


Seorang lelaki bernama Bloom mencadangkan penapis Bloom (nama Inggeris: Penapis Bloom) pada tahun 1970. Ia sebenarnya vektor binari yang panjang dan satu siri fungsi pemetaan rawak. Penapis Bloom boleh digunakan untuk mendapatkan semula sama ada elemen berada dalam koleksi. Kelebihannya ialah kecekapan ruang dan masa pertanyaan jauh lebih tinggi daripada algoritma umum, tetapi kelemahannya ialah ia mempunyai kadar salah pengiktirafan tertentu dan kesukaran dalam pemadaman.
Prinsip Penapis Bloom ialah apabila elemen ditambah pada set, elemen itu dipetakan ke titik K dalam tatasusunan bit melalui fungsi cincang K, tetapkan kepada 1. Apabila mendapatkan semula, kita hanya perlu melihat sama ada mata ini kesemuanya 1 hingga (kira-kira) mengetahui sama ada ia berada dalam set: jika mana-mana mata ini mempunyai 0, maka elemen yang ditandakan mestilah tidak ada di sana jika kesemuanya 1, maka elemen yang diperiksa Kemungkinan besar. Ini adalah idea asas penapis Bloom.
Perbezaan antara Penapis Bloom dan fungsi cincangan tunggal Bit-Map ialah Penapis Bloom menggunakan fungsi cincang k, dan setiap rentetan sepadan dengan k bit. Dengan itu mengurangkan kebarangkalian konflik
Setiap pertanyaan akan dipukul terus ke DB
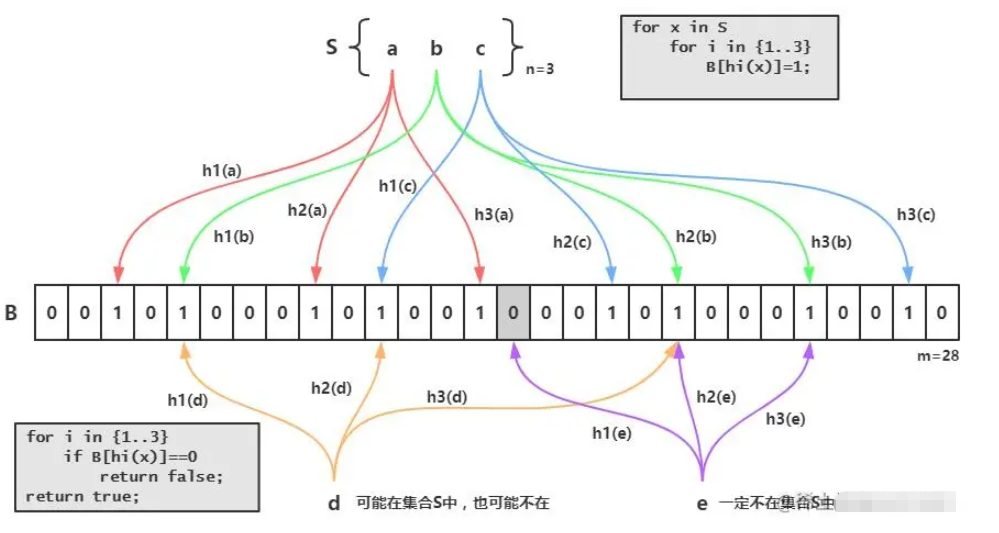
Ringkasnya, secara ringkasnya, kami mula-mula memuatkan semua data daripada pangkalan data kami ke dalam penapis kami Contohnya, id pangkalan data kini mempunyai: 1, 2, 3
Kemudian gunakan id: 1. ialah contoh. Selepas pencincangan tiga kali dalam gambar di atas, dia menukar tiga tempat di mana nilai asalnya ialah 0 kepada 1
Jika nilai id ialah 1 apabila data masuk untuk pertanyaan pada kali seterusnya, maka Saya akan meletakkan 1 Ambil tiga cincang dan mendapati bahawa nilai tiga cincang adalah betul-betul sama dengan tiga kedudukan di atas, yang boleh membuktikan bahawa terdapat 1 dalam penapis
Sebaliknya, jika mereka berbeza, bermakna ia tidak wujud
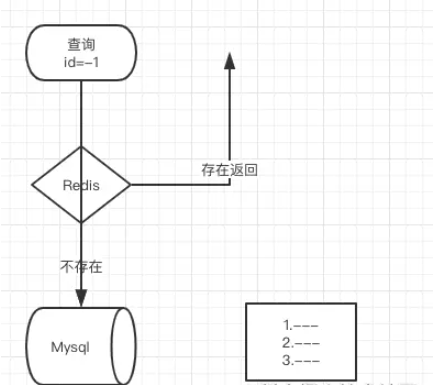
Jadi di manakah senario aplikasi? Secara umumnya kami akan menggunakannya untuk mengelakkan kerosakan cache
Ringkasnya, id pangkalan data anda bermula dengan 1 dan kemudian meningkat dengan sendirinya Kemudian saya tahu bahawa antara muka anda disoal oleh id, jadi saya akan menggunakan negatif nombor untuk pertanyaan Pada masa ini, anda akan mendapati bahawa data tidak berada dalam cache, dan saya pergi ke pangkalan data untuk menyemaknya, tetapi ia tidak dijumpai seperti ini, bagaimana dengan 100, 1,000, atau 10,000 ? DB anda pada asasnya tidak dapat mengendalikannya Jika anda menambah ini pada cache, ia tidak akan wujud lagi Jika anda menilai bahawa tiada data sedemikian, anda tidak akan menyemaknya itu kosong?
Perkara ini sangat bagus, jadi apakah kelemahannya? Ya, mari kita teruskan untuk melihat
Sebab penapis bloom boleh menjadi lebih cekap dalam masa dan ruang adalah kerana ia mengorbankan ketepatan penghakiman
Walaupun bekas mungkin tidak mengandungi elemen yang sepatutnya ditemui, disebabkan oleh operasi cincang, nilai elemen ini dalam kedudukan cincang k adalah kesemuanya 1, jadi ia mungkin membawa kepada salah penilaian. Dengan mewujudkan senarai putih untuk menyimpan elemen yang mungkin salah dinilai, apabila senarai hitam disimpan dalam Penapis Bloom, kadar salah penilaian boleh dikurangkan.
Memadam adalah sukar. Elemen yang diletakkan dalam bekas dipetakan kepada 1 dalam kedudukan k tatasusunan bit Apabila memadam, ia tidak boleh ditetapkan secara langsung kepada 0, kerana ia boleh menjejaskan pertimbangan elemen lain. Anda boleh menggunakan Counting Bloom Filter
1 Mengapa menggunakan pelbagai fungsi cincang?
Jika hanya satu fungsi cincang digunakan, Hash itu sendiri selalunya akan bercanggah. Sebagai contoh, untuk tatasusunan dengan panjang 100, jika hanya satu fungsi cincang digunakan, selepas menambah elemen, kebarangkalian konflik apabila menambah elemen kedua ialah 1%, dan kebarangkalian konflik apabila menambah elemen ketiga ialah 2 %... Tetapi jika dua elemen ditambah, kebarangkalian konflik ialah 1%. A fungsi cincang, selepas menambah elemen, kebarangkalian konflik apabila menambah elemen kedua dikurangkan kepada 4 daripada 10,000 (empat kemungkinan situasi konflik, jumlah bilangan situasi 100x100)
package main
import (
"fmt"
"github.com/bits-and-blooms/bitset"
)
//设置哈希数组默认大小为16
const DefaultSize = 16
//设置种子,保证不同哈希函数有不同的计算方式
var seeds = []uint{7, 11, 13, 31, 37, 61}
//布隆过滤器结构,包括二进制数组和多个哈希函数
type BloomFilter struct {
//使用第三方库
set *bitset.BitSet
//指定长度为6
hashFuncs [6]func(seed uint, value string) uint
}
//构造一个布隆过滤器,包括数组和哈希函数的初始化
func NewBloomFilter() *BloomFilter {
bf := new(BloomFilter)
bf.set = bitset.New(DefaultSize)
for i := 0; i < len(bf.hashFuncs); i++ {
bf.hashFuncs[i] = createHash()
}
return bf
}
//构造6个哈希函数,每个哈希函数有参数seed保证计算方式的不同
func createHash() func(seed uint, value string) uint {
return func(seed uint, value string) uint {
var result uint = 0
for i := 0; i < len(value); i++ {
result = result*seed + uint(value[i])
}
//length = 2^n 时,X % length = X & (length - 1)
return result & (DefaultSize - 1)
}
}
//添加元素
func (b *BloomFilter) add(value string) {
for i, f := range b.hashFuncs {
//将哈希函数计算结果对应的数组位置1
b.set.Set(f(seeds[i], value))
}
}
//判断元素是否存在
func (b *BloomFilter) contains(value string) bool {
//调用每个哈希函数,并且判断数组对应位是否为1
//如果不为1,直接返回false,表明一定不存在
for i, f := range b.hashFuncs {
//result = result && b.set.Test(f(seeds[i], value))
if !b.set.Test(f(seeds[i], value)) {
return false
}
}
return true
}
func main() {
filter := NewBloomFilter()
filter.add("asd")
fmt.Println(filter.contains("asd"))
fmt.Println(filter.contains("2222"))
fmt.Println(filter.contains("155343"))
}Hasil output adalah seperti berikut:
benar
salah
salah
Atas ialah kandungan terperinci Bagaimana untuk melaksanakan penapis Redis BloomFilter Bloom. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan
 Apakah pangkalan data dalam memori?
Apakah pangkalan data dalam memori?
 Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
 Cara menggunakan redis sebagai pelayan cache
Cara menggunakan redis sebagai pelayan cache
 Bagaimana redis menyelesaikan ketekalan data
Bagaimana redis menyelesaikan ketekalan data
 Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
 Apakah data yang biasanya disimpan oleh redis cache?
Apakah data yang biasanya disimpan oleh redis cache?
 Apakah 8 jenis data redis
Apakah 8 jenis data redis








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



