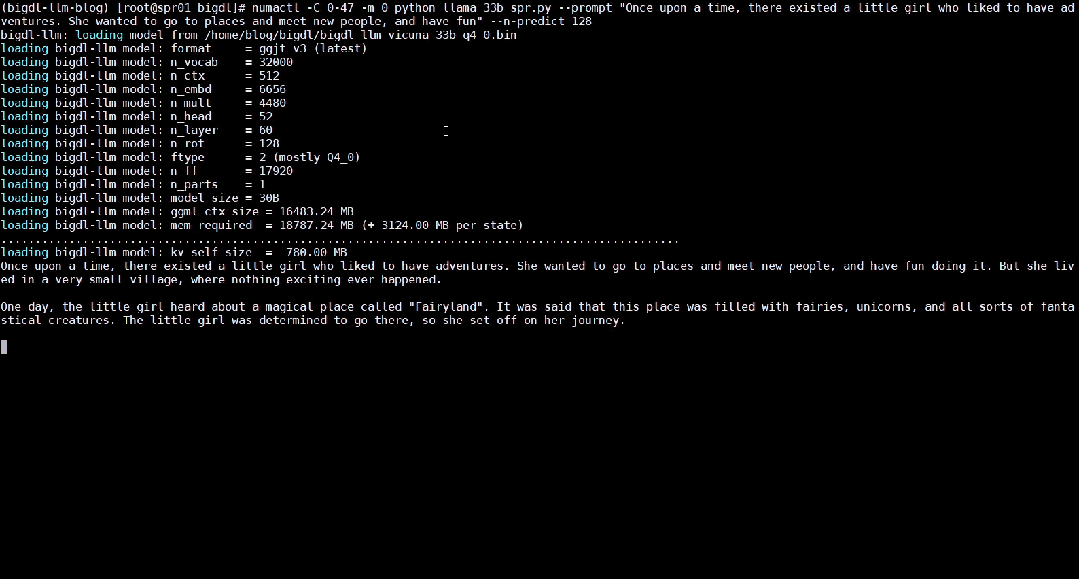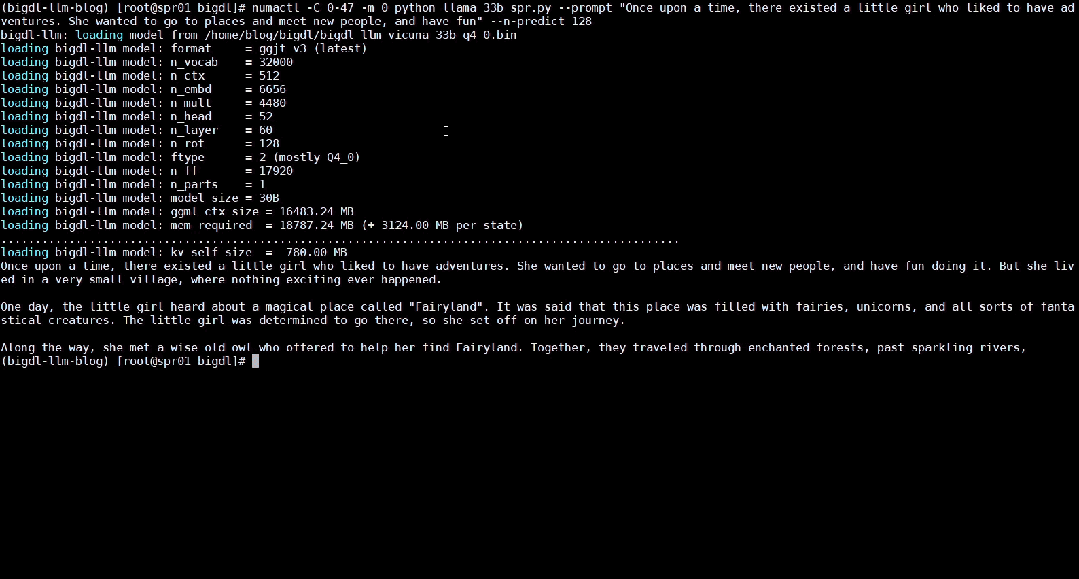
△Kelajuan sebenar menjalankan model bahasa besar parameter 33 bilion pada pelayan yang dilengkapi dengan pemproses Intel® Xeon
®: Intel
Pustaka pecutan model bahasa besar sumber terbuka pada platformBigDL-LLM ialah perpustakaan sumber terbuka yang memfokuskan pada pengoptimuman dan mempercepatkan model bahasa besar Ia adalah sebahagian daripada BigDL dan dikeluarkan di bawah lesen Apache 2.0Ia menyediakan pelbagai jenis bahasa rendah. tahap pengoptimuman Ketepatan (seperti INT4/INT5/INT8), dan boleh menggunakan pelbagai teknologi pecutan perkakasan bersepadu Intel
®CPU (AVX/VNNI/AMX, dsb.) dan pengoptimuman perisian terkini untuk memperkasakan model bahasa besar pada Intel® Mencapai pengoptimuman yang lebih cekap dan operasi yang lebih pantas pada platform. Ciri penting BigDL-LLM ialah untuk model berdasarkan Hugging Face Transformers API, anda hanya perlu menukar satu baris kod untuk mempercepatkan model Secara teori, ia boleh menyokong berjalan
sebarang model Transformers, yang berguna untuk mereka yang biasa dengan Transformers Pembangun API sangat mesra.
Selain API Transformers, ramai orang juga menggunakan LangChain untuk membangunkan aplikasi model bahasa yang besar. Untuk tujuan ini, BigDL-LLM juga menyediakan integrasi LangChain yang mudah digunakan
[3], membolehkan pembangun menggunakan BigDL-LLM dengan mudah untuk membangunkan aplikasi baharu atau memindahkan aplikasi sedia ada berdasarkan Transformers API atau LangChain API . Selain itu, untuk model bahasa besar PyTorch umum (model yang tidak menggunakan Transformer atau LangChain API), anda juga boleh menggunakan BigDL-LLM optimize_model API pecutan satu klik untuk meningkatkan prestasi. Untuk butiran, sila rujuk GitHub README[4] dan dokumentasi rasmi
[5]. BigDL-LLM juga menyediakan sejumlah besar sampel pecutan LLM sumber terbuka yang biasa digunakan (cth. sampel menggunakan Transformers API[6] dan sampel menggunakan LangChain API[7], serta tutorial (termasuk menyokong buku nota jupyter)
[8]Pemasangan dan penggunaan: Proses pemasangan yang ringkas dan antara muka API yang mudah digunakan
Sangat mudah untuk memasang BigDL-LLM, cuma jalankan perkara berikut arahan:
△pip install --pre --upgrade bigdl-llm[all]
Salin selepas log masuk
Ia juga sangat mudah untuk menggunakan BigDL-LLM untuk mempercepatkan model besar (di sini kami hanya menggunakan API gaya Transformers sebagai contoh)
Gunakan API gaya Transformer BigDL-LLM Untuk mempercepatkan model, anda hanya perlu menukar bahagian pemuatan model Proses penggunaan seterusnya adalah sama seperti Transformers asli menggunakan API BigDL-LLM hampir sama dengan API Transformers - pengguna hanya perlu menukar import dan menetapkannya dalam parameter from_pretrained load_in_4bit=True
BigDL-LLM akan melakukan 4-bit low-. kuantisasi ketepatan semasa proses pemuatan model, dan gunakan pelbagai teknologi pecutan perisian dan perkakasan untuk pengoptimuman semasa proses inferens berikutnya
#Load Hugging Face Transformers model with INT4 optimizationsfrom bigdl.llm. transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained('/path/to/model/', load_in_4bit=True)△ Jika kod tidak dipaparkan sepenuhnya, sila luncurkan ke kiri atau kanan
下文将以 LLM 常见应用场景“语音助手”为例,展示采用 BigDL-LLM 快速实现 LLM 应用的案例。通常情况下,语音助手应用的工作流程分为以下两个部分:
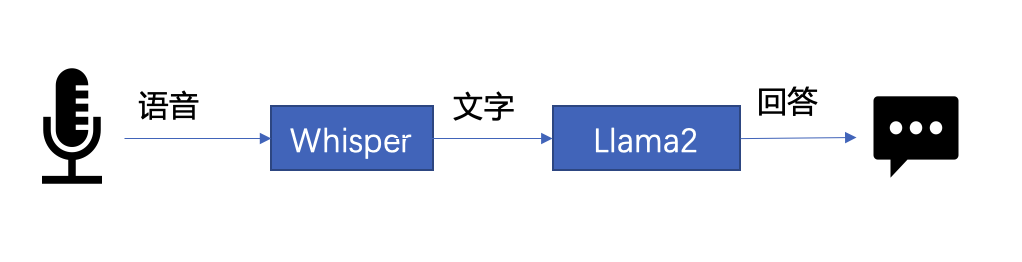
以下是本文使用 BigDL-LLM 和 LangChain[11] 来搭建语音助手应用的过程:
在语音识别阶段:第一步,加载预处理器 processor 和语音识别模型 recog_model。本示例中使用的识别模型 Whisper 是一个 Transformers 模型。
只需使用 BigDL-LLM 中的 AutoModelForSpeechSeq2Seq 并设置参数 load_in_4bit=True,就能够以 INT4 精度加载并加速这一模型,从而显著缩短模型推理用时。
#processor = WhisperProcessor .from_pretrained(recog_model_path)recog_model = AutoModelForSpeechSeq2Seq .from_pretrained(recog_model_path, load_in_4bit=True)
△若代码显示不全,请左右滑动
第二步,进行语音识别。首先使用处理器从输入语音中提取输入特征,然后使用识别模型预测 token,并再次使用处理器将 token 解码为自然语言文本。
input_features = processor(frame_data,sampling_rate=audio.sample_rate,return_tensor=“pt”).input_featurespredicted_ids = recogn_model.generate(input_features, forced_decoder_ids=forced_decoder_ids)text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
△若代码显示不全,请左右滑动
在文本生成阶段,首先使用 BigDL-LLM 的 TransformersLLM API 创建一个 LangChain 语言模型(TransformersLLM 是在 BigDL-LLM 中定义的语言链 LLM 集成)。
可以使用这个 API 来加载 Hugging Face Transformers 的任何模型
llm = TransformersLLM . from_model_id(model_id=llm_model_path,model_kwargs={"temperature": 0, "max_length": args.max_length, "trust_remote_code": True},)△若代码显示不全,请左右滑动
然后,创建一个正常的对话链 LLMChain,并将已经创建的 llm 设置为输入参数。
# The following code is complete the same as the use-casevoiceassistant_chain = LLMChain(llm=llm, prompt=prompt,verbose=True,memory=ConversationBufferWindowMemory(k=2),)
△若代码显示不全,请左右滑动
以下代码将使用一个链条来记录所有对话历史,并将其适当地格式化为大型语言模型的输入。这样,我们可以生成合适的回复。只需将识别模型生成的文本作为 "human_input" 输入即可。代码如下:
response_text = voiceassistant_chain .predict(human_input=text, stop=”\n\n”)
△若代码显示不全,请左右滑动
最后,将语音识别和文本生成步骤放入循环中,即可在多轮对话中与该“语音助手”交谈。您可访问底部 [12] 链接,查看完整的示例代码,并使用自己的电脑进行尝试。快用 BigDL-LLM 来快速搭建自己的语音助手吧!
黄晟盛是英特尔公司的资深架构师,黄凯是英特尔公司的AI框架工程师,戴金权是英特尔院士、大数据技术全球CTO和BigDL项目的创始人,他们都从事着与大数据和AI相关的工作
Atas ialah kandungan terperinci Gunakan BigDL-LLM untuk mempercepatkan berpuluh bilion parameter LLM inferens dengan serta-merta. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



