



Penghuraian dokumen melibatkan pemeriksaan data dalam dokumen dan mengekstrak maklumat yang berguna. Ia boleh mengurangkan banyak kerja manual melalui automasi. Strategi penghuraian yang popular ialah menukar dokumen kepada imej dan menggunakan penglihatan komputer untuk pengecaman. Analisis Imej Dokumen merujuk kepada teknologi mendapatkan maklumat daripada data piksel imej dokumen Dalam beberapa kes, tidak ada jawapan yang jelas tentang hasil yang diharapkan (teks, imej, carta, nombor, Jadual, formula. ..).

OCR (Optical Character Recognition, optical character recognition) ialah proses mengesan dan mengekstrak teks dalam imej melalui penglihatan komputer. Ia dicipta semasa Perang Dunia I, apabila saintis Israel Emanuel Goldberg mencipta mesin yang boleh membaca aksara dan menukarnya menjadi kod telegraf. Kini bidang tersebut telah mencapai tahap yang sangat canggih, mencampurkan pemprosesan imej, penyetempatan teks, pembahagian aksara dan pengecaman aksara. Pada asasnya teknik pengesanan objek untuk teks.
Dalam artikel ini saya akan menunjukkan cara menggunakan OCR untuk penghuraian dokumen. Saya akan menunjukkan kepada anda beberapa kod Python berguna yang boleh digunakan dengan mudah dalam situasi serupa yang lain (hanya salin, tampal, jalankan), dan sediakan muat turun kod sumber penuh.
Di sini kami akan mengambil penyata kewangan dalam format PDF syarikat tersenarai sebagai contoh (pautan di bawah).
https://s2.q4cdn.com/470004039/files/doc_financials/2021/q4/_10-K-2021-(As-Filed).pdf

Kesan dan ekstrak teks, grafik dan jadual daripada PDF ini
Bahagian penghuraian dokumen yang menjengkelkan ialah , di sana adalah begitu banyak alat untuk pelbagai jenis data (teks, grafik, jadual) tetapi tiada satu pun daripadanya berfungsi dengan sempurna. Berikut ialah beberapa kaedah dan pakej yang paling popular:
Mungkin anda akan bertanya: "Mengapa tidak memproses terus fail PDF, tetapi menukar halaman menjadi imej Anda boleh melakukan ini?" Kelemahan utama strategi ini ialah isu pengekodan: dokumen boleh dalam berbilang pengekodan (iaitu UTF-8, ASCII, Unicode), jadi penukaran kepada teks boleh mengakibatkan kehilangan data. Jadi untuk mengelakkan masalah ini, saya akan menggunakan OCR dan menukar halaman kepada imej dengan pdf2image Ambil perhatian bahawa perpustakaan rendering PDF Poppler diperlukan.
# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
Anda boleh membaca fail dengan mudah:
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a pageSama seperti tangkapan skrin kami, jika anda ingin menyimpan imej halaman secara setempat, anda boleh menggunakan kod berikut:
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
Akhir sekali, kita perlu menyediakan enjin CV yang akan kita gunakan. LayoutParser nampaknya merupakan pakej tujuan umum pertama untuk OCR berdasarkan pembelajaran mendalam. Ia menggunakan dua model terkenal untuk menyelesaikan tugas:
Pengesanan: Pustaka pengesanan objek paling canggih Facebook (versi kedua Detectron2 akan digunakan di sini).
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
Tesseract: Sistem OCR paling terkenal, dicipta oleh HP pada tahun 1985 dan kini dibangunkan oleh Google.
pip install "layoutparser[ocr]"
Kini anda sudah bersedia untuk memulakan program OCR untuk pengesanan dan pengekstrakan maklumat.
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
(Sasaran) Pengesanan ialah proses mencari sekeping maklumat dalam imej dan kemudian mengelilinginya dengan sempadan segi empat tepat. Untuk penghuraian dokumen, maklumatnya ialah tajuk, teks, grafik, jadual...
Mari kita lihat halaman kompleks yang mengandungi beberapa perkara:
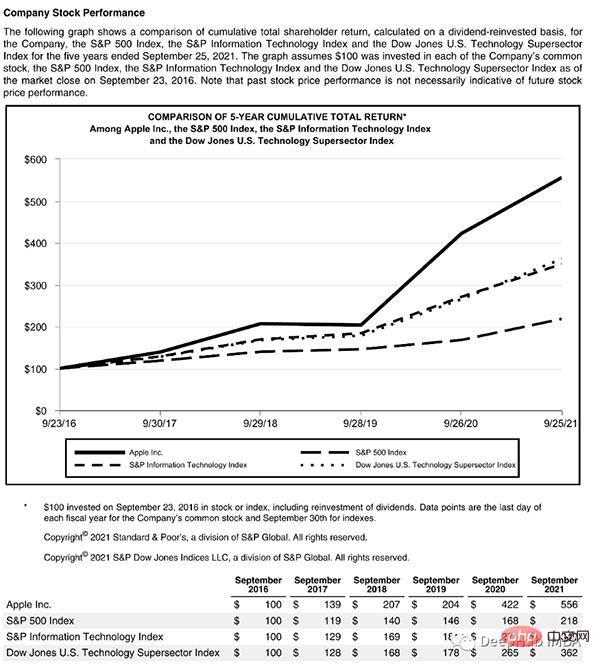
Halaman ini bermula dengan tajuk, mempunyai blok teks, kemudian angka dan jadual, jadi kami memerlukan model terlatih untuk mengenali objek ini. Nasib baik Detectron dapat melakukan ini, kita hanya perlu memilih model dari sini dan menentukan laluannya dalam kod.
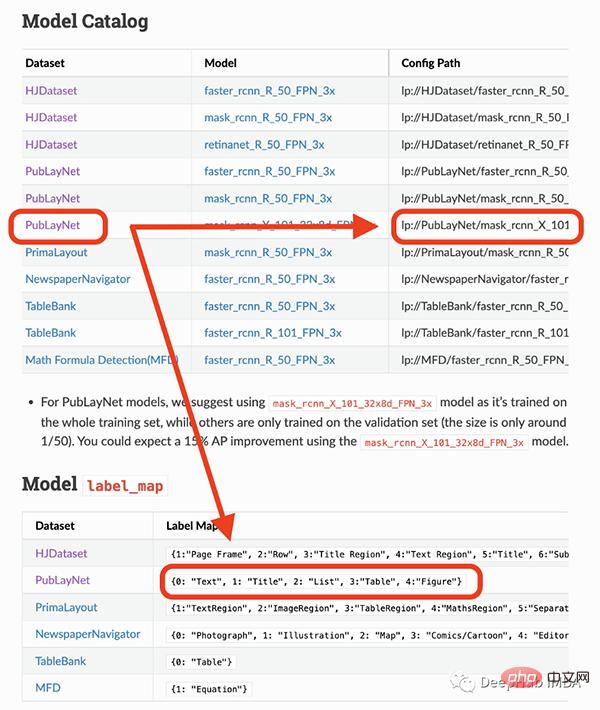
Model yang saya akan gunakan hanya boleh mengesan 4 objek (teks, tajuk, senarai, jadual, graf). Oleh itu, jika anda perlu mengenal pasti perkara lain (seperti persamaan), anda perlu menggunakan model lain.
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)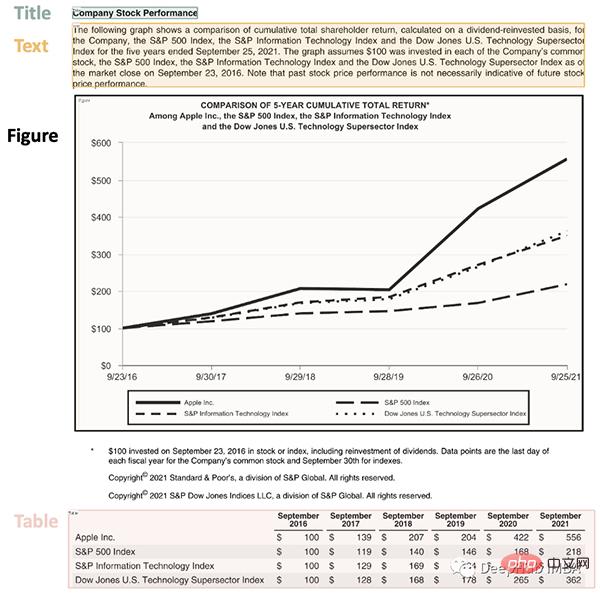
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
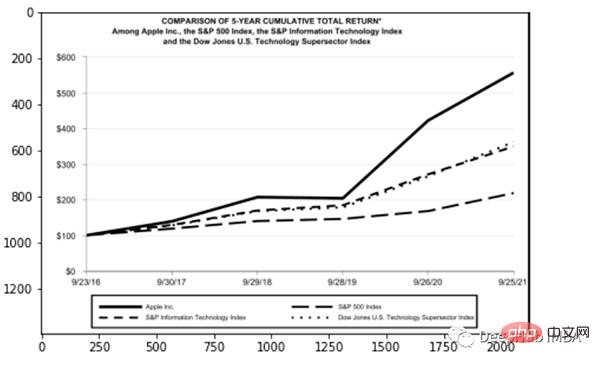
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
Atas ialah kandungan terperinci Demonstrasi kod lengkap penghuraian dokumen menggunakan Python dan OCR (kod dilampirkan). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



