


如果一个集合只包含不多的整数元素,那么Redis会使用整数集合intset。首先看 intset 的数据结构:
typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; } intset;
其实 intset 的数据结构比较好理解。一个数据保存元素,length 保存元素的数量,也就是contents的大小,encoding 用于保存数据的编码方式。
通过代码我们可以知道,encoding 的编码类型包括了:
#define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))
实际上我们可以看出来。 Redis encoding的类型,就是指数据的大小。作为一个内存数据库,采用这种设计就是为了节约内存。
既然有从小到大的三个数据结构,在插入数据的时候尽可能使用小的数据结构来节约内存,如果插入的数据大于原有的数据结构,就会触发扩容。
扩容有三个步骤:
根据新元素的类型,修改整个数组的数据类型,并重新分配空间
将原有的的数据,装换为新的数据类型,重新放到应该在的位置上,且保存顺序性
再插入新元素
整数集合不支持降级操作,一旦升级就不能降级了。
跳跃表是链表的一种,是一种利用空间换时间的数据结构。跳表平均支持 O(logN),最坏O(N)复杂度的查找。
跳表是由一个zskiplist 和 多个 zskiplistNode 组成。我们先看看他们的结构:
/* ZSETs use a specialized version of Skiplists *//* * 跳跃表节点 */ typedef struct zskiplistNode { // 成员对象 robj *obj; // 分值 double score; // 后退指针 struct zskiplistNode *backward; // 层 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; // 跨度 unsigned int span; } level[]; } zskiplistNode; /* * 跳跃表 */ typedef struct zskiplist { // 表头节点和表尾节点 struct zskiplistNode *header, *tail; // 表中节点的数量 unsigned long length; // 表中层数最大的节点的层数 int level; } zskiplist;
所以根据这个代码我们可以画出如下的结构图:
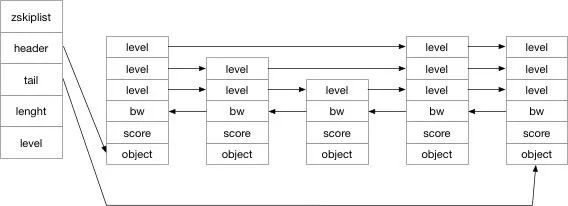
其实跳表就是一个利用空间换时间的数据结构,利用 level 作为链表的索引。
之前有人问过 Redis 的作者 为什么使用跳跃表,而不是 tree 来构建索引?作者的回答是:
省内存。
在使用ZRANGE或ZREVRANGE时,涉及到的是典型的链表操作场景。时间复杂度的表现和平衡树差不多。
最重要的一点是跳跃表的实现很简单就能达到 O(logN)的级别。
压缩链表 Redis 作者的介绍是,为了尽可能节约内存设计出来的双向链表。
对于一个压缩列表代码里注释给出的数据结构如下:
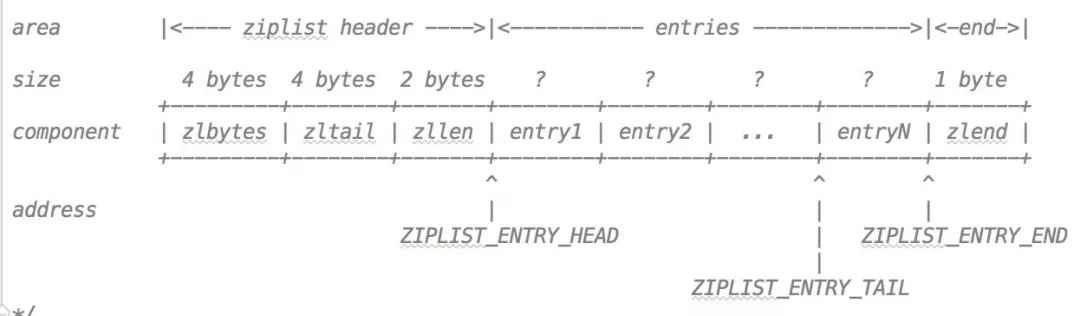
zlbytes表示的是整个压缩列表使用的内存字节数
zltail指定了压缩列表的尾节点的偏移量
zllen是压缩列表 entry 的数量
entry就是 ziplist 的节点
zlend标记压缩列表的末端
这个列表中还有单个指针:
ZIPLIST_ENTRY_HEAD列表开始节点的头偏移量
ZIPLIST_ENTRY_TAIL列表结束节点的头偏移量
ZIPLIST_ENTRY_END列表的尾节点结束的偏移量
再看看一个 entry 的结构:
/* * 保存 ziplist 节点信息的结构 */ typedef struct zlentry { // prevrawlen :前置节点的长度 // prevrawlensize :编码 prevrawlen 所需的字节大小 unsigned int prevrawlensize, prevrawlen; // len :当前节点值的长度 // lensize :编码 len 所需的字节大小 unsigned int lensize, len; // 当前节点 header 的大小 // 等于 prevrawlensize + lensize unsigned int headersize; // 当前节点值所使用的编码类型 unsigned char encoding; // 指向当前节点的指针 unsigned char *p; } zlentry;
依次解释一下这几个参数。
prevrawlen前置节点的长度,这里多了一个 size,其实是记录了 prevrawlen 的尺寸。Redis 为了节约内存并不是直接使用默认的 int 的长度,而是逐渐升级的。
同理len记录的是当前节点的长度,lensize记录的是 len 的长度。headersize就是前文提到的两个 size 之和。encoding就是这个节点的数据类型。这里注意一下 encoding 的类型只包括整数和字符串。p节点的指针,不用过多的解释。
需要注意一点,因为每个节点都保存了前一个节点的长度,如果发生了更新或者删除节点,则这个节点之后的数据也需要修改,有一种最坏的情况就是如果每个节点都处于需要扩容的零界点,就会造成这个节点之后的节点都要修改 size 这个参数,引发连锁反应。这个时候就是 压缩链表最坏的时间复杂度 O(n^2)。不过所有节点都处于临界值,这样的概率可以说比较小。
Atas ialah kandungan terperinci Redis的基础数据结构是怎样的. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan Apakah pangkalan data dalam memori?
Apakah pangkalan data dalam memori? Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis? Cara menggunakan redis sebagai pelayan cache
Cara menggunakan redis sebagai pelayan cache Bagaimana redis menyelesaikan ketekalan data
Bagaimana redis menyelesaikan ketekalan data Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali? Apakah data yang biasanya disimpan oleh redis cache?
Apakah data yang biasanya disimpan oleh redis cache? Apakah 8 jenis data redis
Apakah 8 jenis data redis




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



