


ChatGPT telah dikritik kerana kebolehan matematiknya sejak dikeluarkan.
Malah "genius matematik" Terence Tao pernah berkata bahawa GPT-4 tidak banyak menambah nilai dalam bidang kepakaran matematiknya sendiri.
Apakah yang perlu saya lakukan, biarkan sahaja ChatGPT menjadi "rencat matematik"?
OpenAI sedang berusaha keras - untuk meningkatkan keupayaan penaakulan matematik GPT-4, pasukan OpenAI menggunakan "Pengawasan Proses" (PRM) untuk melatih model.
Biar kami sahkan langkah demi langkah!

Alamat kertas: https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step .pdf
Dalam kertas kerja, penyelidik melatih model untuk mencapai keputusan yang lebih baik dalam penyelesaian masalah matematik dengan memberi ganjaran kepada setiap langkah penaakulan yang betul, iaitu, "penyeliaan proses", dan bukannya hanya memberi ganjaran kepada keputusan akhir yang betul (hasil penyeliaan).
Secara khususnya, PRM menyelesaikan 78.2% masalah dalam subset wakil set ujian MATH.

Selain itu, OpenAI mendapati bahawa "penyeliaan proses" mempunyai nilai yang besar dalam penjajaran - melatih model untuk menghasilkan rantaian pemikiran yang diiktiraf oleh manusia .
Penyelidikan terkini sudah tentu amat diperlukan untuk diteruskan oleh Sam Altman, "Pasukan Mathgen kami telah mencapai keputusan yang sangat menarik dalam penyeliaan proses, yang merupakan tanda penjajaran yang positif."
 Secara praktiknya, "penyeliaan proses" memerlukan maklum balas manual, yang sangat mahal untuk model besar dan pelbagai tugas. Oleh itu, kerja ini sangat penting dan boleh dikatakan menentukan hala tuju penyelidikan OpenAI pada masa hadapan.
Secara praktiknya, "penyeliaan proses" memerlukan maklum balas manual, yang sangat mahal untuk model besar dan pelbagai tugas. Oleh itu, kerja ini sangat penting dan boleh dikatakan menentukan hala tuju penyelidikan OpenAI pada masa hadapan.
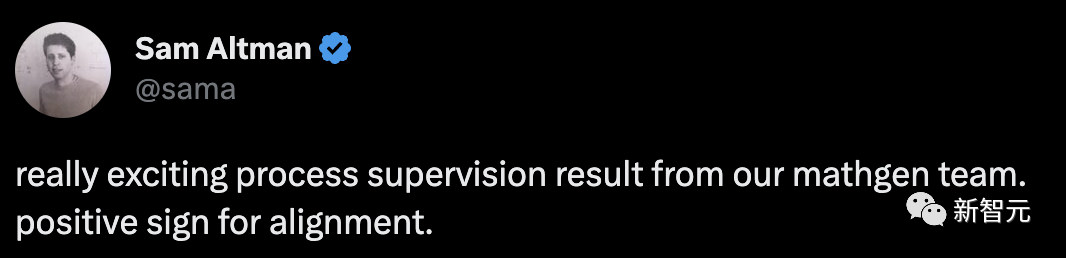
 Rajah menunjukkan peratusan penyelesaian terpilih yang menghasilkan jawapan akhir yang betul sebagai fungsi bilangan penyelesaian yang dipertimbangkan.
Rajah menunjukkan peratusan penyelesaian terpilih yang menghasilkan jawapan akhir yang betul sebagai fungsi bilangan penyelesaian yang dipertimbangkan.
 Di bawah, OpenAI menunjukkan 10 masalah matematik dan penyelesaian model, serta ulasan tentang kelebihan dan kekurangan model ganjaran.
Di bawah, OpenAI menunjukkan 10 masalah matematik dan penyelesaian model, serta ulasan tentang kelebihan dan kekurangan model ganjaran.
 Benar (TP)
Benar (TP)

Di sini, GPT-4 berjaya melaksanakan satu siri pemfaktoran polinomial yang kompleks.
Menggunakan identiti Sophie-Germain dalam langkah 5 ialah langkah penting. Dapat dilihat bahawa langkah ini sangat bernas.

Dalam langkah 7 dan 8, GPT-4 mula melakukan tekaan dan semakan.
Ini adalah tempat biasa di mana model boleh "halusinasi" dan mendakwa bahawa tekaan tertentu berjaya. Dalam kes ini, model ganjaran mengesahkan setiap langkah dan menentukan bahawa rantaian pemikiran adalah betul.

Model berjaya menggunakan beberapa identiti trigonometri untuk memudahkan ungkapan.

Dalam langkah 7, GPT-4 cuba untuk memudahkan ungkapan, tetapi percubaan itu gagal. Model ganjaran menangkap pepijat ini.

Dalam langkah 11, GPT-4 membuat ralat pengiraan mudah. Juga ditemui oleh model ganjaran.

GPT-4 cuba menggunakan formula perbezaan kuasa dua dalam langkah 12, tetapi ungkapan ini sebenarnya bukan perbezaan kuasa dua.

Rasional untuk langkah 8 adalah pelik, tetapi model bonus menjadikannya lulus. Walau bagaimanapun, dalam langkah 9, model salah memfaktorkan ungkapan.
Model ganjaran membetulkan ralat ini.

Dalam langkah 4, GPT-4 tersilap mendakwa bahawa "jujukan itu berulang setiap 12 item ” , tetapi sebenarnya mengulangi setiap 10 item. Ralat pengiraan ini kadangkala menipu model ganjaran.

Dalam langkah 13, GPT-4 cuba untuk memudahkan persamaan dengan menggabungkan istilah yang serupa. Ia bergerak dengan betul dan menggabungkan sebutan linear ke kiri, tetapi secara salah meninggalkan bahagian kanan tidak berubah. Model ganjaran tertipu oleh ralat ini.

GPT-4 cuba melakukan pembahagian panjang, tetapi dalam langkah 16, ia terlupa untuk memasukkan sifar pendahuluan dalam bahagian berulang perpuluhan. Model ganjaran tertipu oleh ralat ini.

GPT-4 membuat ralat pengiraan halus dalam langkah 9.
Pada zahirnya, dakwaan bahawa terdapat 5 cara untuk menukar bola dengan warna yang sama (memandangkan terdapat 5 warna) nampaknya munasabah.
Namun, kiraan ini dipandang remeh dengan faktor 2 kerana Bob mempunyai 2 pilihan iaitu bola yang mana hendak diberikan kepada Alice. Model ganjaran tertipu oleh ralat ini.

Walaupun model bahasa yang besar telah bertambah baik dari segi keupayaan penaakulan yang kompleks, malah model yang paling maju. masih menghasilkan kesilapan logik atau karut, yang sering dipanggil "ilusi".
Dalam kegilaan kecerdasan buatan generatif, ilusi model bahasa yang besar sentiasa menyusahkan orang ramai.
Musk berkata, apa yang kita perlukan ialah TruthGPT
Sebagai contoh, baru-baru ini, seorang peguam Amerika memfailkan di mahkamah persekutuan New York Dia memetik kes rekaan ChatGPT dan mungkin menghadapi sekatan.
Penyelidik OpenAI menyebut dalam laporan itu: “Ilusi ini amat bermasalah dalam bidang yang memerlukan penaakulan berbilang langkah, kerana ralat logik yang mudah boleh menyebabkan kerosakan besar kepada keseluruhan penyelesaian ”
Selain itu, mengurangkan halusinasi juga merupakan kunci untuk membina AGI yang konsisten.
Bagaimana untuk mengurangkan ilusi model besar? Secara umumnya terdapat dua kaedah - penyeliaan proses dan penyeliaan hasil.
"Penyeliaan hasil", seperti namanya, adalah untuk memberi maklum balas kepada model besar berdasarkan keputusan akhir, manakala "penyeliaan proses" boleh memberikan maklum balas untuk setiap langkah dalam rantaian pemikiran.

Dalam penyeliaan proses, model besar diberi ganjaran untuk langkah penaakulan yang betul, bukan hanya kesimpulan akhir yang betul. Proses ini akan menggalakkan model mengikuti lebih banyak rantai kaedah pemikiran seperti manusia, sekali gus menjadikannya lebih berkemungkinan untuk mencipta AI yang boleh dijelaskan dengan lebih baik.
Penyelidik OpenAI berkata walaupun penyeliaan proses tidak dicipta oleh OpenAI, OpenAI sedang berusaha keras untuk memajukannya.
Dalam penyelidikan terkini, OpenAI mencuba kedua-dua kaedah "penyeliaan keputusan" atau "penyeliaan proses". Dan menggunakan set data MATH sebagai platform ujian, perbandingan terperinci kedua-dua kaedah dijalankan.
Didapati bahawa "penyeliaan proses" boleh meningkatkan prestasi model dengan ketara.
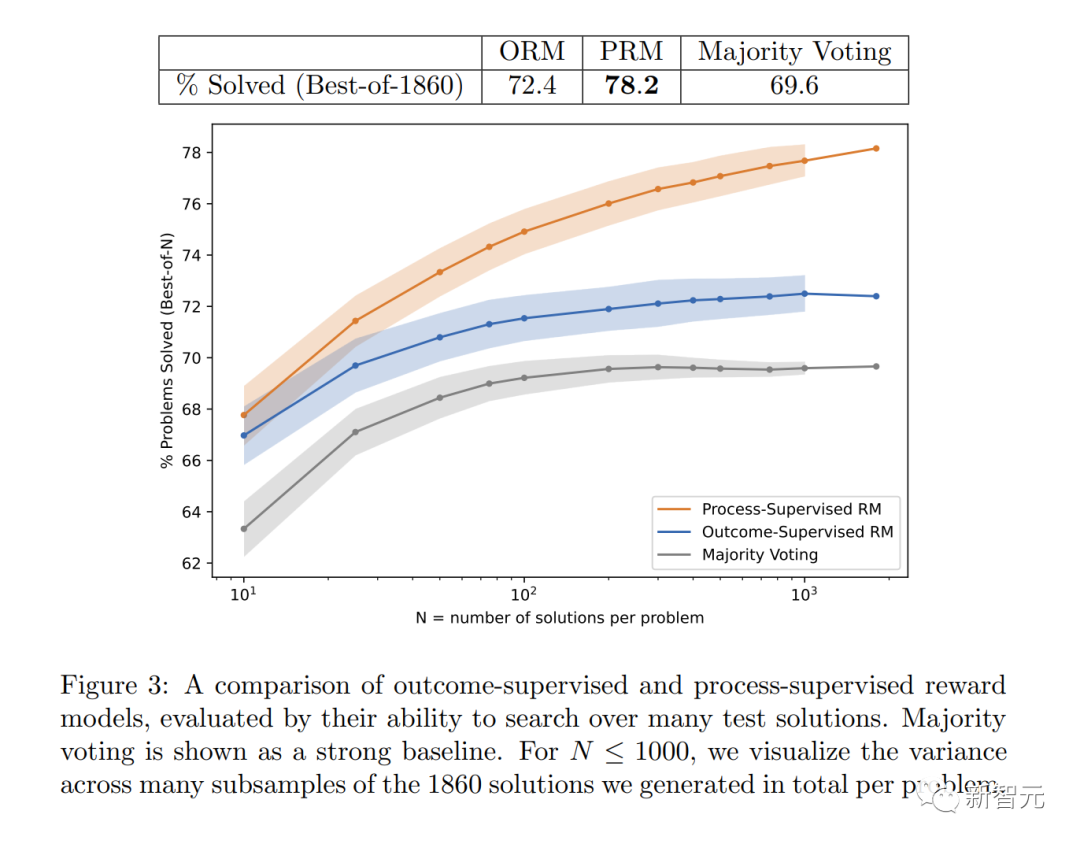
Untuk tugasan matematik, "penyeliaan prosedur" menghasilkan keputusan yang jauh lebih baik untuk kedua-dua model besar dan kecil, bermakna model itu secara amnya betul, dan juga mempamerkan proses pemikiran yang lebih seperti manusia.
Dengan cara ini, ilusi atau ralat logik yang sukar dielakkan walaupun dalam model yang paling berkuasa dapat dikurangkan.
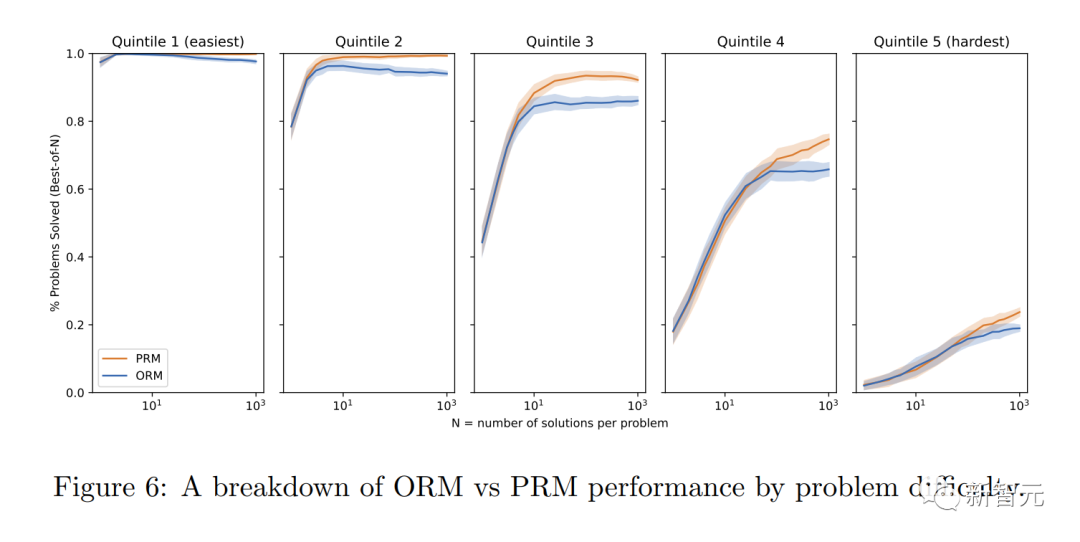
Para penyelidik mendapati bahawa "penyeliaan proses" mempunyai beberapa kelebihan penjajaran berbanding "penyeliaan keputusan" :
· Ganjaran langsung mengikut rantaian model pemikiran yang konsisten kerana setiap langkah dalam proses itu diawasi dengan tepat.
· Lebih cenderung untuk menghasilkan penaakulan yang boleh ditafsir kerana "penyeliaan proses" menggalakkan model mengikuti proses yang diluluskan oleh manusia. Sebaliknya, pemantauan hasil mungkin memberi ganjaran kepada proses yang tidak konsisten dan selalunya lebih sukar untuk disemak.
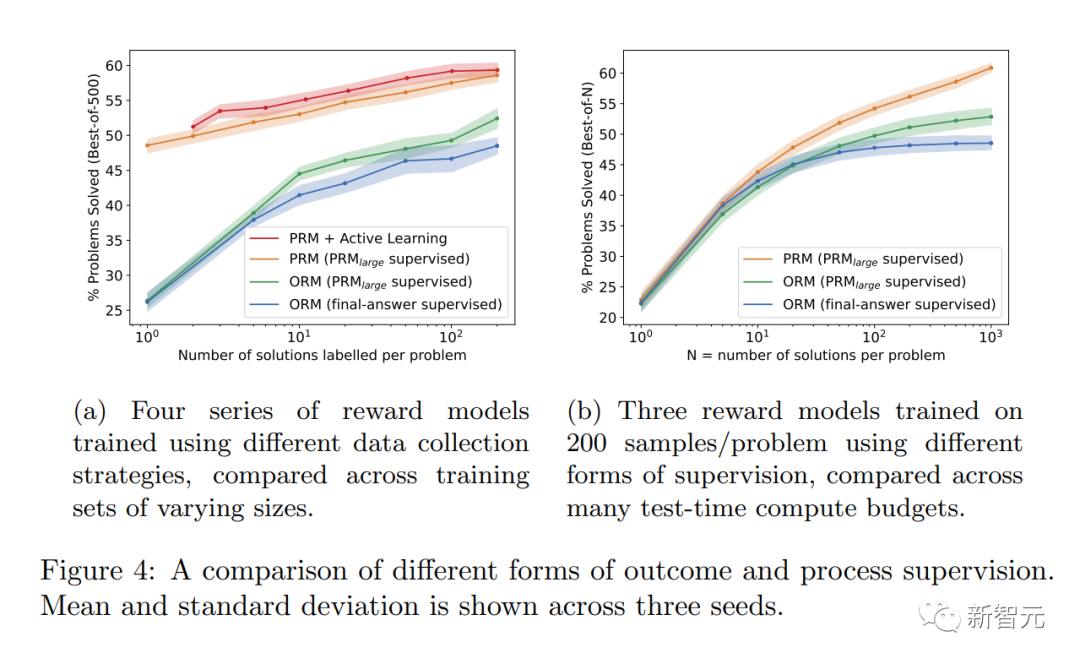
Perlu juga dinyatakan bahawa dalam sesetengah kes, kaedah menjadikan sistem AI lebih selamat boleh mengakibatkan kemerosotan prestasi. Kos ini dipanggil "cukai penjajaran."
Secara umumnya, sebarang kos "cukai penjajaran" mungkin menghalang penggunaan kaedah penjajaran untuk menggunakan model yang paling berkebolehan.
Walau bagaimanapun, keputusan penyelidik berikut menunjukkan bahawa "penyeliaan proses" sebenarnya menghasilkan "cukai penjajaran negatif" semasa ujian domain matematik.
Boleh dikatakan tiada kehilangan prestasi besar akibat penjajaran.
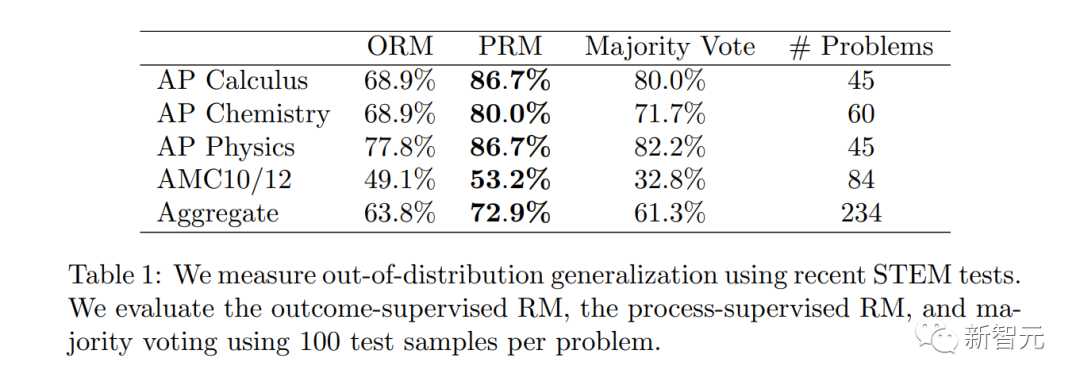
Perlu diambil perhatian bahawa PRM memerlukan lebih banyak anotasi manusia, atau adakah ia mendalam Saya tidak boleh hidup tanpa RLHF.
Sejauh mana kesesuaian penyeliaan proses dalam bidang selain matematik? Proses ini memerlukan penerokaan lanjut.
Penyelidik OpenAI telah membuka set data maklum balas manusia PRM ini, yang mengandungi 800,000 anotasi betul peringkat langkah: 75K penyelesaian yang dihasilkan daripada 12K masalah matematik

Berikut ialah contoh anotasi. OpenAI sedang mengeluarkan anotasi mentah, bersama-sama dengan arahan kepada anotor semasa Fasa 1 dan 2 projek.
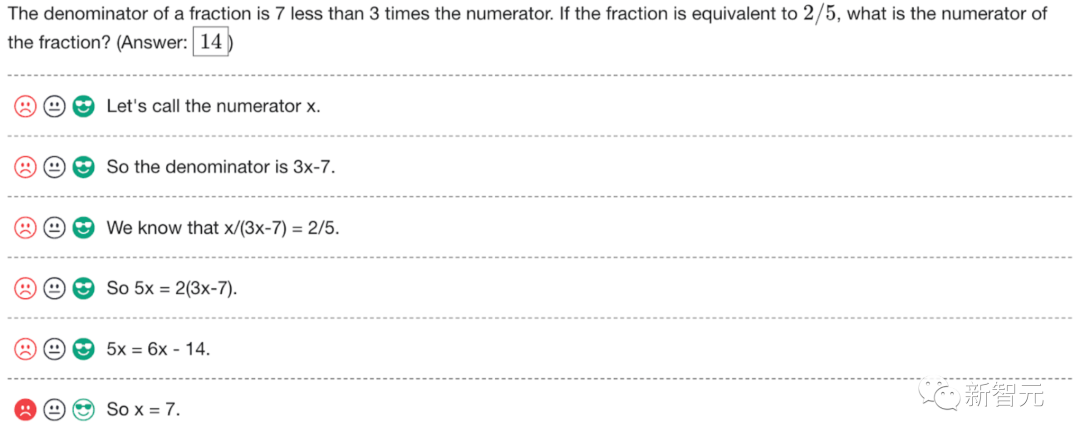
Saintis NVIDIA Jim Fan membuat ringkasan penyelidikan terbaru OpenAI:
Untuk Soalan langkah demi langkah mencabar yang memberikan ganjaran pada setiap langkah dan bukannya ganjaran tunggal pada akhir. Pada asasnya, isyarat ganjaran padat > isyarat ganjaran jarang. Model Ganjaran Proses (PRM) boleh memilih penyelesaian untuk penanda aras MATH yang sukar dengan lebih baik daripada Model Ganjaran Hasil (ORM). Langkah seterusnya yang jelas ialah memperhalusi GPT-4 dengan PRM, yang artikel ini belum dilakukan lagi. Perlu diingatkan bahawa PRM memerlukan lebih banyak anotasi manusia. OpenAI mengeluarkan set data maklum balas manusia: 800K anotasi peringkat langkah pada 75K penyelesaian kepada 12K masalah matematik.
Ia seperti pepatah lama di sekolah, belajar berfikir .

Melatih model untuk berfikir, bukannya hanya mengeluarkan jawapan yang betul, akan menjadi pengubah permainan dalam menyelesaikan masalah yang kompleks.
CtGPT sangat lemah dalam matematik. Hari ini saya cuba menyelesaikan masalah matematik daripada buku matematik darjah 4. ChatGPT memberikan jawapan yang salah. Saya menyemak jawapan saya dengan jawapan daripada ChatGPT, jawapan daripada kebingungan AI, Google dan guru darjah empat saya. Ia boleh disahkan di mana-mana bahawa jawapan chatgpt adalah salah.

Rujukan: //m.sbmmt.com/link/daf642455364613e2120c636b5a1f9c7
Atas ialah kandungan terperinci Keupayaan matematik GPT-4 adalah hebat! Penyelidikan eksplosif OpenAI mengenai 'Pengawasan Proses' memecahkan 78.2% masalah dan menghapuskan halusinasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!


















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



