


Memori yang lemah ialah titik kesakitan utama model bahasa berskala besar semasa Contohnya, ChatGPT hanya boleh memasukkan 4096 token (kira-kira 3000 perkataan saya sering lupa apa yang saya katakan sebelum ini, dan memang begitu tidak cukup untuk membaca cerpen.
Tetingkap input pendek juga mengehadkan senario aplikasi model bahasa Contohnya, apabila meringkaskan kertas saintifik (kira-kira 10,000 patah perkataan), artikel itu perlu dibahagikan secara manual adalah input ke dalam model, maklumat yang berkaitan antara bab yang berbeza hilang.
Walaupun GPT-4 menyokong sehingga 32,000 token dan Claude yang dinaik taraf menyokong sehingga 100,000 token, mereka hanya boleh mengurangkan masalah kapasiti otak yang tidak mencukupi.
Baru-baru ini pasukan keusahawanan Magic mengumumkan bahawa ia tidak lama lagi akan mengeluarkan model LTM-1, yang boleh menyokong sehingga 5 juta token Ia adalah kira-kira 500,000 baris kod atau 5,000 fail, iaitu 50 kali lebih tinggi daripada Claude pada asasnya boleh menampung kebanyakan keperluan storan Ini benar-benar perubahan kuantitatif.
Senario aplikasi utama LTM-1 ialah pelengkapan kod, contohnya, ia boleh menjana cadangan kod yang lebih panjang dan lebih kompleks.
Anda juga boleh menggunakan semula dan mensintesis maklumat merentas berbilang fail.
Berita buruknya ialah Magic, pembangun LTM-1, tidak mengeluarkan prinsip teknikal khusus, tetapi hanya mengatakan bahawa ia mereka bentuk kaedah baharu Rangkaian Memori Jangka Panjang (LTM Net).
Tetapi terdapat juga berita baik pada September 2021, penyelidik dari DeepMind dan institusi lain mencadangkan model yang dipanggil ∞-bekas, yang merangkumi ingatan jangka panjang (ingatan jangka panjang (LTM). ) mekanisme, yang secara teorinya membenarkan model Transformer mempunyai memori yang tidak terhingga, tetapi pada masa ini tidak jelas sama ada kedua-duanya adalah teknologi yang sama atau versi yang lebih baik.

Pautan kertas: https://arxiv.org/pdf/2109.00301.pdf
Pasukan pembangunan menyatakan bahawa walaupun LTM Nets boleh melihat lebih banyak konteks daripada GPT, bilangan parameter model LTM-1 jauh lebih kecil daripada model sota semasa, jadi ia lebih pintar . Rendah, tetapi terus meningkatkan saiz model akan meningkatkan prestasi LTM Nets.
Pada masa ini LTM-1 telah membuka aplikasi ujian alfa.

Pautan aplikasi: https://www.php. cn/link/bbfb937a66597d9646ad992009aee405
Magic, pembangun LTM-1, diasaskan pada 2022. Ia terutamanya membangunkan produk yang serupa dengan GitHub jurutera menulis dan menyemak, menyahpepijat dan mengubah suai kod, matlamatnya adalah untuk mencipta rakan sekerja AI untuk pengaturcara yang kelebihan daya saing utamanya ialah model boleh membaca kod yang lebih panjang.
Magic komited untuk manfaat awam, dan misinya adalah untuk membina dan menggunakan sistem AGI dengan selamat yang melebihi keupayaan manusia Ia kini merupakan syarikat permulaan dengan hanya 10 orang.

Pada Februari tahun ini, Magic menerima AS$23 juta dalam pembiayaan Siri A yang diketuai oleh CapitalG, anak syarikat Alphabet. Pelabur juga Termasuk Nat Friedman, bekas Ketua Pegawai Eksekutif GitHub dan pengeluar bersama Copilot, jumlah pembiayaan syarikat kini mencecah AS$28 juta.
Eric Steinberger, Ketua Pegawai Eksekutif dan pengasas bersama Magic, lulus dari Universiti Cambridge dengan ijazah sarjana muda dalam sains komputer dan telah melakukan penyelidikan pembelajaran mesin di FAIR.

Sebelum mengasaskan Magic, Steinberger juga mengasaskan ClimateScience untuk membantu kanak-kanak di seluruh dunia mengetahui tentang kesan perubahan iklim.
Reka bentuk mekanisme perhatian dalam Transformer, komponen teras model bahasa, akan menyebabkan kerumitan masa meningkat setiap kali panjang daripada jujukan input meningkat.
Walaupun sudah terdapat beberapa varian mekanisme perhatian, seperti perhatian yang jarang, dll. untuk mengurangkan kerumitan algoritma, kerumitannya masih berkaitan dengan panjang input dan tidak boleh berkembang tidak terhingga.
∞-bekas Kunci kepada model Transformer ingatan jangka panjang (LTM) yang boleh memanjangkan urutan input kepada infiniti ialah rangka kerja perhatian spatial berterusan yang mengurangkan kebutiran perwakilan Meningkatkan bilangan unit maklumat ingatan (fungsi asas).
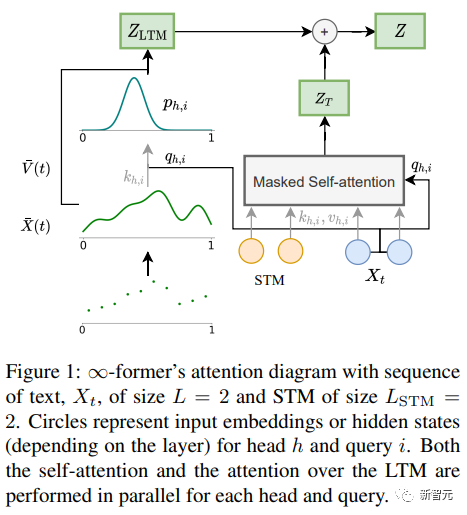
Dalam rangka kerja, jujukan input diwakili sebagai "isyarat berterusan", mewakili N fungsi asas jejari ( RBF ), dengan cara ini, kerumitan perhatian ∞-bekas dikurangkan kepada O(L^2 + L × N), manakala kerumitan perhatian Transformer asal ialah O(L×(L+L_LTM)) , di mana L dan L_LTM sepadan dengan saiz input Transformer dan panjang ingatan jangka panjang masing-masing.
Kaedah perwakilan ini mempunyai dua kelebihan utama:
1 Konteks boleh diwakili oleh fungsi asas N yang lebih kecil daripada nombor daripada token, mengurangkan Kos pengiraan perhatian dikurangkan;
 Sudah tentu, tiada makan tengah hari percuma, dan harganya ialah pengurangan resolusi: apabila menggunakan nombor yang lebih kecil fungsi asas, Boleh mengakibatkan pengurangan ketepatan apabila mewakili urutan input sebagai isyarat berterusan.
Sudah tentu, tiada makan tengah hari percuma, dan harganya ialah pengurangan resolusi: apabila menggunakan nombor yang lebih kecil fungsi asas, Boleh mengakibatkan pengurangan ketepatan apabila mewakili urutan input sebagai isyarat berterusan.
Untuk mengurangkan masalah pengurangan resolusi, penyelidik memperkenalkan konsep "kenangan melekit", yang mengaitkan ruang yang lebih besar dalam isyarat LTM kepada kawasan memori yang lebih kerap diakses , mencipta konsep "kekal " dalam LTM, yang membolehkan model menangkap latar belakang jangka panjang dengan lebih baik tanpa kehilangan maklumat yang relevan, dan juga diilhamkan oleh potensi jangka panjang dan keplastikan otak.
Bahagian eksperimen
Untuk mengesahkan sama ada ∞-bekas boleh memodelkan konteks yang panjang, penyelidik pertama Eksperimen adalah dijalankan pada tugas sintesis menyusun token mengikut kekerapan dalam urutan yang panjang; kemudian eksperimen dijalankan ke atas pemodelan bahasa dan penjanaan dialog berasaskan dokumen dengan menyempurnakan model bahasa yang telah dilatih.
Isih
Input terdiri daripada token yang disampel mengikut taburan kebarangkalian ( tidak diketahui oleh sistem), matlamatnya adalah untuk menjana token mengikut urutan penurunan kekerapan dalam jujukan
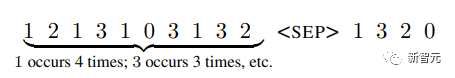 mengikut urutan untuk mengkaji sama ada memori jangka panjang digunakan dengan berkesan, dan Transformer Sama ada ranking dilakukan hanya dengan memodelkan teg terkini, penyelidik mereka bentuk taburan kebarangkalian tag untuk berubah dari semasa ke semasa.
mengikut urutan untuk mengkaji sama ada memori jangka panjang digunakan dengan berkesan, dan Transformer Sama ada ranking dilakukan hanya dengan memodelkan teg terkini, penyelidik mereka bentuk taburan kebarangkalian tag untuk berubah dari semasa ke semasa.
Terdapat 20 token dalam perbendaharaan kata Eksperimen telah dijalankan dengan urutan panjang masing-masing 4,000, 8,000 dan 16,000 dan pengubah mampatan digunakan sebagai model garis dasar.
Hasil eksperimen dapat dilihat bahawa dalam kes panjang jujukan pendek (4,000), Transformer-XL mencapai ketepatan lebih tinggi sedikit daripada model lain tetapi apabila panjang jujukan meningkat, ketepatannya juga menurun dengan cepat, tetapi Untuk ∞-dahulu, penurunan ini tidak jelas, menunjukkan bahawa ia mempunyai lebih banyak kelebihan apabila memodelkan jujukan panjang.
Pemodelan Bahasa
Untuk memahami sama ada ingatan jangka panjang boleh digunakan untuk melanjutkan pra-latihan Untuk model bahasa, penyelidik memperhalusi GPT-2 kecil pada subset Wikitext103 dan PG-19, termasuk kira-kira 200 juta token.
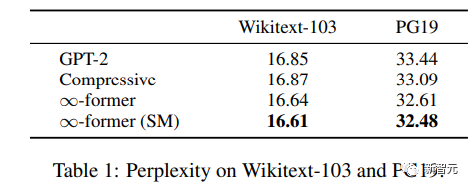
Hasil eksperimen dapat dilihat bahawa ∞-bekas dapat mengurangkan kekeliruan Wikitext-103 dan PG19, dan ∞ - Peningkatan yang diperoleh oleh bekas adalah lebih besar pada set data PG19 kerana buku lebih bergantung pada ingatan jangka panjang berbanding artikel Wikipedia.
Dialog berasaskan dokumen
Dalam penjanaan dialog berasaskan dokumen, kecuali Sebagai tambahan kepada sejarah perbualan, model juga boleh mendapatkan dokumen tentang topik perbualan.
Dalam set data CMU Document Grounded Conversation (CMU-DoG), perbualan adalah mengenai filem dan ringkasan filem diberikan sebagai dokumen tambahan memandangkan perbualan itu mengandungi pelbagai berbeza Dalam wacana berterusan, dokumen tambahan dibahagikan kepada bahagian.
Untuk menilai kegunaan ingatan jangka panjang, penyelidik menjadikan tugasan lebih mencabar dengan hanya memberikan model akses kepada fail sebelum perbualan bermula.
Selepas menala halus GPT-2 kecil, untuk membolehkan model menyimpan keseluruhan dokumen dalam ingatan, LTM berterusan (∞-bekas) dengan fungsi asas N=512 adalah digunakan untuk memanjangkan GPT -2.
Untuk menilai kesan model, gunakan kebingungan, skor F1, Rouge-1 dan Rouge-L serta penunjuk Meteor.
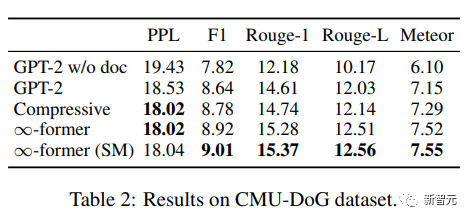
Daripada keputusan, ∞-bekas dan mampatan Transformer boleh menjana korpus yang lebih baik, walaupun kekeliruan antara kedua-dua Darjah pada asasnya adalah sama, tetapi ∞-bekas mencapai skor yang lebih baik pada penunjuk lain.
Atas ialah kandungan terperinci 5 juta token raksasa, baca keseluruhan 'Harry Potter' sekali gus! Lebih daripada 1000 kali lebih lama daripada ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



