


Algoritma penggalak kecerunan ialah salah satu teknik pembelajaran mesin ensemble yang paling biasa digunakan Model ini menggunakan jujukan pepohon keputusan yang lemah untuk membina pelajar yang kuat. Ini juga merupakan asas teori model XGBoost dan LightGBM, jadi dalam artikel ini, kami akan membina model peningkatan kecerunan dari awal dan menggambarkannya.
Algoritma Peningkatan Kecerunan ialah algoritma pembelajaran ensemble yang meningkatkan prestasi dengan membina berbilang pengelas lemah dan kemudian menggabungkannya menjadi pengelas yang kukuh Ketepatan ramalan model.
Prinsip algoritma penggalak kecerunan boleh dibahagikan kepada langkah berikut:
Memandangkan algoritma penggalak kecerunan ialah algoritma bersiri, kelajuan latihannya mungkin lebih perlahan Mari kita perkenalkan dengan contoh praktikal:
Andaikan kita mempunyai ciri Diberikan satu set
Setiap langkah kita mahu menjadikan F_m(x) lebih dekat dengan y|x.

 Kemudian, kita bergerak ke arah di mana fungsi kehilangan berkurangan paling cepat berbanding dengan pelajar Fm Hadapan:
Kemudian, kita bergerak ke arah di mana fungsi kehilangan berkurangan paling cepat berbanding dengan pelajar Fm Hadapan:
Kami tidak tahu nilai tepat kecerunan ini kerana kami tidak boleh mengira y untuk setiap x, tetapi untuk setiap x_i, kecerunan adalah betul-betul sama dengan baki langkah m: r_i!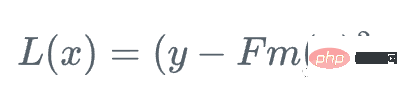
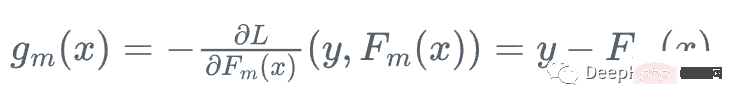
Ini adalah peningkatan kecerunan, kami tidak menggunakan fungsi kehilangan relatif kepada semasa Kecerunan sebenar g_m pelajar digunakan untuk mengemas kini pelajar semasa F_{m}, tetapi pepohon regresi yang lemah h_m digunakan untuk mengemas kininya. 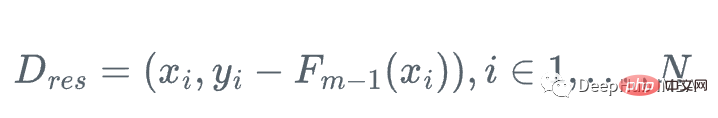
1 Kira baki: 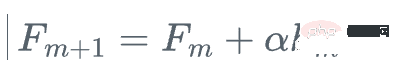
 3 Kemas kini model dengan langkah alpha
3 Kemas kini model dengan langkah alpha
 Visualisasi proses membuat keputusan
Visualisasi proses membuat keputusan
Di sini kita menggunakan set data bulan sklearn, kerana ini ialah Data Kategori tak linear klasik
Mari kita bayangkan data: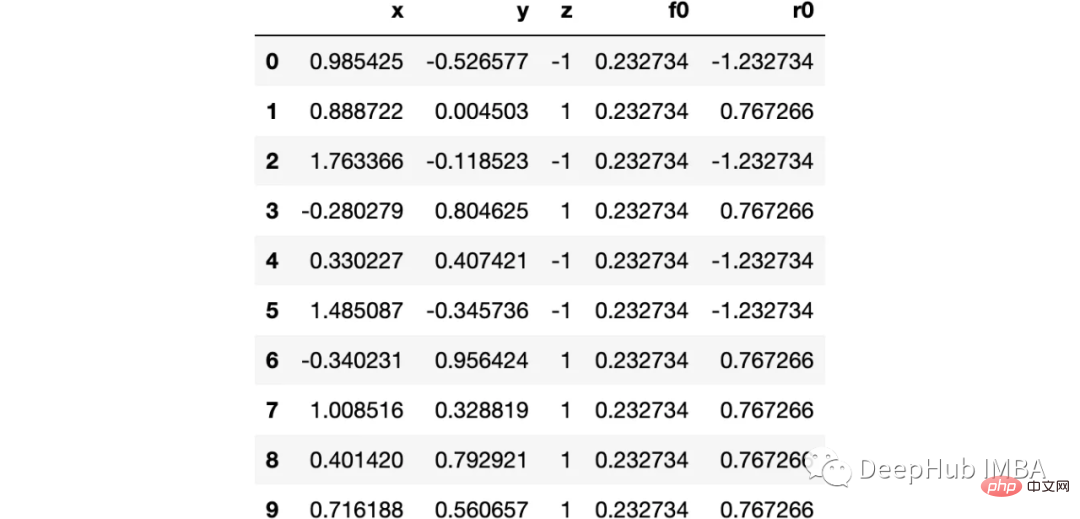
下图可以看到,该数据集是可以明显的区分出分类的边界的,但是因为他是非线性的,所以使用线性算法进行分类时会遇到很大的困难。
那么我们先编写一个简单的梯度增强模型:
1 2 3 4 5 6 7 8 9 10 11 12 |
|
上面代码执行3个简单步骤:
将决策树与残差进行拟合:
1 2 |
|
然后,我们将这个近似的梯度与之前的学习器相加:
1 |
|
最后重新计算残差:
1 |
|
步骤就是这样简单,下面我们来一步一步执行这个过程。
第1次决策

Tree Split for 0 and level 1.563690960407257

第2次决策
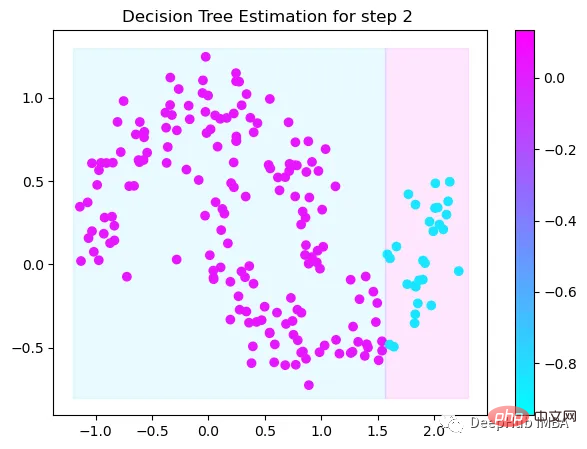
Tree Split for 1 and level 0.5143677890300751
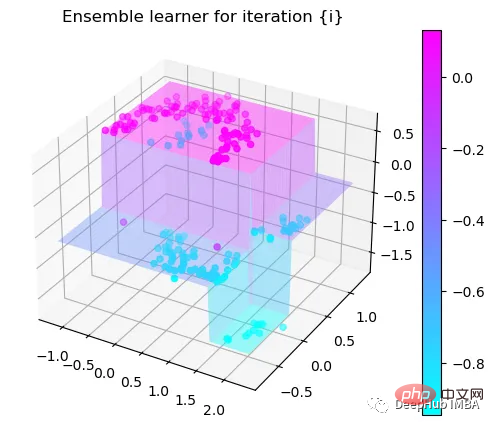
第3次决策
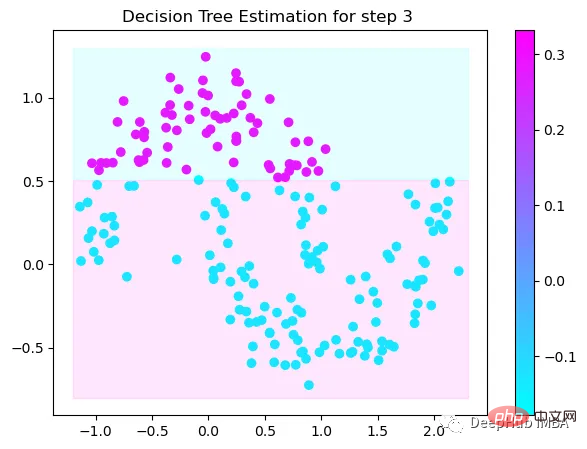
Tree Split for 0 and level -0.6523728966712952

第4次决策

Tree Split for 0 and level 0.3370491564273834

第5次决策

Tree Split for 0 and level 0.3370491564273834

第6次决策

Tree Split for 1 and level 0.022058885544538498

第7次决策

Tree Split for 0 and level -0.3030575215816498

第8次决策

Tree Split for 0 and level 0.6119407713413239

第9次决策

可以看到通过9次的计算,基本上已经把上面的分类进行了区分

我们这里的学习器都是非常简单的决策树,只沿着一个特征分裂!但整体模型在每次决策后边的越来越复杂,并且整体误差逐渐减小。
1 |
|

这也就是上图中我们看到的能够正确区分出了大部分的分类
如果你感兴趣可以使用下面代码自行实验:
//m.sbmmt.com/link/bfc89c3ee67d881255f8b097c4ed2d67
Atas ialah kandungan terperinci Visualisasi langkah demi langkah proses membuat keputusan bagi algoritma penggalak kecerunan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



