



Redis biasanya merupakan komponen penting dalam sistem perniagaan kami, seperti cache, maklumat log masuk akaun, kedudukan, dsb.
Apabila kelewatan permintaan Redis meningkat, ia boleh menyebabkan "avalanche" sistem perniagaan.
Saya bekerja untuk syarikat Internet jenis pembuat jodoh tunggal Semasa Double Eleven, saya melancarkan kempen untuk memberi hadiah kepada teman wanita saya apabila saya membuat pesanan.
Siapa sangka selepas jam 12 pagi, jumlah pengguna meningkat dengan mendadak, dan berlaku gangguan teknikal yang menghalang pengguna untuk membuat tempahan Pada masa itu, kebakaran lama berlaku!
Selepas mencari, saya menjumpai laporan Redis Could not get a resource from the pool.
Tidak boleh mendapatkan sumber sambungan dan bilangan sambungan kepada satu Redis dalam gugusan adalah sangat tinggi.
Sejumlah besar trafik kehilangan respons cache Redis dan memukul MySQL secara langsung Pada akhirnya, pangkalan data juga terputus...
Jadi pelbagai perubahan dibuat kepada bilangan maksimum. sambungan dan bilangan sambungan menunggu, walaupun mesej ralat telah dilaporkan. Kekerapan telah berkurangan, tetapi ralat masih berterusan.
Kemudian, selepas ujian luar talian, didapati bahawa data aksara yang disimpan dalam Redis adalah sangat besar, dan memerlukan purata 1s untuk mengembalikan data.
Boleh didapati apabila kelewatan Redis terlalu tinggi, pelbagai masalah akan berlaku.
Hari ini, mari analisa cara untuk menentukan sama ada Redis mempunyai masalah prestasi dan penyelesaian.
Lengah maksimum ialah masa daripada klien mengeluarkan arahan kepada klien menerima respons kepada arahan Dalam keadaan biasa, masa pemprosesan Redis adalah sangat singkat, pada tahap mikrosaat.
Apabila prestasi Redis turun naik, contohnya, ia mencapai beberapa saat hingga lebih daripada sepuluh saat, jelas sekali kita boleh membuat kesimpulan bahawa prestasi Redis telah menjadi perlahan.
Sesetengah konfigurasi perkakasan agak tinggi Apabila kelewatan adalah 0.6ms, kami mungkin menganggapnya perlahan. Jika perkakasan lemah, mungkin mengambil masa 3 ms sebelum kami fikir ada masalah.
Jadi bagaimana kita menentukan sama ada Redis benar-benar lambat?
Jadi, kita perlu mengukur prestasi garis dasar Redis bagi persekitaran semasa, iaitu prestasi asas sistem di bawah tekanan rendah dan tiada gangguan.
Apabila anda mendapati bahawa kependaman masa jalan Redis adalah lebih daripada 2 kali ganda prestasi garis dasar, anda boleh menentukan bahawa prestasi Redis semakin perlahan.
Pengukuran garis dasar kependaman
Arahan redis-cli menyediakan pilihan –intrinsik-latency untuk memantau dan mengira kependaman maksimum semasa tempoh ujian (dalam milisaat), ini kelewatan boleh digunakan sebagai prestasi asas Redis.
redis-cli --latency -h `host` -p `port`
Sebagai contoh, laksanakan arahan berikut:
redis-cli --intrinsic-latency 100 Max latency so far: 4 microseconds. Max latency so far: 18 microseconds. Max latency so far: 41 microseconds. Max latency so far: 57 microseconds. Max latency so far: 78 microseconds. Max latency so far: 170 microseconds. Max latency so far: 342 microseconds. Max latency so far: 3079 microseconds. 45026981 total runs (avg latency: 2.2209 microseconds / 2220.89 nanoseconds per run). Worst run took 1386x longer than the average latency.
Nota: Parameter 100 ialah bilangan saat ujian akan dilaksanakan. Semakin lama kami menjalankan ujian, semakin besar kemungkinan kami menemui lonjakan latensi.
Biasanya berjalan selama 100 saat biasanya sesuai, yang cukup untuk mengesan masalah kependaman Sudah tentu, kita boleh memilih untuk menjalankan beberapa kali pada masa yang berbeza untuk mengelakkan ralat.
Latensi kependaman maksimum ialah 3079 mikrosaat, jadi prestasi garis dasar ialah 3079 (3 milisaat) mikrosaat.
Perlu diingatkan bahawa kita perlu berjalan pada pelayan Redis, bukan klien. Dengan cara ini, impak rangkaian pada prestasi garis dasar boleh dielakkan.
Anda boleh menyambung ke pelayan melalui -h host -p port Jika anda ingin memantau kesan rangkaian pada prestasi Redis, anda boleh menggunakan Iperf untuk mengukur kelewatan rangkaian daripada klien ke pelayan.
Jika kelewatan rangkaian mencecah beberapa ratus milisaat, ini mungkin menunjukkan bahawa program trafik tinggi lain sedang berjalan, menyebabkan kesesakan rangkaian Anda perlu menghubungi kakitangan operasi dan penyelenggaraan untuk menyelaraskan pengagihan trafik rangkaian.
Bagaimana untuk menilai sama ada ia adalah arahan yang perlahan?
Lihat sama ada kerumitan operasi ialah O(N). Dokumentasi rasmi memperkenalkan kerumitan setiap arahan Gunakan perintah O(1) dan O(log N) sebanyak mungkin.
Kerumitan yang terlibat dalam operasi set biasanya O(N), seperti pertanyaan set penuh HGETALL, SMEMBERS dan operasi pengagregatan set: SORT, LREM, SUNION, dsb.
Adakah terdapat sebarang data pemantauan yang boleh diperhatikan? Saya tidak menulis kod saya tidak tahu sama ada sesiapa telah menggunakan arahan yang perlahan.
Terdapat dua cara untuk menyemaknya:
Gunakan fungsi log perlahan Redis untuk mengesan arahan perlahan; 🎜 >alat monitor kependaman.
Selain itu, anda boleh menyemak penggunaan CPU proses utama Redis dengan cepat menggunakan diri anda (atas, htop, prstat, dll.). Jika penggunaan CPU tinggi tetapi trafik rendah, ia biasanya menunjukkan bahawa arahan perlahan sedang digunakan.
Arahan slowlog dalam Redis membolehkan kami mencari arahan perlahan yang melebihi masa pelaksanaan yang ditentukan Secara lalai, jika masa pelaksanaan sesuatu arahan melebihi 10ms akan direkodkan dalam log. slowlog hanya merekodkan masa pelaksanaan arahan, tidak termasuk operasi pergi balik IO dan tindak balas perlahan yang disebabkan oleh kelewatan rangkaian.
Kami boleh menyesuaikan standard arahan perlahan berdasarkan prestasi garis dasar (dikonfigurasikan kepada 2 kali kelewatan maksimum prestasi garis dasar) dan melaraskan ambang yang mencetuskan rakaman arahan perlahan.
Anda boleh memasukkan arahan berikut dalam redis-cli untuk mengkonfigurasi arahan pengelogan selama lebih daripada 6 milisaat:
redis-cli CONFIG SET slowlog-log-slower-than 6000
Ia juga boleh ditetapkan dalam fail konfigurasi Redis.config, dalam mikrosaat.
想要查看所有执行时间比较慢的命令,可以通过使用 Redis-cli 工具,输入 slowlog get 命令查看,返回结果的第三个字段以微秒位单位显示命令的执行时间。
假如只需要查看最后 2 个慢命令,输入 slowlog get 2 即可。
示例:获取最近2个慢查询命令
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"以第一个 HGET 命令为例分析,每个 slowlog 实体共 4 个字段:
字段 1:1 个整数,表示这个 slowlog 出现的序号,server 启动后递增,当前为 6。
字段 2:表示查询执行时的 Unix 时间戳。
字段 3:表示查询执行微秒数,当前是 74372 微秒,约 74ms。
字段4表示查询命令及其参数,如果参数数量较多或较大,则只显示部分参数。hgetall max.dsp.blacklist是当前正在执行的命令。
Latency Monitoring
Redis 在 2.8.13 版本引入了 Latency Monitoring 功能,用于以秒为粒度监控各种事件的发生频率。
启用延迟监视器的第一步是设置延迟阈值(单位毫秒)。只有超过该阈值的时间才会被记录,比如我们根据基线性能(3ms)的 3 倍设置阈值为 9 ms。
可以用 redis-cli 设置也可以在 Redis.config 中设置;
CONFIG SET latency-monitor-threshold 9
工具记录的相关事件的详情可查看官方文档:https://redis.io/topics/latency-monitor
如获取最近的 latency
127.0.0.1:6379> debug sleep 2 OK (2.00s) 127.0.0.1:6379> latency latest 1) 1) "command" 2) (integer) 1645330616 3) (integer) 2003 4) (integer) 2003
事件的名称;
事件发生的最新延迟的 Unix 时间戳;
毫秒为单位的时间延迟;
该事件的最大延迟。
Redis 的数据读写由单线程执行,如果主线程执行的操作时间太长,就会导致主线程阻塞。
一起分析下都有哪些操作会阻塞主线程,我们又该如何解决?
网络通信导致的延迟
客户端使用 TCP/IP 连接或 Unix 域连接连接到 Redis。1 Gbit/s 网络的典型延迟约为 200 us。
redis 客户端执行一条命令分 4 个过程:
发送命令-〉 命令排队 -〉 命令执行-〉 返回结果
这个过程称为 Round trip time(简称 RTT, 往返时间),mget mset 有效节约了 RTT,但大部分命令(如 hgetall,并没有 mhgetall)不支持批量操作,需要消耗 N 次 RTT ,这个时候需要 pipeline 来解决这个问题。
Redis pipeline 将多个命令连接在一起来减少网络响应往返次数。
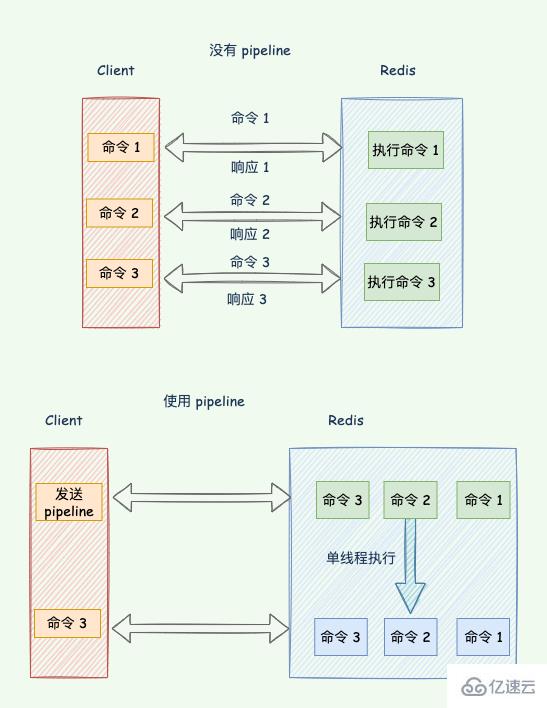
redis-pipeline
慢指令导致的延迟
根据上文的慢指令监控查询文档,查询到慢查询指令。可以通过以下两种方式解决:
在 Cluster 集群中,聚合运算等 O(N) 操作可以在 slave 节点上运行,也可以在客户端端完成。
使用高效的命令代替。采用增量迭代的方法查询数据,避免一次性查询大量数据,在此可参考SCAN、SSCAN、HSCAN和ZSCAN命令。
除此之外,生产中禁用KEYS 命令,它只适用于调试。因为它会遍历所有的键值对,所以操作延时高。
Fork 生成 RDB 导致的延迟
生成 RDB 快照,Redis 必须 fork 后台进程。fork 操作(在主线程中运行)本身会导致延迟。
Redis 使用操作系统的多进程写时复制技术 COW(Copy On Write) 来实现快照持久化,减少内存占用。

写时复制技术保证快照期间数据可修改
但 fork 会涉及到复制大量链接对象,一个 24 GB 的大型 Redis 实例需要 24 GB / 4 kB * 8 = 48 MB 的页表。
执行 bgsave 时,这将涉及分配和复制 48 MB 内存。
此外,从库加载 RDB 期间无法提供读写服务,所以主库的数据量大小控制在 2~4G 左右,让从库快速的加载完成。
内存大页(transparent huge pages)
常规的内存页是按照 4 KB 来分配,Linux 内核从 2.6.38 开始支持内存大页机制,该机制支持 2MB 大小的内存页分配。
Redis 使用了 fork 生成 RDB 做持久化提供了数据可靠性保证。
当生成 RDB 快照的过程中,Redis 采用**写时复制**技术使得主线程依然可以接收客户端的写请求。
也就是当数据被修改的时候,Redis 会复制一份这个数据,再进行修改。
采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。
使用以下指令禁用 Linux 内存大页即可:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swap:操作系统分页
当物理内存(内存条)不够用的时候,将部分内存上的数据交换到 swap 空间上,以便让系统不会因内存不够用而导致 oom 或者更致命的情况出现。
当某进程向 OS 请求内存发现不足时,OS 会把内存中暂时不用的数据交换出去,放在 SWAP 分区中,这个过程称为 SWAP OUT。
当某进程又需要这些数据且 OS 发现还有空闲物理内存时,又会把 SWAP 分区中的数据交换回物理内存中,这个过程称为 SWAP IN。
内存 swap 是操作系统里将内存数据在内存和磁盘间来回换入和换出的机制,涉及到磁盘的读写。
触发 swap 的情况有哪些呢?
对于 Redis 而言,有两种常见的情况:
Redis 使用了比可用内存更多的内存;
与 Redis 在同一机器运行的其他进程在执行大量的文件读写 I/O 操作(包括生成大文件的 RDB 文件和 AOF 后台线程),文件读写占用内存,导致 Redis 获得的内存减少,触发了 swap。
我要如何排查是否因为 swap 导致的性能变慢呢?
Linux 提供了很好的工具来排查这个问题,所以当怀疑由于交换导致的延迟时,只需按照以下步骤排查。
获取 Redis 实例 pid
$ redis-cli info | grep process_id process_id:13160
进入此进程的 /proc 文件系统目录:
cd /proc/13160
在这里有一个 smaps 的文件,该文件描述了 Redis 进程的内存布局,运行以下指令,用 grep 查找所有文件中的 Swap 字段。
$ cat smaps | egrep '^(Swap|Size)' Size: 316 kB Swap: 0 kB Size: 4 kB Swap: 0 kB Size: 8 kB Swap: 0 kB Size: 40 kB Swap: 0 kB Size: 132 kB Swap: 0 kB Size: 720896 kB Swap: 12 kB
每行 Size 表示 Redis 实例所用的一块内存大小,和 Size 下方的 Swap 对应这块 Size 大小的内存区域有多少数据已经被换出到磁盘上了。
如果 Size == Swap 则说明数据被完全换出了。
可以看到有一个 720896 kB 的内存大小有 12 kb 被换出到了磁盘上(仅交换了 12 kB),这就没什么问题。
Redis 本身会使用很多大小不一的内存块,所以,你可以看到有很多 Size 行,有的很小,就是 4KB,而有的很大,例如 720896KB。不同内存块被换出到磁盘上的大小也不一样。
敲重点了
如果 Swap 一切都是 0 kb,或者零星的 4k ,那么一切正常。
当出现百 MB,甚至 GB 级别的 swap 大小时,就表明,此时,Redis 实例的内存压力很大,很有可能会变慢。
解决方案
增加机器内存;
将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求;
增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存。
AOF 和磁盘 I/O 导致的延迟
为了保证数据可靠性,Redis 使用 AOF 和 RDB 快照实现快速恢复和持久化。
可以使用 appendfsync 配置将 AOF 配置为以三种不同的方式在磁盘上执行 write 或者 fsync (可以在运行时使用 CONFIG SET命令修改此设置,比如:redis-cli CONFIG SET appendfsync no)。
no:Redis 不执行 fsync,唯一的延迟来自于 write 调用,write 只需要把日志记录写到内核缓冲区就可以返回。
everysec:Redis 每秒执行一次 fsync。使用后台子线程异步完成 fsync 操作。最多丢失 1s 的数据。
always:每次写入操作都会执行 fsync,然后用 OK 代码回复客户端(实际上 Redis 会尝试将同时执行的许多命令聚集到单个 fsync 中),没有数据丢失。建议使用能够快速执行 fsync 并搭配快速的磁盘的文件系统实现,因为在这种模式下性能通常非常低。
我们通常将 Redis 用于缓存,数据丢失完全恶意从数据获取,并不需要很高的数据可靠性,建议设置成 no 或者 everysec。
除此之外,避免 AOF 文件过大, Redis 会进行 AOF 重写,生成缩小的 AOF 文件。
可以把配置项 no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作。
也就是说,Redis 实例把写命令写到内存后,不调用后台线程进行 fsync 操作,就直接返回了。
expires 淘汰过期数据
Redis 有两种方式淘汰过期数据:
惰性删除:当接收请求的时候发现 key 已经过期,才执行删除;
定时删除:每 100 毫秒删除一些过期的 key。
定时删除的算法如下:
随机采样 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,删除所有过期的 key;
如果发现还有超过 25% 的 key 已过期,则执行步骤一。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP默认设置为 20,每秒执行 10 次,删除 200 个 key 问题不大。
Jika item kedua dicetuskan, ia akan menyebabkan Redis memadam data tamat tempoh secara konsisten untuk mengosongkan memori. Dan pemadaman menyekat.
Apakah keadaan yang mencetuskan?
Iaitu, sebilangan besar kekunci menetapkan parameter masa yang sama. Penyahduaan berbilang diperlukan untuk mengurangkan bilangan kunci tamat tempoh kepada kurang daripada 25%. Kekunci ini tamat tempoh dalam jumlah yang banyak dalam saat yang sama.
Ringkasnya: sebilangan besar kunci tamat tempoh serentak boleh menyebabkan turun naik prestasi.
Penyelesaian
Jika sekumpulan kunci tamat tempoh pada masa yang sama, anda boleh menambah nombor rawak dalam julat saiz tertentu kepada parameter masa tamat tempoh EXPIREAT dan EXPIRE , Dengan cara ini, ia bukan sahaja memastikan bahawa kunci dipadamkan dalam julat masa yang berdekatan, tetapi juga mengelakkan tekanan yang disebabkan oleh tamat tempoh serentak.
bigkey
Biasanya kami memanggil Kunci yang mengandungi data yang besar atau bilangan ahli yang besar atau senarai sebagai Kunci besar Di bawah kami akan menggunakan beberapa contoh sebenar menerangkan ciri Kunci yang besar:
Kekunci jenis STRING, nilainya ialah 5MB (data terlalu besar)
A A Kunci jenis LIST, bilangan senarainya ialah 10,000 (bilangan senarai terlalu banyak)
Kunci jenis ZSET, bilangan ahlinya ialah 10,000 (bilangan ahli terlalu ramai)
Kunci dalam format HASH Walaupun hanya mempunyai 1000 ahli, jumlah saiz nilai ahli ini ialah 10MB (saiz ahli terlalu besar)
.Bigkey membawa masalah berikut:
Memori Redis terus berkembang, menyebabkan OOM, atau mencapai nilai tetapan memori maksimum, menyebabkan sekatan tulis atau kunci penting menjadi diusir;
Memori nod tertentu dalam Kluster Redis jauh melebihi nod lain, tetapi butiran minimum pemindahan data dalam Kluster Redis ialah Kunci, jadi memori pada nod tidak boleh seimbang;
Permintaan baca bigkey mengambil terlalu banyak lebar jalur, perlahan dan menjejaskan perkhidmatan lain pada pelayan; kunci besar menyebabkan perpustakaan utama disekat untuk masa yang lama dan mencetuskan penyegerakan Interrupt atau pertukaran induk-hamba; alat redis-rdb-tools untuk mencari kunci besar dengan cara yang disesuaikan.
Sebagai contoh, bahagikan Kunci HASH yang mengandungi puluhan ribu ahli kepada berbilang Kunci HASH dan Pastikan bahawa bilangan ahli setiap Kunci berada dalam julat yang munasabah Dalam struktur Kluster Redis, pemisahan Kekunci besar boleh memainkan peranan penting dalam keseimbangan memori antara nod. Pembersihan tak segerak kekunci besar
Redis telah menyediakan arahan UNLINK sejak 4.0, yang boleh membersihkan kunci masuk secara perlahan-lahan tanpa menyekat Melalui UNLINK, anda boleh memadam dengan selamat mereka Kunci Besar atau Kunci Tambahan Besar.
Atas ialah kandungan terperinci Bagaimana untuk menentukan sama ada Redis mempunyai masalah prestasi dan cara menyelesaikannya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan
 Apakah pangkalan data dalam memori?
Apakah pangkalan data dalam memori?
 Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
 Cara menggunakan redis sebagai pelayan cache
Cara menggunakan redis sebagai pelayan cache
 Bagaimana redis menyelesaikan ketekalan data
Bagaimana redis menyelesaikan ketekalan data
 Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
 Apakah data yang biasanya disimpan oleh redis cache?
Apakah data yang biasanya disimpan oleh redis cache?
 Apakah 8 jenis data redis
Apakah 8 jenis data redis








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



