


Saya suka emoji. Siapa yang tidak?
Saya sedang menggilap siaran X yang sangat intelek beberapa hari lalu apabila saya menyedari sesuatu.
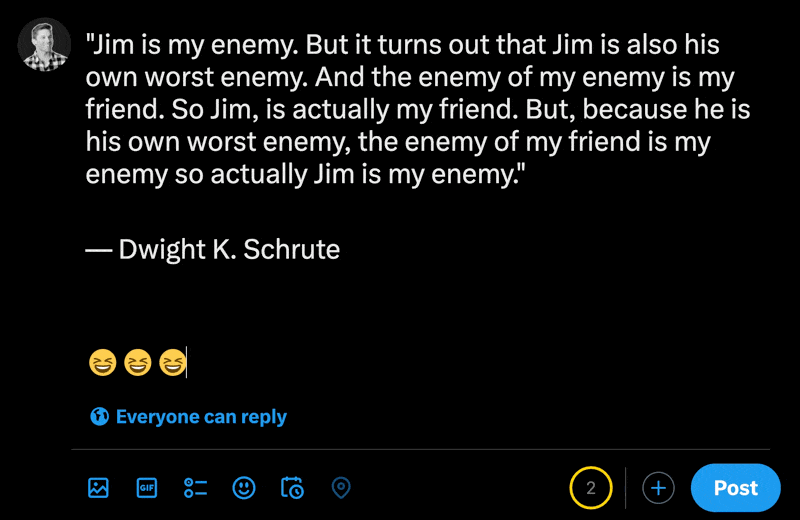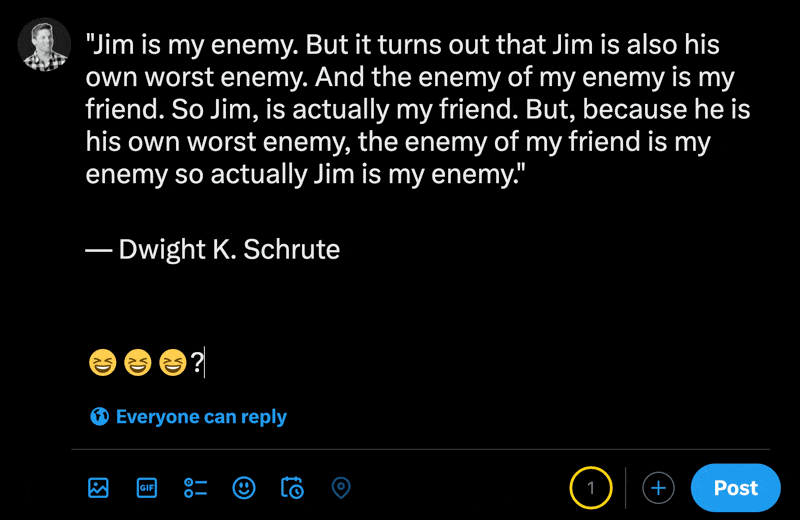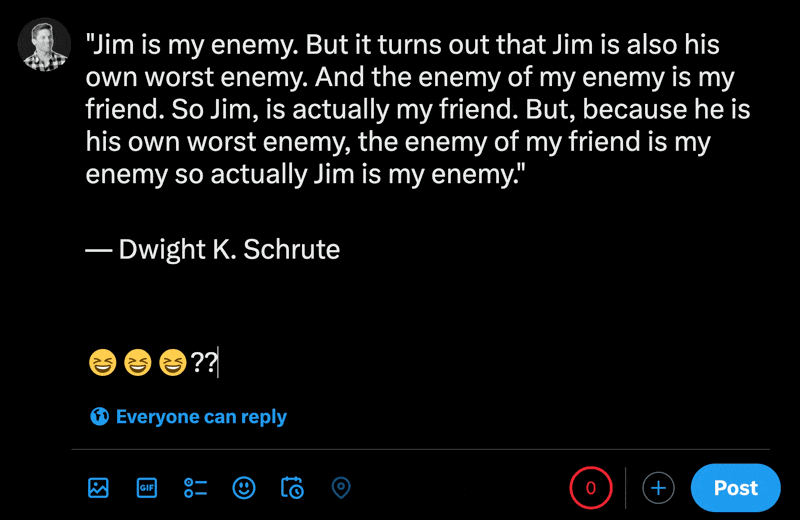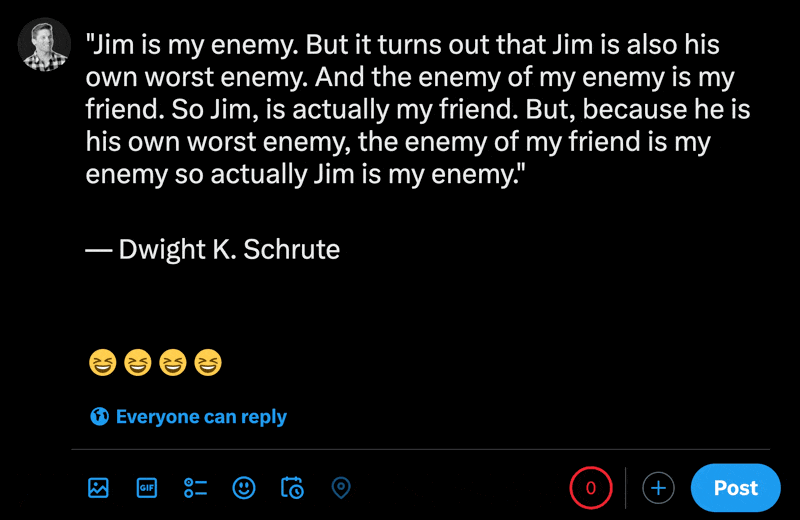
Apabila menaip emoji dalam bahagian siaran baharu X, anda boleh melihat cara aksara biasa dikira kurang daripada emoji.
Selepas carian pantas, saya mendapati ia ada kaitan dengan cara ia dikodkan dalam sistem Unicode.
Pada asasnya, emoji diperbuat daripada berbilang titik kod dan panjang hanya mengira titik kod, bukan aksara.
Tidak kira mengapa ia berlaku, saya memikirkan semua pembilang teks yang saya buat dan berapa banyak yang wujud di tanah SaaS.
Emoji tidak mendapat goncangan yang adil ?.
Hanya mengambil panjang rentetan bukanlah kiraan yang tepat. Ambil, sebagai contoh, sesuatu seperti ini:
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return text.length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
Ini ialah komponen React ringkas yang menjejaki aksara yang ditaip ke dalam medan teks. Ia merupakan pelaksanaan yang paling biasa bagi ciri ini.
Tetapi output memberi kita masalah yang sama seperti siaran X saya:

Anda boleh menggunakan objek terbina dalam yang dipanggil Intl.Segmenter.
Terdapat kes penggunaan yang lebih luas untuk objek, tetapi pada asasnya ia memecahkan rentetan kepada item yang lebih bermakna seperti perkataan dan ayat berdasarkan tempat yang anda berikan. Ia menawarkan lebih butiran daripada hanya menggunakan titik kod.
Untuk membetulkan contoh kami di atas, yang perlu kami lakukan ialah mengemas kini fungsi countString kami seperti ini:
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return Array.from(new Intl.Segmenter().segment(text)).length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
Kami mencipta contoh baharu objek Intl.Segmenter dan menghantar teks kami kepadanya. Kami meletakkan output itu ke dalam tatasusunan dan kemudian akhirnya mengambil panjang, yang akan menjadi jauh lebih tepat daripada hanya mengambil panjang rentetan asal.
Inilah hasilnya:

Jawapan ringkas: Saya tidak tahu.
Saya telah membuat pengaturcaraan terlalu lama untuk memperdayakan diri sendiri untuk berfikir ada jawapan yang mudah.
Tetapi Intl.Segmenter mempunyai sokongan penyemak imbas yang baik dan sebarang kekangan prestasi atau memori akan diabaikan.
Tekaan terbaik saya ialah pangkalan kod itu sangat besar dan terlalu lama sehingga tidak berbaloi dengan kesan sampingan refactor.
Saya berbesar hati untuk mengetahui lebih lanjut jika sesiapa mempunyai cerapan yang lebih baik tentang perkara ini.
Saya harap ini membantu ?.
Selamat pengekodan ?.
Atas ialah kandungan terperinci Cara Mengira Rentetan Dengan Emoji Dalam JavaScript. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



