


Dalam artikel ini, saya akan menerangkan secara terperinci kertas kerja "Mengapa model berasaskan pokok masih mengatasi pembelajaran mendalam pada data jadual" Kertas kerja ini menerangkan pemerhatian yang telah diperhatikan oleh pengamal pembelajaran mesin di seluruh dunia dalam pelbagai bidang diperhatikan - model berasaskan pokok adalah lebih baik dalam menganalisis data jadual daripada pembelajaran mendalam/rangkaian saraf.
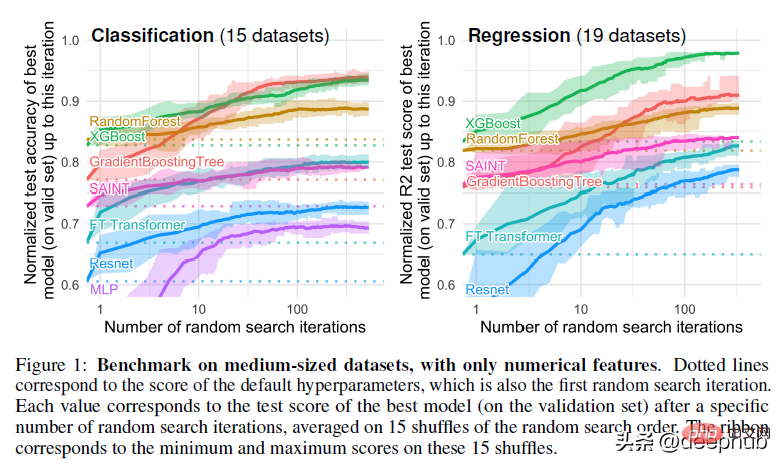
Kertas ini telah melalui banyak prapemprosesan. Contohnya, perkara seperti mengalih keluar data yang hilang boleh menghalang prestasi pokok, tetapi hutan rawak bagus untuk situasi data yang hilang jika data anda sangat kemas: mengandungi banyak ciri dan dimensi. Kekukuhan dan kelebihan RF menjadikannya lebih unggul daripada penyelesaian yang lebih "maju", yang terdedah kepada masalah.

Kebanyakan kerja yang lain adalah agak standard. Saya secara peribadi tidak suka menggunakan terlalu banyak teknik pra-pemprosesan kerana ini boleh menyebabkan kehilangan banyak nuansa set data, tetapi langkah-langkah yang diambil dalam kertas pada dasarnya menghasilkan set data yang sama. Walau bagaimanapun, adalah penting untuk ambil perhatian bahawa kaedah pemprosesan yang sama digunakan semasa menilai keputusan akhir.
Kertas ini juga menggunakan carian rawak untuk penalaan hiperparameter. Ini juga merupakan standard industri, tetapi dalam pengalaman saya carian Bayesian lebih sesuai untuk mencari dalam ruang carian yang lebih luas.
Memahami perkara ini, kita boleh menyelami persoalan utama kita - mengapa kaedah berasaskan pokok mengatasi pembelajaran mendalam
Ini sebab pertama yang penulis kongsikan mengapa rangkaian neural pembelajaran mendalam tidak boleh bersaing dengan hutan rawak. Ringkasnya, rangkaian saraf mempunyai masa yang sukar untuk mencipta kesesuaian terbaik apabila ia berkaitan dengan sempadan fungsi/keputusan yang tidak lancar. Hutan rawak lebih baik dalam corak pelik/bergerigi/tidak teratur.

Jika saya meneka sebabnya, ini mungkin penggunaan kecerunan dalam rangkaian saraf, dan kecerunan bergantung pada ruang carian yang boleh dibezakan, yang mengikut definisi adalah lancar, Jadi ia adalah mustahil untuk membezakan antara titik tajam dan beberapa fungsi rawak. Jadi saya mengesyorkan mempelajari konsep AI seperti Algoritma Evolusi, Carian Tradisional dan lebih banyak konsep asas kerana konsep ini boleh membawa kepada hasil yang hebat dalam pelbagai situasi apabila NN gagal.
Untuk contoh yang lebih spesifik tentang perbezaan sempadan keputusan antara kaedah berasaskan pokok (RandomForests) dan pelajar mendalam, lihat rajah di bawah -
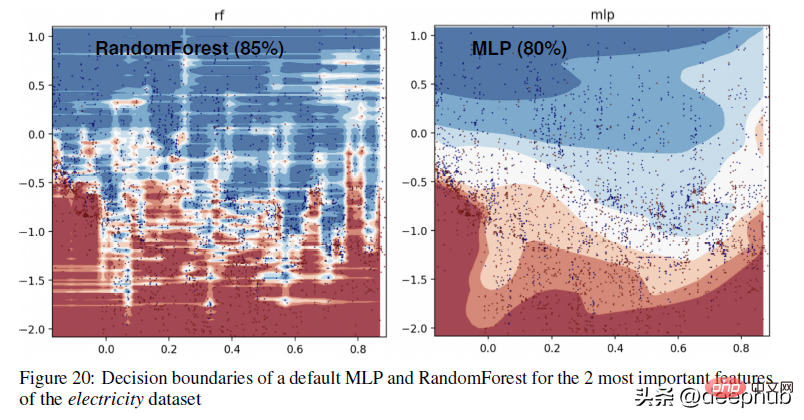
dalam lampiran , penulis menerangkan visualisasi di atas seperti berikut:
Dalam bahagian ini, kita dapat melihat bahawa RandomForest dapat mempelajari corak tidak sekata pada paksi-x (bersesuaian dengan ciri-ciri tarikh) yang MLP tidak dapat belajar. Kami menunjukkan perbezaan ini dalam hiperparameter lalai, yang merupakan tingkah laku tipikal rangkaian saraf, tetapi dalam praktiknya adalah sukar (walaupun tidak mustahil) untuk mencari hiperparameter yang berjaya mempelajari corak ini.
Satu lagi faktor penting, terutamanya bagi set data besar yang mengekodkan berbilang perhubungan secara serentak. Jika anda menyalurkan ciri yang tidak berkaitan ke rangkaian saraf, hasilnya akan menjadi buruk (dan anda akan membazirkan lebih banyak sumber untuk melatih model anda). Inilah sebabnya mengapa sangat penting untuk menghabiskan banyak masa pada penerokaan EDA/domain. Ini akan membantu memahami ciri dan memastikan semuanya berjalan lancar.
Pengarang kertas menguji prestasi model apabila menambah rawak dan mengalih keluar ciri yang tidak berguna. Berdasarkan keputusan mereka, 2 hasil yang sangat menarik ditemui
Mengalih keluar sejumlah besar ciri mengurangkan jurang prestasi antara model. Ini jelas menunjukkan bahawa salah satu kelebihan model pokok ialah keupayaan mereka menilai sama ada ciri berguna dan mengelakkan pengaruh ciri tidak berguna.
Menambahkan ciri rawak pada set data menunjukkan bahawa rangkaian saraf merosot jauh lebih teruk daripada kaedah berasaskan pokok. ResNet terutamanya mengalami sifat tidak berguna ini. Penambahbaikan transformer mungkin kerana mekanisme perhatian di dalamnya akan membantu pada tahap tertentu.
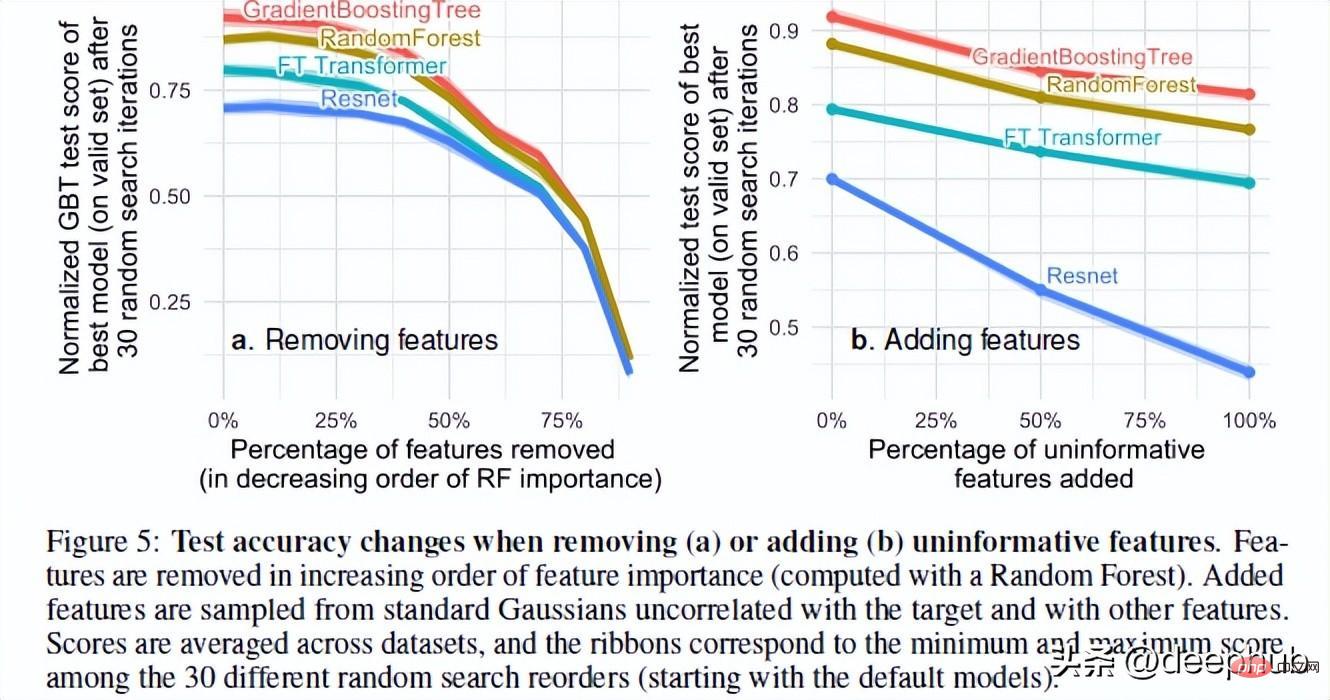
Satu penjelasan yang mungkin untuk fenomena ini ialah cara pepohon keputusan direka bentuk. Sesiapa yang telah mengikuti kursus AI akan mengetahui konsep perolehan maklumat dan entropi dalam pepohon keputusan. Ini membolehkan pepohon keputusan memilih laluan terbaik dengan membandingkan ciri yang selebihnya.
Kembali kepada topik, terdapat satu perkara terakhir yang menjadikan RF berprestasi lebih baik daripada NN apabila ia berkaitan dengan data jadual. Itulah invarian putaran.
Rangkaian saraf adalah invarian putaran. Ini bermakna jika anda melakukan operasi putaran pada set data anda, ia tidak akan mengubah prestasinya. Selepas memutar set data, prestasi dan kedudukan model yang berbeza berubah dengan ketara Walaupun ResNets sentiasa yang paling teruk, ia mengekalkan prestasi asalnya selepas berputar, manakala semua model lain berubah dengan ketara.
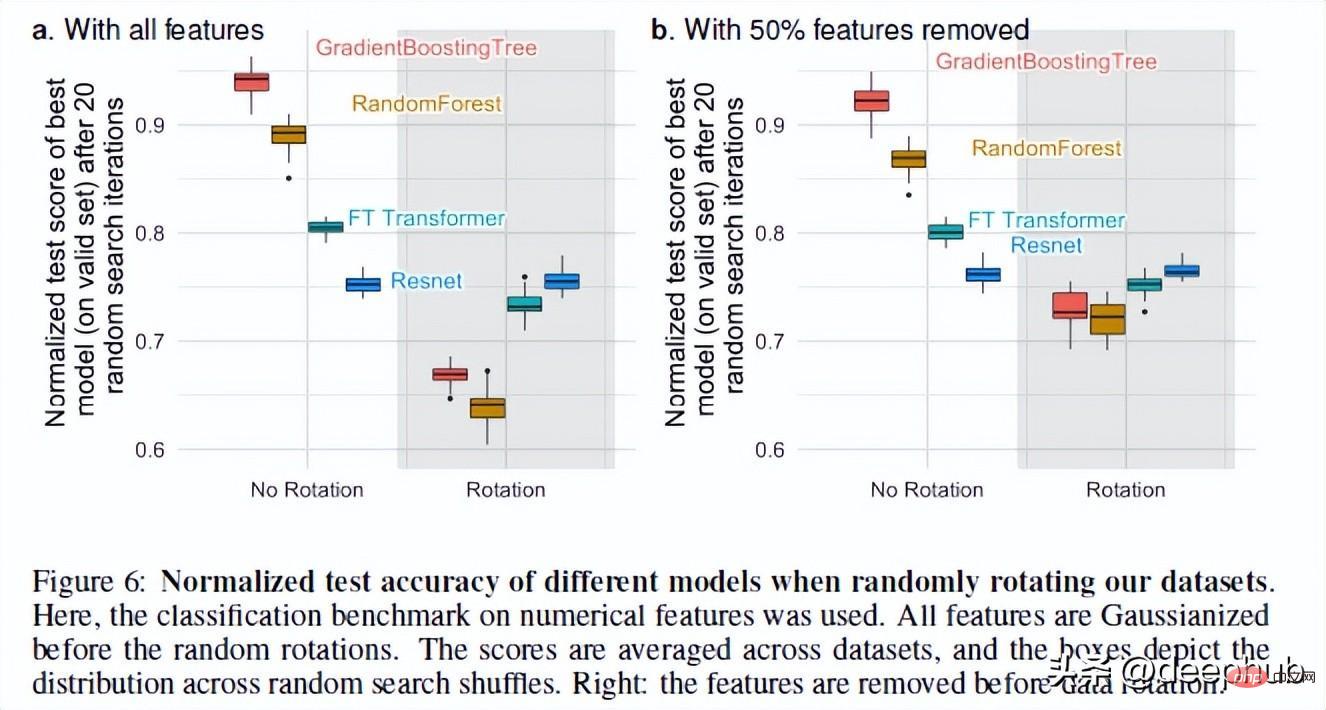
Ini sangat menarik: apakah sebenarnya maksud memutar set data Tiada penjelasan terperinci dalam keseluruhan kertas kerja (saya telah menghubungi pengarang dan akan menindaklanjuti fenomena ini) . Jika anda mempunyai sebarang pemikiran, sila kongsikannya dalam komen juga.
Tetapi operasi ini membolehkan kita melihat sebab varians putaran penting. Menurut pengarang, mengambil kombinasi linear ciri (yang menjadikan ResNets invarian) sebenarnya boleh menyalahgambarkan ciri dan hubungannya.
Mendapatkan bias data yang optimum dengan mengekodkan data asal, yang mungkin mencampurkan ciri dengan sifat statistik yang sangat berbeza dan tidak boleh dipulihkan oleh model invarian putaran, akan menyediakan model dengan prestasi yang Lebih Baik.
Ini adalah kertas kerja yang sangat menarik Walaupun pembelajaran mendalam telah mencapai kemajuan besar pada set data teks dan imej, ia pada asasnya tidak mempunyai kelebihan pada data jadual. Makalah ini menggunakan 45 set data daripada domain yang berbeza untuk ujian, dan keputusan menunjukkan bahawa walaupun tanpa mengambil kira kelajuan unggulnya, model berasaskan pokok masih tercanggih pada data sederhana (~10K sampel).
Atas ialah kandungan terperinci Mengapa model berasaskan pokok masih mengatasi pembelajaran mendalam pada data jadual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



