


Membuka Kekuatan Apache Lucene: Panduan Komprehensif
Pernah tertanya -tanya tentang enjin di belakang aplikasi carian teratas seperti Elasticsearch dan Solr? Apache Lucene, perpustakaan carian Java berprestasi tinggi, adalah jawapannya. Panduan ini memberikan pemahaman asas Lucene, walaupun bagi mereka yang baru untuk mencari kejuruteraan.
Objektif Pembelajaran:
(Artikel ini adalah sebahagian daripada Blogathon Sains Data.)
Jadual Kandungan:
Apa itu Apache Lucene?
Kuasa Lucene terletak pada beberapa konsep utama. Mari kita periksa mereka menggunakan contoh katalog produk:
{
"Product_id": "1",
"Tajuk": "Bunyi Tanpa Wayar Membatalkan Fon kepala",
"Jenama": "Bose",
"Kategori": ["Elektronik", "Audio", "Headphone"],
"Harga": 300
}
{
"Product_id": "2",
"Tajuk": "Bluetooth Mouse",
"Jenama": "Jelly Comb",
"Kategori": ["Elektronik", "Aksesori Komputer", "Mouse"],
"Harga": 30
}
{
"Product_id": "3",
"Tajuk": "Papan Kekunci Tanpa Wayar",
"jenama": "iclever",
"Kategori": ["Elektronik", "Aksesori Komputer", "Keyboard"],
"Harga": 40
}Dokumen: Unit asas dalam Lucene. Setiap kemasukan produk adalah dokumen, yang dikenal pasti secara unik oleh ID dokumen.
Bidang: Setiap atribut dalam dokumen (misalnya, product_id , title , brand ).
Istilah: satu unit carian. Lucene Preprocesses Text untuk mencipta istilah (misalnya, "tanpa wayar," "fon kepala").
| ID Dokumen | Syarat |
|---|---|
| 1 | Tajuk: Tanpa Wayar, Kebisingan, Pembatalan, Fon kepala; Jenama: Bose; Kategori: elektronik, audio, fon kepala |
| 2 | Tajuk: Bluetooth, Mouse; Jenama: Jelly, sikat; Kategori: Elektronik, Komputer, Aksesori |
| 3 | Tajuk: Wireless, Keyboard; Jenama: Iclever; Kategori: Elektronik, Komputer, Aksesori |

Segmen: Indeks boleh dibahagikan kepada pelbagai segmen, masing-masing bertindak sebagai indeks mandiri. Carian di seluruh segmen biasanya berurutan.
SCORING: Lucene menduduki kaitan dokumen menggunakan kaedah seperti TF-IDF (dan lain-lain seperti BM25).
Kekerapan jangka panjang (TF): Berapa kerap istilah muncul dalam dokumen.




Komponen Aplikasi Carian Lucene
Lucene terdiri daripada dua bahagian utama:
IndexWriter ): Indeks dokumen, melakukan pemprosesan teks (tokenisasi, dan lain -lain) dan mewujudkan indeks terbalik. 
IndexSearcher ): Melaksanakan carian menggunakan objek pertanyaan. 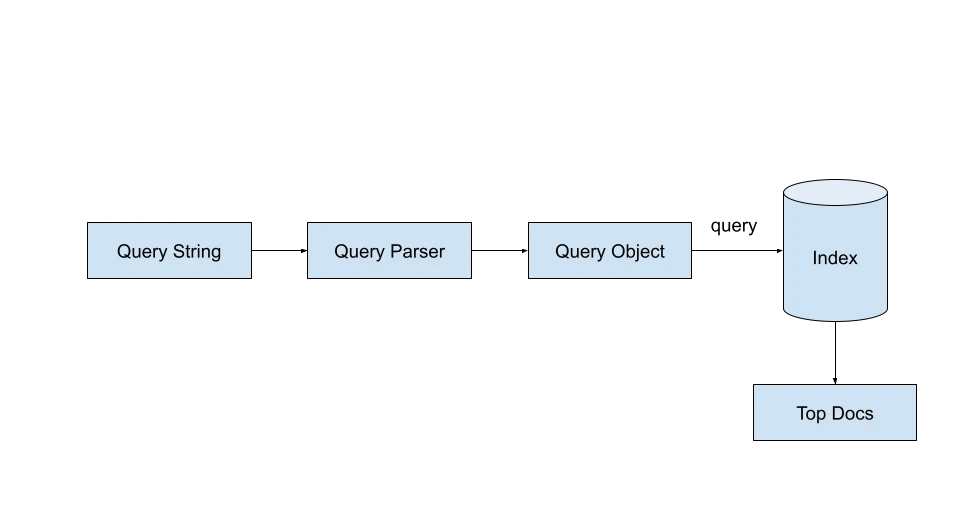
Jenis pertanyaan Lucene yang disokong
Lucene menawarkan pelbagai jenis pertanyaan:
Pertanyaan Term: Memadankan dokumen yang mengandungi istilah tertentu. new TermQuery(new Term("brand", "jelly"))
Pertanyaan Boolean: Menggabungkan pertanyaan lain menggunakan logik Boolean.
Pertanyaan Julat: Memadankan dokumen dengan nilai medan dalam julat yang ditentukan.
Pertanyaan Frasa: Memadankan dokumen yang mengandungi urutan istilah tertentu.
Pertanyaan fungsi: Skor dokumen berdasarkan nilai medan.
Membina aplikasi carian Lucene yang mudah
Kod Java berikut menunjukkan aplikasi Lucene yang mudah:
(Contoh kod untuk pengindeks dan pencari tetap sama seperti dalam input asal)
Kesimpulan
Apache Lucene adalah alat yang berkuasa untuk membina aplikasi carian berprestasi tinggi. Panduan ini telah meliputi asas -asas, membolehkan anda membuat penyelesaian carian yang lebih maju.
Takeaways Kunci:
IndexWriter dan IndexSearcher adalah penting untuk pengindeksan dan pencarian.Soalan yang sering ditanya
Q1. Adakah Lucene menyokong Python? A. Ya, melalui Pylucene.
S2. Apakah enjin carian sumber terbuka? A. Solr, OpenSearch, Meilisearch, dll.
Q3. Adakah Lucene menyokong carian semantik dan vektor? A. Ya, dengan batasan pada dimensi vektor (kini 1024).
Q4. Apakah algoritma pemarkahan kaitan yang digunakan oleh Lucene? A. TF-IDF, BM25, dll.
S5. Apakah beberapa contoh pertanyaan Lucene yang kompleks? A. Pertanyaan Fuzzy, pertanyaan span, dll.
(Nota: Imej dikekalkan dalam format dan kedudukan asalnya.)
Atas ialah kandungan terperinci Pengenalan kepada Apache Lucene. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 penggunaan atribut
penggunaan atribut
 Alat penilaian nama domain tapak web
Alat penilaian nama domain tapak web
 Apakah pelayan awan?
Apakah pelayan awan?
 Bagaimana untuk menyelesaikan masalah kehilangan steam_api.dll
Bagaimana untuk menyelesaikan masalah kehilangan steam_api.dll
 pelayar Ethereum pertanyaan mata wang digital
pelayar Ethereum pertanyaan mata wang digital
 Komponen utama yang membentuk CPU
Komponen utama yang membentuk CPU
 Apakah kaedah pemindahan fail java?
Apakah kaedah pemindahan fail java?
 Bagaimana untuk menetapkan komputer untuk menyambung ke WiFi secara automatik
Bagaimana untuk menetapkan komputer untuk menyambung ke WiFi secara automatik
 Adakah perdagangan Bitcoin dibenarkan di China?
Adakah perdagangan Bitcoin dibenarkan di China?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



