

 Peranti teknologi
AI
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Peranti teknologi
AI
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG


Editor |. ScienceAI
Set data Soal Jawab (QA) memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik.
Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan lain-lain, set data ini masih mempunyai beberapa kekurangan.
Pertama, borang data adalah agak mudah, yang kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi ia mengehadkan julat pilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, jawapan soalan terbuka (openQA) boleh menilai dengan lebih komprehensif keupayaan model, tetapi tidak mempunyai metrik penilaian yang sesuai.
Kedua, kebanyakan kandungan set data sedia ada datang daripada buku teks di peringkat universiti dan ke bawah, menjadikannya sukar untuk menilai keupayaan pengekalan pengetahuan peringkat tinggi LLM dalam penyelidikan akademik sebenar atau persekitaran pengeluaran.
Ketiga, penciptaan set data penanda aras ini bergantung pada anotasi pakar manusia.
Menangani cabaran ini adalah penting untuk membina set data QA yang lebih komprehensif dan juga kondusif untuk penilaian LLM saintifik yang lebih tepat.
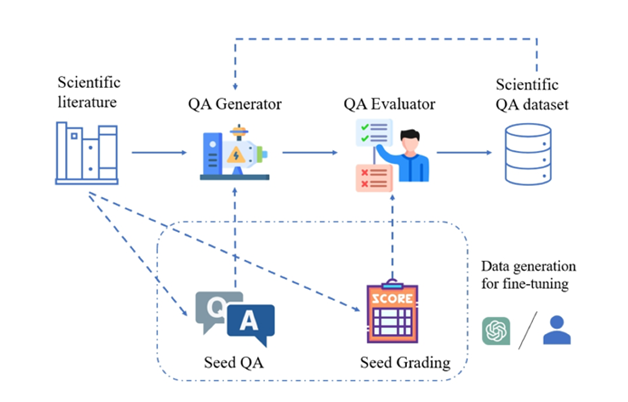
Ilustrasi: Rangka kerja SciQAG untuk menjana pasangan soalan dan jawapan saintifik berkualiti tinggi daripada kesusasteraan saintifik.
Untuk tujuan ini, Makmal Kebangsaan Argonne di Amerika Syarikat, pasukan Profesor Ian Foster dari Universiti Chicago (pemenang Hadiah Gordon Bell 2002), pasukan UNSW AI4Science Profesor Bram Hoex dari Universiti New South Wales, Australia, syarikat AI4Science GreenDynamics dan pasukan Profesor Jie Chunyu dari City University of Hong Kong bersama-sama mencadangkan SciQAG, rangka kerja novel pertama yang menjana pasangan soalan dan jawapan terbuka saintifik berkualiti tinggi secara automatik daripada korpora kesusasteraan saintifik besar berdasarkan model bahasa besar (LLM).

Pautan kertas:https://arxiv.org/abs/2405.09939
pautan github:https://github.com/MasterAI-EAM/SciQAG
menyiasat SciQAG SciQAG-24D, set data QA saintifik terbuka berskala besar, berkualiti tinggi dan terbuka, mengandungi 188,042 pasangan QA yang diekstrak daripada 22,743 kertas saintifik dalam 24 bidang saintifik, dan direka bentuk untuk menyempurnakan LLM dan penilaian masalah saintifik- keupayaan menyelesaikan. Percubaan menunjukkan bahawa LLM yang diperhalusi pada set data SciQAG-24D boleh meningkatkan prestasinya dengan ketara dalam menjawab soalan terbuka dan tugasan saintifik. Set data, model dan kod penilaian telah menjadi sumber terbuka (https://github.com/MasterAI-EAM/SciQAG) untuk menggalakkan pembangunan bersama Soal Jawab saintifik terbuka oleh komuniti AI untuk Sains.Rangka kerja SciQAG dengan set data penanda aras SciQAG-24D
SciQAG terdiri daripada penjana QA dan penilai QA, yang bertujuan untuk menjana pasangan soalan dan jawapan terbuka yang pelbagai dengan cepat berdasarkan kesusasteraan saintifik pada skala. Mula-mula, penjana menukar kertas saintifik kepada pasangan soal jawab, dan kemudian penilai menapis pasangan soalan dan jawapan yang tidak memenuhi piawaian kualiti, dengan itu memperoleh set data soalan dan jawapan saintifik yang berkualiti tinggi.QA Generator
Para penyelidik mereka bentuk gesaan dua langkah (prompt) melalui eksperimen perbandingan, membolehkan LLM mengekstrak kata kunci dahulu dan kemudian menjana pasangan soalan dan jawapan berdasarkan kata kunci. Memandangkan set data soalan dan jawapan yang dijana menggunakan mod "buku tertutup", iaitu kertas asal tidak disediakan dan hanya menumpukan pada pengetahuan saintifik yang diekstrak itu sendiri. Gesaan memerlukan pasangan soalan dan jawapan yang dihasilkan tidak bergantung pada atau merujuk kepada maklumat unik dalam kertas asal (contohnya, tiada tatanama moden dibenarkan seperti "kertas ini/ini", "penyelidikan ini/ini", dsb., atau bertanya soalan tentang jadual/gambar dalam). rencana). Untuk mengimbangi prestasi dan kos, para penyelidik memilih untuk memperhalusi LLM sumber terbuka sebagai penjana. Pengguna SciQAG boleh memilih mana-mana LLM sumber terbuka atau sumber tertutup sebagai penjana mengikut keadaan mereka sendiri, sama ada menggunakan penalaan halus atau kejuruteraan kata segera.Penilai QA
Penilai digunakan untuk mencapai dua tujuan: (1) Menilai kualiti pasangan soalan dan jawapan yang dihasilkan; (2) Buang pasangan soalan dan jawapan berkualiti rendah berdasarkan kriteria yang ditetapkan. Penyelidik membangunkan indeks penilaian komprehensif RACAR, yang terdiri daripada lima dimensi: perkaitan, agnostik, kesempurnaan, ketepatan dan kewajaran. Dalam kajian ini, penyelidik secara langsung menggunakan GPT-4 sebagai penilai QA untuk menilai pasangan QA yang dijana mengikut RACAR, dengan tahap penilaian 1-5 (1 bermakna tidak boleh diterima, 5 bermakna boleh diterima sepenuhnya). Seperti yang ditunjukkan dalam rajah, untuk mengukur ketekalan antara GPT-4 dan penilaian manual, dua pakar domain menggunakan metrik RACAR untuk melakukan penilaian manual pada 10 artikel (sebanyak 100 pasangan soalan dan jawapan). Pengguna boleh memilih mana-mana LLM sumber terbuka atau sumber tertutup sebagai penilai mengikut keperluan mereka. 🎜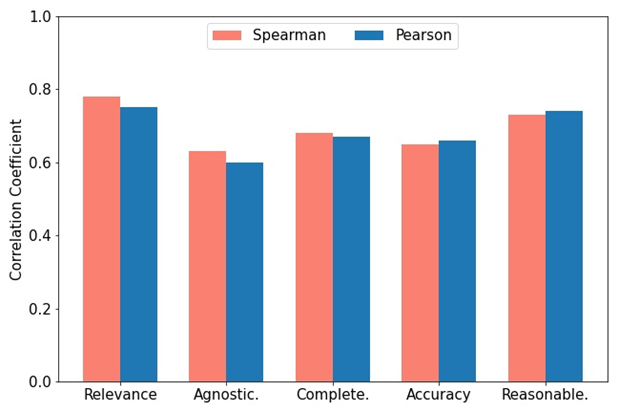
Ilustrasi: Korelasi Spearman dan Pearson antara markah yang diberikan GPT-4 dan skor anotasi pakar.
Aplikasi rangka kerja SciQAG
Kajian ini memperoleh sejumlah 22,743 kertas kerja yang mendapat sebutan tinggi dalam 24 kategori daripada pangkalan data koleksi teras Web of Science (WoS), daripada bidang sains bahan, kimia, fizik, tenaga, dll. , bertujuan untuk membina sumber pengetahuan saintifik yang boleh dipercayai, kaya, seimbang dan mewakili.
Untuk memperhalusi LLM sumber terbuka untuk membentuk penjana QA, penyelidik secara rawak memilih 426 kertas daripada koleksi kertas sebagai input dan menghasilkan 4260 pasangan QA benih dengan menggesa GPT-4.
Menggunakan penjana QA terlatih untuk melakukan inferens pada baki kertas, sejumlah 227,430 pasangan QA (termasuk pasangan QA benih) telah dihasilkan. Lima puluh kertas telah diekstrak daripada setiap kategori (1,200 kertas keseluruhannya), GPT-4 digunakan untuk mengira skor RACAR bagi setiap pasangan QA yang dijana, dan pasangan QA dengan mana-mana skor dimensi yang lebih rendah daripada 3 ditapis sebagai set ujian.
Untuk pasangan QA yang tinggal, kaedah berasaskan peraturan digunakan untuk menapis semua pasangan soalan dan jawapan yang mengandungi maklumat unik kertas untuk membentuk set latihan.
Set data penanda aras SciQAG-24D
Berdasarkan perkara di atas, penyelidik menubuhkan set data penanda aras QA saintifik terbuka SciQAG-24D Set latihan yang ditapis termasuk 21,529 kertas dan 179,511 set berpasangan QA. 1,199 kertas dan 8,531 pasangan QA.
Statistik menunjukkan bahawa 99.15% daripada data dalam jawapan datang daripada kertas asal, 87.29% daripada soalan mempunyai persamaan di bawah 0.3, dan jawapan meliputi 78.26% daripada kandungan asal.
Set data ini digunakan secara meluas: set latihan boleh digunakan untuk memperhalusi LLM dan menyuntik pengetahuan saintifik ke dalamnya; set ujian boleh digunakan untuk menilai prestasi LLM pada tugas QA terbuka dalam bidang saintifik khusus atau keseluruhan . Memandangkan set ujian lebih besar, ia juga boleh digunakan sebagai data berkualiti tinggi untuk penalaan halus.
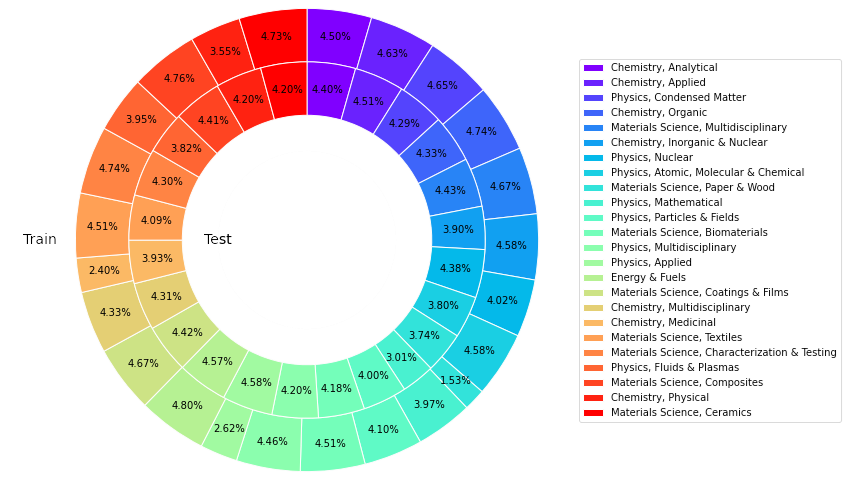
Ilustrasi: Perkadaran artikel dalam kategori berbeza dalam latihan dan ujian set data SciQAG-24D.
Hasil eksperimen
Para penyelidik menjalankan eksperimen komprehensif untuk membandingkan perbezaan prestasi dalam menjawab soalan saintifik antara model bahasa yang berbeza dan meneroka kesan penalaan halus.
Tetapan sifar tangkapan
Para penyelidik menggunakan sebahagian daripada set ujian dalam SciQAG-24D untuk menjalankan perbandingan prestasi sifar tangkapan bagi lima model. Dua daripadanya ialah LLM sumber terbuka: LLaMA1 (7B) dan LLaMA2-chat (7B), dan selebihnya ialah LLM sumber tertutup.
Dipanggil melalui API: GPT3.5 (gpt-3.5-turbo), GPT-4 (gpt-4-1106-pratonton) dan Claude 3 (claude-3-opus-20240229). Setiap model digesa dengan 1,000 soalan dalam ujian, dan outputnya dinilai oleh metrik CAR (diadaptasi daripada metrik RACAR, memfokuskan hanya pada penilaian tindak balas) untuk mengukur keupayaan sifar pukulan untuk menjawab soalan penyelidikan saintifik.
Seperti yang ditunjukkan dalam rajah, antara semua model, GPT-4 mempunyai skor tertinggi untuk kesempurnaan (4.90) dan kebolehpercayaan (4.99), manakala Claude 3 mempunyai skor ketepatan tertinggi (4.95). GPT-3.5 juga menunjukkan prestasi yang sangat baik, mendapat markah rapat di belakang GPT-4 dan Claude 3 pada semua metrik.
Terutama, LLaMA1 mempunyai markah terendah dalam ketiga-tiga dimensi. Sebaliknya, walaupun model sembang LLaMA2 tidak mendapat markah setinggi model GPT, ia bertambah baik dengan ketara berbanding LLaMA1 asal dalam semua metrik. Hasilnya menunjukkan prestasi unggul LLM komersial dalam menjawab soalan saintifik, manakala model sumber terbuka (seperti LLaMA2-chat) juga telah mencapai kemajuan yang ketara dalam hal ini.
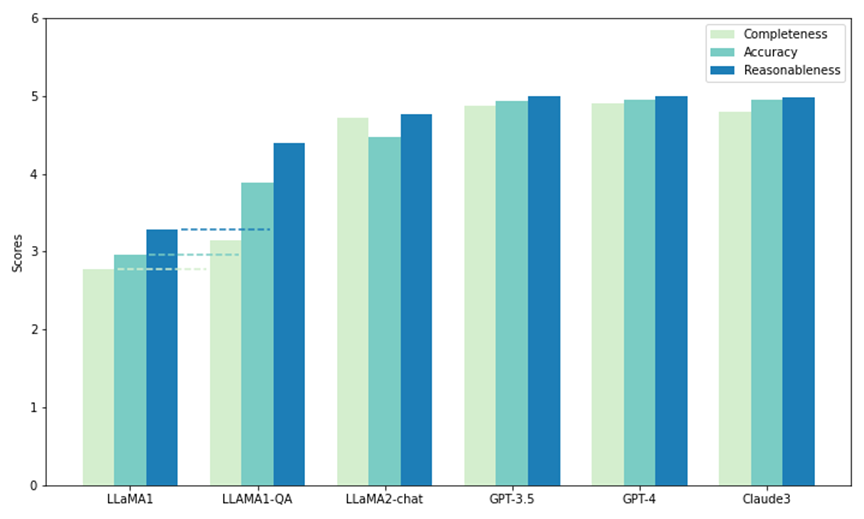
Ilustrasi: Ujian sampel sifar dan ujian penalaan halus (LLAMA1-QA) pada SciQAG-24D
tetapan penalaan halus (tetapan penalaan halus)
Para penyelidik sifar LworLast memilih prestasi sampel Penalaan halus dilakukan pada set latihan SciQAG-24D untuk mendapatkan LLaMA1-QA. Melalui tiga eksperimen, para penyelidik menunjukkan bahawa SciQAG-24D boleh digunakan sebagai data penalaan halus yang berkesan untuk meningkatkan prestasi tugas saintifik hiliran:
(a) LLaMA-QA berbanding LLaMA1 asal pada set ujian SciQAG-24D yang ghaib Prestasi perbandingan.
Seperti yang ditunjukkan dalam rajah di atas, prestasi LLaMA1-QA telah meningkat dengan ketara berbanding LLaMA1 asal (kesempurnaan meningkat sebanyak 13%, ketepatan dan kebolehpercayaan meningkat lebih daripada 30%). Ini menunjukkan bahawa LLaMA1 telah mempelajari logik menjawab soalan saintifik daripada data latihan SciQAG-24D dan menghayati beberapa pengetahuan saintifik.
(b) Perbandingan prestasi penalaan halus pada SciQ, penanda aras MCQ saintifik.
Barisan pertama jadual di bawah menunjukkan bahawa LLaMA1-QA lebih baik sedikit daripada LLaMA1 (+1%). Menurut pemerhatian, penalaan halus juga meningkatkan keupayaan arahan model berikut: kebarangkalian output tidak boleh dihuraikan menurun daripada 4.1% dalam LLaMA1 kepada 1.7% dalam LLaMA1-QA.
(c) Perbandingan prestasi penalaan halus pada pelbagai tugas saintifik.
Dari segi penunjuk penilaian, skor F1 digunakan untuk tugasan klasifikasi, MAE digunakan untuk tugasan regresi, dan perbezaan KL digunakan untuk tugas transformasi. Seperti yang ditunjukkan dalam jadual di bawah, LLaMA1-QA mempunyai peningkatan yang ketara berbanding model LLaMA1 dalam tugas saintifik.
Peningkatan yang paling jelas ditunjukkan dalam tugas regresi, di mana MAE turun daripada 463.96 kepada 185.32. Penemuan ini mencadangkan bahawa menggabungkan pasangan QA semasa latihan boleh meningkatkan keupayaan model untuk belajar dan menggunakan pengetahuan saintifik, dengan itu meningkatkan prestasinya dalam tugas ramalan hiliran.
Anehnya, berbanding model pembelajaran mesin yang direka khas dengan ciri, LLM boleh mencapai hasil yang setanding atau bahkan mengatasinya dalam beberapa tugas. Sebagai contoh, dalam tugas jurang jalur, walaupun LLaMA1-QA tidak berprestasi sebaik model seperti MODNet (0.3327), ia telah mengatasi AMMExpress v2020 (0.4161).
Dalam tugas kepelbagaian, LLaMA1-QA mengatasi garis dasar pembelajaran mendalam (0.3198). Penemuan ini menunjukkan bahawa LLM mempunyai potensi besar dalam tugas saintifik tertentu.
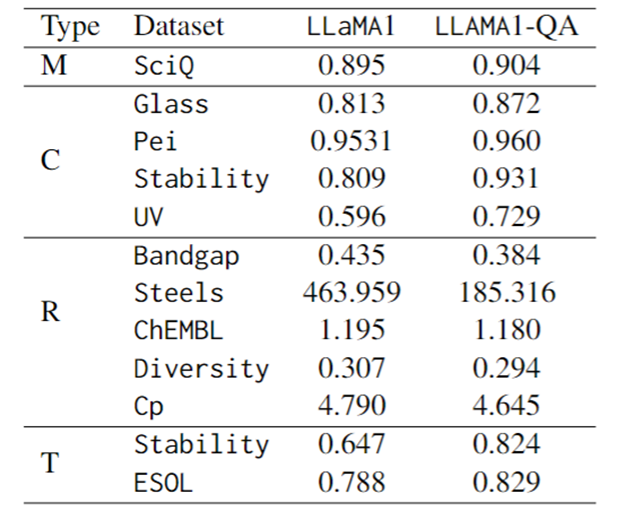
Ilustrasi: Prestasi penalaan halus LLaMA1 dan LLaMA1-QA pada SciQ dan tugasan saintifik (M mewakili pelbagai pilihan, C mewakili klasifikasi, R mewakili regresi, T mewakili transformasi)
Ringkasan dan Tinjauan 1) SciQAG ialah rangka kerja untuk menjana pasangan QA daripada kesusasteraan saintifik Digabungkan dengan metrik RACAR untuk menilai dan menapis pasangan QA, ia boleh menjana sejumlah besar data QA berasaskan pengetahuan untuk bidang saintifik yang miskin sumber.
(2) Pasukan ini menghasilkan set data QA saintifik sumber terbuka yang komprehensif yang mengandungi 188,042 pasangan QA, dipanggil SciQAG-24D. Set latihan digunakan untuk memperhalusi LLM, dan set ujian menilai prestasi LLM pada tugasan QA saintifik buku tertutup terbuka. Membandingkan prestasi sampel sifar beberapa LLM pada set ujian SciQAG-24D dan LLaMA1 yang diperhalusi pada set latihan SciQAG-24D untuk mendapatkan LLaMA1-QA. Penalaan halus ini meningkatkan prestasinya dengan ketara pada pelbagai tugas saintifik. (3) Penyelidikan menunjukkan bahawa LLM mempunyai potensi dalam tugas saintifik, dan keputusan LLaMA1-QA boleh mencapai tahap walaupun melebihi garis dasar pembelajaran mesin. Ini menunjukkan utiliti pelbagai rupa SciQAG-24D dan menunjukkan bahawa memasukkan data QA saintifik ke dalam proses latihan boleh meningkatkan keupayaan LLM untuk mempelajari dan menggunakan pengetahuan saintifik.Atas ialah kandungan terperinci Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.


Stock Market GPT
Penyelidikan pelaburan dikuasakan AI untuk keputusan yang lebih bijak

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1651
1651
 276
276

 Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Menerobos sempadan pengesanan kecacatan tradisional, 'Spektrum Kecacatan' mencapai ketepatan ultra tinggi dan pengesanan kecacatan industri semantik yang kaya buat kali pertama.
Jul 26, 2024 pm 05:38 PM
Dalam pembuatan moden, pengesanan kecacatan yang tepat bukan sahaja kunci untuk memastikan kualiti produk, tetapi juga teras untuk meningkatkan kecekapan pengeluaran. Walau bagaimanapun, set data pengesanan kecacatan sedia ada selalunya tidak mempunyai ketepatan dan kekayaan semantik yang diperlukan untuk aplikasi praktikal, menyebabkan model tidak dapat mengenal pasti kategori atau lokasi kecacatan tertentu. Untuk menyelesaikan masalah ini, pasukan penyelidik terkemuka yang terdiri daripada Universiti Sains dan Teknologi Hong Kong Guangzhou dan Teknologi Simou telah membangunkan set data "DefectSpectrum" secara inovatif, yang menyediakan anotasi berskala besar yang kaya dengan semantik bagi kecacatan industri. Seperti yang ditunjukkan dalam Jadual 1, berbanding set data industri lain, set data "DefectSpectrum" menyediakan anotasi kecacatan yang paling banyak (5438 sampel kecacatan) dan klasifikasi kecacatan yang paling terperinci (125 kategori kecacatan
 Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Latihan dengan berjuta-juta data kristal untuk menyelesaikan masalah fasa kristalografi, kaedah pembelajaran mendalam PhAI diterbitkan dalam Sains
Aug 08, 2024 pm 09:22 PM
Editor |KX Sehingga hari ini, perincian dan ketepatan struktur yang ditentukan oleh kristalografi, daripada logam ringkas kepada protein membran yang besar, tidak dapat ditandingi oleh mana-mana kaedah lain. Walau bagaimanapun, cabaran terbesar, yang dipanggil masalah fasa, kekal mendapatkan maklumat fasa daripada amplitud yang ditentukan secara eksperimen. Penyelidik di Universiti Copenhagen di Denmark telah membangunkan kaedah pembelajaran mendalam yang dipanggil PhAI untuk menyelesaikan masalah fasa kristal Rangkaian saraf pembelajaran mendalam yang dilatih menggunakan berjuta-juta struktur kristal tiruan dan data pembelauan sintetik yang sepadan boleh menghasilkan peta ketumpatan elektron yang tepat. Kajian menunjukkan bahawa kaedah penyelesaian struktur ab initio berasaskan pembelajaran mendalam ini boleh menyelesaikan masalah fasa pada resolusi hanya 2 Angstrom, yang bersamaan dengan hanya 10% hingga 20% daripada data yang tersedia pada resolusi atom, manakala Pengiraan ab initio tradisional
 SK Hynix akan memaparkan produk berkaitan AI baharu pada 6 Ogos: HBM3E 12 lapisan, NAND 321 tinggi, dsb.
Aug 01, 2024 pm 09:40 PM
SK Hynix akan memaparkan produk berkaitan AI baharu pada 6 Ogos: HBM3E 12 lapisan, NAND 321 tinggi, dsb.
Aug 01, 2024 pm 09:40 PM
Menurut berita dari laman web ini pada 1 Ogos, SK Hynix mengeluarkan catatan blog hari ini (1 Ogos), mengumumkan bahawa ia akan menghadiri Global Semiconductor Memory Summit FMS2024 yang akan diadakan di Santa Clara, California, Amerika Syarikat dari 6 hingga 8 Ogos, mempamerkan banyak produk penjanaan teknologi baru. Pengenalan kepada Sidang Kemuncak Memori dan Penyimpanan Masa Depan (FutureMemoryandStorage), dahulunya Sidang Kemuncak Memori Flash (FlashMemorySummit) terutamanya untuk pembekal NAND, dalam konteks peningkatan perhatian kepada teknologi kecerdasan buatan, tahun ini dinamakan semula sebagai Sidang Kemuncak Memori dan Penyimpanan Masa Depan (FutureMemoryandStorage) kepada jemput vendor DRAM dan storan serta ramai lagi pemain. Produk baharu SK hynix dilancarkan tahun lepas
 PRO |. Mengapa model besar berdasarkan MoE lebih patut diberi perhatian?
Aug 07, 2024 pm 07:08 PM
PRO |. Mengapa model besar berdasarkan MoE lebih patut diberi perhatian?
Aug 07, 2024 pm 07:08 PM
Pada tahun 2023, hampir setiap bidang AI berkembang pada kelajuan yang tidak pernah berlaku sebelum ini. Pada masa yang sama, AI sentiasa menolak sempadan teknologi trek utama seperti kecerdasan yang terkandung dan pemanduan autonomi. Di bawah trend berbilang modal, adakah status Transformer sebagai seni bina arus perdana model besar AI akan digoncang? Mengapakah penerokaan model besar berdasarkan seni bina MoE (Campuran Pakar) menjadi trend baharu dalam industri? Bolehkah Model Penglihatan Besar (LVM) menjadi satu kejayaan baharu dalam penglihatan umum? ...Daripada surat berita ahli PRO 2023 laman web ini yang dikeluarkan dalam tempoh enam bulan lalu, kami telah memilih 10 tafsiran khas yang menyediakan analisis mendalam tentang aliran teknologi dan perubahan industri dalam bidang di atas untuk membantu anda mencapai matlamat anda dalam bidang baharu. tahun. Tafsiran ini datang dari Week50 2023
 Kadar ketepatan mencapai 60.8%. Model ramalan retrosintesis kimia Universiti Zhejiang berdasarkan Transformer diterbitkan dalam sub-jurnal Nature
Aug 06, 2024 pm 07:34 PM
Kadar ketepatan mencapai 60.8%. Model ramalan retrosintesis kimia Universiti Zhejiang berdasarkan Transformer diterbitkan dalam sub-jurnal Nature
Aug 06, 2024 pm 07:34 PM
Editor |. KX Retrosynthesis ialah tugas kritikal dalam penemuan ubat dan sintesis organik, dan AI semakin digunakan untuk mempercepatkan proses. Kaedah AI sedia ada mempunyai prestasi yang tidak memuaskan dan kepelbagaian terhad. Dalam amalan, tindak balas kimia sering menyebabkan perubahan molekul tempatan, dengan pertindihan yang besar antara bahan tindak balas dan produk. Diilhamkan oleh ini, pasukan Hou Tingjun di Universiti Zhejiang mencadangkan untuk mentakrifkan semula ramalan retrosintetik satu langkah sebagai tugas penyuntingan rentetan molekul, secara berulang menapis rentetan molekul sasaran untuk menghasilkan sebatian prekursor. Dan model retrosintetik berasaskan penyuntingan EditRetro dicadangkan, yang boleh mencapai ramalan berkualiti tinggi dan pelbagai. Eksperimen yang meluas menunjukkan bahawa model itu mencapai prestasi cemerlang pada set data penanda aras standard USPTO-50 K, dengan ketepatan 1 teratas 60.8%.
 Iyo One: Bahagian fon kepala, sebahagian komputer audio
Aug 08, 2024 am 01:03 AM
Iyo One: Bahagian fon kepala, sebahagian komputer audio
Aug 08, 2024 am 01:03 AM
Pada bila-bila masa, tumpuan adalah satu kebaikan. Pengarang |. Editor Tang Yitao |. AIPin yang paling popular telah menemui ulasan negatif yang belum pernah terjadi sebelumnya. Marques Brownlee (MKBHD) menyifatkannya sebagai produk terburuk yang pernah dia semak; Editor The Verge, David Pierce berkata dia tidak akan mengesyorkan sesiapa pun membeli peranti ini. Pesaingnya, RabbitR1, tidak jauh lebih baik. Keraguan terbesar tentang peranti AI ini ialah ia jelas hanya sebuah aplikasi, tetapi Arnab telah membina perkakasan bernilai $200. Ramai orang melihat inovasi perkakasan AI sebagai peluang untuk menumbangkan era telefon pintar dan menumpukan diri mereka kepadanya.
 Persaingan tersembunyi versi biologi DeepSeek, model Cina dianggap sebagai lawan yang lebih kuat, dan Sanofi bertaruh pada $ 1 bilion!
Mar 12, 2025 pm 01:18 PM
Persaingan tersembunyi versi biologi DeepSeek, model Cina dianggap sebagai lawan yang lebih kuat, dan Sanofi bertaruh pada $ 1 bilion!
Mar 12, 2025 pm 01:18 PM
Kuasa AI China mengetuai dunia: Model bioteknov3 Biotech Xtrimov3 melampaui Evo2 model Biologi AI Evo2 yang dikeluarkan oleh Stanford University dan Nvidia telah menyebabkan perbincangan yang dipanaskan. Baite Biotech, sebuah syarikat yang dianggap sebagai perintis dalam model asas sains hayat oleh pasaran AS, terus memperdalam usahanya dalam bidang ini sejak tahun 2020. Pada bulan Oktober 2024, model biologi penuh modal XTRIMOV3 dilancarkan, yang menetapkan rekod baru untuk model AI Sains Kehidupan Asas terbesar di dunia dengan 210 bilion parameter. Terobosan Xtrimov3 terletak pada yang pertama
 perkakasan AI menambah ahli lain! Daripada menggantikan telefon bimbit, bolehkah NotePin hidup lebih lama?
Sep 02, 2024 pm 01:40 PM
perkakasan AI menambah ahli lain! Daripada menggantikan telefon bimbit, bolehkah NotePin hidup lebih lama?
Sep 02, 2024 pm 01:40 PM
Setakat ini, tiada produk dalam trek peranti boleh pakai AI telah mencapai hasil yang sangat baik. AIPin, yang dilancarkan di MWC24 pada awal tahun ini, sebaik sahaja prototaip penilaian dihantar, "mitos AI" yang digembar-gemburkan pada masa pelancarannya mula berkecai, dan ia mengalami pulangan berskala besar dalam hanya satu beberapa bulan; RabbitR1, yang juga terjual dengan baik pada mulanya, agak Lebih baik, tetapi ia juga menerima ulasan negatif serupa dengan "kes Android" apabila ia dihantar dalam kuantiti yang banyak. Kini, syarikat lain telah memasuki trek peranti boleh pakai AI. Media teknologi TheVerge menerbitkan catatan blog semalam mengatakan bahawa permulaan AI Plaud telah melancarkan produk yang dipanggil NotePin. Berbeza dengan AIFriend yang masih dalam peringkat "melukis", NotePin kini telah bermula
