


k-Nearest Neighbors (k-NN) ialah kaedah bukan parametrik yang meramalkan nilai output berdasarkan purata (atau purata wajaran) bagi titik data latihan k-hampir dalam ruang ciri. Pendekatan ini boleh memodelkan hubungan kompleks dalam data dengan berkesan tanpa menganggap bentuk fungsi tertentu.
Kaedah regresi k-NN boleh diringkaskan seperti berikut:
Bukan Parametrik: Tidak seperti model parametrik, k-NN tidak mengambil bentuk khusus untuk hubungan asas antara ciri input dan pembolehubah sasaran. Ini menjadikannya fleksibel dalam menangkap corak yang kompleks.
Pengiraan Jarak: Pilihan metrik jarak boleh menjejaskan prestasi model dengan ketara. Metrik biasa termasuk jarak Euclidean, Manhattan dan Minkowski.
Pilihan k: Bilangan jiran (k) boleh dipilih berdasarkan pengesahan silang. K yang kecil boleh membawa kepada pemasangan berlebihan, manakala k yang besar boleh melancarkan ramalan terlalu banyak, yang berpotensi tidak sesuai.
Contoh ini menunjukkan cara menggunakan regresi k-NN dengan ciri polinomial untuk memodelkan perhubungan yang kompleks sambil memanfaatkan sifat bukan parametrik k-NN.
1. Import Perpustakaan
import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.preprocessing import PolynomialFeatures from sklearn.neighbors import KNeighborsRegressor from sklearn.metrics import mean_squared_error, r2_score
Blok ini mengimport pustaka yang diperlukan untuk manipulasi data, plot dan pembelajaran mesin.
2. Jana Data Contoh
np.random.seed(42) # For reproducibility X = np.linspace(0, 10, 100).reshape(-1, 1) y = 3 * X.ravel() + np.sin(2 * X.ravel()) * 5 + np.random.normal(0, 1, 100)
Blok ini menjana data sampel yang mewakili perhubungan dengan beberapa bunyi, mensimulasikan variasi data dunia sebenar.
3. Pisahkan Set Data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Blok ini membahagikan set data kepada set latihan dan ujian untuk penilaian model.
4. Cipta Ciri Polinomial
degree = 3 # Change this value for different polynomial degrees poly = PolynomialFeatures(degree=degree) X_poly_train = poly.fit_transform(X_train) X_poly_test = poly.transform(X_test)
Blok ini menjana ciri polinomial daripada set data latihan dan ujian, membolehkan model menangkap perhubungan bukan linear.
5. Cipta dan Latih Model Regresi k-NN
k = 5 # Number of neighbors knn_model = KNeighborsRegressor(n_neighbors=k) knn_model.fit(X_poly_train, y_train)
Blok ini memulakan model regresi k-NN dan melatihnya menggunakan ciri polinomial yang diperoleh daripada set data latihan.
6. Buat Ramalan
y_pred = knn_model.predict(X_poly_test)
Blok ini menggunakan model terlatih untuk membuat ramalan pada set ujian.
7. Plot Keputusan
plt.figure(figsize=(10, 6))
plt.scatter(X, y, color='blue', alpha=0.5, label='Data Points')
X_grid = np.linspace(0, 10, 1000).reshape(-1, 1)
X_poly_grid = poly.transform(X_grid)
y_grid = knn_model.predict(X_poly_grid)
plt.plot(X_grid, y_grid, color='red', linewidth=2, label=f'k-NN Regression (k={k}, Degree {degree})')
plt.title(f'k-NN Regression (Polynomial Degree {degree})')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True)
plt.show()
Blok ini mencipta plot taburan titik data sebenar berbanding nilai ramalan daripada model regresi k-NN, menggambarkan lengkung yang dipasang.
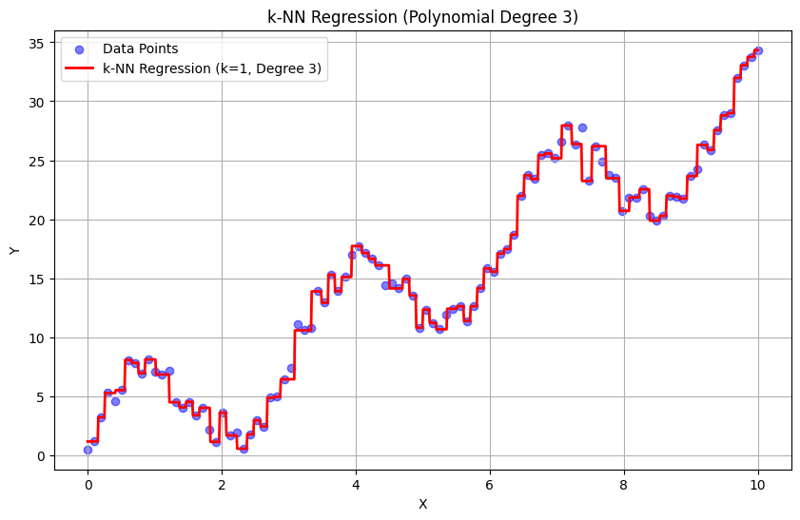
Output dengan k = 1:
Output dengan k = 10:
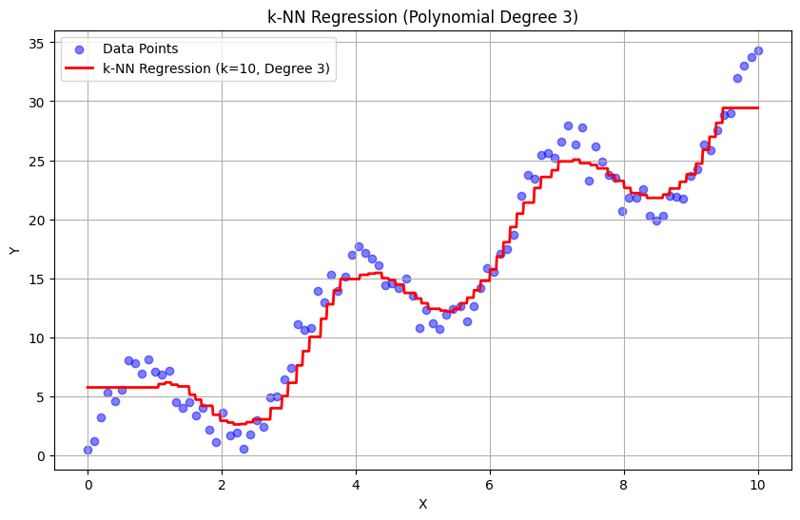
Pendekatan berstruktur ini menunjukkan cara melaksanakan dan menilai regresi k-Nearest Neighbors dengan ciri polinomial. Dengan menangkap corak tempatan melalui purata tindak balas jiran berdekatan, regresi k-NN secara berkesan memodelkan hubungan kompleks dalam data sambil menyediakan pelaksanaan yang mudah. Pilihan darjah k dan polinomial mempengaruhi prestasi dan fleksibiliti model dengan ketara dalam menangkap trend asas.
Atas ialah kandungan terperinci K Regresi Jiran Terdekat, Regresi: Pembelajaran Mesin Terselia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 IIS penyelesaian ralat tidak dijangka 0x8ffe2740
IIS penyelesaian ralat tidak dijangka 0x8ffe2740
 format flac
format flac
 Apakah platform e-dagang?
Apakah platform e-dagang?
 Perbezaan antara ++a dan a++ dalam bahasa c
Perbezaan antara ++a dan a++ dalam bahasa c
 Di manakah saya harus mengisi tempat lahir saya: wilayah, bandar atau daerah?
Di manakah saya harus mengisi tempat lahir saya: wilayah, bandar atau daerah?
 Apakah perbezaan antara 5g dan 4g
Apakah perbezaan antara 5g dan 4g
 Bagaimana untuk menggunakan carian magnetik btbook
Bagaimana untuk menggunakan carian magnetik btbook
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran laluan dalam java
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran laluan dalam java








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



