


Kecerdasan buatan telah menjadi salah satu topik yang paling banyak diperkatakan sejak beberapa tahun kebelakangan ini, dan perkhidmatan yang dahulunya dianggap sebagai fiksyen sains semata-mata kini menjadi kenyataan berkat pembangunan rangkaian saraf. Daripada ejen perbualan kepada penjanaan kandungan media, kecerdasan buatan mengubah cara kita berinteraksi dengan teknologi. Khususnya, model pembelajaran mesin (ML) telah mencapai kemajuan yang ketara dalam bidang pemprosesan bahasa semula jadi (NLP). Satu kejayaan utama ialah pengenalan "perhatian diri" dan seni bina Transformers untuk pemprosesan jujukan, yang membolehkan beberapa masalah utama yang sebelum ini mendominasi bidang diselesaikan.
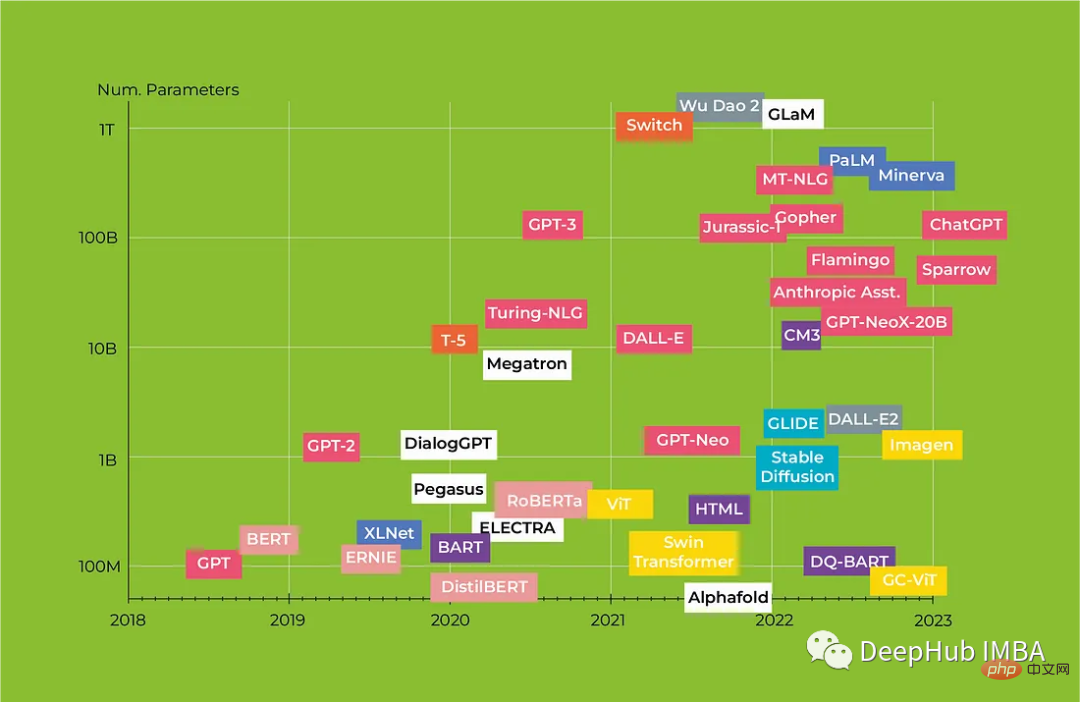
Dalam artikel ini, kita akan melihat seni bina Transformers revolusioner dan bagaimana ia mengubah NLP, kami juga akan memberikan ulasan komprehensif Transformers dari BERT kepada model Alpaca, menonjolkan ciri-ciri utama setiap model dan potensi aplikasinya.
Bahagian pertama ialah model berdasarkan pengekod Transformer, yang digunakan untuk pengvektoran, pengelasan, pelabelan jujukan, QA (Soal Jawab), NER (Entiti Dinamakan Pengiktirafan), dsb.
Pengekod Transformer, tokenisasi bahagian perkataan (30K perbendaharaan kata). Pembenaman input terdiri daripada tiga vektor: vektor label, vektor kedudukan boleh dilatih dan vektor serpihan (sama ada teks pertama atau teks kedua). Input model ialah pembenaman token CLS, pembenaman teks pertama dan pembenaman teks kedua.
BERT mempunyai dua tugas latihan: Pemodelan Bahasa Bertopeng (MLM) dan Prediksi Ayat Seterusnya (NSP). Dalam MLM, 15% token bertopeng, 80% digantikan dengan token MASK, 10% digantikan dengan token rawak, dan 10% kekal tidak berubah. Model meramalkan token yang betul, dan kerugian hanya dikira pada 15% token yang disekat ini. Dalam NSP, model meramalkan sama ada teks kedua mengikuti teks pertama. Ramalan dibuat pada vektor keluaran token CLS.
Untuk mempercepatkan latihan, 90% latihan pertama dilakukan pada panjang urutan 128 token, dan kemudian baki 10% masa dihabiskan untuk melatih model pada 512 token untuk mendapatkan pembenaman kedudukan yang lebih berkesan .
Versi BERT yang dipertingkatkan, ia hanya dilatih pada MLM (kerana NSP dianggap kurang berguna), dan urutan latihan lebih panjang (512 token). Menggunakan pelekat dinamik (token yang berbeza disembunyikan apabila data yang sama diproses semula), hiperparameter latihan dipilih dengan teliti.
XLM mempunyai dua tugas latihan: MLM dan terjemahan. Terjemahan pada dasarnya adalah sama seperti MLM pada sepasang teks, tetapi teks tersebut adalah terjemahan selari antara satu sama lain, dengan topeng rawak dan bahasa pengekodan pembenaman segmen.
4. Transformer-XL Carnegie Mellon University / 2019
Teks panjang dibahagikan kepada segmen dan diproses satu segmen pada satu masa. Output segmen sebelumnya dicache, dan apabila mengira perhatian diri dalam segmen semasa, kunci dan nilai dikira berdasarkan output segmen semasa dan segmen sebelumnya (hanya digabungkan bersama). Kecerunan juga dikira hanya dalam segmen semasa.
Kaedah ini tidak berfungsi dengan kedudukan mutlak. Oleh itu, formula berat perhatian diparameterkan semula dalam model. Vektor pengekodan kedudukan mutlak digantikan dengan matriks tetap berdasarkan sinus jarak antara kedudukan penanda dan vektor boleh dilatih yang biasa kepada semua kedudukan.
5. ERNIE Tsinghua University, Huawei / 2019
6. XLNet Carnegie Mellon University / 2019
XLNet adalah berdasarkan Transformer-XL, kecuali untuk tugas pemodelan bahasa (PLM) gantian, di mana ia belajar untuk meramalkan token dalam konteks pendek dan bukannya menggunakan MASK secara langsung. Ini memastikan bahawa kecerunan dikira untuk semua penanda dan menghapuskan keperluan untuk penanda topeng khas.
Token dalam konteks dikacau (contohnya: token ke-i boleh diramalkan berdasarkan token ke-2 dan ke-1+), tetapi kedudukannya masih diketahui. Ini tidak boleh dilakukan dengan pengekodan kedudukan semasa (termasuk Transformer-XL). Apabila cuba meramalkan kebarangkalian token yang diberikan sebahagian daripada konteks, model tidak seharusnya mengetahui token itu sendiri, tetapi harus mengetahui kedudukan token dalam konteks. Untuk menyelesaikan masalah ini, mereka membahagikan perhatian diri kepada dua aliran:
Semasa penalaan halus, jika anda mengabaikan vektor pertanyaan, model akan berfungsi seperti Transformer-XL biasa.
Dalam amalan, model memerlukan konteks mestilah cukup panjang untuk model belajar dengan betul. Ia mempelajari jumlah data yang sama seperti RoBERTa dengan hasil yang serupa, tetapi disebabkan kerumitan pelaksanaan, model itu tidak menjadi popular seperti RoBERTa.
Permudahkan BERT tanpa mengorbankan kualiti:
Model ini dilatih mengenai MLM dan Prediksi Susunan Ayat (SOP).
Cara lain untuk mengoptimumkan BERT ialah penyulingan:
Modelisasi berbilang bahasa berdasarkan BERT. Ia dilatih mengenai MLM dan TLM (20% daripada penanda bertopeng) dan kemudian diperhalusi. Ia menyokong lebih 100 bahasa dan mengandungi 500K perbendaharaan kata bertanda.
Mempercepatkan latihan BERT menggunakan kaedah lawan generatif:
Jumlah data latihan adalah sama seperti RoBERTa atau XLNet, dan modelnya lebih pantas daripada BERT, RoBERTa dan ALBERT Belajar ke tahap kualiti yang sama. Lebih lama ia dilatih, lebih baik prestasinya.
Model lain yang memisahkan kandungan dan kedudukan vektor penanda kepada dua vektor yang berasingan:
Model berdasarkan Transformers lengkap. Rangkaian aplikasinya sangat luas: sebagai tambahan kepada tugas bahagian sebelumnya, ia termasuk ejen perbualan, terjemahan mesin, penaakulan logik dan matematik, analisis dan penjanaan kod, dan pada asasnya penjanaan teks. Model terbesar dan "paling pintar" biasanya berdasarkan seni bina penyahkod. Model sedemikian sering berprestasi baik dalam mod beberapa tangkapan dan sifar tangkapan tanpa penalaan halus.
Penyahkod dilatih mengenai tugas LM sebab (meramalkan token seterusnya berdasarkan konteks sebelah kiri). Dari perspektif seni bina, terdapat beberapa perubahan kecil: mengalih keluar lapisan perhatian silang daripada setiap blok penyahkod dan menggunakan LayerNorm
Tokenizer yang digunakan ialah BPE peringkat bait (perbendaharaan kata 50K) dan tidak menggunakan subrentetan yang serupa seperti ("anjing", "anjing!", "anjing."). Panjang jujukan maksimum ialah 1024. Output lapisan menyimpan semua teg yang dijana sebelum ini.
Pra-latihan penuh tentang MLM (15% daripada token bertopeng), rentang bertopengkan oleh kod (
Alih Keluar Token
Ini ialah model GPT-2 dengan seni bina Sparse Transformer dan panjang jujukan 2048 token. Adakah anda masih ingat ayat itu: Jangan tanya, tanya sahaja: GPT3
6, mT5 Google / 2020 adalah berdasarkan model T5, dengan latihan yang serupa, tetapi menggunakan berbilang bahasa data. Pengaktifan ReLU telah digantikan dengan GeGLU dan perbendaharaan kata telah dikembangkan kepada 250K token. 7. GLAM Google / 2021Model ini secara konsepnya serupa dengan Switch Transformer, tetapi lebih memfokuskan pada bekerja dalam mod beberapa sampel dan bukannya penalaan halus. Model saiz berbeza menggunakan 32 hingga 256 lapisan pakar, K=2. Gunakan pengekodan kedudukan relatif daripada Transformer-XL. Apabila memproses token, kurang daripada 10% parameter rangkaian diaktifkan. 8. LaMDA Google / 2021Model yang serupa dengan gpt. Model ini ialah model perbualan yang telah dilatih pada LM sebab dan diperhalusi pada penjanaan dan tugasan diskriminatif. Model ini juga boleh membuat panggilan ke sistem luaran (carian, terjemahan). 9. GPT-NeoX-20B EleutherAI / 2022Model ini serupa dengan GPT-J dan juga menggunakan pengekodan kedudukan putaran. Berat model diwakili oleh apungan16. Panjang jujukan maksimum ialah 2048. 10. BLOOM BigScience / 2022Ini adalah model sumber terbuka terbesar dalam 46 bahasa dan 13 bahasa pengaturcaraan. Untuk melatih model, set data terkumpul besar yang dipanggil ROOTS digunakan, yang merangkumi kira-kira 500 set data terbuka. 11, PaLM Google / 2022Ini ialah model penyahkod berbilang bahasa yang besar, dilatih menggunakan Adafactor, melumpuhkan keciciran semasa pra-latihan dan menggunakan 0.1 semasa penalaan halus. 12. LLaMA Meta / 2023Sumber terbuka berskala besar seperti LM yang digunakan untuk penyelidikan saintifik dan telah digunakan untuk melatih berbilang model arahan. Model ini menggunakan pra-LayerNorm, pengaktifan SwiGLU dan pembenaman kedudukan RoPE. Kerana ia adalah sumber terbuka, ini adalah salah satu model utama untuk memotong di selekoh. Model Panduan untuk TeksTangkapan model ini digunakan untuk membetulkan output model (cth. RLHF) untuk meningkatkan kualiti tindak balas semasa dialog dan penyelesaian tugas. 1. InstructGPT OpenAI/2022Kerja ini menyesuaikan GPT-3 untuk mengikut arahan dengan cekap. Model ini diperhalusi pada set data yang terdiri daripada pembayang dan jawapan yang dianggap baik oleh manusia berdasarkan satu set kriteria. Berdasarkan InstructGPT, OpenAI mencipta model yang kini kita kenali sebagai ChatGPT. 2. Flan-T5 Google / 2022Model bimbingan sesuai untuk T5. Dalam sesetengah tugas, Flan-T5 11B mengatasi prestasi PaLM 62B tanpa penalaan halus ini. Model-model ini telah dikeluarkan sebagai sumber terbuka. 3. Sparrow DeepMind / 2022Model asas diperoleh dengan menyempurnakan Chinchilla pada perbualan berkualiti tinggi terpilih, dengan 80% lapisan pertama dibekukan. Model itu kemudiannya dilatih lagi menggunakan gesaan besar untuk membimbingnya melalui perbualan. Beberapa model ganjaran juga dilatih di atas Chinchilla. Model ini boleh mengakses enjin carian dan mendapatkan semula coretan sehingga 500 aksara yang boleh menjadi respons. Semasa inferens, model ganjaran digunakan untuk meletakkan kedudukan calon. Calon sama ada dijana oleh model atau diperoleh daripada carian, dan kemudian yang terbaik menjadi respons.Model bimbingan LLaMA di atas. Fokus utama adalah pada proses membina set data menggunakan GPT-3:
Sebanyak 52K triple unik telah dijana dan diperhalusi pada LLaMA 7B.
Ini ialah penalaan halus LLaMA pada data arahan, tetapi tidak seperti Alpaca di atas, ia bukan sahaja dijana oleh model besar seperti GPT-3 Fine -menala data. Komposisi set data ialah:
DM perwakilan dalaman
Persamaan antara vektor kumpulan perhatian imej dan vektor teg CLS bagi teks pasangan perihalan imej.
Kehilangan autoregresif untuk keseluruhan keluaran penyahkod (bersyarat pada imej).
Imej dikodkan oleh ViT, vektor output serta token dan arahan teks dimasukkan ke PaLM dan PaLM menjana teks output.
PaLM-E digunakan untuk semua tugas termasuk VQA, pengesanan objek dan operasi robot.
Ini ialah model tertutup dengan beberapa butiran yang diketahui. Mungkin, ia mempunyai penyahkod dengan perhatian yang jarang dan input berbilang modal. Ia menggunakan latihan autoregresif dan penalaan halus RLHF dengan panjang jujukan dari 8K hingga 32K.
Ia telah diuji dalam pemeriksaan manusia dengan sampel sifar dan beberapa sampel, dan mencapai tahap seperti manusia. Ia boleh serta-merta dan langkah demi langkah menyelesaikan masalah berasaskan imej (termasuk masalah matematik), memahami dan mentafsir imej, serta boleh menganalisis dan menjana kod. Juga sesuai untuk bahasa yang berbeza, termasuk bahasa minoriti.
Berikut adalah kesimpulan ringkas. Ia mungkin tidak lengkap, atau hanya salah, dan disediakan untuk rujukan sahaja.
Selepas kad grafik automatik tidak dapat dilombong, pelbagai model berskala besar berpusu-pusu, dan asas model telah berkembang Namun, peningkatan lapisan mudah dan pertumbuhan set data telah digantikan dengan pelbagai yang lebih baik teknologi. Teknologi ini Membolehkan peningkatan kualiti (penggunaan data dan alatan luaran, struktur rangkaian yang dipertingkatkan dan teknik penalaan halus baharu). Tetapi badan kerja yang semakin meningkat menunjukkan bahawa kualiti data latihan adalah lebih penting daripada kuantiti: Pemilihan dan pembentukan set data yang betul boleh mengurangkan masa latihan dan meningkatkan kualiti keputusan.
OpenAI kini menjadi sumber tertutup, mereka telah cuba untuk tidak melepaskan berat GPT-2 tetapi gagal. Tetapi GPT4 adalah kotak hitam Arah aliran dalam beberapa bulan kebelakangan ini untuk menambah baik dan mengoptimumkan kos penalaan halus dan kelajuan inferens model sumber terbuka telah mengurangkan nilai model persendirian yang besar kerana model sumber terbuka juga cepat mengejar gergasi dalam kualiti , yang membolehkan memotong di selekoh lagi.
Ringkasan model sumber terbuka akhir adalah seperti berikut:
Atas ialah kandungan terperinci Ulasan Transformers: Daripada BERT kepada GPT4. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



