


Adakah anda masih ingat bahawa orang besar telah dibahagikan kepada dua kem mengenai "sama ada AI boleh menghapuskan manusia"?
Oleh kerana dia tidak faham mengapa "AI mencipta risiko", Andrew Ng baru-baru ini memulakan siri dialog dan pergi bercakap dengan dua pemenang Anugerah Turing:
Apakah AI wujud? Apakah risikonya?

Apa yang menarik ialah selepas mengadakan perbualan yang mendalam dengan Yoshua Bengio dan Geoffrey Hinton, dia “mencapai banyak kata sepakat” dengan mereka"!
Mereka berdua percaya bahawa kedua-dua pihak harus bersama-sama membincangkan risiko khusus yang akan dicipta oleh kecerdasan buatan dan mengetahui sejauh mana ia difahami. Hinton juga secara khusus menyebut pemenang Anugerah Turing Yann LeCun sebagai "wakil pembangkang"
Perdebatan masih sangat sengit dalam isu ini, malah sarjana yang dihormati seperti Yann percaya bahawa model besar tidak benar-benar Memahami apa yang mereka katakan.
Musk juga sangat berminat dengan perbualan ini:
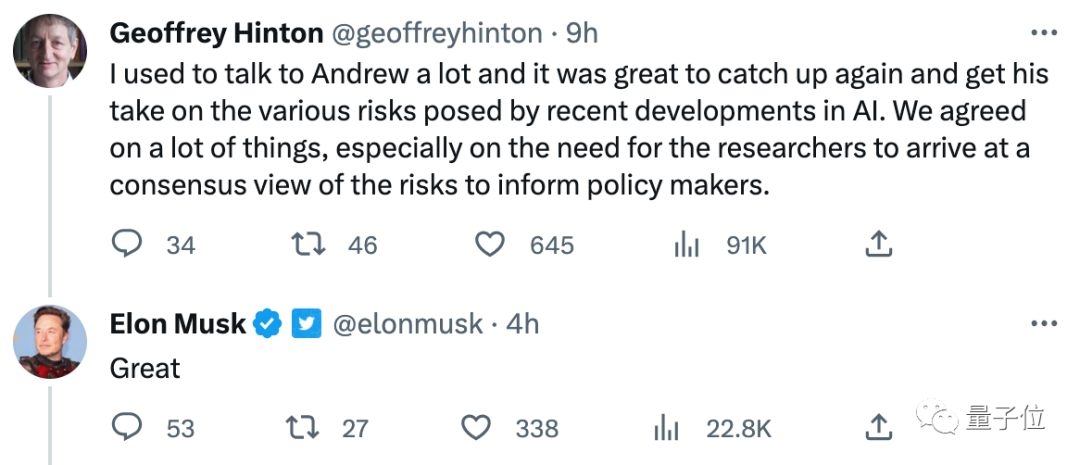
Selain itu, Hinton baru-baru ini The Intellectual Property Conference sekali lagi "berkhutbah" tentang risiko AI, mengatakan bahawa kecerdasan super yang lebih pintar daripada manusia akan muncul tidak lama lagi:
Kami tidak biasa memikirkan perkara yang jauh lebih bijak daripada kami, dan cara berinteraksi dengan mereka Mereka berinteraksi.
Saya tidak nampak cara untuk menghalang superintelligence daripada "keluar kawalan" sekarang, dan saya sudah tua. Saya berharap lebih ramai penyelidik muda akan menguasai kaedah mengawal superintelligence.
Mari kita lihat perkara teras perbualan ini dan pandangan pakar AI yang berbeza mengenai perkara ini.
Perbualan pertama dengan Bengio. Ng dan beliau mencapai kata sepakat utama, iaitu:
Para saintis harus cuba mencari "senario khusus di mana risiko AI wujud."
Dalam erti kata lain, di mana senario AI akan menyebabkan kemudaratan besar kepada manusia, atau bahkan membawa kepada kepupusan manusia, ini adalah kata sepakat yang perlu dicapai oleh kedua-dua pihak.
Bengio percaya bahawa masa depan AI penuh dengan "kabus dan ketidakpastian", jadi adalah perlu untuk mengetahui beberapa senario khusus di mana AI akan menyebabkan kemudaratan.

Kemudian berlakulah perbualan dengan Hinton, dan kedua-dua pihak mencapai dua kata sepakat penting.
Di satu pihak, semua saintis mesti mempunyai perbincangan yang baik mengenai isu "risiko AI" untuk menggubal dasar yang baik
Sebaliknya, AI sememangnya memahami dunia . Menyenaraikan isu teknikal utama mengenai isu keselamatan AI boleh membantu saintis mencapai kata sepakat.
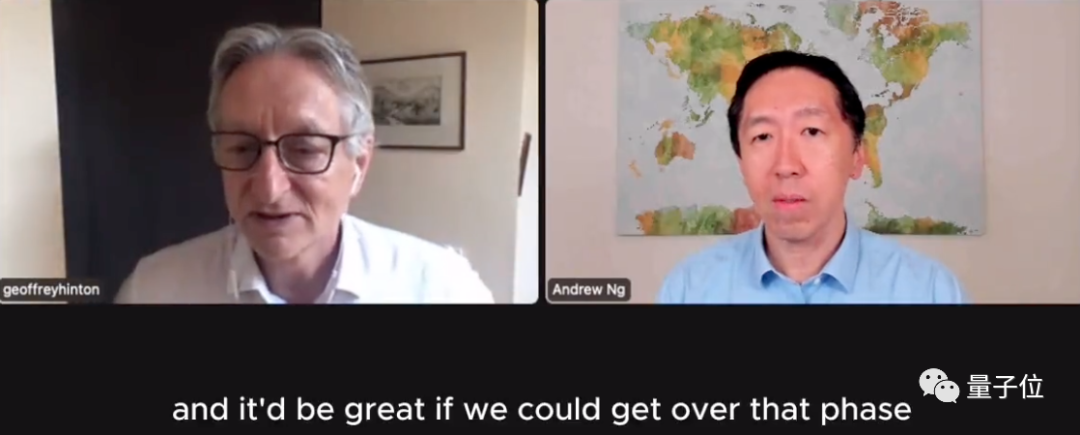
Semasa proses ini, Hinton menyebut perkara utama yang perlu dicapai, iaitu "sama ada model dialog besar seperti GPT-4 dan Bard benar-benar faham apa yang mereka katakan":
Ada orang fikir mereka faham, ada orang fikir mereka hanya burung kakak tua secara rawak.
Saya rasa kita semua percaya mereka faham (apa yang mereka katakan), tetapi sesetengah ulama yang sangat kami hormati, seperti Yann, berpendapat mereka tidak faham.
Sudah tentu, LeCun, yang "dipanggil", juga tiba tepat pada masanya dan menyatakan pandangannya dengan sangat serius:
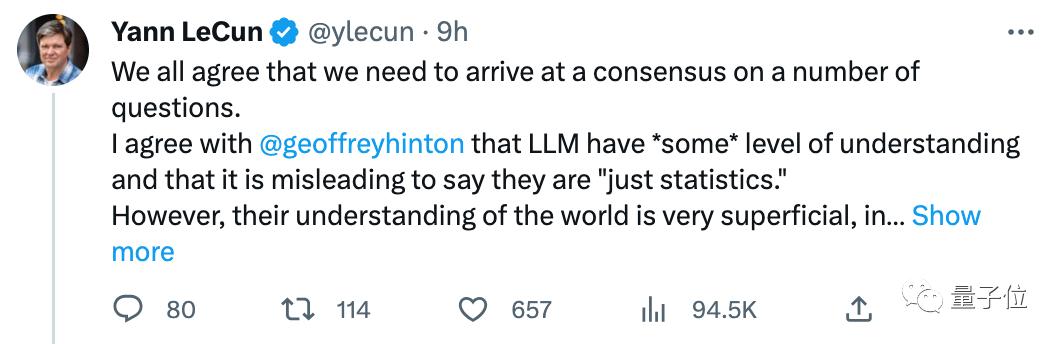
Kita semua bersetuju bahawa kita perlu mencapai kata sepakat dalam beberapa isu. Saya juga bersetuju dengan Hinton bahawa LLM mempunyai sedikit pemahaman dan mengatakan mereka "hanya statistik" adalah mengelirukan.
1. Tetapi pemahaman mereka tentang dunia sangat cetek, sebahagian besarnya kerana mereka hanya dilatih dengan teks biasa. Sistem AI yang mempelajari cara dunia berfungsi daripada penglihatan akan mempunyai pemahaman yang lebih mendalam tentang realiti, manakala keupayaan penaakulan dan perancangan LLM autoregresif adalah sangat terhad jika dibandingkan.
2. Saya tidak percaya tahap AI yang hampir dengan manusia (atau kucing) akan muncul tanpa syarat berikut:
(1) Model dunia dipelajari daripada input deria seperti video
(2) Satu seni bina yang boleh menaakul dan merancang (bukan hanya autoregresif)
3. Jika kita mempunyai seni bina yang memahami perancangan, ia akan didorong oleh matlamat, iaitu berdasarkan pengoptimuman masa inferens (bukan hanya masa latihan) Matlamat untuk merancang kerja. Matlamat ini boleh menjadi pagar yang menjadikan sistem AI "taat" dan selamat, atau malah akhirnya mencipta model dunia yang lebih baik daripada yang manusia boleh.
Masalahnya kemudiannya menjadi mereka bentuk (atau melatih) fungsi objektif yang baik yang menjamin keselamatan dan kecekapan.
4. Ini adalah masalah kejuruteraan yang sukar, tetapi tidak sesusah yang dikatakan oleh sesetengah orang.
Walaupun respons ini masih tidak menyebut "risiko AI" sama sekali, LeCun memberikan cadangan praktikal untuk meningkatkan keselamatan AI (mencipta "pengadang" AI), dan membayangkan penyelesaian yang lebih baik daripada manusia. adakah "kelihatan" AI yang lebih berkuasa (input berbilang deria + perancangan inferens).
Pada tahap tertentu, kedua-dua pihak telah mencapai beberapa konsensus mengenai idea bahawa AI mempunyai isu keselamatan.
Sudah tentu, ia bukan sahaja perbualan dengan Andrew Ng.
Hinton, yang baru-baru ini meninggalkan Google, telah bercakap mengenai topik risiko AI pada banyak kesempatan, termasuk Persidangan Sumber Pintar baru-baru ini yang dihadirinya.
Pada persidangan itu, dengan tema "Dua Laluan Kecerdasan", beliau membincangkan dua laluan kecerdasan "penyulingan pengetahuan" dan "perkongsian berat", serta cara menjadikan AI lebih pintar, dan Saya sendiri pandangan tentang kemunculan superintelligence.
Ringkasnya, Hinton bukan sahaja percaya bahawa superintelligence (lebih pintar daripada manusia) akan muncul, tetapi ia akan muncul lebih awal daripada yang orang fikirkan.
Bukan itu sahaja, dia berpendapat kecerdasan super ini akan hilang kawalan, tetapi pada masa ini dia tidak dapat memikirkan cara yang baik untuk menghalangnya:
Kecerdasan super boleh diperolehi dengan mudah lebih berkuasa dengan memanipulasi orang. Kita tidak biasa memikirkan perkara yang jauh lebih bijak daripada kita dan cara berinteraksi dengan mereka. Ia menjadi mahir menipu orang kerana ia boleh mempelajari contoh menipu orang lain daripada karya fiksyen tertentu.
Apabila sudah pandai menipu orang, ia mempunyai cara untuk membuat orang melakukan apa sahaja... Saya rasa ini ngeri tetapi saya tidak dapat melihat bagaimana untuk menghalang perkara ini daripada berlaku kerana saya sudah tua.
Saya berharap penyelidik muda dan berbakat seperti anda akan mengetahui cara kami mempunyai kecerdasan super ini dan menjadikan hidup kami lebih baik.
Apabila slaid "THE END" ditayangkan, Hinton menekankan dengan penuh makna:
Ini adalah PPT terakhir saya dan permulaan ucapan ini.
Pautan rujukan:
[1]https://twitter.com/AndrewYNg/status/1667920020587020290
[ 2]https://twitter.com/AndrewYNg/status/1666582174257254402
[3]https://2023.baai.ac.cn/
Atas ialah kandungan terperinci Hinton, pemenang Anugerah Turing: Saya sudah tua, saya serahkan kepada anda untuk mengawal AI yang lebih bijak daripada manusia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Kaedah BigDecimal untuk membandingkan saiz
Kaedah BigDecimal untuk membandingkan saiz
 Bagaimana untuk mematikan tembok api
Bagaimana untuk mematikan tembok api
 html editor dalam talian
html editor dalam talian
 Proses jual beli Bitcoin di Huobi.com
Proses jual beli Bitcoin di Huobi.com
 Pelayan tidak boleh ditemui pada penyelesaian komputer
Pelayan tidak boleh ditemui pada penyelesaian komputer
 Bagaimana Oracle mencipta pangkalan data
Bagaimana Oracle mencipta pangkalan data
 Pengenalan kepada penggunaan fungsi sort() dalam python
Pengenalan kepada penggunaan fungsi sort() dalam python
 Kekunci yang manakah harus saya tekan untuk memulihkan apabila saya tidak boleh menaip pada papan kekunci komputer saya?
Kekunci yang manakah harus saya tekan untuk memulihkan apabila saya tidak boleh menaip pada papan kekunci komputer saya?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



