


Kemunculan AI perbualan seperti ChatGPT telah membuatkan orang ramai terbiasa dengan perkara sedemikian: masukkan sekeping teks, kod atau gambar, dan robot perbualan akan memberikan jawapan yang anda inginkan. Tetapi di sebalik kaedah interaksi mudah ini, model AI perlu melakukan pemprosesan dan pengiraan data yang sangat kompleks, dan tokenisasi adalah perkara biasa.
Dalam bidang pemprosesan bahasa semula jadi, tokenisasi merujuk kepada membahagikan input teks kepada unit yang lebih kecil, dipanggil "token". Token ini boleh berupa perkataan, subkata atau aksara, bergantung pada strategi pembahagian perkataan dan keperluan tugas tertentu. Sebagai contoh, jika kita melakukan tokenisasi pada ayat "Saya suka makan epal", kita akan mendapat urutan token: ["Saya", "Suka", "Makan", "Epal"]. Sesetengah orang menterjemahkan tokenisasi kepada "pembahagian perkataan", tetapi sesetengah orang berpendapat bahawa terjemahan ini mengelirukan Lagipun, token yang dibahagikan mungkin bukan "perkataan" yang kita fahami setiap hari.
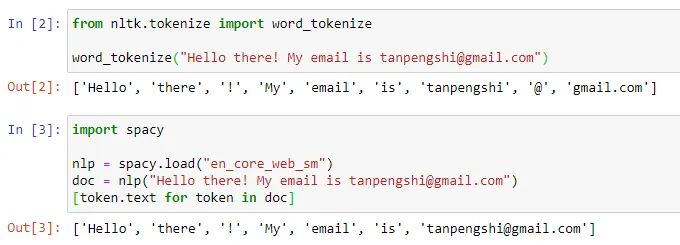
Sumber imej: https://towardsdatascience.com/dynamic-word-tokenization-with-regex -tokenizer-801ae839d1cd
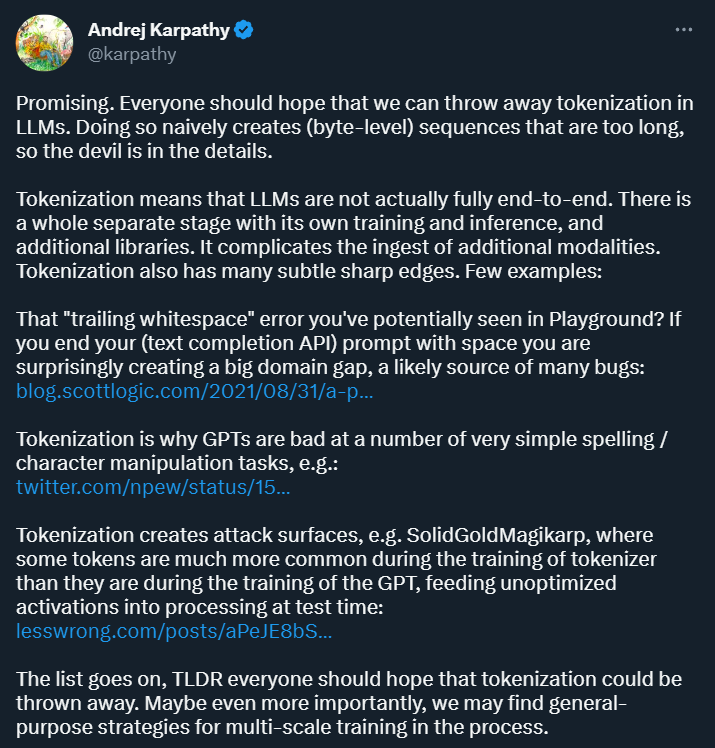
Tujuan Tokenisasi adalah untuk menukar data input ke dalam bentuk yang boleh diproses oleh komputer dan menyediakan perwakilan berstruktur untuk latihan dan analisis model seterusnya . Kaedah ini membawa kemudahan kepada penyelidikan pembelajaran mendalam, tetapi ia juga membawa banyak masalah. Andrej Karpathy, yang baru menyertai OpenAI suatu ketika dahulu, menunjukkan beberapa daripada mereka.
Pertama sekali, Karpathy percaya bahawa tokenisasi memperkenalkan kerumitan: dengan menggunakan tokenisasi, model bahasa bukanlah model hujung ke hujung yang lengkap. Ia memerlukan peringkat berasingan untuk tokenisasi, yang mempunyai proses latihan dan inferens sendiri dan memerlukan perpustakaan tambahan. Ini meningkatkan kerumitan memperkenalkan data daripada modaliti lain.
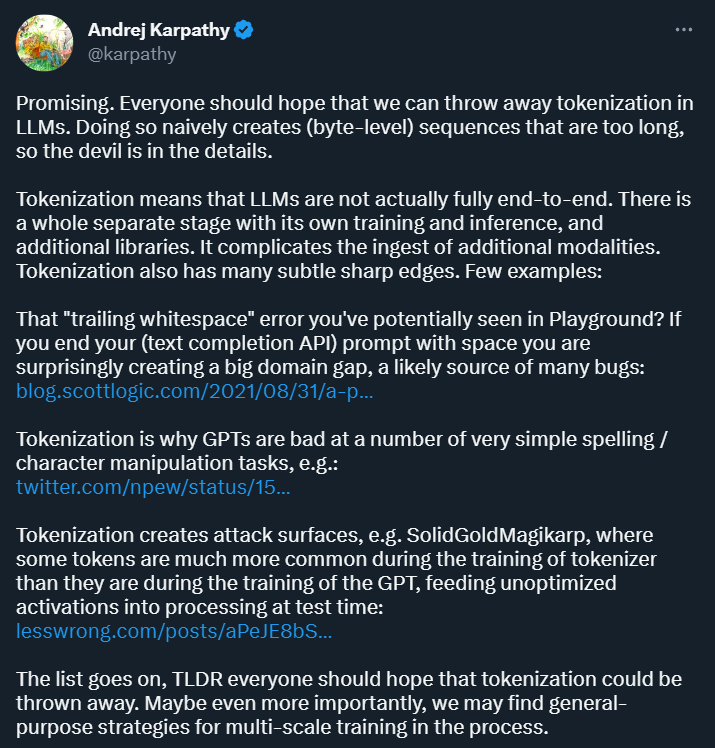
Selain itu, tokenisasi juga boleh menjadikan model terdedah kepada ralat dalam senario tertentu, seperti apabila menggunakan pelapik teks. Dengan API penuh, jika gesaan anda berakhir dengan ruang, hasil yang anda peroleh mungkin sangat berbeza.

Sumber imej: https://blog.scottlogic.com/2021/08/31/a -primer-on-the-openai-api-1.html
Untuk contoh lain, kerana kewujudan tokenisasi, ChatGPT yang berkuasa tidak akan menulis perkataan secara terbalik ( di bawah Keputusan ujian adalah daripada GPT 3.5).
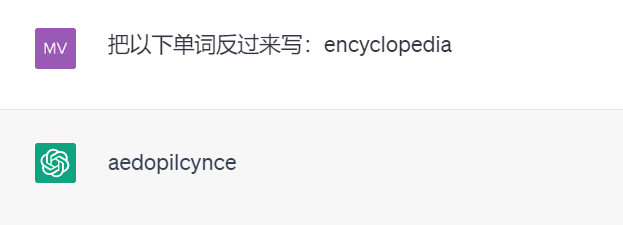
Mungkin terdapat banyak contoh sedemikian. Karpathy percaya bahawa untuk menyelesaikan masalah ini, kita mesti meninggalkan tokenisasi terlebih dahulu.
Sebuah kertas kerja baharu yang diterbitkan oleh Meta AI meneroka soalan ini. Secara khusus, mereka mencadangkan seni bina penyahkod berbilang skala yang dipanggil "MEGABYTE" yang boleh melaksanakan pemodelan boleh dibezakan hujung ke hujung bagi jujukan melebihi satu juta bait.

Pautan kertas: https://arxiv.org/pdf/2305.07185.pdf
Yang penting, kertas kerja ini menunjukkan kemungkinan untuk meninggalkan tokenisasi dan dinilai sebagai "berjanji" oleh Karpathy.
Berikut ialah butiran kertas tersebut.
Seperti yang dinyatakan dalam artikel pembelajaran mesin, sebab pembelajaran mesin nampaknya dapat menyelesaikan banyak masalah kompleks adalah kerana ia mengubah masalah ini menjadi untuk masalah matematik.
NLP mempunyai idea yang sama adalah "data tidak berstruktur" terlebih dahulu ", data berstruktur boleh diubah menjadi masalah matematik, dan pembahagian perkataan adalah langkah pertama dalam transformasi.
Disebabkan kos mekanisme perhatian kendiri yang tinggi dan rangkaian suapan ke hadapan yang besar, penyahkod transformer besar (LLM) biasanya hanya menggunakan beribu-ribu token konteks. Ini sangat mengehadkan set tugas yang LLM boleh digunakan.
Berdasarkan perkara ini, penyelidik dari Meta AI mencadangkan kaedah baharu untuk memodelkan jujukan bait panjang - MEGABYTE. Kaedah ini membahagikan jujukan bait kepada tampungan bersaiz tetap, serupa dengan token.
Model MEGABYTE terdiri daripada tiga bahagian:
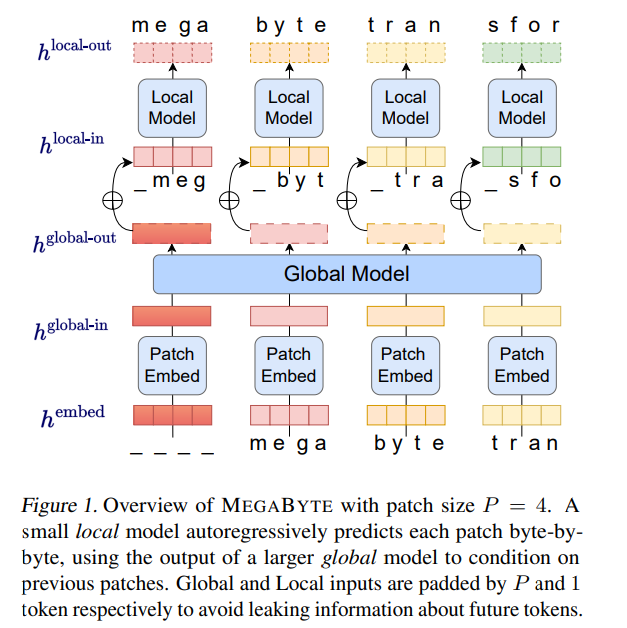 Seni bina MEGABYTE telah membuat tiga penambahbaikan besar pada Transformer untuk pemodelan jujukan panjang:
Seni bina MEGABYTE telah membuat tiga penambahbaikan besar pada Transformer untuk pemodelan jujukan panjang:
perhatian diri sub-kuadrat
. Kebanyakan kerja pada model jujukan panjang memfokuskan pada mengurangkan kos kuadratik perhatian diri. Dengan menguraikan jujukan yang panjang kepada dua jujukan yang lebih pendek dan saiz tampung yang optimum, MEGABYTE mengurangkan kos mekanisme perhatian kendiri kepada , menjadikan jujukan yang panjang pun mudah untuk diproses. 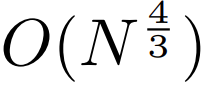
. Dalam model yang sangat besar seperti GPT-3, lebih daripada 98% FLOPS digunakan untuk mengira lapisan suapan ke hadapan mengikut kedudukan. MEGABYTE mendayakan model yang lebih besar dan lebih ekspresif pada kos yang sama dengan menggunakan lapisan suapan hadapan yang besar bagi setiap tampung (bukannya setiap kedudukan). Dengan saiz tampung P, pengubah garis dasar akan menggunakan lapisan suapan hadapan yang sama dengan parameter m P kali, manakala MEGABYTE hanya perlu menggunakan lapisan dengan parameter mP sekali pada kos yang sama. 3.
Penyahkod selari. Transformer mesti melakukan semua pengiraan secara bersiri semasa penjanaan kerana input setiap langkah masa adalah output langkah masa sebelumnya. Dengan menjana perwakilan tampalan secara selari, MEGABYTE mencapai keselarian yang lebih besar dalam proses penjanaan. Sebagai contoh, model MEGABYTE dengan parameter 1.5B menjana jujukan 40% lebih pantas daripada pengubah parameter 350M standard, di samping menambah baik kebingungan apabila dilatih menggunakan pengiraan yang sama. Secara keseluruhan, MEGABYTE membolehkan kami melatih model yang lebih besar dan berprestasi lebih baik dengan belanjawan pengiraan yang sama, akan dapat mengendalikan urutan yang sangat panjang dan meningkatkan penjanaan semasa kelajuan penggunaan.
MEGABYTE juga berbeza dengan model autoregresif sedia ada, yang biasanya menggunakan beberapa bentuk tokenisasi di mana jujukan bait dipetakan ke dalam token diskret yang lebih besar (Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al. , 2021). Tokenisasi merumitkan prapemprosesan, pemodelan multimodal dan pemindahan ke domain baharu, sambil menyembunyikan struktur berguna dalam model. Ini bermakna kebanyakan model SOTA bukanlah model hujung ke hujung yang sebenar. Kaedah tokenisasi yang paling banyak digunakan memerlukan penggunaan heuristik khusus bahasa (Radford et al., 2019) atau kehilangan maklumat (Ramesh et al., 2021). Oleh itu, menggantikan tokenisasi dengan model bait yang cekap dan berprestasi akan mempunyai banyak kelebihan.
Kajian ini menjalankan eksperimen pada MEGABYTE dan beberapa model garis dasar yang berkuasa. Keputusan percubaan menunjukkan bahawa MEGABYTE berprestasi setanding dengan model subkata pada pemodelan bahasa konteks panjang, mencapai kebingungan anggaran ketumpatan terkini pada ImageNet dan membenarkan pemodelan audio daripada fail audio mentah. Keputusan eksperimen ini menunjukkan kebolehlaksanaan pemodelan jujukan autoregresif bebas tokenisasi berskala besar.

pembenam patch
Pembenam tampalan saiz P boleh memetakan jujukan bait
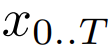
ke dalam urutan panjang
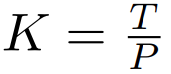
, tampalan urutan pembenaman dengan dimensi
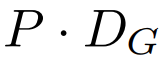
.
Pertama, setiap bait dibenamkan dengan jadual carian
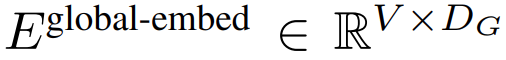
, membentuk benam saiz D_G dan menambah benam kedudukan.
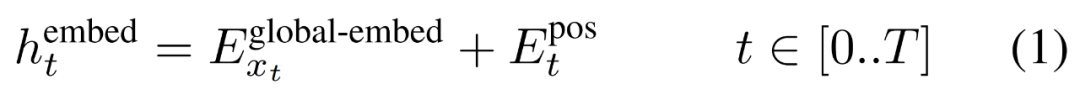
Kemudian, pembenaman bait dibentuk semula menjadi dimensi
Jujukan daripada tampung K yang dibenamkan dalam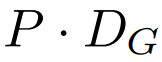
. Untuk membenarkan pemodelan autoregresif, urutan tampalan dilapisi dengan pembenaman padding daripada saiz tampalan boleh dilatih (
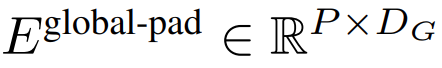
), dan kemudian daripada input Alih keluar tampalan terakhir. Urutan ini ialah input kepada model global, diwakili sebagai
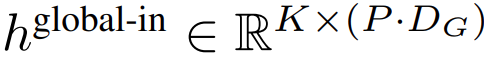
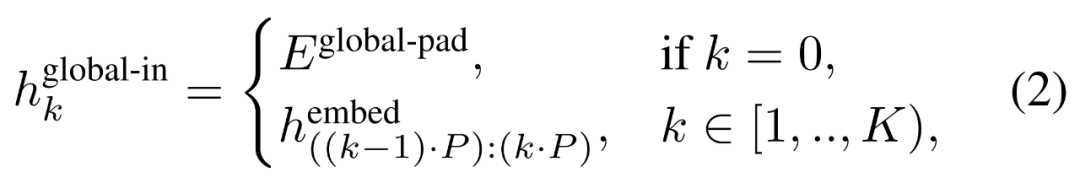
Modul global
Modul global ialah model pengubah dimensi P・D_G seni bina penyahkod sahaja yang beroperasi pada jujukan tampung k. Modul global menggabungkan mekanisme perhatian kendiri dan topeng penyebab untuk menangkap kebergantungan antara patch. Modul global memasukkan perwakilan jujukan tampalan k
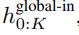
dan mengeluarkan perwakilan yang dikemas kini
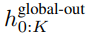
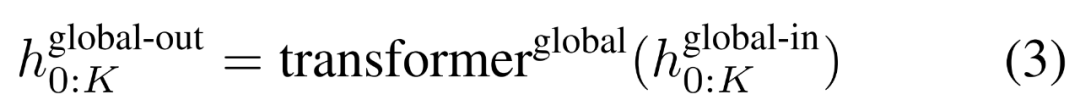
, dengan D_L ialah dimensi modul tempatan. Ini kemudiannya digabungkan dengan pembenaman bait bersaiz D_L untuk token
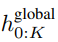
seterusnya.
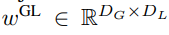
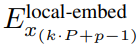
Modul tempatan
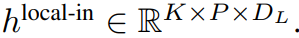
Modul tempatan ialah model pengubah dimensi D_L yang lebih kecil, seni bina penyahkod yang mengandungi elemen P tampung tunggal k, setiap elemen ialah jumlah output modul global dan pembenaman bait sebelumnya dalam jujukan. K salinan modul tempatan dijalankan secara berasingan pada setiap tampalan dan selari semasa latihan, dengan itu mengira perwakilan
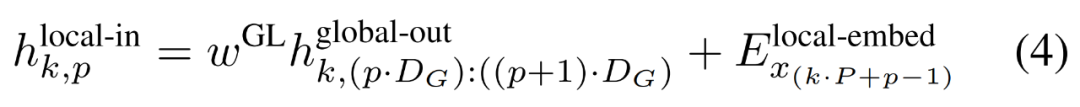
Akhir sekali, pengkaji dapat mengira taburan kebarangkalian perkataan bagi setiap kedudukan. Elemen p-th tampalan k-th sepadan dengan elemen t urutan lengkap, di mana t = k·P + p.
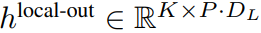

Para penyelidik menganalisis kos seni bina yang berbeza apabila menskalakan panjang jujukan dan saiz model. Seperti yang ditunjukkan dalam Rajah 3 di bawah, seni bina MEGABYTE menggunakan lebih sedikit FLOPS daripada transformer bersaiz setanding dan transformer linear merentas pelbagai saiz model dan panjang jujukan, membenarkan penggunaan model yang lebih besar pada kos pengiraan yang sama. 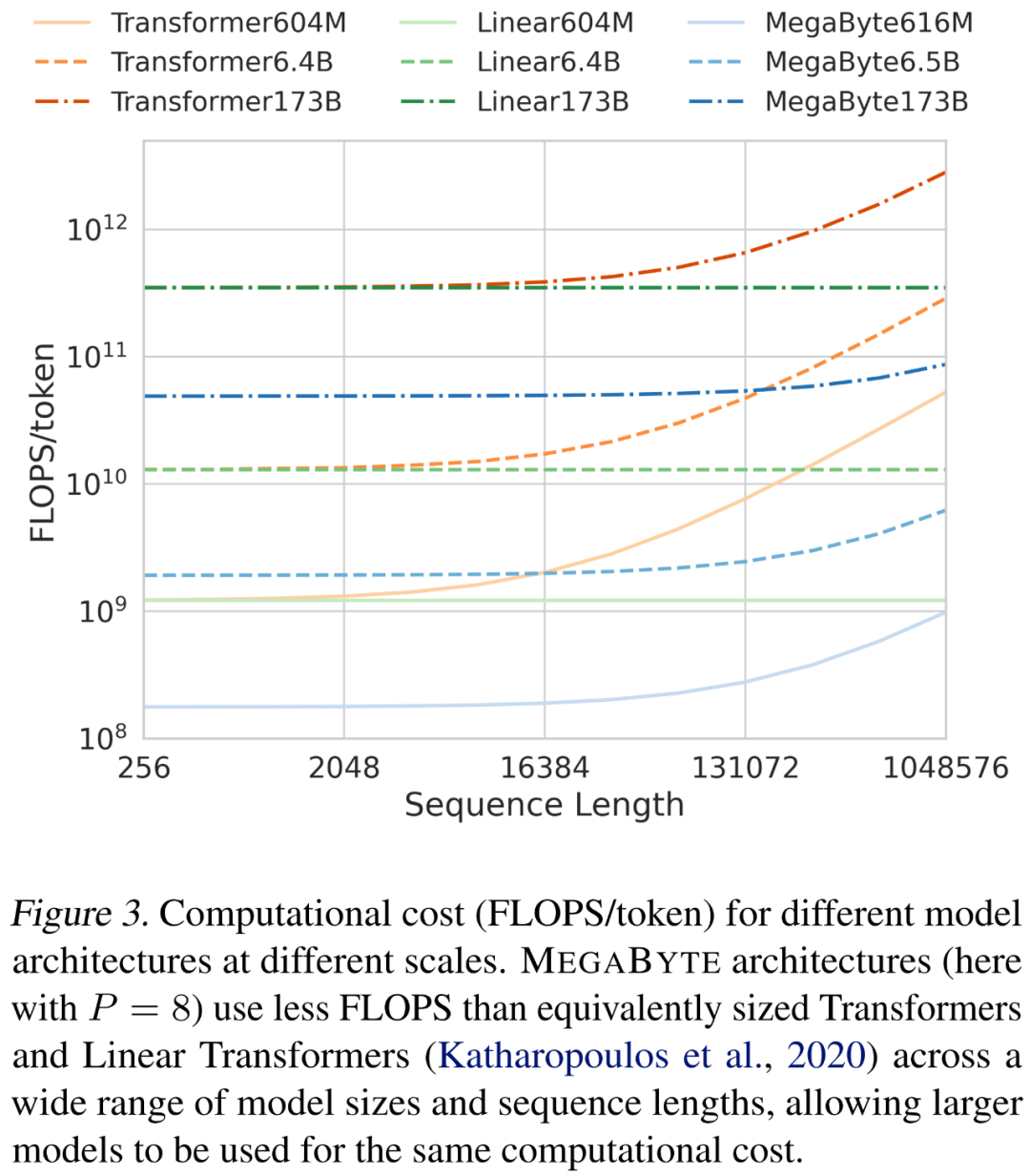
Kecekapan penjanaan
Pertimbangkan yang ini Model MEGABYTE, yang mempunyai lapisan L_global dalam model global dan lapisan L_local dalam modul tempatan, saiz tampalan ialah P dan dibandingkan dengan seni bina pengubah dengan lapisan L_local + L_global. Menjana setiap tampung dengan MEGABYTE memerlukan urutan O (L_global + P・L_local) bagi operasi bersiri. Apabila L_global ≥ L_local (modul global mempunyai lebih banyak lapisan daripada modul tempatan), MEGABYTE boleh mengurangkan kos inferens hampir P kali ganda.
Pemodelan bahasa
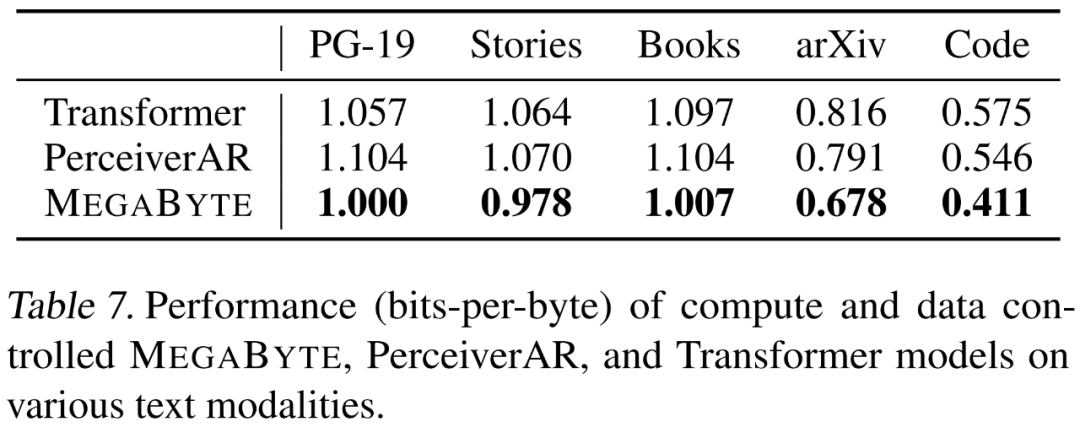
Penyelidik menekankan 5 aspek pergantungan jarak jauh Keupayaan pemodelan bahasa MEGABYTE dinilai pada set data yang berbeza, iaitu Projek Gutenberg (PG-19), Buku, Cerita, arXiv dan Kod. Keputusan ditunjukkan dalam Jadual 7 di bawah, MEGABYTE secara konsisten mengatasi pengubah garis dasar dan PerceiverAR pada semua set data.
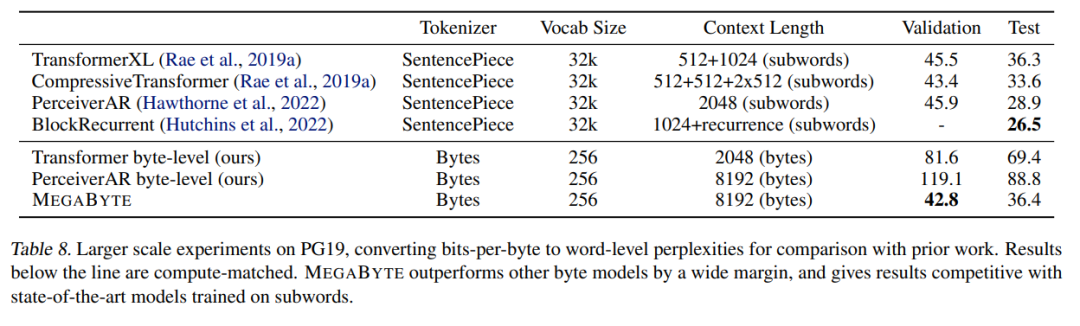
Para penyelidik juga memanjangkan data latihan pada PG-19 Keputusan ditunjukkan dalam Jadual 8 di bawah ketara Mengungguli model bait lain dan setanding dengan model SOTA yang dilatih pada subkata.
Pemodelan Imej
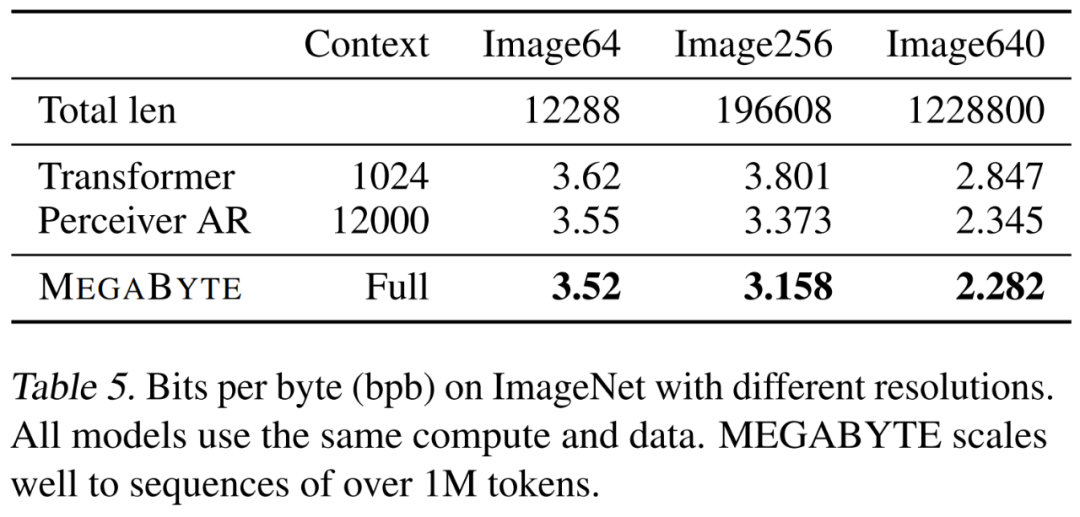
Penyelidik A besar Model MEGABYTE telah dilatih pada set data ImageNet 64x64, di mana parameter modul global dan tempatan masing-masing adalah 2.7B dan 350M, dan terdapat token 1.4T. Mereka menganggarkan bahawa latihan model mengambil masa kurang daripada separuh jumlah jam GPU yang diperlukan untuk menghasilkan semula model PerceiverAR terbaik dalam kertas Hawthorne et al., 2022. Seperti yang ditunjukkan dalam Jadual 8 di atas, MEGABYTE mempunyai prestasi yang setanding dengan SOTA PerceiverAR, sambil menggunakan hanya separuh daripada pengiraan yang terakhir.
Para penyelidik membandingkan tiga varian transformer, iaitu vanila, PerceiverAR dan MEGABYTE, untuk menguji kebolehskalaan jujukan panjang pada resolusi imej yang semakin besar. Keputusan ditunjukkan dalam Jadual 5 di bawah di bawah tetapan kawalan pengiraan ini, MEGABYTE mengatasi model garis dasar pada semua resolusi.
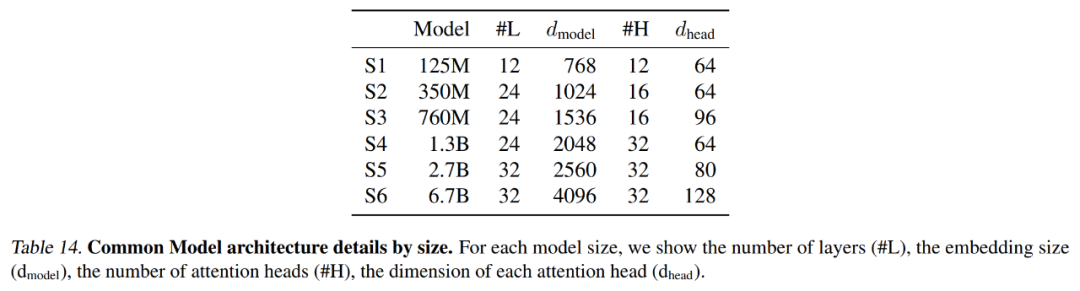
Jadual 14 di bawah meringkaskan tetapan tepat yang digunakan oleh setiap model garis dasar, termasuk panjang konteks dan bilangan pendam.
Pemodelan audio
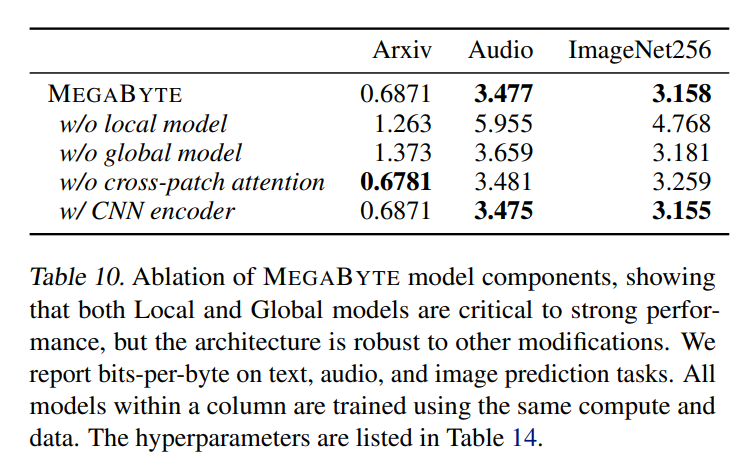
Rangkap audio Dengan struktur teks yang berurutan dan sifat imej yang berterusan, ini adalah aplikasi yang menarik untuk MEGABYTE. Model dalam artikel ini memperoleh bpb 3.477, yang jauh lebih rendah daripada perceiverAR (3.543) dan model pengubah vanila (3.567). Keputusan ablasi tambahan diperincikan dalam Jadual 10 di bawah.
Untuk butiran lanjut teknikal dan keputusan percubaan, sila rujuk kertas asal.
Atas ialah kandungan terperinci Adakah perlu 'participle'? Andrej Karpathy: Sudah tiba masanya untuk membuang bagasi bersejarah ini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah mata wang BTC?
Apakah mata wang BTC?
 Bagaimana untuk membuka fail dmp
Bagaimana untuk membuka fail dmp
 Bagaimana untuk memadam data dalam MongoDB
Bagaimana untuk memadam data dalam MongoDB
 Pengenalan kepada penggunaan fungsi sort() dalam python
Pengenalan kepada penggunaan fungsi sort() dalam python
 Bagaimana untuk memuat turun fail flv
Bagaimana untuk memuat turun fail flv
 Bagaimana untuk menyelesaikan masalah yang tomcat tidak dapat memaparkan halaman
Bagaimana untuk menyelesaikan masalah yang tomcat tidak dapat memaparkan halaman
 Kad grafik 940mx
Kad grafik 940mx
 Bagaimana untuk membeli dan menjual Bitcoin di okex
Bagaimana untuk membeli dan menjual Bitcoin di okex





















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



