


Kuantiti pengaktifan, pemberat dan kecerunan kepada 4 bit, yang dijangka mempercepatkan latihan rangkaian saraf.
Walau bagaimanapun, kaedah latihan 4 digit sedia ada memerlukan format nombor tersuai, yang tidak disokong oleh perkakasan moden.
Baru-baru ini, pasukan Tsinghua Zhu Jun mencadangkan kaedah latihan Transformer yang menggunakan algoritma INT4 untuk melaksanakan semua pendaraban matriks.
Latihan dengan ketepatan INT4 ultra rendah adalah sangat mencabar. Untuk mencapai matlamat ini, penyelidik dengan teliti menganalisis struktur khusus pengaktifan dan kecerunan dalam Transformer dan mencadangkan pengkuantiti khusus untuk mereka.
Untuk penyebaran ke hadapan, para penyelidik mengenal pasti cabaran outlier dan mencadangkan quantizer Hadamard untuk menyekat outlier.
Untuk perambatan belakang, mereka mengeksploitasi keterukan struktur kecerunan dengan mencadangkan pembahagian bit, dan menggunakan teknik pensampelan pecahan untuk mengukur kecerunan dengan tepat.
Algoritma baharu ini mencapai ketepatan kompetitif pada pelbagai tugas, termasuk pemahaman bahasa semula jadi, terjemahan mesin dan klasifikasi imej.
Prototaip pengendali linear adalah 2.2 kali lebih pantas daripada pengendali serupa dalam FP16, dan kelajuan latihan meningkat sebanyak 35.1%. . Algoritma latihan INT 4
 Melatih rangkaian saraf sangat memerlukan pengiraan. Latihan menggunakan aritmetik ketepatan rendah (latihan terkuantiti sepenuhnya/FQT) dijangka meningkatkan kecekapan pengiraan dan ingatan.
Melatih rangkaian saraf sangat memerlukan pengiraan. Latihan menggunakan aritmetik ketepatan rendah (latihan terkuantiti sepenuhnya/FQT) dijangka meningkatkan kecekapan pengiraan dan ingatan.
Kaedah FQT menambah beberapa pengkuantiti dan nyahkuantisasi pada graf pengiraan ketepatan penuh asal, dan menggantikan operasi titik terapung yang lebih mahal dengan operasi titik terapung ketepatan rendah yang lebih murah.
Penyelidikan FQT bertujuan untuk mengurangkan ketepatan berangka latihan tanpa mengorbankan terlalu banyak kelajuan atau ketepatan penumpuan.
Latihan FP8 dilaksanakan dalam GPU Nvidia H100 dengan enjin Transformer, mempercepatkan latihan Transformer berskala besar. Ketepatan berangka latihan baru-baru ini telah menurun kepada 4 digit.
Walau bagaimanapun, kaedah latihan 4-bit ini tidak boleh digunakan terus untuk pecutan kerana ia memerlukan format nombor tersuai, yang tidak disokong oleh perkakasan moden.
Pertama sekali, pengkuantiti yang tidak boleh dibezakan dalam perambatan hadapan akan menjadikan keadaan kehilangan bergelombang, dan pengoptimum berasaskan kecerunan boleh jatuh ke dalam optimum setempat dengan mudah.
Kedua, kecerunan hanya dianggarkan dengan ketepatan yang rendah. Kecerunan yang tidak tepat seperti ini boleh melambatkan proses latihan dan juga menyebabkan latihan menjadi tidak stabil atau menyimpang.
Dalam kerja ini, para penyelidik mencadangkan algoritma latihan INT4 novel untuk Transformer.
Gambar
Semua operasi linear kos tinggi untuk latihan Transformer boleh ditulis dalam bentuk pendaraban matriks (MM).
Borang MM ini membolehkan kami mereka bentuk pengkuantiti yang lebih fleksibel, yang boleh menganggarkan pendaraban matriks FP32 dengan lebih baik dengan menggunakan struktur khusus pengaktifan, pemberat dan kecerunan dalam Transformer.
Kemajuan dalam bidang Random Numerical Linear Algebra (RandNLA) dieksploitasi sepenuhnya oleh pengkuantiti ini.
 Untuk penyebaran ke hadapan, penyelidik mendapati bahawa outlier dalam pengaktifan adalah sebab utama penurunan ketepatan.
Untuk penyebaran ke hadapan, penyelidik mendapati bahawa outlier dalam pengaktifan adalah sebab utama penurunan ketepatan.
Untuk menyekat outlier, mereka mencadangkan pengkuantiti Hadamard, yang mengkuantasikan versi transformasi matriks pengaktifan. Transformasi ini ialah matriks Hadamard pepenjuru blok, yang menyebarkan maklumat yang dibawa dalam outlier ke entri jiran matriks, dengan itu mengecilkan julat berangka outlier.
Untuk perambatan belakang, mereka mengeksploitasi ketersedian struktur kecerunan pengaktifan. Penyelidik mendapati bahawa sesetengah token mempunyai kecerunan yang sangat besar. Pada masa yang sama, kecerunan kebanyakan token lain adalah sangat seragam, malah lebih seragam daripada sisa terkuantasi kecerunan besar.
 Gambar
Gambar
Jadi daripada mengira semua kecerunan, adalah lebih baik untuk menyimpan sumber pengiraan untuk mengira sisa kecerunan yang lebih besar.
Untuk memanfaatkan kesederhanaan ini, penyelidik mencadangkan pembahagian bit, yang membahagikan kecerunan setiap token kepada 4 bit tinggi dan 4 bit rendah.
Kemudian, kecerunan yang paling bermaklumat dipilih melalui pensampelan skor leverage, yang merupakan teknik pensampelan penting RandNLA.
 Gambar
Gambar
Menggabungkan teknik pengkuantitian perambatan ke hadapan dan ke belakang, para penyelidik mencadangkan algoritma yang menggunakan INT4MM untuk melaksanakan semua operasi linear dalam Transformer, dan menilai algoritma untuk melatih Transformer, termasuk pelbagai tugasan semula jadi. pemahaman, menjawab soalan, terjemahan mesin dan klasifikasi imej.
Algoritma mereka mencapai ketepatan kompetitif atau lebih tinggi berbanding dengan algoritma latihan 4-bit sedia ada.
Tambahan pula, algoritma ini serasi dengan perkakasan kontemporari seperti GPU, kerana ia tidak memerlukan format nombor tersuai seperti FP4 atau format logaritma.
Pelaksanaan operator pengkuantitian prototaip + INT4 MM ini adalah 2.2 kali lebih pantas daripada garis dasar FP16MM dan meningkatkan kelajuan latihan sebanyak 35.1%.
Kaedah Latihan Kuantiti Penuh (FQT) mempercepatkan latihan dengan mengukur pengaktifan, pemberat, dan kecerunan semasa latihan tak linear rendah berketepatan, tak linear rendah. -aritmetik ketepatan.
Penyelidikan FQT telah mereka bentuk format berangka baru dan algoritma pengkuantitian yang boleh menganggarkan tensor ketepatan penuh dengan lebih baik.
Sempadan penyelidikan semasa ialah 4-bit FQT. FQT mencabar kerana julat kecerunan berangka yang besar dan masalah pengoptimuman untuk melatih rangkaian terkuantisasi dari awal.
Disebabkan cabaran ini, algoritma FQT 4-bit sedia ada masih mengalami kehilangan ketepatan 1-2.5% pada beberapa tugas dan tidak dapat menyokong perkakasan kontemporari.
 Gambar
Gambar
Menggaul pakar meningkatkan kapasiti model tanpa meningkatkan bajet latihan.
Keciciran struktur menggunakan kaedah pengiraan yang cekap untuk menyusun model. Perhatian yang cekap mengurangkan kerumitan masa kuadratik perhatian pengkomputeran.
Sistem latihan yang diedarkan mengurangkan masa latihan dengan menggunakan lebih banyak sumber pengkomputeran.
Kerja penyelidik untuk mengurangkan ketepatan berangka adalah ortogon dengan arah ini.
 Gambar
Gambar
Propagasi ke hadapan
Latihan rangkaian saraf ialah proses pengoptimuman berulang yang mengira kecerunan stokastik melalui perambatan ke hadapan dan ke belakang.
Pasukan penyelidik menggunakan algoritma integer 4-bit (INT4) untuk mempercepatkan perambatan ke hadapan dan ke belakang.
Rambatan ke hadapan boleh dilaksanakan dengan gabungan pengendali linear dan bukan linear (GeLU, normalization, softmax, dll.).
Semasa proses latihan kami, kami mempercepatkan semua operator linear dengan aritmetik INT4 dan mengekalkan semua operator tak linear yang lebih murah dari segi pengiraan dalam format titik terapung 16-bit (FP16).
Semua operasi linear dalam Transformer boleh ditulis dalam bentuk pendaraban matriks (MM).
Untuk memudahkan ungkapan, artikel ini mempertimbangkan pecutan pendaraban matriks mudah berikut:
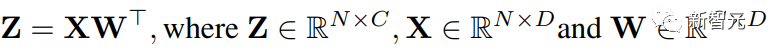 Gambar
Gambar
Kes penggunaan utama MM jenis ini ialah lapisan bersambung sepenuhnya.
Pertimbangkan Transformer yang bentuk inputnya (saiz kelompok S, panjang jujukan T, dimensi D).
Lapisan yang bersambung sepenuhnya boleh dinyatakan seperti formula di atas, di mana X ialah pengaktifan N = STtoken dan W ialah matriks berat.
Untuk lapisan perhatian, pendaraban matriks kelompok (BMMS) mungkin diperlukan.
Teknologi yang dicadangkan kami boleh digunakan untuk BMMS.
Untuk mempercepatkan latihan, operasi integer mesti digunakan untuk mengira perambatan ke hadapan.
Para penyelidik menggunakan Pengkuantiti Langkah Pembelajaran (LSQ) untuk tujuan ini.
LSQ ialah kuantisasi statiknya tidak bergantung pada kaedah input, jadi ia lebih murah daripada kaedah dinamik perlu mengira skala kuantisasi dalam setiap lelaran. .
Gambar Seperti yang ditunjukkan dalam gambar di atas, pengaktifan mempunyai beberapa entri outlier, yang bersaiz jauh lebih besar daripada entri lain.
Malangnya, Transformers cenderung untuk menyimpan maklumat dalam outlier ini, dan pemotongan sedemikian boleh menjejaskan ketepatan dengan serius.
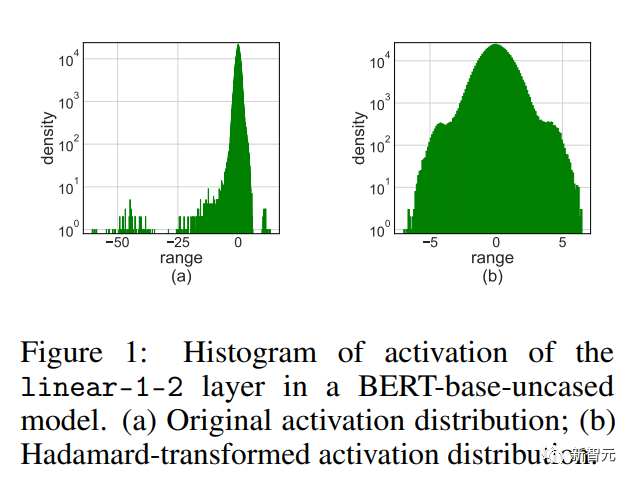 Masalah luar biasa amat ketara apabila tugas latihan adalah untuk memperhalusi model pra-latihan pada beberapa tugas hiliran baharu.
Masalah luar biasa amat ketara apabila tugas latihan adalah untuk memperhalusi model pra-latihan pada beberapa tugas hiliran baharu.
Oleh kerana model pra-latihan mengandungi lebih banyak outlier daripada permulaan rawak.
Hadamard Quantization
Kami mencadangkan Hadamard Quantization (HQ) untuk menyelesaikan masalah outlier.
Idea utama adalah untuk mengkuantisasi matriks lain dalam ruang linear dengan lebih sedikit outlier.
Ia biasanya tertumpu dalam beberapa dimensi, iaitu, hanya beberapa lajur dalam X adalah lebih besar daripada lajur lain.
Transformasi Hardamand ialah transformasi linear yang menyebarkan outlier kepada entri lain.
Backpropagation
Sekarang kami mempertimbangkan untuk menggunakan operasi INT4 untuk mempercepatkan backpropagation lapisan linear.
Kami akan membincangkan pengiraan kecerunan pengaktifan/kecerunan berat dalam bahagian ini.
Kekurangan struktur kecerunan
Kami mendapati bahawa matriks kecerunan cenderung sangat jarang semasa latihan.
Dan sparsity mempunyai struktur sedemikian: beberapa baris
Gambar
Kekurangan struktur ini terhasil daripada penparameteran berlebihan rangkaian saraf moden yang teruk.
 Rangkaian berjalan dalam skema hiperparameter hampir sepanjang proses latihan, dan kecuali beberapa contoh sukar, ia menyesuaikan diri dengan baik kepada kebanyakan data latihan.
Rangkaian berjalan dalam skema hiperparameter hampir sepanjang proses latihan, dan kecuali beberapa contoh sukar, ia menyesuaikan diri dengan baik kepada kebanyakan data latihan.
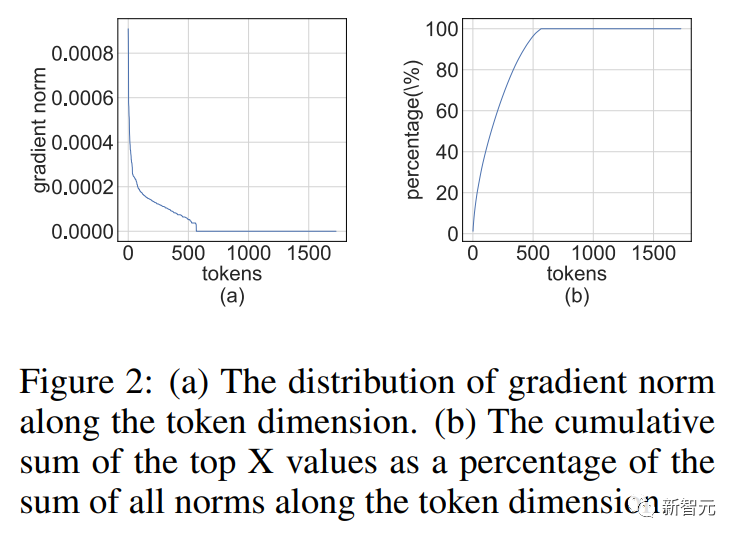 Jadi untuk titik data yang dipasang dengan baik, kecerunan (pengaktifan) akan menghampiri sifar.
Jadi untuk titik data yang dipasang dengan baik, kecerunan (pengaktifan) akan menghampiri sifar.
Penyelidik mendapati bahawa untuk tugasan pra-latihan, contohnya, keterlanjuran struktur muncul dengan cepat selepas beberapa tempoh latihan.
Untuk tugas penalaan halus, kecerunan sentiasa jarang sepanjang proses latihan.
Bagaimana untuk mereka bentuk pengkuantiti kecerunan untuk mengira MM dengan tepat semasa perambatan belakang menggunakan sparsity struktur?
Idea lanjutan ialah: banyak baris kecerunan adalah sangat kecil sehingga memberikan sedikit kesan pada kecerunan parameter, tetapi membazirkan banyak pengiraan.
Sebaliknya, bank besar tidak boleh diwakili dengan tepat oleh INT4.
Kami melepaskan beberapa baris kecil dan menggunakan kuasa pengkomputeran yang disimpan untuk mewakili baris besar dengan lebih tepat.
Eksperimen
Penyelidik menilai penalaan halus algoritma latihan INT4 kami pada pelbagai tugas termasuk model bahasa, terjemahan mesin dan klasifikasi imej.
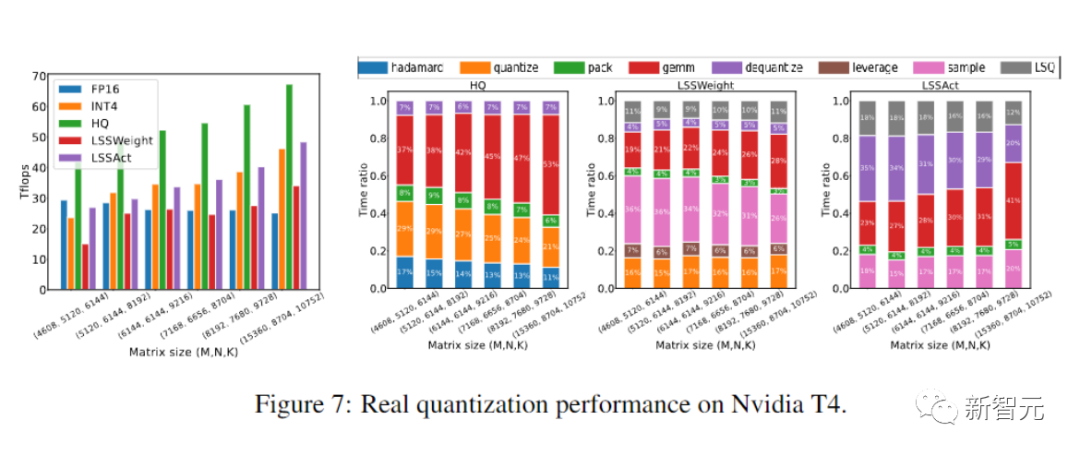
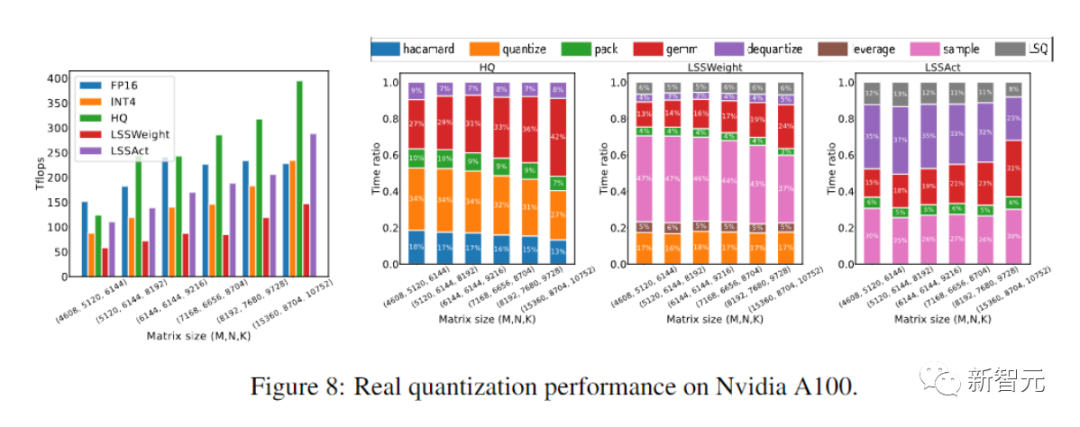
Para penyelidik melaksanakan algoritma HQ-MM dan LSS-MM yang dicadangkan mereka menggunakan CUDA dan cutlass.
Para penyelidik menggantikan semua pengendali linear titik terapung dengan pelaksanaan INT4, tetapi tidak hanya menggunakan LSQ untuk membenamkan lapisan dan mengekalkan ketepatan lapisan pengelas terakhir.
Akhirnya, penyelidik menggunakan seni bina lalai, pengoptimum, penjadual dan hiperparameter untuk semua model yang dinilai.
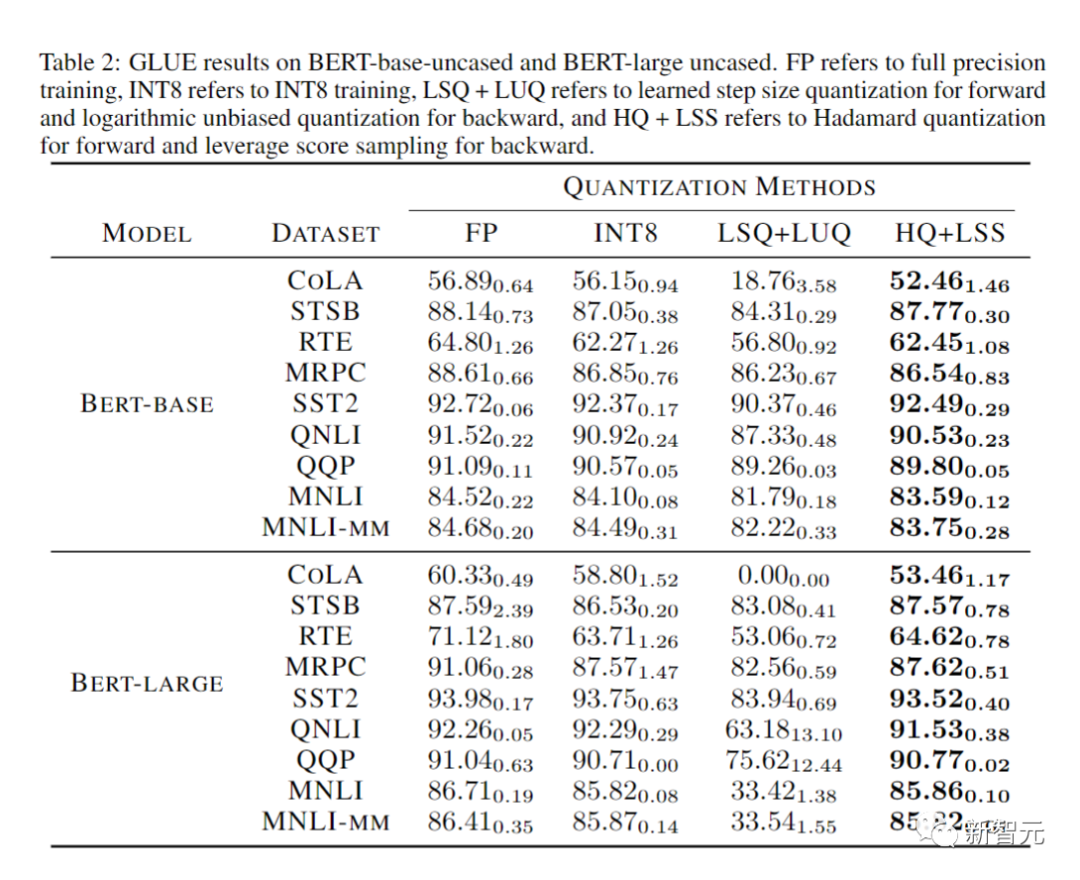
Para penyelidik membandingkan ketepatan model tertumpu pada pelbagai tugas dalam jadual di bawah.
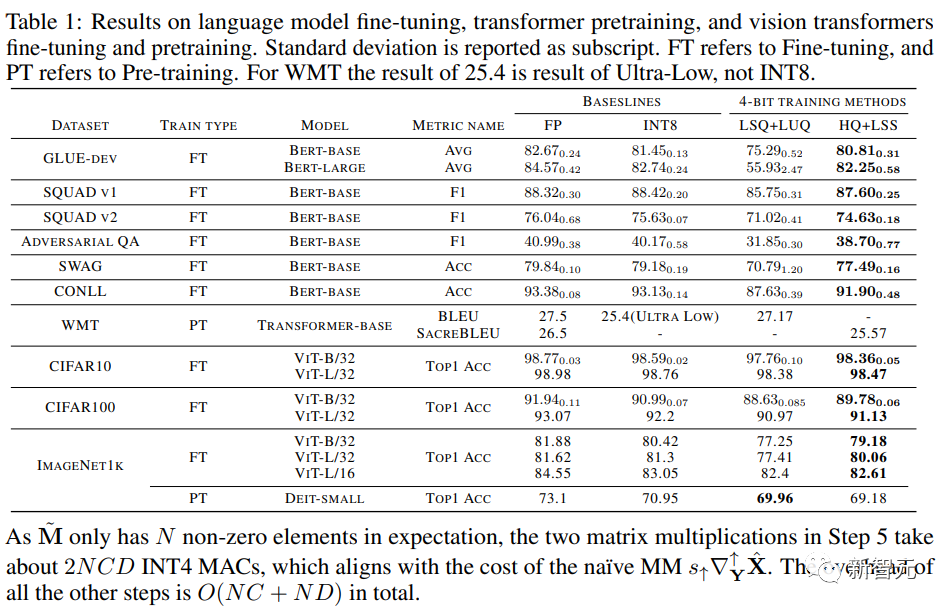 Gambar
Gambar
Sebagai perbandingan, kaedah termasuk latihan ketepatan penuh (FP), latihan INT8 (INT8), latihan FP4 ("ultra rendah"), menggunakan LSQ untuk pengaktifan dan pemberat (LSQ+LUQ) Pengkuantitian logaritma 4 bit dan algoritma kami yang menggunakan HQ untuk perambatan hadapan dan LSS untuk perambatan belakang (HQ+LSS).
"Ultra Low" tidak mempunyai pelaksanaan awam, jadi kami hanya menyenaraikan prestasinya dalam kertas asal mengenai tugas terjemahan mesin.
Kecuali untuk tugas terjemahan mesin yang besar dan tugas Transformer visual yang besar, kami mengulangi setiap larian tiga kali dan melaporkan sisihan piawai sebagai subskrip dalam jadual.
Para penyelidik tidak melakukan sebarang jenis penyulingan pengetahuan atau penambahan data.
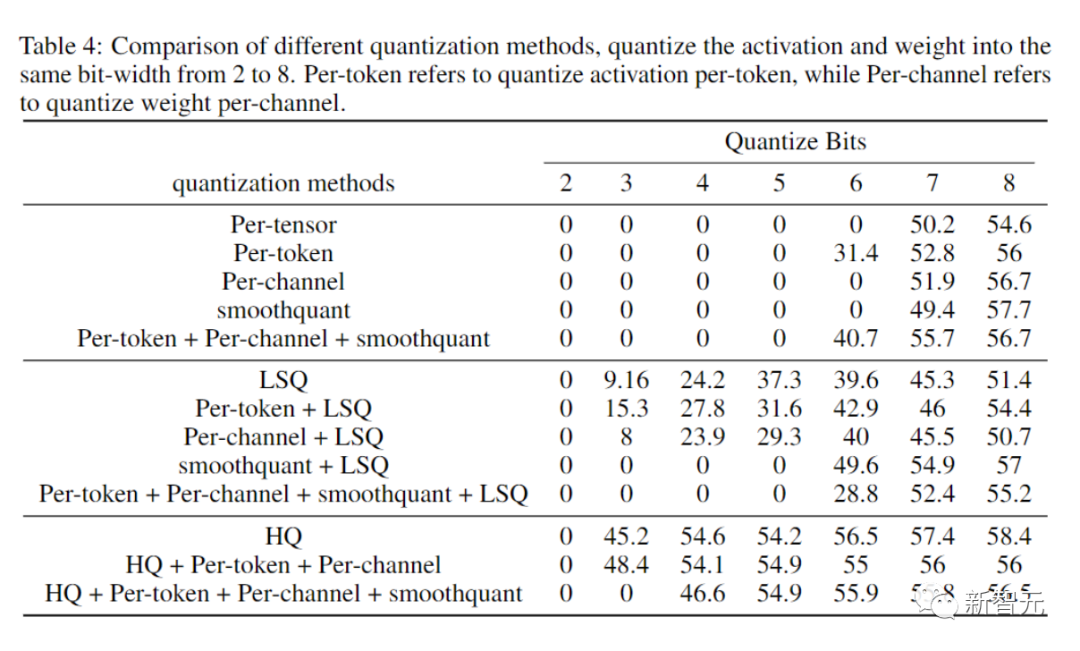
Tujuan eksperimen ablasi dijalankan oleh penyelidik adalah untuk menunjukkan keberkesanan kaedah ke hadapan dan ke belakang.
Untuk mengkaji keberkesanan perambatan ke hadapan untuk pengkuantiti yang berbeza, kami meninggalkan perambatan ke belakang dalam FP16.
Hasilnya ditunjukkan dalam gambar di bawah.
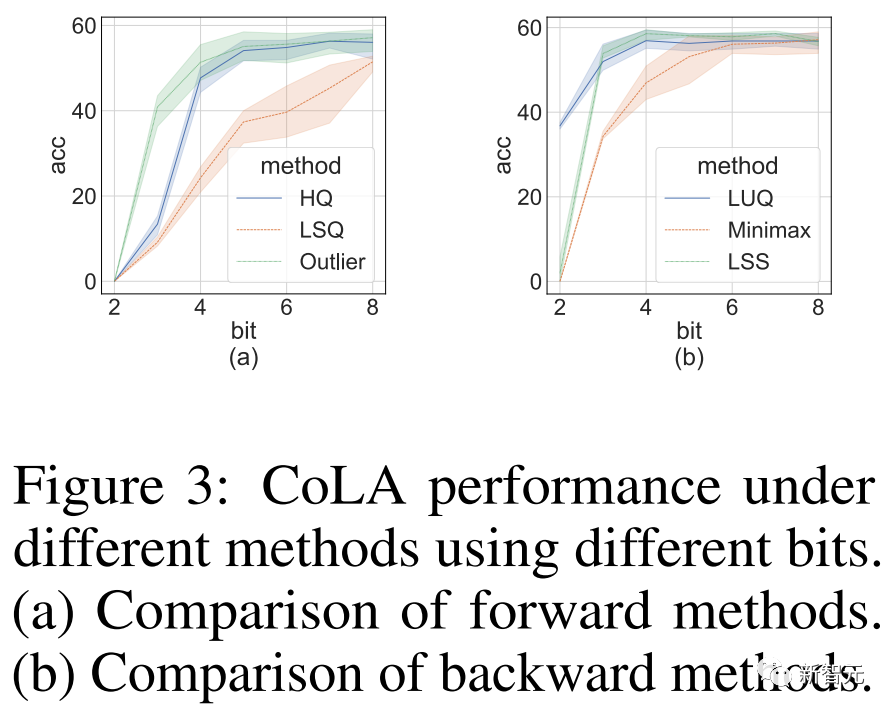 Gambar
Gambar
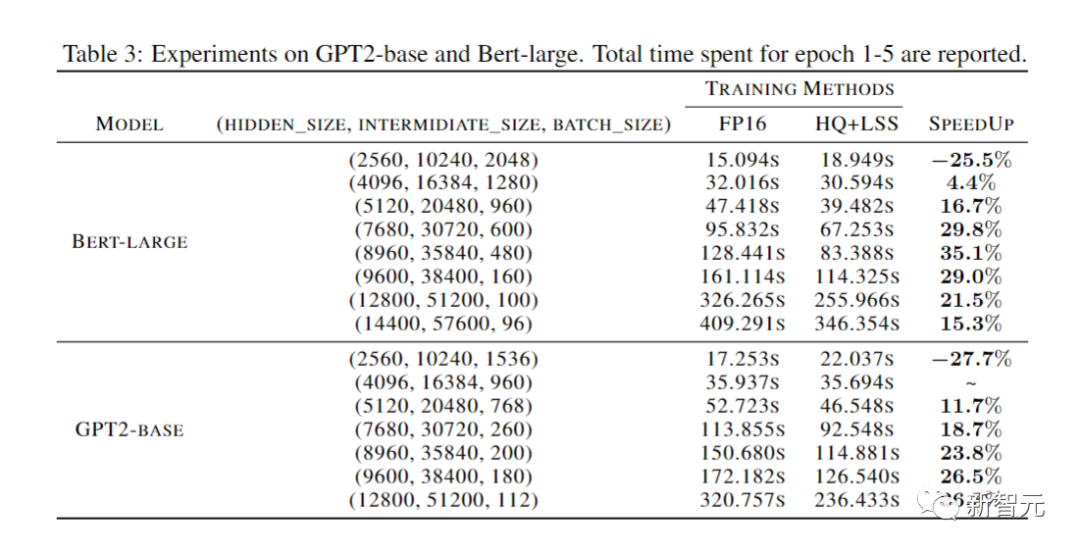
Akhirnya, penyelidik menunjukkan potensi pendekatan mereka untuk mempercepatkan latihan rangkaian saraf dengan menilai pelaksanaan prototaip mereka.
Dan pelaksanaannya masih belum dioptimumkan sepenuhnya.
Para penyelidik juga tidak menggabungkan operator linear dengan ketaklinearan dan normalisasi.
Oleh itu, keputusan tidak mencerminkan sepenuhnya potensi algoritma latihan INT4.
Pelaksanaan yang dioptimumkan sepenuhnya memerlukan kejuruteraan yang meluas dan di luar skop kertas kerja kami.
Para penyelidik mencadangkan kaedah latihan mesra perkakasan untuk Transformer INT4.
Dengan menganalisis sifat MM dalam Transformer, penyelidik mencadangkan kaedah HQ dan LSS untuk mengukur pengaktifan dan kecerunan sambil mengekalkan ketepatan.
Pada beberapa tugas penting, kaedah kami berfungsi dengan baik atau lebih baik daripada kaedah INT4 sedia ada.
Kerja penyelidik boleh diperluaskan kepada seni bina MM lain selain Transformers, seperti MLP-Mixer, rangkaian saraf graf dan rangkaian rangkaian saraf berulang.
Ini adalah hala tuju penyelidikan masa depan mereka.
Impak Lebih Luas: Algoritma penyelidik boleh meningkatkan kecekapan dan mengurangkan penggunaan tenaga bagi melatih rangkaian saraf, yang boleh membantu mengurangkan pelepasan karbon yang disebabkan oleh pembelajaran mendalam.
Walau bagaimanapun, algoritma latihan yang cekap juga boleh memudahkan pembangunan model bahasa yang besar dan aplikasi AI berniat jahat yang menimbulkan risiko keselamatan manusia.
Sebagai contoh, model dan aplikasi berkaitan yang akan digunakan untuk penjanaan kandungan palsu.
Keterbatasan: Keterbatasan utama kerja ini ialah ia hanya boleh mempercepatkan model besar dengan pendaraban matriks berskala lebih besar (lapisan linear), tetapi bukan lapisan konvolusi.
Selain itu, kaedah yang dicadangkan tidak sesuai untuk model yang sangat besar seperti OPT-175B.
Setahu kami, latihan INT8 pun masih menjadi masalah yang tidak dapat diselesaikan untuk model yang sangat besar ini.
Atas ialah kandungan terperinci Kerja baharu pasukan Zhu Jun di Universiti Tsinghua: Gunakan integer 4 digit untuk melatih Transformer, iaitu 2.2 kali lebih pantas daripada FP16, 35.1% lebih pantas, mempercepatkan ketibaan AGI!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Algoritma penggantian halaman
Algoritma penggantian halaman
 Apakah yang perlu saya lakukan jika imej CAD tidak boleh dialihkan?
Apakah yang perlu saya lakukan jika imej CAD tidak boleh dialihkan?
 Bagaimana untuk menyelesaikan kod kacau securecrt
Bagaimana untuk menyelesaikan kod kacau securecrt
 Cara membuat gambar bulat dalam ppt
Cara membuat gambar bulat dalam ppt
 Konfigurasikan fail HOSTS
Konfigurasikan fail HOSTS
 rgb kepada penukaran heksadesimal
rgb kepada penukaran heksadesimal
 Situasi biasa kegagalan indeks mysql
Situasi biasa kegagalan indeks mysql
 Koleksi lengkap tag HTML
Koleksi lengkap tag HTML








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



