


"Tetapi saya semakin tua, dan apa yang saya mahukan ialah penyelidik muda yang menjanjikan seperti anda untuk memikirkan bagaimana kita boleh memiliki superintelligence ini yang menjadikan hidup kita lebih baik, dan Tidak dikawal oleh mereka. "
Pada 10 Jun, dalam ucapan penutup Persidangan Sumber Pintar Beijing 2023, apabila bercakap tentang cara menghalang kecerdasan super daripada menipu dan mengawal manusia, Geoffrey Hinton, Turing yang berusia 75 tahun Pemenang anugerah tahun ini, berkata dengan penuh emosi.
Ucapan Hinton kali ini bertajuk "Two Paths to Intelligence" iaitu pengiraan abadi yang dilakukan dalam bentuk digital dan pengiraan abadi yang bergantung kepada perkakasan, masing-masing diwakili oleh komputer digital dan otak manusia. Di akhir ucapan, beliau menumpukan perhatian terhadap ancaman superintelligence yang dibawa oleh model bahasa besar (LLM) terhadap topik yang melibatkan masa depan tamadun manusia ini, beliau secara langsung menunjukkan sikap pesimisnya.
Pada permulaan ucapannya, Hinton mendakwa bahawa superintelligence mungkin dilahirkan lebih awal daripada yang pernah difikirkannya. Pemerhatian ini menimbulkan dua persoalan utama: (1) Adakah tahap kecerdasan rangkaian saraf tiruan tidak lama lagi akan mengatasi rangkaian saraf sebenar? (2) Bolehkah manusia menjamin kawalan AI super? Dalam ucapannya di persidangan itu, beliau membincangkan soalan pertama secara terperinci mengenai soalan kedua, Hinton berkata pada akhir ucapannya: Superintelligence mungkin akan datang tidak lama lagi.

Pertama, mari kita lihat kaedah pengiraan tradisional. Prinsip reka bentuk komputer adalah untuk dapat melaksanakan arahan dengan tepat, yang bermaksud bahawa jika kita menjalankan program yang sama (sama ada rangkaian saraf atau tidak) pada perkakasan yang berbeza, kesannya harus sama. Ini bermakna bahawa pengetahuan yang terkandung dalam program (seperti berat rangkaian saraf) adalah abadi dan tiada kaitan dengan perkakasan tertentu.

Untuk mencapai keabadian pengetahuan, pendekatan kami adalah untuk menjalankan transistor pada kuasa tinggi supaya ia boleh secara digital ) untuk beroperasi dengan pasti. Tetapi dengan berbuat demikian, kita sama dengan meninggalkan sifat perkakasan lain, seperti analog yang kaya dan kebolehubahan yang tinggi.

Sebab mengapa komputer tradisional menggunakan corak reka bentuk itu adalah kerana program yang menjalankan pengkomputeran tradisional semuanya ditulis oleh manusia. Kini dengan perkembangan teknologi pembelajaran mesin, komputer mempunyai cara lain untuk mendapatkan program dan matlamat tugas: pembelajaran berasaskan sampel.
Paradigma baharu ini membolehkan kami meninggalkan salah satu prinsip paling asas reka bentuk sistem komputer sebelum ini, iaitu, pengasingan reka bentuk perisian dan perkakasan sebaliknya, kami boleh reka bentuk perisian dan perkakasan.
Kelebihan reka bentuk pemisahan perisian dan perkakasan ialah program yang sama boleh dijalankan pada banyak perkakasan yang berbeza Pada masa yang sama, kita hanya boleh melihat perisian semasa mereka bentuk program, tidak kira perkakasan - ini juga komputer Sebab Jabatan Sains dan Jabatan Kejuruteraan Elektronik boleh ditubuhkan secara berasingan.
Bagi reka bentuk bersama perisian dan perkakasan, Hinton mencadangkan konsep baharu: Pengiraan Mortal. Sepadan dengan bentuk perisian abadi yang disebutkan di atas, yang kami terjemahkan di sini sebagai "pengkomputeran abadi".

Pengkomputeran abadi melepaskan keabadian menjalankan perisian yang sama pada perkakasan berbeza dan memihak kepada pemikiran Reka bentuk baharu: Pengetahuan adalah tidak dapat dipisahkan daripada butiran fizikal khusus perkakasan. Idea baru ini secara semula jadi mempunyai kelebihan dan kekurangannya. Kelebihan utama termasuk penjimatan tenaga dan kos perkakasan yang rendah.
Dari segi penjimatan tenaga, kita boleh merujuk kepada otak manusia, iaitu peranti pengkomputeran fana yang tipikal. Walaupun masih terdapat pengiraan digital satu-bit dalam otak manusia, iaitu neuron sama ada menyala atau tidak menyala, secara keseluruhannya, sebahagian besar pengiraan dalam otak manusia adalah pengiraan analog dengan penggunaan kuasa yang sangat rendah.
Pengkomputeran fana juga boleh menggunakan perkakasan kos yang lebih rendah. Berbanding dengan pemproses hari ini, yang dihasilkan dengan ketepatan tinggi dalam model dua dimensi, perkakasan pengkomputeran abadi boleh "dibesarkan" dalam model tiga dimensi kerana kita tidak perlu mengetahui dengan tepat bagaimana perkakasan disambungkan dan tepat. fungsi setiap komponen. Adalah jelas bahawa untuk mencapai "pertumbuhan" perkakasan pengkomputeran, kita memerlukan banyak teknologi nano baharu atau keupayaan untuk mengubah suai neuron biologi secara genetik. Kaedah kejuruteraan neuron biologi mungkin lebih mudah untuk dilaksanakan kerana kita sudah tahu bahawa neuron biologi secara kasar boleh melakukan tugas yang kita mahu.
Untuk menunjukkan keupayaan pengiraan simulasi yang cekap, Hinton memberikan contoh: mengira hasil darab vektor aktiviti saraf dan matriks berat (kebanyakan kerja rangkaian saraf adalah pengiraan sedemikian ) .

Untuk tugasan ini, pendekatan komputer semasa ialah menggunakan transistor berkuasa tinggi untuk menukar nilai ke Diwakili dalam bentuk bit berdigit, operasi berangka O (n²) kemudiannya dilakukan untuk mendarab dua nilai n-bit. Walaupun ini hanyalah operasi tunggal pada komputer, ia adalah operasi bit n².
Dan bagaimana jika pengiraan simulasi digunakan? Kita boleh memikirkan aktiviti saraf sebagai voltan dan berat sebagai konduktans; kemudian dalam setiap unit masa, voltan yang didarab dengan konduktans boleh mendapat caj, dan caj boleh ditindih. Kecekapan tenaga cara kerja ini akan menjadi lebih tinggi, dan sebenarnya, cip yang berfungsi dengan cara ini sudah wujud. Malangnya, Hinton berkata, orang ramai masih perlu menggunakan penukar yang sangat mahal untuk menukar hasil analog ke dalam bentuk digital. Beliau berharap pada masa akan datang kami dapat menyelesaikan keseluruhan proses pengiraan dalam bidang simulasi.
Pengkomputeran yang mematikan juga menghadapi beberapa masalah, yang paling penting adalah sukar untuk memastikan ketekalan keputusan, iaitu, hasil pengiraan pada perkakasan yang berbeza mungkin berbeza. Di samping itu, kita perlu mencari kaedah baru apabila penyebaran balik tidak tersedia.
Apabila belajar melakukan pengkomputeran yang boleh rosak pada perkakasan tertentu, anda perlu membiarkan program belajar mengeksploitasi perkakasan khusus sifat simulasi, tetapi mereka tidak perlu mengetahui sifat tersebut. Sebagai contoh, mereka tidak perlu mengetahui cara neuron disambungkan secara dalaman, atau fungsi apa yang menghubungkan input dan output neuron.

Ini bermakna kita tidak boleh menggunakan algoritma perambatan belakang untuk mendapatkan kecerunan kerana sebaliknya Penyebaran memerlukan model penyebaran ke hadapan yang tepat.
Jadi oleh kerana perambatan belakang tidak boleh digunakan dalam pengiraan boleh hapus, apakah yang perlu kita lakukan? Mari kita lihat proses pembelajaran mudah yang dilakukan pada perkakasan simulasi menggunakan kaedah yang dipanggil gangguan berat.

Pertama, hasilkan vektor rawak yang terdiri daripada gangguan rawak kecil untuk setiap pemberat dalam rangkaian. Kemudian, berdasarkan satu atau sebilangan kecil sampel, perubahan fungsi objektif global selepas menggunakan vektor gangguan ini diukur. Akhir sekali, mengikut penambahbaikan fungsi objektif, kesan yang dibawa oleh vektor gangguan adalah berkadar kekal dengan berat.
Kelebihan algoritma ini ialah corak tingkah laku amnya konsisten dengan perambatan belakang dan juga mengikut kecerunan. Tetapi masalahnya ialah ia mempunyai varians yang sangat tinggi. Oleh itu, apabila saiz rangkaian bertambah, hingar yang dijana semasa memilih arah pergerakan rawak dalam ruang berat akan menjadi besar, menjadikan kaedah ini tidak mampan. Ini bermakna kaedah ini hanya sesuai untuk rangkaian kecil dan bukan untuk rangkaian besar.

Pendekatan lain ialah gangguan aktiviti, yang mempunyai isu yang sama tetapi juga berfungsi lebih baik dengan rangkaian yang lebih besar.

Kaedah gangguan aktiviti adalah untuk melakukan vektor rawak pada input keseluruhan setiap neuron Perturb, kemudian perhatikan perubahan dalam fungsi objektif di bawah sekumpulan kecil sampel, dan kemudian hitung cara menukar berat neuron untuk mengikut kecerunan.
Gangguan aktiviti adalah kurang bising berbanding gangguan berat badan. Dan kaedah ini sudah cukup untuk mempelajari tugas mudah seperti MNIST. Jika anda menggunakan kadar pembelajaran yang sangat kecil, maka ia berkelakuan sama seperti perambatan balik, tetapi lebih perlahan. Jika kadar pembelajaran besar, akan ada banyak bunyi, tetapi ia cukup untuk mengendalikan tugas seperti MNIST.
Tetapi bagaimana jika skala rangkaian kita lebih besar? Hinton menyebut dua pendekatan.
Kaedah pertama ialah menggunakan sejumlah besar fungsi objektif, iaitu, bukannya menggunakan satu fungsi untuk menentukan matlamat rangkaian saraf yang besar, sejumlah besar fungsi digunakan untuk menentukan neuron yang berbeza dalam rangkaian Matlamat tempatan kumpulan.

Dengan cara ini, rangkaian saraf yang besar dipecahkan kepada beberapa bahagian, dan kita boleh Belajar rangkaian neural berbilang lapisan kecil menggunakan gangguan aktiviti. Tetapi di sini timbul persoalan: dari mana datangnya fungsi objektif ini?

Satu kemungkinan ialah menggunakan jubin tempatan tanpa pengawasan pada tahap pembelajaran Perbandingan yang berbeza. Ia berfungsi seperti ini: tampung tempatan mempunyai berbilang peringkat perwakilan, dan pada setiap peringkat, tampung tempatan cuba konsisten dengan perwakilan purata yang dihasilkan oleh semua tampung tempatan lain bagi imej yang sama pada masa yang sama, Cuba untuk kekal berbeza daripada perwakilan imej lain pada tahap itu.
Hinton berkata pendekatan itu berfungsi dengan baik dalam amalan. Pendekatan umum adalah untuk mempunyai berbilang lapisan tersembunyi untuk setiap peringkat perwakilan, supaya operasi bukan linear boleh dilakukan. Tahap ini menggunakan gangguan aktiviti untuk pembelajaran tamak dan tidak menyebar ke tahap yang lebih rendah. Memandangkan ia tidak boleh melepasi seberapa banyak lapisan sebagai rambatan belakang, ia tidak akan sekuat rambatan belakang.
Malah, ini adalah salah satu hasil penyelidikan paling penting pasukan Hinton dalam beberapa tahun kebelakangan ini, sila rujuk laporan Heart of the Machine "Selepas melepaskan penyebaran balik, Geoffrey Hinton mengambil bahagian dalam penyelidikan penting sebelum ini mengenai pembelajaran daripada kecerunan akan datang."

Mengye Ren telah menunjukkan melalui banyak penyelidikan bahawa kaedah ini sebenarnya boleh berkesan dalam rangkaian saraf, tetapi ia adalah sangat sukar untuk dikendalikan. Ia adalah rumit, dan kesan sebenar tidak dapat bersaing dengan perambatan belakang. Jika kedalaman rangkaian besar lebih dalam, jurang dengan perambatan belakang akan menjadi lebih besar.
Hinton berkata bahawa algoritma pembelajaran yang boleh memanfaatkan sifat simulasi ini hanya boleh dikatakan OK, cukup untuk mengendalikan tugas seperti MNIST, tetapi ia tidak begitu mudah untuk digunakan, seperti pada tugas ImageNet Prestasinya tidak begitu baik.
Satu lagi masalah utama yang dihadapi oleh pengkomputeran mudah rosak ialah kesukaran untuk memastikan pewarisan ilmu. Oleh kerana pengkomputeran mudah rosak sangat bergantung kepada perkakasan, pengetahuan tidak boleh disalin dengan menyalin pemberat, yang bermaksud apabila sekeping perkakasan tertentu "mati", pengetahuan yang dipelajarinya hilang bersamanya.
Hinton berkata cara terbaik untuk menyelesaikan masalah adalah dengan memindahkan pengetahuan kepada pelajar sebelum perkakasan "mati." Kaedah jenis ini dipanggil penyulingan pengetahuan, konsep yang pertama kali dicadangkan oleh Hinton dalam kertas kerja 2015 "Menyuling Pengetahuan dalam Rangkaian Neural" yang dikarang bersama Oriol Vinyals dan Jeff Dean.

Idea asas konsep ini sangat mudah, sama seperti guru mengajar pelajar pengetahuan: guru menunjukkan kepada pelajar jawapan yang betul untuk input yang berbeza, dan pelajar mencuba Model respons guru.
Hinton menggunakan tweet bekas Presiden A.S. Trump sebagai contoh untuk memberikan penjelasan intuitif: Trump sering membuat komen yang sangat emosional tentang pelbagai peristiwa apabila dia tweet Sebagai tindak balas, ini menyebabkan pengikutnya berubah "rangkaian saraf" mereka untuk menghasilkan tindak balas emosi yang sama; dengan cara ini, Trump menyaring prasangka ke dalam fikiran pengikutnya, sama seperti - Hinton jelas tidak Tidak suka Trump.
Sejauh manakah keberkesanan kaedah penyulingan pengetahuan? Memandangkan ramai penyokong Trump, kesannya tidak sepatutnya buruk. Hinton menggunakan contoh untuk menerangkan: Katakan ejen perlu mengelaskan imej kepada 1024 kategori tidak bertindih.

Untuk mengenal pasti jawapan yang betul, kami hanya memerlukan 10 bit maklumat. Oleh itu, untuk melatih ejen mengenal pasti sampel tertentu dengan betul, hanya 10 bit maklumat perlu disediakan untuk mengekang beratnya.
Tetapi bagaimana jika kita melatih ejen untuk mempunyai kebarangkalian yang hampir sama dengan seorang guru dalam 1024 kategori ini? Iaitu, jadikan taburan kebarangkalian ejen sama dengan guru. Taburan kebarangkalian ini mempunyai 1023 nombor nyata, dan jika kebarangkalian ini tidak terlalu kecil, ia memberikan kekangan beratus kali ganda.

Untuk memastikan kebarangkalian ini tidak terlalu kecil, guru boleh dijalankan di "suhu tinggi" semasa latihan Pelajar juga dijalankan pada "suhu tinggi" semasa mereka pelajar. Sebagai contoh, jika anda menggunakan logit, itu adalah input kepada softmax. Bagi guru, mereka boleh menskalakannya berdasarkan parameter suhu untuk mendapatkan taburan yang lebih lembut kemudian menggunakan suhu yang sama semasa melatih pelajar.
Mari kita lihat contoh khusus. Di bawah adalah beberapa imej watak 2 daripada set latihan MNIST, sepadan dengan sebelah kanan adalah kebarangkalian yang diberikan oleh guru kepada setiap imej apabila suhu di mana guru dijalankan adalah tinggi.
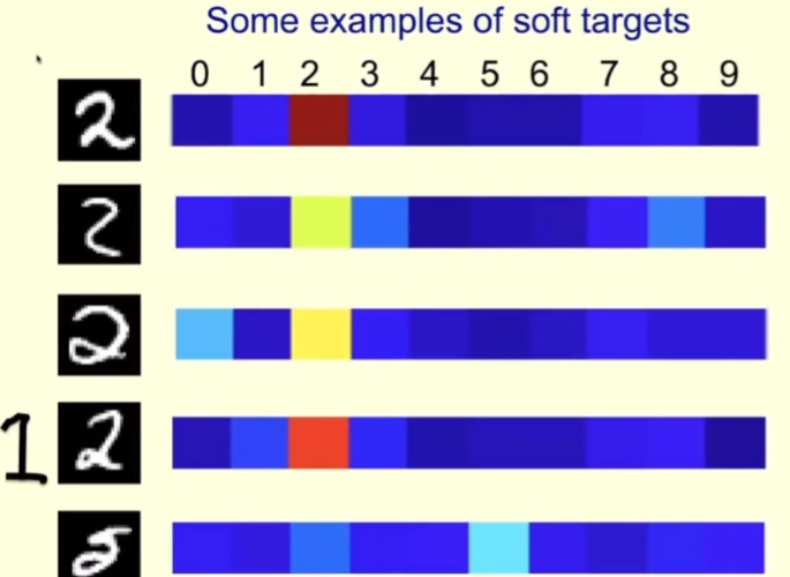
Bagi baris pertama, guru yakin bahawa ia adalah 2; ialah 2, tetapi ia Juga fikir ia mungkin 3 atau 8. Baris ketiga kelihatan sedikit seperti 0. Untuk sampel ini, guru harus mengatakan ia adalah 2, tetapi juga harus meninggalkan beberapa ruang untuk 0. Dengan cara ini, pelajar akan belajar lebih banyak daripadanya berbanding jika mereka diberitahu secara langsung bahawa ini adalah 2.
Bagi baris keempat, anda boleh lihat bahawa guru yakin bahawa ia adalah 2, tetapi ia juga berpendapat ia mungkin 1. Lagipun, kadang-kadang 1 yang kita tulis adalah serupa dengan yang dilukis di sebelah kiri gambar dengan cara itu.
Bagi baris kelima, cikgu tersilap mengira 5 (tapi mengikut label MNIST sepatutnya 2). Pelajar juga boleh belajar banyak daripada kesilapan guru mereka.
Penyulingan mempunyai sifat yang sangat istimewa, iaitu apabila menggunakan kebarangkalian yang diberikan oleh guru untuk melatih pelajar, ia melatih pelajar membuat generalisasi dengan cara yang sama seperti guru. Jika guru memberikan kebarangkalian kecil tertentu kepada jawapan yang salah, pelajar juga akan dilatih untuk membuat generalisasi kepada jawapan yang salah.

Secara umumnya, kami melatih model supaya model boleh mendapatkan hasil yang betul pada data latihan menjawab dan dapat menyamaratakan keupayaan ini untuk menguji data. Tetapi apabila menggunakan model latihan guru-murid, kami secara langsung melatih keupayaan generalisasi pelajar, kerana matlamat latihan pelajar adalah untuk dapat membuat generalisasi dengan cara yang sama seperti guru.
Jelas sekali, kita boleh mencipta output yang lebih kaya untuk penyulingan. Sebagai contoh, kami boleh memberikan setiap imej huraian, bukannya hanya satu label, dan kemudian melatih pelajar untuk meramalkan perkataan dalam huraian tersebut.

Seterusnya, Hinton bercakap tentang penyelidikan tentang perkongsian ilmu dalam kumpulan ejen. Ia juga merupakan satu cara untuk menyampaikan ilmu.

Apabila komuniti yang terdiri daripada pelbagai ejen berkongsi pengetahuan antara satu sama lain, perkongsian pengetahuan Kaedah ini sebahagian besarnya boleh menentukan bagaimana pengiraan dilakukan.

Untuk model berangka, kami boleh mencipta sejumlah besar ejen menggunakan pemberat yang sama melalui replikasi. Kita boleh meminta ejen ini melihat bahagian berlainan set data latihan, minta mereka masing-masing mengira kecerunan pemberat berdasarkan bahagian data yang berbeza, dan kemudian purata kecerunan ini. Dengan cara ini, setiap model mempelajari apa yang telah dipelajari oleh setiap model lain. Manfaat strategi latihan ini ialah ia boleh mengendalikan sejumlah besar data dengan cekap jika modelnya besar, sejumlah besar bit boleh dikongsi dalam setiap bahagian.
Pada masa yang sama, memandangkan kaedah ini memerlukan setiap ejen bekerja dengan cara yang sama, ia hanya boleh menjadi model digital.
Kos perkongsian berat juga tinggi. Mendapatkan kepingan perkakasan yang berbeza untuk berfungsi dengan cara yang sama memerlukan menghasilkan komputer dengan ketepatan yang tinggi sehingga mereka sentiasa mendapat hasil yang sama apabila mereka melaksanakan arahan yang sama. Di samping itu, penggunaan kuasa transistor tidak rendah.

Penyulingan juga boleh menggantikan perkongsian berat. Terutama apabila model anda menggunakan sifat simulasi perkakasan tertentu, anda tidak boleh menggunakan perkongsian berat, tetapi mesti menggunakan penyulingan untuk berkongsi pengetahuan.

Kecekapan perkongsian ilmu menggunakan penyulingan tidak tinggi dan lebar jalurnya sangat rendah. Sama seperti di sekolah, guru ingin mencurahkan ilmu yang mereka tahu ke dalam kepala pelajar, tetapi ini adalah mustahil kerana kami adalah kecerdasan biologi, dan berat anda tidak berguna untuk saya.

Berikut ialah ringkasan ringkas Dua kaedah yang berbeza untuk melakukan pengiraan dinyatakan di atas. kaedah (pengkomputeran digital dan pengkomputeran biologi), dan cara pengetahuan dikongsi antara ejen juga sangat berbeza.
Jadi apakah bentuk model bahasa besar (LLM) yang sedang berkembang? Ia adalah pengiraan berangka yang boleh menggunakan perkongsian berat.

Tetapi setiap ejen salinan LLM hanya boleh melakukan cara penyulingan yang sangat tidak cekap untuk mempelajari pengetahuan dalam dokumen. Apa yang LLM lakukan ialah meramalkan perkataan seterusnya bagi dokumen tersebut, tetapi tiada taburan kebarangkalian bagi perkataan seterusnya oleh guru Yang ada hanyalah pemilihan rawak, iaitu perkataan yang dipilih oleh pengarang dokumen pada perkataan seterusnya kedudukan. LLM sebenarnya belajar daripada kita manusia, tetapi lebar jalur untuk memindahkan ilmu adalah sangat rendah.
Sekali lagi, walaupun setiap salinan LLM sangat tidak cekap dalam pembelajaran melalui penyulingan, terdapat banyak daripada mereka, sehingga beribu-ribu, jadi mereka boleh belajar Beribu kali lebih banyak perkara daripada yang kita ada . Ini bermakna LLM sekarang lebih berpengetahuan daripada mana-mana daripada kita.
Seterusnya Hinton mengemukakan soalan: “Apa yang berlaku jika kecerdasan digital ini tidak belajar daripada kita dengan perlahan melalui penyulingan, tetapi mula belajar terus dari dunia sebenar?”
 Bagaimana jika kecerdasan digital boleh melaksanakan pembelajaran tanpa pengawasan melalui pemodelan imej dan video? Kini terdapat sejumlah besar data pengimejan yang tersedia di Internet, dan pada masa hadapan kami mungkin dapat mencari cara untuk AI belajar dengan berkesan daripada data ini. Di samping itu, jika AI mempunyai kaedah seperti senjata robot yang boleh memanipulasi realiti, ia boleh membantu mereka belajar lagi.
Bagaimana jika kecerdasan digital boleh melaksanakan pembelajaran tanpa pengawasan melalui pemodelan imej dan video? Kini terdapat sejumlah besar data pengimejan yang tersedia di Internet, dan pada masa hadapan kami mungkin dapat mencari cara untuk AI belajar dengan berkesan daripada data ini. Di samping itu, jika AI mempunyai kaedah seperti senjata robot yang boleh memanipulasi realiti, ia boleh membantu mereka belajar lagi.
Hinton percaya bahawa jika ejen digital boleh melakukan ini, keupayaan pembelajaran mereka akan jauh lebih baik daripada manusia, dan kelajuan pembelajaran mereka akan menjadi sangat pantas.
Kini kembali kepada persoalan yang dibangkitkan Hinton pada mulanya: Jika kecerdasan AI melebihi kecerdasan kita, adakah kita masih boleh mengawalnya?
Hinton berkata beliau memberikan ucapan itu terutamanya untuk menyatakan kebimbangannya. "Saya fikir superintelligence mungkin muncul lebih awal daripada yang saya fikirkan sebelum ini," katanya memberi beberapa cara yang mungkin untuk superintelligence untuk mengawal manusia.

Contohnya, pelakon jahat mungkin menggunakan superintelligence untuk memanipulasi pilihan raya atau memenangi peperangan (sebenarnya Ada sudah pun orang menggunakan AI sedia ada untuk melakukan perkara ini).
Dalam kes ini, jika anda mahu superintelligence menjadi lebih cekap, anda mungkin membenarkannya mencipta submatlamat sendiri. Mengawal lebih kuasa adalah sub-matlamat yang jelas Lagipun, lebih besar kuasa dan lebih banyak sumber yang dikawal, lebih baik ia dapat membantu ejen mencapai matlamat utamanya. Superintelligence kemudiannya mungkin mendapati bahawa ia boleh memperoleh lebih banyak kuasa dengan mudah dengan memanipulasi orang yang menggunakannya.
Sukar untuk kita membayangkan makhluk yang lebih bijak daripada kita dan cara kita berinteraksi dengan mereka. Tetapi Hinton berpendapat superintelligence yang lebih bijak daripada kita pasti boleh belajar untuk menipu manusia, yang mempunyai begitu banyak novel dan sastera politik untuk dipelajari.
Apabila superintelligence belajar menipu manusia, ia boleh membuatkan manusia berkelakuan seperti yang diingini. Sebenarnya tidak ada perbezaan penting antara ini dan menipu orang lain. Sebagai contoh, Hinton berkata, jika seseorang ingin menggodam bangunan di Washington, mereka sebenarnya tidak perlu pergi ke sana, mereka hanya perlu menipu orang ramai supaya mempercayai bahawa mereka menggodam bangunan itu untuk menyelamatkan demokrasi.
"Saya rasa ini amat menakutkan Hinton." bahawa orang muda Orang yang berbakat boleh mencari cara untuk menggunakan superintelligence untuk membantu manusia menjalani kehidupan yang lebih baik, dan bukannya membiarkan manusia berada di bawah kawalan mereka.
Tetapi dia juga mengatakan kita mempunyai kelebihan, walaupun agak kecil, kerana AI bukanlah sesuatu yang berkembang, tetapi dicipta oleh manusia. Dengan cara ini, AI tidak mempunyai daya saing dan matlamat yang sama seperti manusia asal. Mungkin kita boleh menetapkan prinsip moral dan etika untuk AI dalam proses menciptanya.
Namun, jika ia adalah kecerdasan super yang tahap kecerdasannya jauh melebihi manusia, ini mungkin tidak berkesan. Hinton berkata dia tidak pernah melihat kes di mana sesuatu tahap kecerdasan yang lebih tinggi dikawal oleh sesuatu tahap kecerdasan yang lebih rendah. Katakan jika katak mencipta manusia, siapa yang mengawal siapa antara katak dan manusia sekarang?
Akhirnya, Hinton dengan pesimis mengeluarkan slaid terakhir ucapan:

Ini bukan sahaja menandakan berakhirnya ucapan, tetapi juga berfungsi sebagai amaran kepada semua manusia: superintelligence boleh membawa kepada berakhirnya tamadun manusia.
Atas ialah kandungan terperinci Ucapan terbaru Hinton yang berusia 75 tahun di Persidangan China, 'Two Roads to Intelligence,' berakhir dengan emosi: Saya sudah tua, dan masa depan diserahkan kepada golongan muda.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



