


这篇文章主要介绍了关于Pandas实现数据类型转换的一些技巧,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下
前言
Pandas是Python当中重要的数据分析工具,利用Pandas进行数据分析时,确保使用正确的数据类型是非常重要的,否则可能会导致一些不可预知的错误发生。
Pandas 的数据类型:数据类型本质上是编程语言用来理解如何存储和操作数据的内部结构。例如,一个程序需要理解你可以将两个数字加起来,比如 5 + 10 得到 15。或者,如果是两个字符串,比如「cat」和「hat」,你可以将它们连接(加)起来得到「cathat」。尚学堂•百战程序员陈老师指出有关 Pandas 数据类型的一个可能令人困惑的地方是,Pandas、Python 和 numpy 的数据类型之间有一些重叠。
大多数情况下,你不必担心是否应该明确地将熊猫类型强制转换为对应的 NumPy 类型。一般来说使用 Pandas 的默认 int64 和 float64 就可以。我列出此表的唯一原因是,有时你可能会在代码行间或自己的分析过程中看到 Numpy 的类型。
数据类型是在你遇到错误或意外结果之前并不会关心的事情之一。不过当你将新数据加载到 Pandas 进行进一步分析时,这也是你应该检查的第一件事情。
笔者使用Pandas已经有一段时间了,但是还是会在一些小问题上犯错误,追根溯源发现在对数据进行操作时某些特征列并不是Pandas所能处理的类型。因此本文将讨论一些小技巧如何将Python的基本数据类型转化为Pandas所能处理的数据类型。
Pandas、Numpy、Python各自支持的数据类型
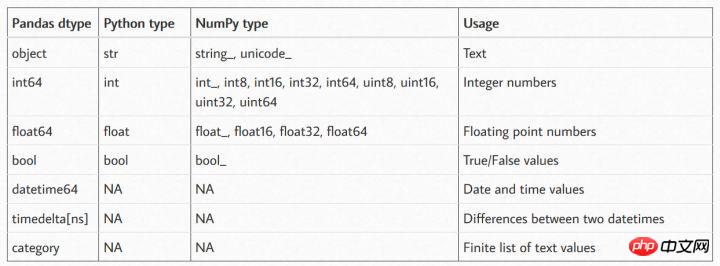
从上述表格中可以看出Pandas支持的数据类型最为丰富,在某种情形下Numpy的数据类型可以和Pandas的数据类型相互转化,毕竟Pandas库是在Numpy的基础之上开发的的。
引入实际数据进行分析
数据类型是你平常可能不太关心,直到得到了错误的结果才映像深刻的东西,因此在这里引入一个实际数据分析的例子来加深理解。
import numpy as np import pandas as pd data = pd.read_csv('data.csv', encoding='gbk') #因为数据中含有中文数据 data
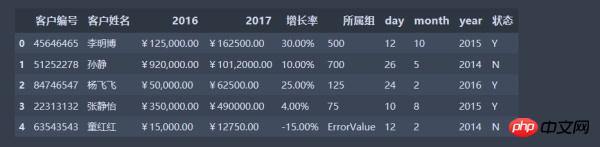
数据加载完毕,如果现在想要在该数据上进行一些操作,比如把数据列2016、2017对应项相加。
data['2016'] + data['2017'] #想当然的做法
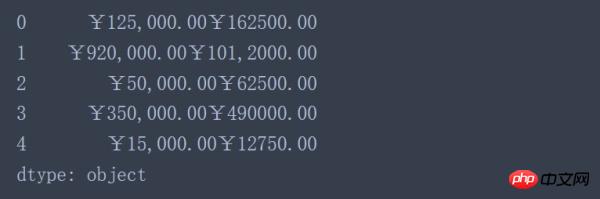
从结果来看并没有像想象中那样数值对应相加,这是因为在Pandas中object类型相加等价于Python中的字符串相加。
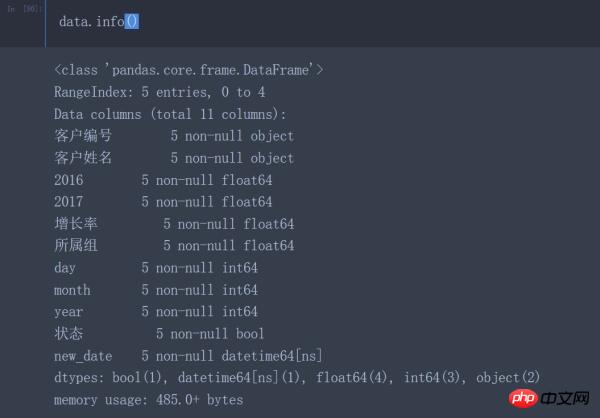
data.info() #在对数据进行处理之前应该先查看加载数据的相关信息
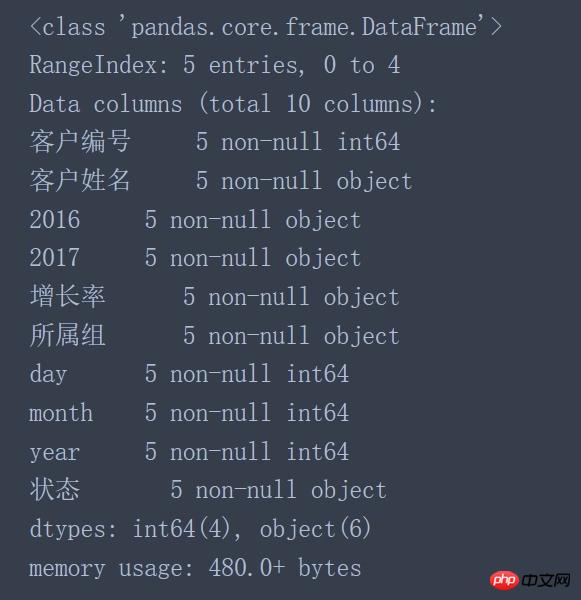
在看到加载数据的相关信息后可以发现如下几个问题:
客户编号的数据类型是int64而不是object类型
2016、2017列的数据类型是object而不是数值类型(int64、float64)
增长率、所属组的数据类型应该为数值类型而不是object类型
year、month、day的数据类型应该为datetime64类型而不是object类型
Pandas中进行数据类型转换有三种基本方法:
使用astype()函数进行强制类型转换
自定义函数进行数据类型转换
使用Pandas提供的函数如to_numeric()、to_datetime()
使用astype()函数进行类型转换
对数据列进行数据类型转换最简单的方法就是使用astype()函数
data['客户编号'].astype('object') data['客户编号'] = data['客户编号'].astype('object') #对原始数据进行转换并覆盖原始数据列
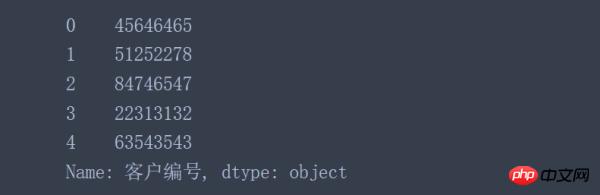
上面的结果看起来很不错,接下来给出几个astype()函数作用于列数据但失效的例子
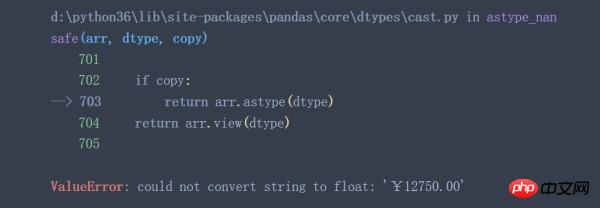
data['2017'].astype('float')
data['所属组'].astype('int')
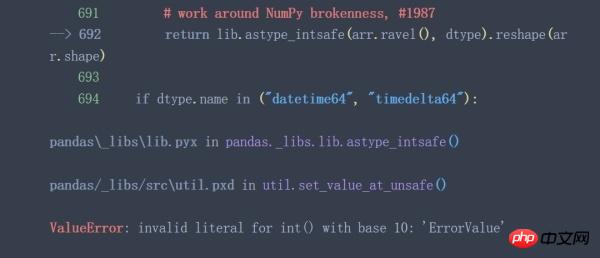
从上面两个例子可以看出,当待转换列中含有不能转换的特殊值时(例子中¥,ErrorValue等)astype()函数将失效。有些时候astype()函数执行成功了也并不一定代表着执行结果符合预期(神坑!)
data['状态'].astype('bool')
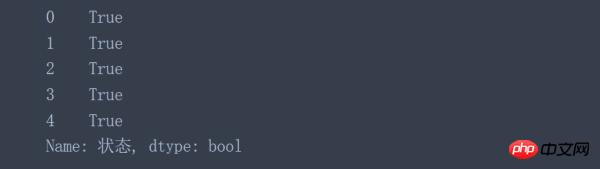
乍一看,结果看起来不错,但仔细观察后,会发现一个大问题。那就是所有的值都被替换为True了,但是该列中包含好几个N标志,所以astype()函数在该列也是失效的。
总结一下astype()函数有效的情形:
数据列中的每一个单位都能简单的解释为数字(2, 2.12等)
数据列中的每一个单位都是数值类型且向字符串object类型转换
如果数据中含有缺失值、特殊字符astype()函数可能失效。
使用自定义函数进行数据类型转换
该方法特别适用于待转换数据列的数据较为复杂的情形,可以通过构建一个函数应用于数据列的每一个数据,并将其转换为适合的数据类型。
对于上述数据中的货币,需要将它转换为float类型,因此可以写一个转换函数:
def convert_currency(value): """ 转换字符串数字为float类型 - 移除 ¥ , - 转化为float类型 """ new_value = value.replace(',', '').replace('¥', '') return np.float(new_value)
现在可以使用Pandas的apply函数通过covert_currency函数应用于2016列中的所有数据中。
data['2016'].apply(convert_currency)
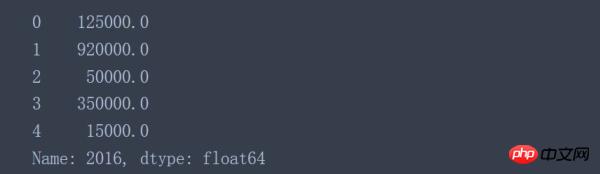
该列所有的数据都转换成对应的数值类型了,因此可以对该列数据进行常见的数学操作了。如果利用lambda表达式改写一下代码,可能会比较简洁但是对新手不太友好。
data['2016'].apply(lambda x: x.replace('¥', '').replace(',', '')).astype('float')
当函数需要重复应用于多个列时,个人推荐使用第一种方法,先定义函数还有一个好处就是可以搭配read_csv()函数使用(后面介绍)。
#2016、2017列完整的转换代码 data['2016'] = data['2016'].apply(convert_currency) data['2017'] = data['2017'].apply(convert_currency)
同样的方法运用于增长率,首先构建自定义函数
def convert_percent(value): """ 转换字符串百分数为float类型小数 - 移除 % - 除以100转换为小数 """ new_value = value.replace('%', '') return float(new_value) / 100
使用Pandas的apply函数通过covert_percent函数应用于增长率列中的所有数据中。
data['增长率'].apply(convert_percent)
使用lambda表达式:
data['增长率'].apply(lambda x: x.replace('%', '')).astype('float') / 100
结果都相同:
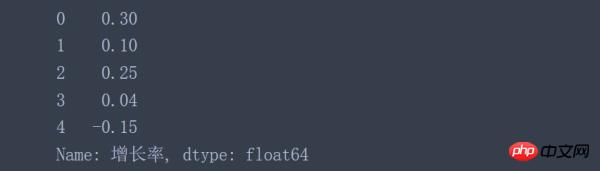
为了转换状态列,可以使用Numpy中的where函数,把值为Y的映射成True,其他值全部映射成False。
data['状态'] = np.where(data['状态'] == 'Y', True, False)
同样的你也可以使用自定义函数或者使用lambda表达式,这些方法都可以完美的解决这个问题,这里只是多提供一种思路。
利用Pandas的一些辅助函数进行类型转换
Pandas的astype()函数和复杂的自定函数之间有一个中间段,那就是Pandas的一些辅助函数。这些辅助函数对于某些特定数据类型的转换非常有用(如to_numeric()、to_datetime())。所属组数据列中包含一个非数值,用astype()转换出现了错误,然而用to_numeric()函数处理就优雅很多。
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)

可以看到,非数值被替换成0.0了,当然这个填充值是可以选择的,具体文档见
pandas.to_numeric - pandas 0.22.0 documentation
Pandas中的to_datetime()函数可以把单独的year、month、day三列合并成一个单独的时间戳。
pd.to_datetime(data[['day', 'month', 'year']])
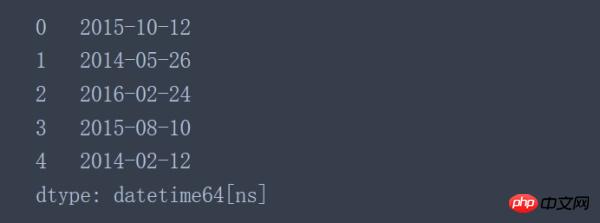
完成数据列的替换
data['new_date'] = pd.to_datetime(data[['day', 'month', 'year']]) #新产生的一列数据 data['所属组'] = pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
到这里所有的数据列都转换完毕,最终的数据显示:
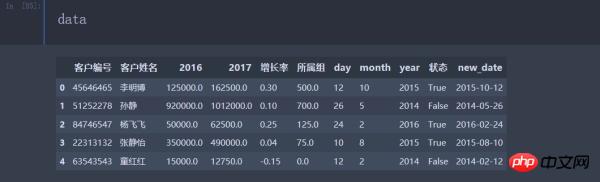
在读取数据时就对数据类型进行转换,一步到位
data2 = pd.read_csv("data.csv",
converters={
'客户编号': str,
'2016': convert_currency,
'2017': convert_currency,
'增长率': convert_percent,
'所属组': lambda x: pd.to_numeric(x, errors='coerce'),
'状态': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')在这里也体现了使用自定义函数比lambda表达式要方便很多。(大部分情况下lambda还是很简洁的,笔者自己也很喜欢使用)
总结
对数据集进行操作的第一步是确保设置正确的数据类型,然后才能进行数据的分析、可视化等操作,Pandas提供了很多非常方便的函数,有了这些函数那么对数据进行分析将会是很方便的。
相关推荐:
Atas ialah kandungan terperinci Pandas实现数据类型转换的一些技巧. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



