Le cercle vidéo de l'IA « se bat ».
Luma et Runway de l'étranger, Kuaishou Keling, Byte Dream, Zhipu Qingying de Chine... chantez simplement et j'apparaîtrai. Sans exception, ils ciblent tous le légendaire Sora.
En fait, lorsqu'il s'agit des challengers mondiaux de Sora, Vidu de Shengshu Technology est indispensable.
Il y a trois mois déjà, alors que le domaine de la génération vidéo au pays et à l'étranger était encore « silencieux », Shengshu Technology a soudainement exposé la vidéo promotionnelle de son dernier modèle vidéo à grande échelle Vidu avec son aspect vif et réaliste. performances, il n'est pas inférieur à Sora. L'effet a étonné de nombreux internautes.
Aujourd'hui encore, Vidu est officiellement lancé. Aucune candidature n'est requise, tant que vous disposez d'une adresse e-mail, vous pouvez commencer. (Lien du site officiel de Vidu : www.vidu.studio)
Par exemple, Pikachu et Doraemon jouent à "Cheap Kill" :

Les protagonistes masculins et féminins de "Twilight" montrent leur affection :

Cela résout même le problème de l'incapacité de l'IA à écrire :

De plus, l'efficacité de génération de Vidu est également étonnante, atteignant la vitesse d'inférence la plus rapide de l'industrie, et il ne faut que 30 secondes pour générer un 4- deuxième séquence.
Ensuite, nous fournirons le dernier examen de première main pour voir à quel point ce "Sora domestique" est fort.
Test pratique : le langage de l'objectif est audacieux et l'image ne s'effondrera pas !
Cette fois, Vidu a montré ses compétences uniques.
Non seulement continue les avantages de la dynamique élevée, de la haute fidélité et de la cohérence élevée démontrés en avril de cette année, mais ajoute également de nouvelles fonctionnalités telles que le style d'animation, la génération d'écrans de texte et d'effets spéciaux et la cohérence des personnages.
Le thème principal est : je veux avoir les fonctions que les autres ont, et je veux aussi avoir les fonctions que les autres n'ont pas.
Oh non, il reconnaît en fait les caractères et les chiffres
À ce stade, Vidu a deux fonctions principales : la vidéo Wen Sheng et la vidéo Tuxing.
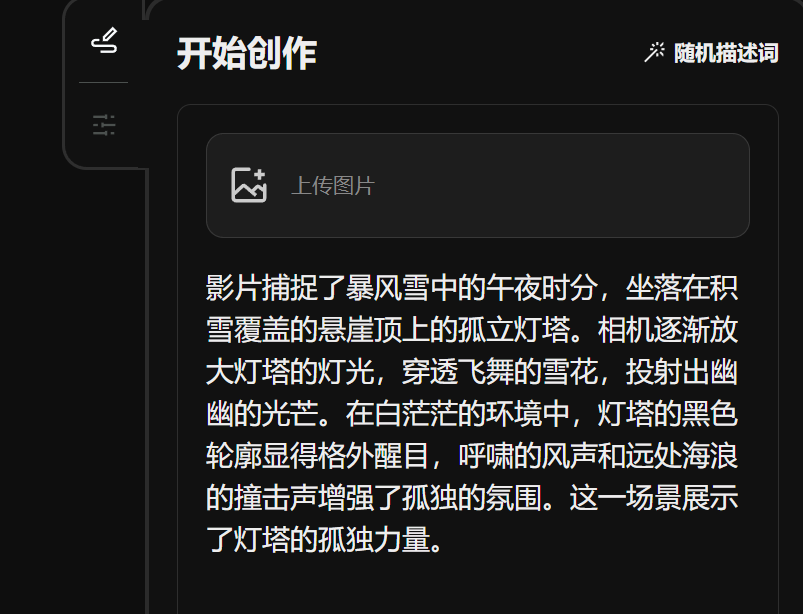
Fournit deux options de durée de 4s et 8s, avec une résolution jusqu'à 1080P. En termes de style, il existe deux options : réaliste et animé.
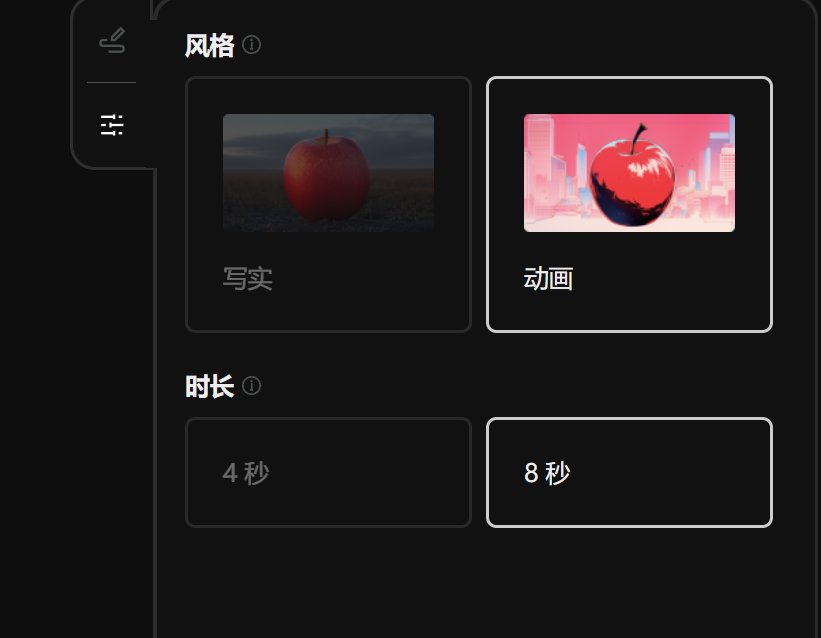
Regardez d'abord la vidéo de Tusheng.
Ramener l'histoire à la vie est la façon de jouer la plus populaire du moment. Il s'agit de la célèbre œuvre "Portrait du peintre et de sa fille" de la peintre française Elisabeth Louise Verry.

Nous entrons le mot prompt : portrait du peintre et de sa fille, mère et fille s'embrassant étroitement.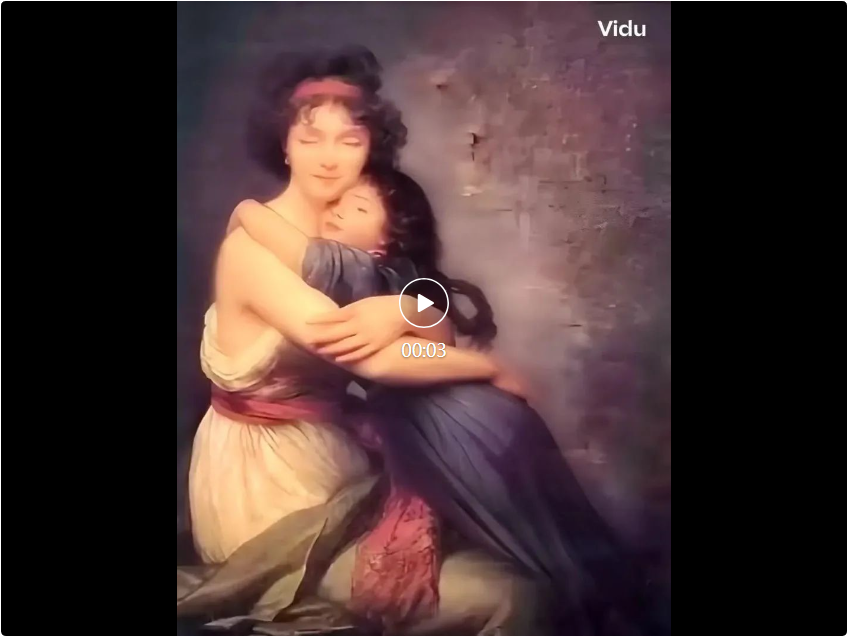
La version haute définition générée est accrocheuse. Les personnages bougent largement et même leurs yeux changent, mais l'effet est assez naturel.
Essayez à nouveau "La Femme à la belette d'argent" de Léonard de Vinci.

즉시말: 은색 족제비를 안고 있는 여자가 웃고 있습니다.
 8초 길이의 영상 속에서 여성과 반려동물이 크게 움직이는데, 특히 여성의 손을 만지는 동작, 몸과 얼굴의 변화 등이 모두 사진의 자연스러움과 부드러움에 영향을 미치지 않습니다.
크고 정확한 움직임은 영상의 줄거리와 캐릭터의 감정을 더 잘 표현하는 데 도움이 됩니다. 그러나 동작 범위가 커지면 화면이 무너지기 쉽습니다. 따라서 일부 모델은 부드러움을 보장하기 위해 진폭을 희생하지만 Vidu는 이 문제를 더 잘 해결합니다.
실제 물리적 세계의 움직임을 시뮬레이션하는데 정말 좋습니다. 예를 들어, 큐브릭의 "2001: A Space Odyssey"와 유사한 장면을 재현해보세요! ㅋㅋㅋ 프롬프트 단어: 긴 렌즈 아래에서 천천히 사라집니다.长 : 알림 단어: 긴 렌즈 아래에 떠 있고 끝에 천천히 떠 있습니다.
8초 길이의 영상 속에서 여성과 반려동물이 크게 움직이는데, 특히 여성의 손을 만지는 동작, 몸과 얼굴의 변화 등이 모두 사진의 자연스러움과 부드러움에 영향을 미치지 않습니다.
크고 정확한 움직임은 영상의 줄거리와 캐릭터의 감정을 더 잘 표현하는 데 도움이 됩니다. 그러나 동작 범위가 커지면 화면이 무너지기 쉽습니다. 따라서 일부 모델은 부드러움을 보장하기 위해 진폭을 희생하지만 Vidu는 이 문제를 더 잘 해결합니다.
실제 물리적 세계의 움직임을 시뮬레이션하는데 정말 좋습니다. 예를 들어, 큐브릭의 "2001: A Space Odyssey"와 유사한 장면을 재현해보세요! ㅋㅋㅋ 프롬프트 단어: 긴 렌즈 아래에서 천천히 사라집니다.长 : 알림 단어: 긴 렌즈 아래에 떠 있고 끝에 천천히 떠 있습니다.

 투성 영상 외에도 빈센트 영상도 있어요.朵 활용팁: 검은 바탕에 두 개의 꽃이 천천히 피어나 섬세한 꽃잎과 수술을 보여줍니다.
투성 영상 외에도 빈센트 영상도 있어요.朵 활용팁: 검은 바탕에 두 개의 꽃이 천천히 피어나 섬세한 꽃잎과 수술을 보여줍니다.
Petua: Di pondok antik tepi laut, matahari memandikan bilik, kamera perlahan-lahan beralih ke balkoni yang menghadap ke laut yang tenang, dan akhirnya kamera membeku di laut terapung, perahu layar dan awan pemantul.
Vidu juga boleh memahami dengan tepat dan menyatakan bahasa kanta seperti fotografi orang pertama dan selang masa Pengguna hanya perlu memperhalusi perkataan gesaan untuk meningkatkan kebolehkawalan video dengan lebih baik.
 Vidu ialah penjana video yang boleh memahami dan menjana beberapa perbendaharaan kata dengan tepat, seperti nombor.块 Petua: Kek hari jadi dengan lilin di atasnya adalah nombor "32".
Vidu ialah penjana video yang boleh memahami dan menjana beberapa perbendaharaan kata dengan tepat, seperti nombor.块 Petua: Kek hari jadi dengan lilin di atasnya adalah nombor "32".
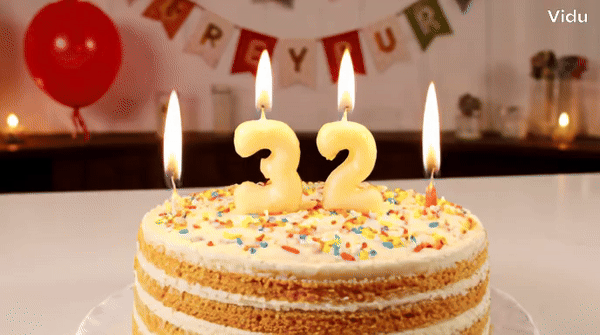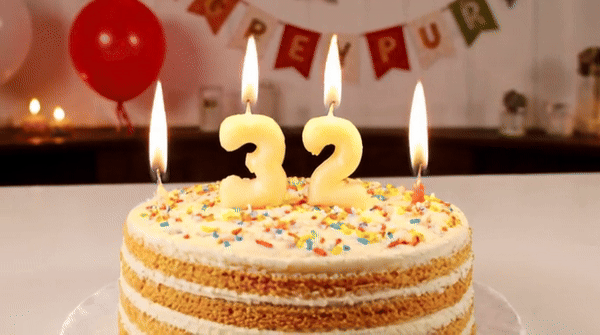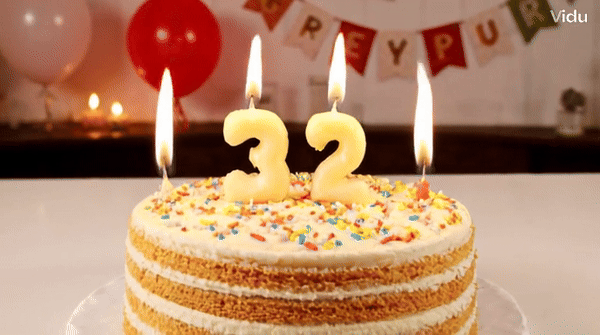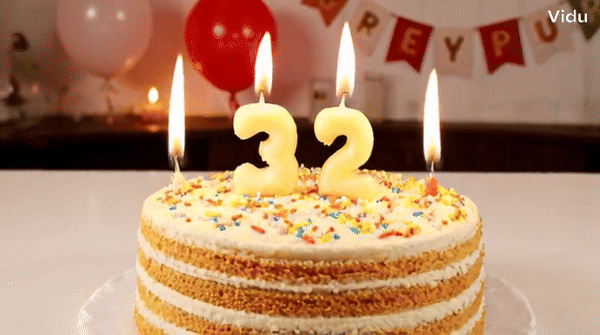
Tukar perkataan "Happy Birthday" pada kek dan ia akan bertahan. .
Gaya anime mudah digunakan
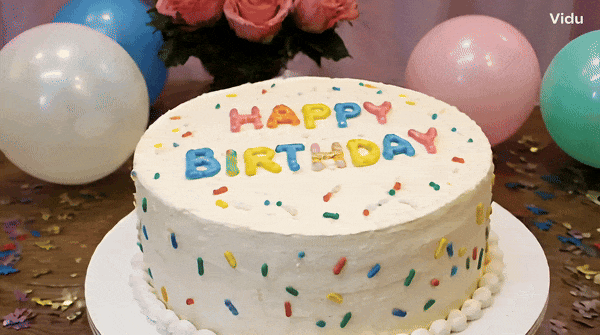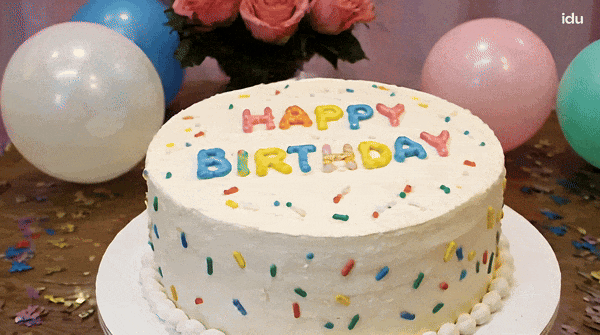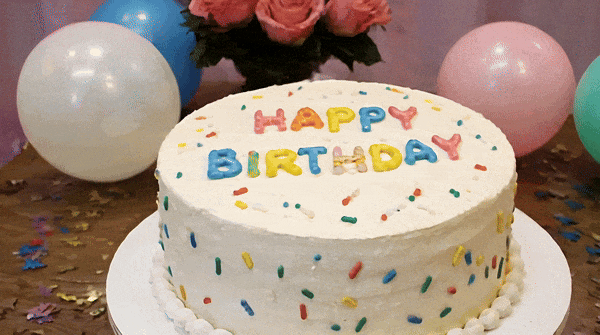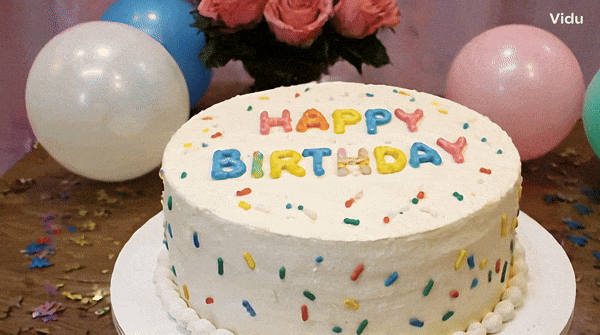
Kebanyakan alat video AI yang ada di pasaran kini terhad kepada gaya realistik atau berdasarkan imaginasi realistik, manakala Vidu bukan sahaja , tetapi turut menyokong gaya anime.
Kami memilih model animasi dan terus memasukkan perkataan gesaan untuk mengeluarkan video gaya animasi.
Contohnya, kata gesaan: gaya anime, gadis kecil berdiri di dapur memotong sayur.
Sejujurnya, gaya lukisan ini mempunyai perisa Hayao Miyazaki. Vidu memahami kata-kata pantas itu, dan gadis kecil itu memotong sayur dengan lancar, tetapi jari dan pisaunya masih cacat secara tidak sengaja.
Kata anjuran: Gaya anime, seorang gadis kecil memakai fon kepala sedang menari.
Vidu mempunyai banyak imaginasi Dia menetapkan latar belakang ke taman dengan air pancut, yang juga menjadikan video itu kurang monoton.
Sudah tentu, kita juga boleh memuat naik gambar rujukan anime dan memasukkan perkataan gesaan, supaya watak anime dalam gambar boleh bergerak.

Sebagai contoh, kami memuat naik gambar statik Crayon Shin-chan, dan kemudian masukkan perkataan gesaan: Crayon Shin-chan ketawa dan mengangkat bunga kecil di tangannya. Pilih "Gunakan sebagai bingkai permulaan" untuk penggunaan imej.
효과를 살펴보겠습니다.
 귀여운 피카츄 이미지를 업로드하고 "피카츄가 행복하게 뛰어오릅니다"라는 메시지를 입력하세요. 이미지 사용을 위해 "시작 프레임으로 사용"을 선택하십시오.
귀여운 피카츄 이미지를 업로드하고 "피카츄가 행복하게 뛰어오릅니다"라는 메시지를 입력하세요. 이미지 사용을 위해 "시작 프레임으로 사용"을 선택하십시오.

계속해서 효과를 적용하세요.
 "One Piece"의 Luffy 이미지를 업로드하고 프롬프트 단어를 입력하세요. 소년이 갑자기 울기 시작했습니다.
"One Piece"의 Luffy 이미지를 업로드하고 프롬프트 단어를 입력하세요. 소년이 갑자기 울기 시작했습니다.

효과는 다음과 같습니다.
 Vidu의 애니메이션 효과는 스타일의 일관성을 유지하면서도 영상의 안정성과 부드러움을 크게 향상시키며, 정말 놀랍습니다. 변형이나 붕괴가 없습니다. 또는 여섯 손가락의 미치광이와 왼쪽과 오른쪽 다리가 불분명한 등의 "사악한" 장면.
"Tusheng Video" 섹션에서 Vidu는 첫 번째 프레임 이미지 업로드를 지원하는 것 외에도 이번에 새로운 기능인 문자 일관성( 캐릭터를 비디오로).
소위 캐릭터 일관성이란 캐릭터 이미지를 업로드한 다음 캐릭터를 지정하여 어떤 장면에서나 어떤 행동을 할 수 있도록 하는 것입니다.
Vidu의 애니메이션 효과는 스타일의 일관성을 유지하면서도 영상의 안정성과 부드러움을 크게 향상시키며, 정말 놀랍습니다. 변형이나 붕괴가 없습니다. 또는 여섯 손가락의 미치광이와 왼쪽과 오른쪽 다리가 불분명한 등의 "사악한" 장면.
"Tusheng Video" 섹션에서 Vidu는 첫 번째 프레임 이미지 업로드를 지원하는 것 외에도 이번에 새로운 기능인 문자 일관성( 캐릭터를 비디오로).
소위 캐릭터 일관성이란 캐릭터 이미지를 업로드한 다음 캐릭터를 지정하여 어떤 장면에서나 어떤 행동을 할 수 있도록 하는 것입니다.
우징을 예로 들어보겠습니다. ㅋㅋㅋ 프롬프트 말: 우주선 안에서 Wu Jing은 우주복을 입고 카메라를 향해 손을 흔들고 있습니다. ㅋㅋㅋ ~


첫 번째 프레임 이미지를 업로드하는 것이 장면 일관성이 있는 동영상을 만드는 데 적합하다면, 역할 일관성 기능을 사용하면 배우가 공상과학 역할에서 현대 드라마로 72번 변경할 수 있습니다.
게다가 캐릭터 일관성 기능으로 일반 사용자도 재미있게 "밈", "이모티콘"을 만들 수 있어요!

예를 들어, "잊을 수 없는" 북미 저스틴 비버와 셀레나는 다시 인연을 맺었습니다:
"무림가이덴"에서 통샹위와 바이잔탕은 멜론씨를 먹으며 통푸 여관의 소문에 대해 이야기를 나누고 있었습니다. :
"진환전설"에도 서럽게 우는 황후가 있습니다:
당신의 상상력이 충분히 크면 Vidu는 지하철에 있는 노인이 휴대폰을 먹게 하고, Ao Bai와 Wei Xiaobao가 보를 연주하게 하고, Rong 할머니가 Ziwei 닭다리에 먹이를 주게 할 수 있습니다.
영상 제작 과정에서 유저들이 가장 짜증나는 점은 무엇인가요? 물론 크롤링 진행률 표시줄입니다.
몇 초 분량의 영상을 위해 컴퓨터 앞에 누워서 10분을 기다린다고 상상해 보세요. 아무리 조급한 사람이라도 방어를 깨지 않기는 어려울 것입니다.
현재 시중에 나와 있는 주류 AI 동영상 도구는 약 4초 분량의 동영상 클립을 생성하는데, 이는 일반적으로 1~5분 또는 그 이상이 소요됩니다.
예를 들어 Runway의 최신 Gen-3 도구는 5초 비디오 생성을 완료하는 데 1분이 걸리고 Keling은 2~3분이 걸리며 Vidu는 이 대기 시간을 30초로 단축합니다. 이는 업계에서 가장 빠른 것보다 빠릅니다. 3세대는 2배 빠릅니다.

완전히 자체 개발한 U-ViT 아키텍처를 기반으로 하며 상업용으로 신중하게 배치되었습니다.
"Vidu"의 하단 레이어는 완전 자체 개발된 U-ViT 아키텍처를 기반으로 하며, Sora보다 먼저 채택된 DiT 아키텍처는 Diffusion과 Transformer를 통합한 세계 최초의 아키텍처입니다.

DiT 논문이 발표되기 두 달 전에 Tsinghua University의 Zhu Jun 팀은 "All are Worth Words: A ViT Backbone for Diffusion Models"라는 논문을 제출했습니다. 본 논문에서는 CNN 기반의 U-Net을 대체하기 위해 Transformer를 사용하는 네트워크 아키텍처 U-ViT를 제안한다. 이것이 "Vidu"의 가장 중요한 기술적 기반입니다.
Comme elle n'implique pas de traitement en plusieurs étapes tel que l'insertion et l'épissage d'images intermédiaires, la conversion du texte en vidéo est directe et continue. Le travail de "Vidu" semble plus ponctuel et la vidéo est générée en continu du début à la fin. fin, sans aucune trace d'insertion de cadre. En plus des innovations dans l'architecture sous-jacente, « Vidu » réutilise également l'expérience et les capacités d'ingénierie accumulées par Shengshu Technology dans le passé.
Shengshu Technology a dit un jour que de l'unification des tâches graphiques à l'intégration des capacités vidéo, « Vidu » peut être considéré comme un modèle visuel universel pouvant prendre en charge la génération de contenu vidéo plus diversifié et plus long. Ils ont également révélé que « Vidu » continue d’accélérer les améliorations itératives. Face à l’avenir, l’architecture de modèle flexible de « Vidu » sera également compatible avec un plus large éventail de capacités multimodales.
Shengshu Technology a été créée en mars 2023. Les principaux membres sont issus de l'Institut de recherche en intelligence artificielle de l'Université Tsinghua et s'engagent à développer de manière indépendante le premier grand modèle général multimodal contrôlable au monde. Depuis sa création en 2023, l'équipe a été reconnue par de nombreuses institutions industrielles bien connues telles que Ant Group, Qiming Venture Partners, BV Baidu Ventures, Byte Jinqiu Fund, etc., et a réalisé un financement de centaines de millions de yuans. Il est rapporté que Shenshu Technology est actuellement l'équipe entrepreneuriale la plus valorisée dans le secteur des grands modèles multimodaux en Chine.
Le scientifique en chef de l'entreprise est Zhu Jun, directeur adjoint de l'Institut de recherche sur l'intelligence artificielle de Tsinghua.
PDG Tang Jiayua étudié au département d'informatique de l'Université de Tsinghua et est membre du groupe THUNLP ; doctorant au Département d'informatique de l'Université Tsinghua et professeur Zhu Jun. Membre de l'équipe de recherche, il s'intéresse depuis longtemps à la recherche dans le domaine des modèles de diffusion. Il a dirigé la réalisation d'U-ViT et d'UniDiffuser.
En janvier de cette année, PixWeaver, une plate-forme de conception créative visuelle appartenant à Shengshu Technology, a lancé une fonction de génération de vidéos courtes, prenant en charge un contenu vidéo court hautement esthétique de 4 secondes. Après le lancement de Sora en février, Shengshu Technology a créé une équipe de recherche interne pour accélérer les progrès de la recherche et du développement dans la direction vidéo originale. En moins d'un mois, elle a réalisé une génération vidéo de 8 secondes en interne, puis a franchi la barre des 16. -deuxième génération vidéo en avril, réalisant des percées dans tous les aspects de la qualité et de la durée de la génération.
Si la sortie du modèle en avril a démontré le leadership de Vidu en matière de capacités de génération vidéo, le produit officiellement lancé démontre cette fois la mise en page soignée de Vidu en matière de commercialisation. Shengshu Technology adopte actuellement un modèle bidirectionnel de couche modèle et de couche application.
D'une part, créer un grand modèle polyvalent de bas niveau couvrant des capacités multimodales telles que du texte, des images, des vidéos, des modèles 3D, etc., et fournir des capacités de service de modèle pour la face B.
D'autre part, les applications verticales sont créées pour des scénarios tels que la génération d'images et la génération de vidéos, et sont facturées sous forme d'abonnements. Les directions d'application sont principalement des scénarios de création de contenu tels que la production de jeux et la publication de films et de télévision. -production.
Lien de référence :
Lien du site officiel de Vidu : www.vidu.studio
Atas ialah kandungan terperinci Satu lagi 'versi domestik Sora' dilancarkan secara global! Pasukan keusahawanan Tsinghua Zhu Jun, penjanaan video hanya mengambil masa 30 saat. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




 Bagaimana untuk menggunakan NSTimeInterval
Bagaimana untuk menggunakan NSTimeInterval Cara membuat entri ensiklopedia
Cara membuat entri ensiklopedia Bagaimana untuk mendapatkan Bitcoin
Bagaimana untuk mendapatkan Bitcoin Penggunaan lain dalam struktur gelung Python
Penggunaan lain dalam struktur gelung Python tag biasa untuk dedecms
tag biasa untuk dedecms Apakah arahan pembersihan cakera?
Apakah arahan pembersihan cakera? Bagaimana untuk menyelesaikan masalah yang tiba-tiba semua folder tidak boleh dibuka dalam win10
Bagaimana untuk menyelesaikan masalah yang tiba-tiba semua folder tidak boleh dibuka dalam win10 Mengapa melumpuhkan kemas kini automatik dalam Windows 11 adalah tidak sah
Mengapa melumpuhkan kemas kini automatik dalam Windows 11 adalah tidak sah




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



