


Dalam pancaindera manusia, gambar boleh menggabungkan banyak pengalaman sebagai contoh, gambar pantai boleh mengingatkan kita tentang bunyi ombak, tekstur pasir, angin bertiup ke muka kita, malah boleh memberi inspirasi. Inspirasi untuk sebuah puisi. Sifat imej "mengikat" ini menyediakan sumber penyeliaan yang besar untuk mempelajari ciri visual dengan menjajarkannya dengan sebarang pengalaman deria yang berkaitan dengannya.
Sebaik-baiknya, ciri visual harus dipelajari dengan menjajarkan semua deria untuk satu ruang benam bersama. Walau bagaimanapun, ini memerlukan mendapatkan data berpasangan untuk semua jenis deria dan gabungan daripada set imej yang sama, yang jelas tidak boleh dilaksanakan.
Baru-baru ini, banyak kaedah mempelajari ciri imej yang sejajar dengan teks, audio, dsb. Kaedah ini menggunakan satu pasangan modaliti atau paling banyak beberapa modaliti visual. Pembenaman terakhir adalah terhad kepada pasangan modal yang digunakan untuk latihan. Oleh itu, pembenaman video-audio tidak boleh digunakan secara langsung untuk tugasan teks imej dan sebaliknya. Halangan utama dalam mempelajari benam bersama yang benar ialah kekurangan sejumlah besar data multimodal di mana semua modaliti digabungkan bersama.
Hari ini, Meta AI mencadangkan ImageBind, yang mempelajari satu ruang perwakilan dikongsi dengan memanfaatkan berbilang jenis data gandingan imej. Penyelidikan ini tidak memerlukan set data di mana semua modaliti muncul serentak antara satu sama lain, Sebaliknya, mengambil kesempatan daripada sifat mengikat imej asalkan pembenaman setiap modaliti diselaraskan dengan pembenaman imej , semua modaliti akan dicapai dengan cepat . Meta AI juga mengumumkan kod yang sepadan.

Khususnya, ImageBind memanfaatkan data padanan skala web (imej, teks) dan memasangkannya dengan data berpasangan sedia ada (video, audio, imej, kedalaman) digabungkan untuk mempelajari satu ruang benam bersama. Melakukannya membolehkan ImageBind menyelaraskan pembenaman teks secara tersirat dengan modaliti lain (seperti audio, kedalaman, dll.), membolehkan pengecaman sifar tangkapan pada modaliti ini tanpa gandingan semantik atau teks yang eksplisit.
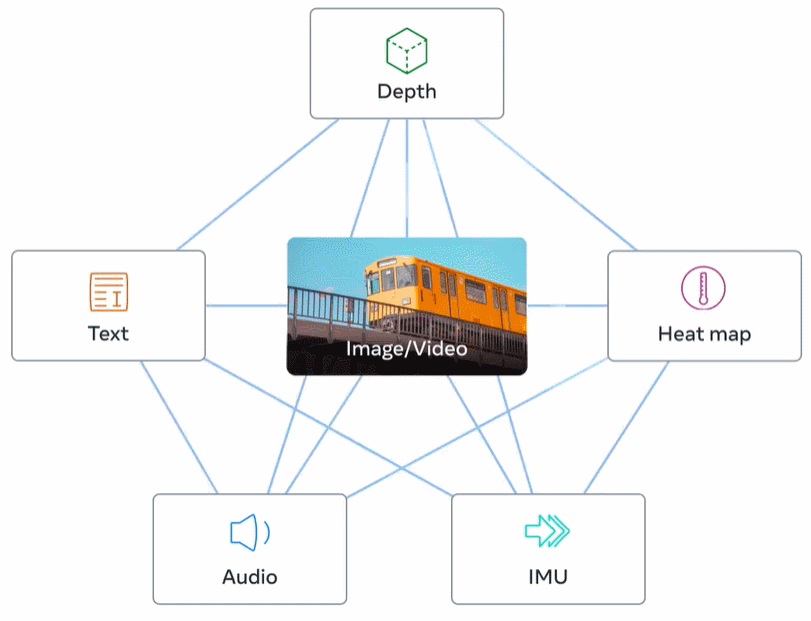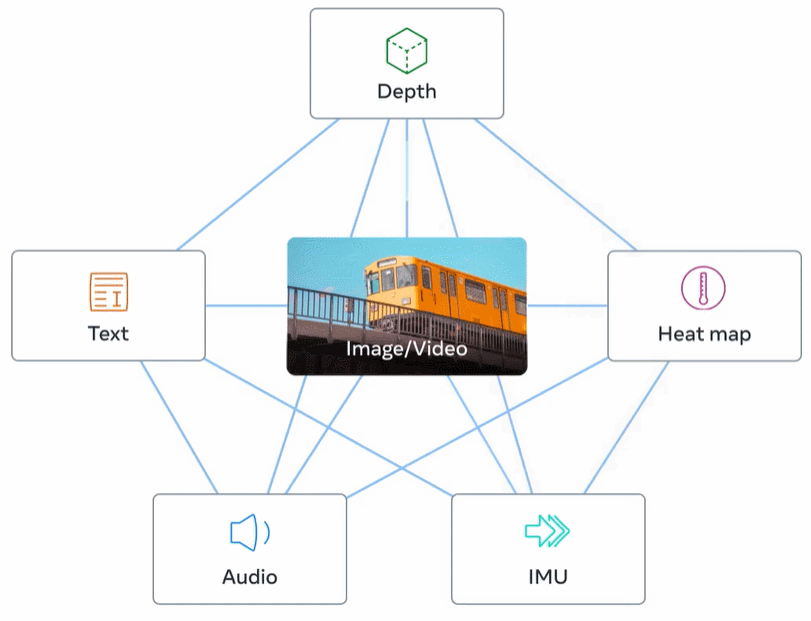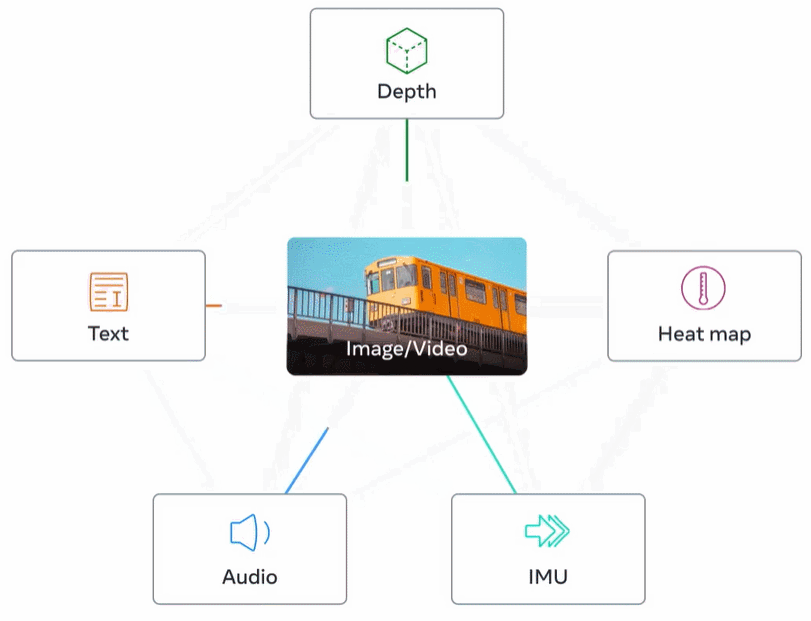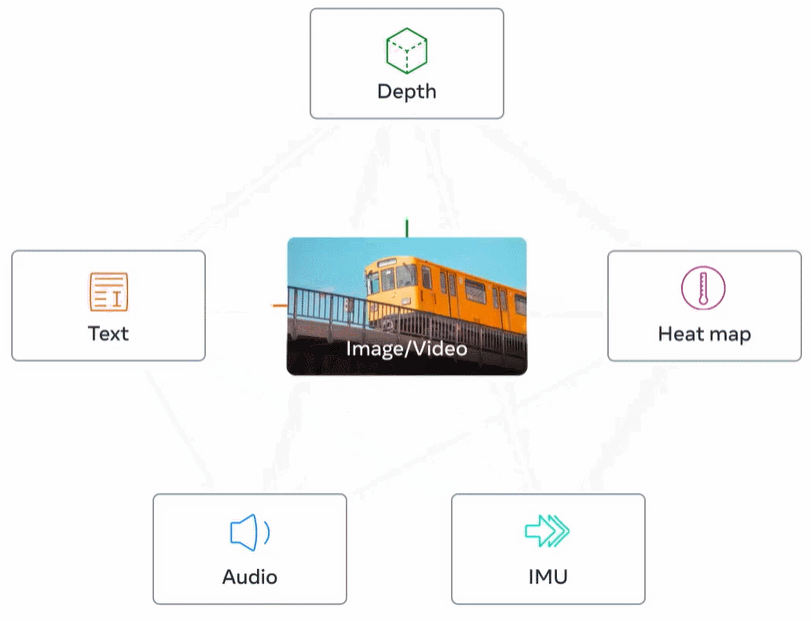
Rajah 2 di bawah ialah gambaran keseluruhan ImageBind.

Pada masa yang sama, penyelidik berkata bahawa ImageBind boleh dimulakan menggunakan model bahasa visual berskala besar (seperti CLIP) untuk memanfaatkan imej yang kaya bagi model ini dan perwakilan teks. Oleh itu, ImageBind memerlukan latihan yang sangat sedikit dan boleh digunakan untuk pelbagai modaliti dan tugasan yang berbeza.
ImageBind ialah sebahagian daripada komitmen Meta untuk mencipta sistem AI berbilang modal yang belajar daripada semua jenis data yang berkaitan. Apabila bilangan modaliti meningkat, ImageBind membuka pintu air kepada penyelidik untuk cuba membangunkan sistem holistik baharu, seperti menggabungkan penderia 3D dan IMU untuk mereka bentuk atau mengalami dunia maya yang mengasyikkan. Ia juga menyediakan cara yang kaya untuk meneroka memori anda dengan menggunakan gabungan teks, video dan imej untuk mencari imej, video, fail audio atau maklumat teks.
Manusia mempunyai keupayaan untuk mempelajari konsep baharu dengan sampel yang sangat sedikit, seperti selepas membaca penerangan haiwan Anda boleh mengenali mereka dalam kehidupan sebenar; daripada foto model kereta yang tidak dikenali, anda boleh meramalkan bunyi yang mungkin dihasilkan oleh enjinnya. Ini sebahagiannya kerana satu imej boleh "menggabungkan" pengalaman deria keseluruhan bersama-sama. Walau bagaimanapun, dalam bidang kecerdasan buatan, walaupun bilangan modaliti telah meningkat, kekurangan data pelbagai deria akan mengehadkan pembelajaran multi-modal standard yang memerlukan data berpasangan.
Sebaik-baiknya, ruang benam bersama dengan jenis data yang berbeza membolehkan model mempelajari modaliti lain sambil mempelajari ciri visual. Sebelum ini, selalunya perlu untuk mengumpul semua gabungan data berpasangan yang mungkin untuk semua modaliti mempelajari ruang benam bersama.
ImageBind memintas kesukaran ini dengan memanfaatkan model bahasa visual berskala besar terbaharu ini memanjangkan keupayaan tangkapan sifar model bahasa visual berskala besar terkini kepada modaliti baharu yang berkaitan dengan imej. Gandingan semula jadi, seperti video-audio dan data kedalaman imej, untuk mempelajari ruang benam bersama. Untuk empat modaliti lain (audio, kedalaman, pengimejan terma dan bacaan IMU), para penyelidik menggunakan data seliaan sendiri yang dipasangkan secara semula jadi.
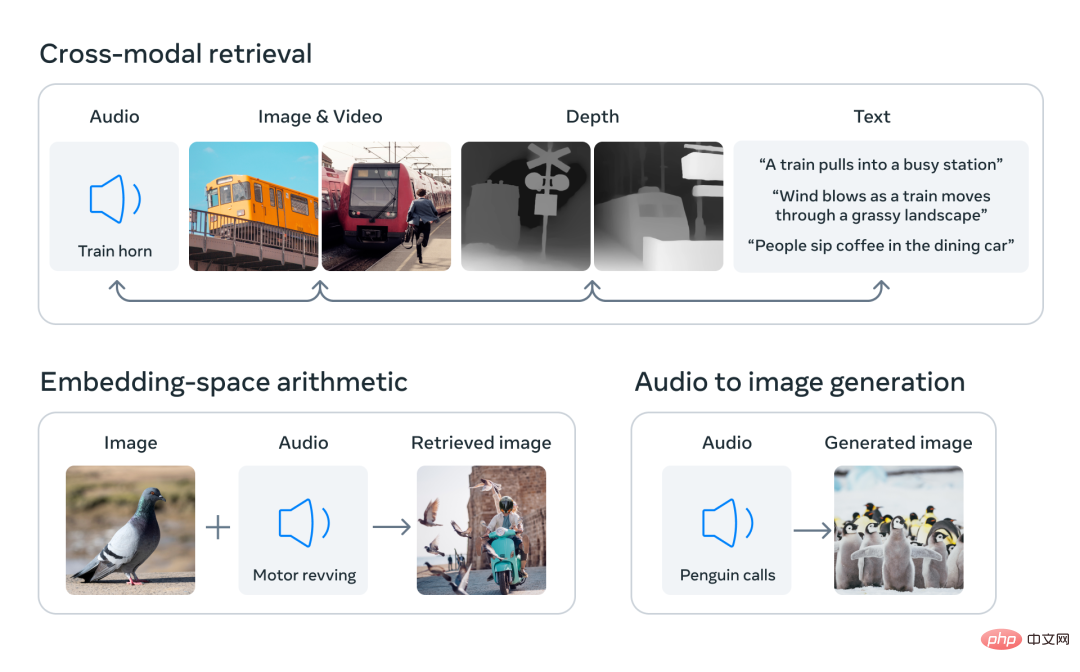
Dengan menyelaraskan benam enam modaliti ke dalam ruang bersama, ImageBind boleh merentas mod mendapatkan semula jenis kandungan yang berbeza yang tidak diperhatikan serentak, menambah pembenaman modaliti berbeza untuk menggabungkan semantiknya secara semula jadi, dan menggunakan pembenaman audio Meta AI dengan penyahkod DALLE-2 yang telah terlatih (direka bentuk Digunakan dengan pembenaman teks CLIP) untuk melaksanakan penjanaan audio-ke-imej.
Terdapat sejumlah besar imej yang muncul bersama-sama dengan teks di Internet, jadi latihan model teks imej telah dikaji secara meluas. ImageBind memanfaatkan sifat pengikatan imej yang boleh disambungkan kepada pelbagai modaliti, seperti menyambungkan teks ke imej menggunakan data rangkaian, atau menyambungkan gerakan ke video menggunakan data video yang ditangkap dalam kamera boleh pakai dengan penderia IMU.
Perwakilan visual yang dipelajari daripada data rangkaian berskala besar boleh digunakan sebagai sasaran untuk mempelajari ciri mod yang berbeza. Ini membolehkan ImageBind menjajarkan imej dengan mana-mana modaliti yang hadir pada masa yang sama, secara semula jadi menjajarkan modaliti tersebut antara satu sama lain. Modaliti seperti peta haba dan peta kedalaman yang mempunyai perkaitan kuat dengan imej lebih mudah untuk diselaraskan. Modaliti bukan visual seperti audio dan IMU (Unit Pengukuran Inersia) mempunyai korelasi yang lebih lemah Contohnya, bunyi tertentu seperti tangisan bayi boleh sepadan dengan pelbagai latar belakang visual.
ImageBind menunjukkan bahawa data gandingan imej adalah mencukupi untuk mengikat enam modaliti ini bersama-sama. Model ini boleh menerangkan kandungan dengan lebih lengkap, membenarkan modaliti yang berbeza untuk "bercakap" antara satu sama lain dan mencari hubungan antara mereka tanpa memerhatikannya secara serentak. Sebagai contoh, ImageBind boleh memautkan audio dan teks tanpa memerhatikannya bersama-sama. Ini membolehkan model lain "memahami" modaliti baharu tanpa memerlukan sebarang latihan intensif sumber.
Prestasi penskalaan hebat ImageBind membolehkan model ini menggantikan atau mempertingkatkan banyak model kecerdasan buatan, membolehkan mereka menggunakan modaliti lain. Contohnya, sementara Make-A-Scene boleh menjana imej dengan menggunakan gesaan teks, ImageBind boleh menaik tarafnya untuk menjana imej menggunakan audio, seperti ketawa atau bunyi hujan.
Analisis Meta menunjukkan bahawa tingkah laku penskalaan ImageBind bertambah baik dengan kekuatan pengekod imej. Dengan kata lain, keupayaan ImageBind untuk menyelaraskan skala modaliti dengan kuasa dan saiz model visual. Ini menunjukkan bahawa model visual yang lebih besar bermanfaat untuk tugas bukan visual, seperti klasifikasi audio, dan bahawa faedah latihan model sedemikian melangkaui tugas penglihatan komputer.
Dalam percubaan, Meta menggunakan pengekod audio dan kedalaman ImageBind dan membandingkannya dengan kerja sebelumnya pada pengambilan sifar tangkapan dan tugas pengelasan audio dan kedalaman.
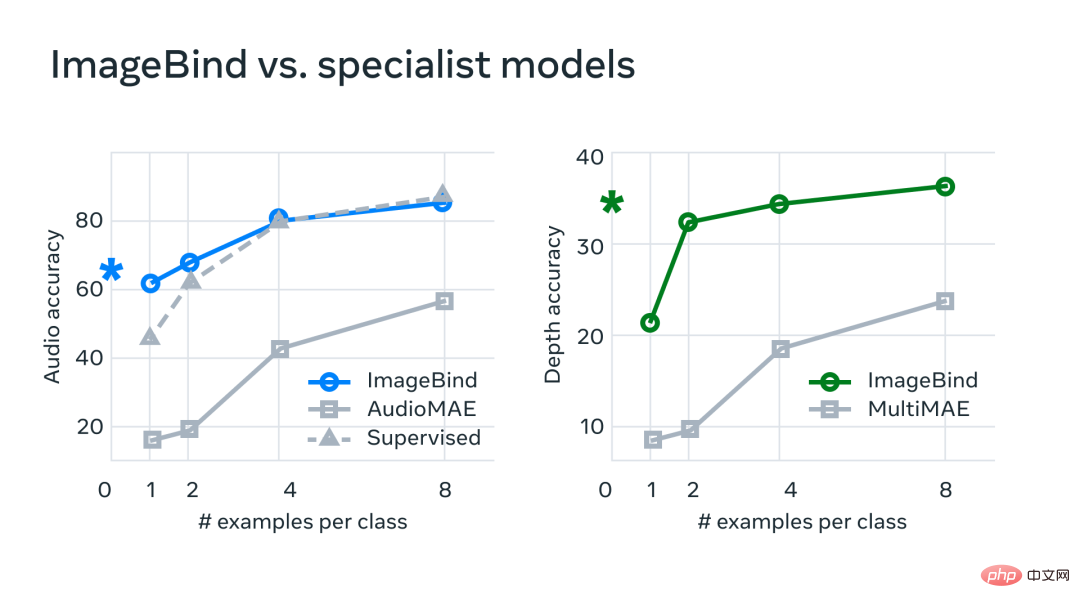
Pada penanda aras, ImageBind mengatasi pakar dalam Model audio dan kedalaman.
Meta mendapati bahawa ImageBind boleh digunakan untuk tugas audio beberapa tangkapan dan pengelasan mendalam serta mengatasi kaedah tersuai sebelumnya. Contohnya, ImageBind dengan ketara mengatasi model AudioMAE seliaan sendiri Meta yang dilatih pada Audioset, serta model AudioMAE seliaannya diperhalusi pada klasifikasi audio.
Selain itu, ImageBind mencapai prestasi SOTA baharu pada tugas pengecaman sifar pukulan merentas modaliti, mengatasi prestasi walaupun model terkini yang dilatih untuk mengenali konsep dalam modaliti tersebut.
Atas ialah kandungan terperinci Menggunakan imej untuk menyelaraskan semua modaliti, model asas AI berbilang deria sumber terbuka Meta untuk mencapai penyatuan yang hebat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Adakah anda tahu jika anda membatalkan orang lain sejurus selepas mengikuti mereka di Douyin?
Adakah anda tahu jika anda membatalkan orang lain sejurus selepas mengikuti mereka di Douyin?
 cmccedu
cmccedu
 Cara menggunakan postmessage
Cara menggunakan postmessage
 Bagaimana untuk memuat turun fail flv
Bagaimana untuk memuat turun fail flv
 Cara menggunakan html untuk navigasi web
Cara menggunakan html untuk navigasi web
 Penggunaan item dalam python
Penggunaan item dalam python
 penggunaan fungsi memcpy
penggunaan fungsi memcpy
 Cadangan perisian pengaturcaraan PHP
Cadangan perisian pengaturcaraan PHP








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



