Lajur AIxiv ialah lajur di mana kandungan akademik dan teknikal diterbitkan di laman web ini. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Artikel ini telah disempurnakan oleh HMI Lab. HMI LabBergantung pada dua platform utama Pusat Penyelidikan Kejuruteraan Kebangsaan bagi Teknologi Video dan Visual Universiti Peking dan Makmal Utama Kebangsaan Pemprosesan Maklumat Multimedia, ia telah lama terlibat dalam penyelidikan ke arah pembelajaran mesin, pembelajaran pelbagai mod dan kecerdasan yang terkandung. Pengarang pertama karya ini ialah Dr. Liu Jiaming, yang hala tuju penyelidikannya ialah model besar yang merangkumi pelbagai mod dan teknologi pembelajaran berterusan untuk dunia terbuka. Pengarang kedua karya ini ialah Liu Mengzhen, yang hala tuju penyelidikannya ialah model asas penglihatan dan manipulasi robot. Pengajarnya ialah Chen Shanghang, seorang penyelidik di Pusat Pengajian Sains Komputer di Universiti Peking, seorang penyelia kedoktoran, dan seorang sarjana muda liberal. Terlibat dalam penyelidikan tentang model besar berbilang modal dan kecerdasan yang terkandung, beliau telah mencapai satu siri hasil penyelidikan yang penting. Beliau telah menerbitkan lebih daripada 80 kertas kerja dalam jurnal dan persidangan kecerdasan buatan teratas, dan telah dipetik oleh Google lebih daripada 9,700 kali. Memenangi Anugerah Kertas Terbaik daripada AAAI, persidangan kecerdasan buatan terbaik dunia, dan menduduki tempat pertama dalam Trending Research, repositori kod sumber akademik terbesar di dunia. Untuk memberikan robot keupayaan penaakulan dan manipulasi hujung ke hujung, artikel ini secara inovatif menyepadukan pengekod visual dengan model bahasa ruang keadaan yang cekap untuk membina model besar berbilang mod RoboMamba baharu, menjadikannya mampu visual biasa tugas rasa dan keupayaan penaakulan robot pada tugas yang berkaitan, dan telah mencapai prestasi lanjutan. Pada masa yang sama, artikel ini mendapati bahawa apabila RoboMamba mempunyai keupayaan penaakulan yang kukuh, kami boleh membolehkan RoboMamba menguasai pelbagai keupayaan ramalan postur manipulasi melalui kos latihan yang sangat rendah.


Rajah 1. Keupayaan Robo yang berkaitan dengan tugasan , perancangan misi segera, perancangan misi jarak jauh, pertimbangan kebolehgerakan, penjanaan kebolehgerakan, ramalan masa depan dan masa lalu, ramalan pose effector akhir, dsb. Abstrak
Matlamat asas manipulasi robot adalah untuk membolehkan model memahami pemandangan visual dan melakukan tindakan. Walaupun model besar multimodal robot (MLLM) sedia ada boleh mengendalikan satu siri tugasan asas, mereka masih menghadapi cabaran dalam dua aspek: 1) Keupayaan penaakulan yang tidak mencukupi untuk mengendalikan tugas yang kompleks; tinggi. Model ruang negeri (SSM) yang dicadangkan baru-baru ini, iaitu Mamba, mempunyai kerumitan inferens linear sambil menunjukkan keupayaan yang menjanjikan dalam pemodelan jujukan. Diilhamkan oleh ini, kami melancarkan robot hujung ke hujung MLLM—RoboMamba, yang menggunakan model Mamba untuk menyediakan penaakulan robot dan keupayaan tindakan sambil mengekalkan keupayaan penalaan halus dan penaakulan yang cekap.
Secara khusus, kami mula-mula menyepadukan pengekod visual dengan Mamba untuk menyelaraskan data visual dengan pembenaman bahasa melalui latihan bersama, memberikan model kami akal sehat visual dan keupayaan penaakulan berkaitan robot. Untuk mempertingkatkan lagi keupayaan ramalan pose manipulasi RoboMamba, kami meneroka strategi penalaan halus yang cekap hanya menggunakan Ketua Dasar yang ringkas. Kami mendapati bahawa sebaik sahaja RoboMamba mempunyai keupayaan penaakulan yang mencukupi, ia boleh menguasai pelbagai kemahiran operasi dengan parameter penalaan halus yang sangat sedikit (0.1% daripada model) dan masa penalaan halus (20 minit). Dalam eksperimen, RoboMamba menunjukkan keupayaan penaakulan yang sangat baik pada tanda aras penilaian umum dan robotik, seperti yang ditunjukkan dalam Rajah 2. Pada masa yang sama, model kami menunjukkan keupayaan ramalan pose manipulasi yang mengagumkan dalam simulasi dan eksperimen dunia sebenar, dengan kelajuan inferens sehingga 7 kali lebih pantas daripada MLLM robotik sedia ada. 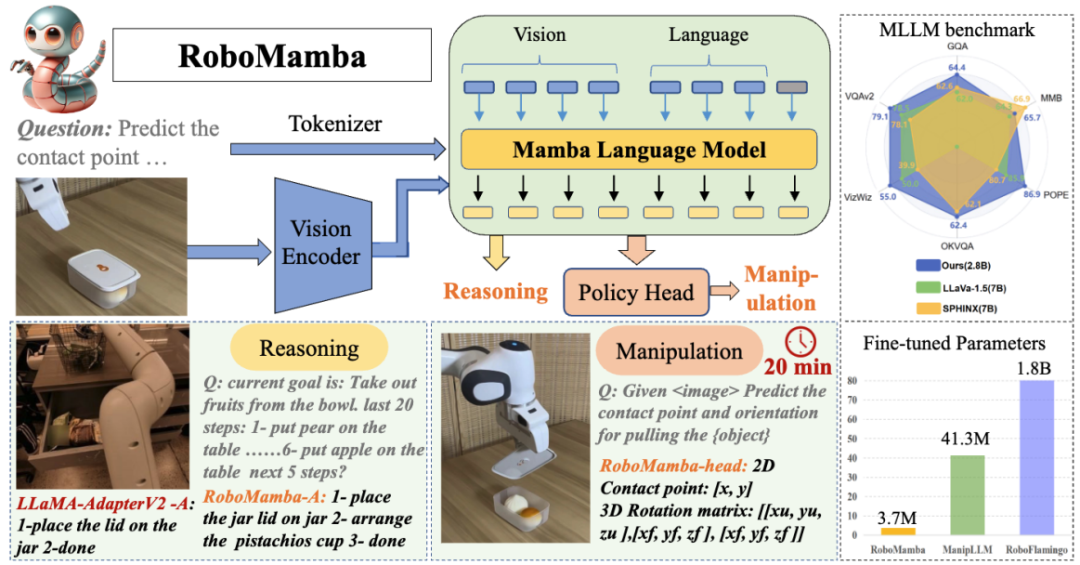
🎜🎜
Rajah 2. Gambaran Keseluruhan: Robomamba ialah model robot besar berbilang mod yang cekap dengan keupayaan penaakulan dan operasi yang kuat. RoboMamba-2.8B mencapai prestasi inferens kompetitif dengan MLLM 7B lain pada penanda aras MLLM tujuan umum sambil menunjukkan keupayaan inferens jarak jauh dalam tugas robotik. Selepas itu, kami memperkenalkan strategi penalaan halus yang sangat cekap untuk memberikan RoboMamba keupayaan untuk meramalkan pose manipulasi, dan hanya mengambil masa 20 minit untuk memperhalusi kepala strategi yang mudah. Sumbangan utama artikel ini diringkaskan seperti berikut:
- Kami secara inovatif menyepadukan pengekod visual dengan model bahasa Mamba-ke hujung besar yang cekap untuk membina satu hujung baharu yang cekap. model robot, RoboMamba , yang mempunyai akal sehat visual dan keupayaan penaakulan komprehensif yang berkaitan dengan robot.
- Untuk melengkapkan RoboMamba dengan keupayaan ramalan pose manipulasi kesan akhir, kami meneroka strategi penalaan halus yang cekap menggunakan Ketua Polisi yang ringkas. Kami mendapati bahawa sebaik sahaja RoboMamba mencapai keupayaan penaakulan yang mencukupi, ia boleh menguasai kemahiran ramalan pose manipulasi pada kos yang sangat rendah.
- Dalam eksperimen kami yang meluas, RoboMamba berprestasi baik pada tanda aras penilaian inferens am dan robotik, dan menunjukkan hasil ramalan pose yang mengagumkan dalam simulator dan eksperimen dunia sebenar. . Untuk memahami maklumat multimodal, model bahasa besar multimodal (MLLM) muncul, memberikan LLM keupayaan untuk mengikuti arahan visual dan memahami adegan. Diilhamkan oleh keupayaan berkuasa MLLM dalam persekitaran tujuan umum, penyelidikan terkini bertujuan untuk menggunakan MLLM dalam bidang pengendalian robot. Beberapa usaha penyelidikan membolehkan robot memahami bahasa semula jadi dan pemandangan visual dan menjana pelan misi secara automatik. Kerja-kerja penyelidikan lain mengeksploitasi keupayaan sedia ada MLLM untuk membolehkan mereka meramalkan pose operasi.
Operasi robot melibatkan interaksi dengan objek dalam persekitaran dinamik, memerlukan keupayaan penaakulan seperti manusia untuk memahami maklumat semantik tempat kejadian, serta keupayaan ramalan pose manipulasi yang berkuasa. Walaupun MLLM berasaskan robot sedia ada boleh mengendalikan pelbagai tugas asas, mereka masih menghadapi cabaran dalam dua aspek. 1) Pertama, keupayaan penaakulan MLLM pra-latihan dalam senario robotik didapati tidak mencukupi. Seperti yang ditunjukkan dalam Rajah 2
, kelemahan ini mewujudkan cabaran apabila MLLM robotik yang diperhalusi menghadapi tugas penaakulan yang kompleks. 2) Kedua, disebabkan kerumitan pengiraan yang tinggi bagi mekanisme perhatian MLLM sedia ada, penalaan halus MLLM dan menggunakannya untuk menjana tindakan pengendalian robot akan menanggung kos pengiraan yang lebih tinggi. Untuk mengimbangi keupayaan dan kecekapan penaakulan, beberapa kajian telah muncul dalam bidang NLP. Khususnya, Mamba memperkenalkan Model Ruang Negeri Terpilih (SSM) yang inovatif, yang memudahkan penaakulan sedar konteks sambil mengekalkan kerumitan linear. Diinspirasikan oleh ini, kami bertanya soalan: "Bolehkah kami membangunkan MLLM robotik yang cekap yang bukan sahaja mempunyai keupayaan penaakulan yang kukuh, tetapi juga memperoleh kemahiran operasi robotik dengan cara yang sangat menjimatkan?" kaedah
1. Pengetahuan latar belakangPernyataan masalah
berdasarkan bahasa robot
untuk soalan bahasa dan penaakulan visual kami Jawapannya ialah
, dinyatakan sebagai .Jawapan penaakulan selalunya mengandungi subtugasan yang berasingan  untuk soalan
untuk soalan  . Sebagai contoh, apabila berhadapan dengan masalah perancangan seperti "Bagaimana untuk mengosongkan jadual jawapan biasanya termasuk langkah-langkah seperti "Langkah 1: Angkat objek" dan "Langkah 2: Letakkan objek ke dalam kotak." Untuk ramalan tindakan, kami menggunakan kepala dasar yang cekap dan mudah π untuk meramalkan tindakan
. Sebagai contoh, apabila berhadapan dengan masalah perancangan seperti "Bagaimana untuk mengosongkan jadual jawapan biasanya termasuk langkah-langkah seperti "Langkah 1: Angkat objek" dan "Langkah 2: Letakkan objek ke dalam kotak." Untuk ramalan tindakan, kami menggunakan kepala dasar yang cekap dan mudah π untuk meramalkan tindakan  . Berikutan kerja sebelumnya, kami menggunakan 6-DoF untuk menyatakan pose efek akhir lengan robotik Franka Emika Panda. 6 darjah kebebasan termasuk kedudukan pengesan akhir
. Berikutan kerja sebelumnya, kami menggunakan 6-DoF untuk menyatakan pose efek akhir lengan robotik Franka Emika Panda. 6 darjah kebebasan termasuk kedudukan pengesan akhir 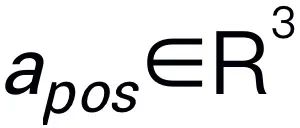 mewakili koordinat tiga dimensi dan arah
mewakili koordinat tiga dimensi dan arah  mewakili matriks putaran. Jika berlatih tentang tugas menggenggam, kami menambah keadaan penggenggam pada ramalan pose, membolehkan kawalan 7-DoF.
mewakili matriks putaran. Jika berlatih tentang tugas menggenggam, kami menambah keadaan penggenggam pada ramalan pose, membolehkan kawalan 7-DoF. - Model Angkasa Negeri (SSM)
Artikel ini memilih Mamba sebagai model bahasa besar. Mamba terdiri daripada banyak blok Mamba, komponen yang paling kritikal ialah SSM. SSM direka bentuk berdasarkan sistem berterusan yang menayangkan jujukan input 1D 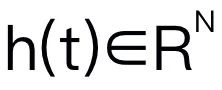 kepada jujukan output 1D
kepada jujukan output 1D 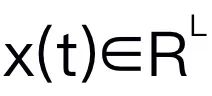 melalui keadaan tersembunyi
melalui keadaan tersembunyi  . SSM terdiri daripada tiga parameter utama: matriks keadaan
. SSM terdiri daripada tiga parameter utama: matriks keadaan  , matriks input
, matriks input  dan matriks output
dan matriks output  . SSM boleh dinyatakan sebagai:
. SSM boleh dinyatakan sebagai: 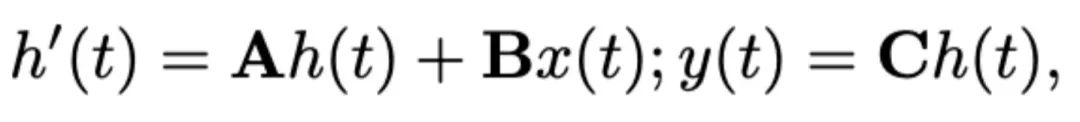
SSM terkini (cth., Mamba) dibina sebagai sistem berterusan diskret menggunakan parameter skala masa Δ. Parameter ini menukar parameter berterusan A dan B kepada parameter diskret  dan
dan  . Diskretisasi menggunakan kaedah pemeliharaan tertib sifar, yang ditakrifkan seperti berikut:
. Diskretisasi menggunakan kaedah pemeliharaan tertib sifar, yang ditakrifkan seperti berikut: 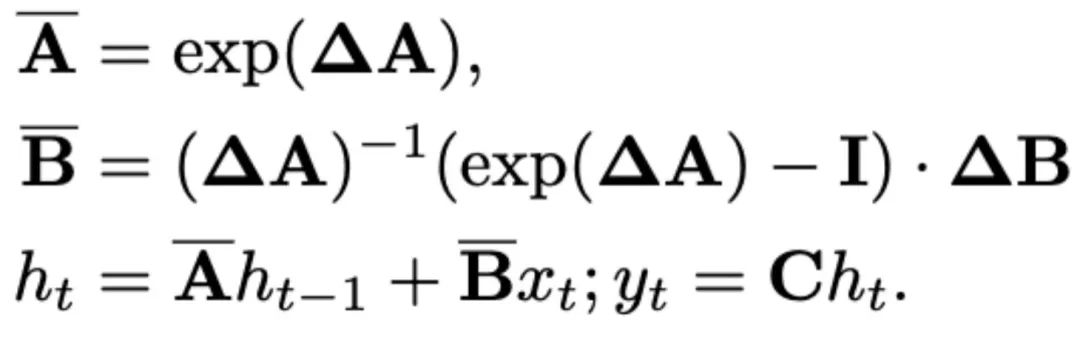
Mamba memperkenalkan mekanisme imbasan terpilih (S6) untuk membentuk operasi SSMnya di setiap blok Mamba. Parameter SSM dikemas kini kepada 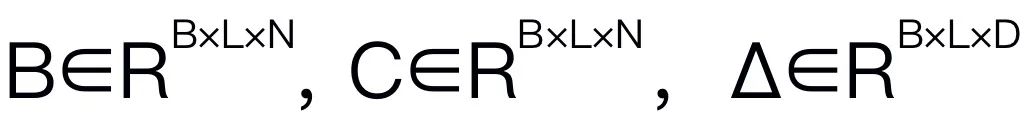 untuk inferens sedar kandungan yang lebih baik. Butiran blok Mamba ditunjukkan dalam Rajah 3 di bawah. 2. Struktur model RoboMamba
untuk inferens sedar kandungan yang lebih baik. Butiran blok Mamba ditunjukkan dalam Rajah 3 di bawah. 2. Struktur model RoboMamba 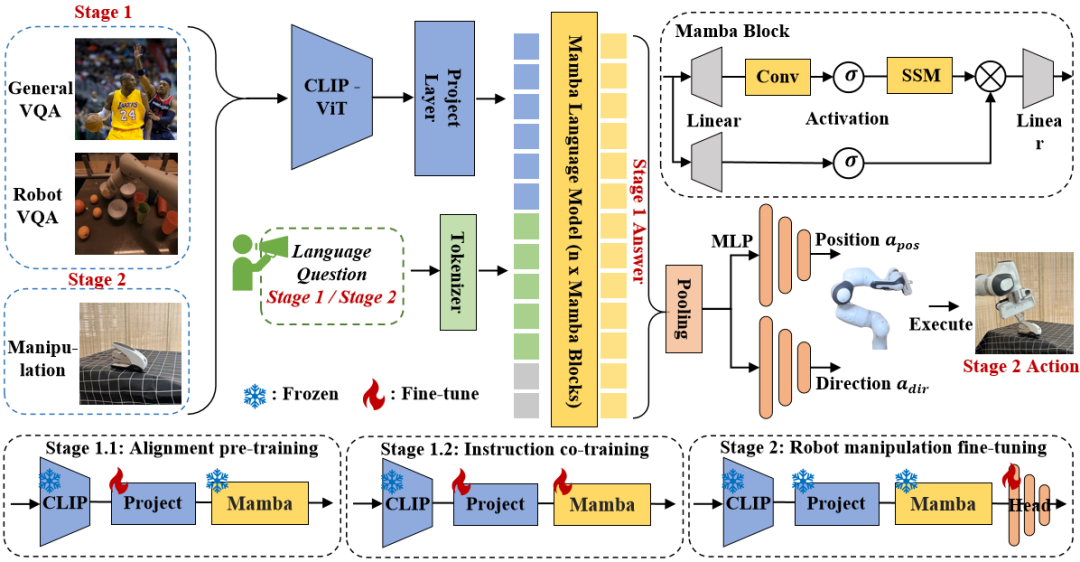
Rajah 3. Kerangka keseluruhan Robomamba. RoboMamba menayangkan imej ke dalam ruang benam bahasa Mamba melalui pengekod visual dan lapisan unjuran, yang kemudiannya digabungkan dengan token teks dan dimasukkan ke dalam model Mamba. Untuk meramalkan kedudukan dan orientasi pengesan akhir, kami memperkenalkan ketua dasar MLP yang mudah dan menggunakan operasi pengumpulan untuk menjana token global daripada token output bahasa sebagai input. Strategi latihan RoboMamba. Untuk latihan model, kami membahagikan proses latihan kepada dua peringkat. Dalam Peringkat 1, kami memperkenalkan pra-latihan sejajar (Tahap 1.1) dan latihan bersama arahan (Tahap 1.2) untuk melengkapkan RoboMamba dengan penaakulan akal dan keupayaan penaakulan berkaitan robot. Pada Peringkat 2, kami mencadangkan penalaan halus operasi robot untuk memperkasakan RoboMamba dengan kemahiran operasi Tahap Rendah dengan cekap. Untuk melengkapkan RoboMamba dengan penaakulan visual dan keupayaan operasi, kami membina seni bina MLLM yang cekap bermula daripada model bahasa besar (LLM) yang telah dilatih dan model penglihatan. Seperti yang ditunjukkan dalam Rajah 3 di atas, kami menggunakan pengekod visual CLIP untuk mengekstrak ciri visual 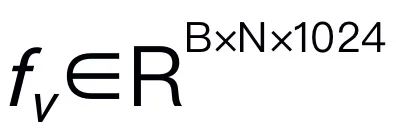 daripada imej input I, di mana B dan N mewakili saiz kelompok dan bilangan token masing-masing. Tidak seperti MLLM baru-baru ini, kami tidak menggunakan teknik ensembel pengekod visual, yang menggunakan pelbagai rangkaian tulang belakang (iaitu, DINOv2, CLIP-ConvNeXt, CLIP-ViT) untuk pengekstrakan ciri imej. Penyepaduan memperkenalkan kos pengiraan tambahan, yang menjejaskan kepraktisan robotik MLLM dalam dunia sebenar. Oleh itu, kami menunjukkan bahawa reka bentuk model yang ringkas dan mudah juga boleh mencapai keupayaan inferens yang berkuasa apabila data berkualiti tinggi dan strategi latihan yang sesuai digabungkan. Untuk menjadikan LLM memahami ciri visual, kami menggunakan perceptron berbilang lapisan (MLP) untuk menyambungkan pengekod visual kepada LLM. Dengan penyambung rentas mod yang ringkas ini, RoboMamba boleh mengubah maklumat visual menjadi ruang pembenaman bahasa
daripada imej input I, di mana B dan N mewakili saiz kelompok dan bilangan token masing-masing. Tidak seperti MLLM baru-baru ini, kami tidak menggunakan teknik ensembel pengekod visual, yang menggunakan pelbagai rangkaian tulang belakang (iaitu, DINOv2, CLIP-ConvNeXt, CLIP-ViT) untuk pengekstrakan ciri imej. Penyepaduan memperkenalkan kos pengiraan tambahan, yang menjejaskan kepraktisan robotik MLLM dalam dunia sebenar. Oleh itu, kami menunjukkan bahawa reka bentuk model yang ringkas dan mudah juga boleh mencapai keupayaan inferens yang berkuasa apabila data berkualiti tinggi dan strategi latihan yang sesuai digabungkan. Untuk menjadikan LLM memahami ciri visual, kami menggunakan perceptron berbilang lapisan (MLP) untuk menyambungkan pengekod visual kepada LLM. Dengan penyambung rentas mod yang ringkas ini, RoboMamba boleh mengubah maklumat visual menjadi ruang pembenaman bahasa 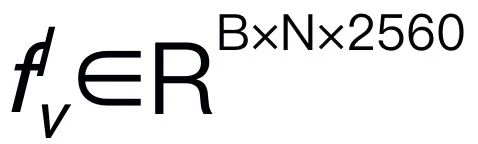 . Sila ambil perhatian bahawa kecekapan model adalah penting dalam bidang robotik, kerana robot perlu bertindak balas dengan cepat kepada arahan manusia. Oleh itu, kami memilih Mamba sebagai model bahasa besar kami kerana keupayaan penaakulan yang sedar konteks dan kerumitan pengiraan linear. Gesaan teks dikodkan ke dalam ruang benam
. Sila ambil perhatian bahawa kecekapan model adalah penting dalam bidang robotik, kerana robot perlu bertindak balas dengan cepat kepada arahan manusia. Oleh itu, kami memilih Mamba sebagai model bahasa besar kami kerana keupayaan penaakulan yang sedar konteks dan kerumitan pengiraan linear. Gesaan teks dikodkan ke dalam ruang benam 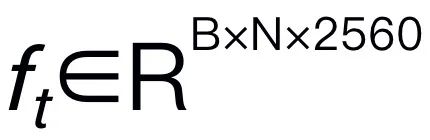 menggunakan tokenizer yang telah dilatih, kemudian digabungkan (kucing) dengan token visual dan dimasukkan ke dalam Mamba. Kami memanfaatkan pemodelan jujukan Mamba yang berkuasa untuk memahami maklumat pelbagai mod dan menggunakan strategi latihan yang berkesan untuk membangunkan keupayaan penaakulan visual (seperti yang diterangkan dalam bahagian seterusnya). Token keluaran (
menggunakan tokenizer yang telah dilatih, kemudian digabungkan (kucing) dengan token visual dan dimasukkan ke dalam Mamba. Kami memanfaatkan pemodelan jujukan Mamba yang berkuasa untuk memahami maklumat pelbagai mod dan menggunakan strategi latihan yang berkesan untuk membangunkan keupayaan penaakulan visual (seperti yang diterangkan dalam bahagian seterusnya). Token keluaran ( ) kemudiannya dinyahkod (det) untuk menjana tindak balas bahasa semula jadi
) kemudiannya dinyahkod (det) untuk menjana tindak balas bahasa semula jadi 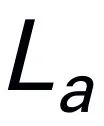 . Proses ke hadapan model boleh dinyatakan seperti berikut:
. Proses ke hadapan model boleh dinyatakan seperti berikut: 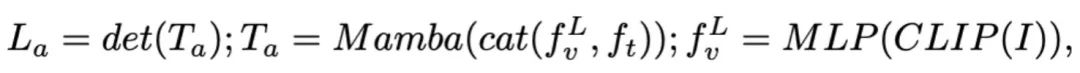
3.RoboMamba visi umum dan latihan keupayaan penaakulan robotSelepas membina seni bina RoboMamba, matlamat seterusnya adalah untuk melatih model kami untuk mempelajari penaakulan visual umum dan kebolehan penaakulan berkaitan robot. Seperti yang ditunjukkan dalam Rajah 3, kami membahagikan latihan Peringkat 1 kepada dua sub-langkah: penjajaran pra-latihan (Peringkat 1.1) dan latihan bersama arahan (Peringkat 1.2). Khususnya, tidak seperti kaedah latihan MLLM sebelumnya, kami menyasarkan untuk membolehkan RoboMamba memahami visi umum dan senario robotik. Memandangkan bidang robotik melibatkan banyak tugas yang kompleks dan baru, RoboMamba memerlukan keupayaan generalisasi yang lebih kukuh. Oleh itu, kami menggunakan strategi latihan bersama dalam Peringkat 1.2 untuk menggabungkan data robot peringkat tinggi (cth., perancangan misi) dengan data arahan am. Kami mendapati bahawa latihan bersama bukan sahaja menghasilkan dasar robot yang lebih umum, tetapi juga menghasilkan keupayaan penaakulan senario umum yang dipertingkatkan disebabkan oleh tugas penaakulan yang kompleks dalam data robot. Butiran latihan adalah seperti berikut: - Peringkat 1.1: Pra-latihan penjajaran.
Kami mengguna pakai set data berpasangan 558k imej-teks ditapis LLaVA untuk penjajaran rentas modal. Seperti yang ditunjukkan dalam Rajah 3, kami membekukan parameter pengekod CLIP dan model bahasa Mamba dan hanya mengemas kini lapisan unjuran. Dengan cara ini, kami boleh menyelaraskan ciri imej dengan pembenaman perkataan Mamba yang telah terlatih. - Peringkat 1.2: Perintah untuk berlatih bersama.
Dalam peringkat ini, kami mula-mula mengikuti kerja MLLM sebelumnya untuk pengumpulan data arahan visual am. Kami menggunakan Set Data Arahan Hibrid 655K LLaVA dan Set Data Arahan LRV 400K untuk mempelajari arahan visual mengikut dan mengurangkan halusinasi, masing-masing. Adalah penting untuk ambil perhatian bahawa mengurangkan halusinasi memainkan peranan penting dalam senario robotik kerana MLLM robotik perlu menjana rancangan misi berdasarkan senario sebenar dan bukannya yang dibayangkan. Sebagai contoh, MLLM sedia ada boleh menjawab "Buka ketuhar gelombang mikro" secara formula dengan menyebut "Langkah 1: Cari pemegang," tetapi kebanyakan ketuhar gelombang mikro tidak mempunyai pemegang. Seterusnya, kami menggabungkan set data 800K RoboVQA untuk mempelajari kemahiran robotik peringkat tinggi seperti perancangan misi jarak jauh, pertimbangan kebolehgerakan, penjanaan kebolehgerakan, ramalan masa depan dan masa lalu, dsb. Semasa latihan bersama, seperti yang ditunjukkan dalam Rajah 3, kami membekukan parameter pengekod CLIP dan memperhalusi lapisan unjuran dan Mamba pada set data gabungan 1.8m. Semua output daripada model bahasa Mamba diawasi menggunakan kehilangan entropi silang. 4. Keupayaan Manipulasi RoboMamba Latihan Penalaan Halus Berdasarkan keupayaan penaakulan RoboMamba yang berkuasa, kami memperkenalkan strategi penalaan halus bahagian operasi robot kami, yang dipanggil dalam Rajah 2 bahagian latihan robot ini. . Kaedah pengendalian robot berasaskan MLLM sedia ada memerlukan pengemaskinian lapisan unjuran dan keseluruhan LLM semasa fasa penalaan halus operasi. Walaupun paradigma ini boleh memberikan keupayaan ramalan pose tindakan model, ia juga memusnahkan keupayaan sedia ada MLLM dan memerlukan sejumlah besar sumber latihan. Untuk menangani cabaran ini, kami mencadangkan strategi penalaan halus yang cekap, seperti yang ditunjukkan dalam Rajah 3. Kami membekukan semua parameter RoboMamba dan memperkenalkan kepala Polisi ringkas untuk memodelkan token keluaran Mamba. Ketua polisi mengandungi dua MLP yang masing-masing mempelajari kedudukan dan arah pengesan akhir, menduduki sejumlah 0.1% daripada keseluruhan parameter model. Mengikut kerja sebelumnya where2act, formula kehilangan kedudukan dan arah adalah seperti berikut: 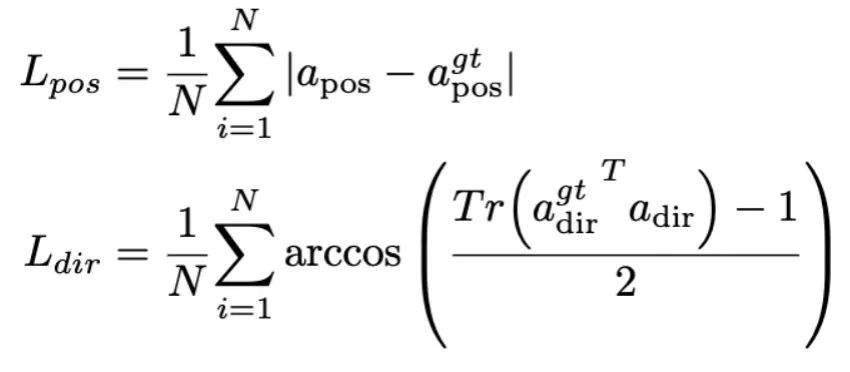 di mana, N mewakili bilangan sampel latihan, dan Tr (A) mewakili jejak matriks A. RoboMamba hanya meramalkan kedudukan 2D (x, y) piksel kenalan dalam imej dan kemudian menggunakan maklumat kedalaman untuk menukarnya kepada ruang 3D. Untuk menilai strategi penalaan halus ini, kami menghasilkan set data sebanyak 10,000 ramalan pose kesan akhir menggunakan simulasi SAPIEN. Selepas penalaan halus operasi, kami mendapati bahawa sebaik sahaja RoboMamba mempunyai keupayaan penaakulan yang mencukupi, ia boleh memperoleh kemahiran ramalan pose melalui penalaan halus yang sangat cekap. Disebabkan bilangan minimum parameter penalaan halus (7MB) dan reka bentuk model yang cekap, kami boleh mencapai pembelajaran kemahiran operasi baharu dalam masa 20 minit sahaja. Penemuan ini menyerlahkan kepentingan keupayaan penaakulan dalam mempelajari kemahiran operasi dan mencadangkan perspektif baharu: kita boleh memperkasakan MLLM dengan cekap dengan keupayaan operasi tanpa menjejaskan keupayaan penaakulan yang wujud. Akhir sekali, RoboMamba boleh menggunakan respons bahasa untuk akal sehat dan penaakulan berkaitan robot, dan ketua dasar untuk ramalan pose tindakan. 1. Penilaian Kebolehan Penaakulan Umum (Tanda Aras MLLM) 🎜🎜🎜🎜 yang popular. QAv2, OKVQA, GQA, OCRVQA , VizWiz, POPE, MME, MMBench dan MM-Vet.Selain itu, kami juga secara langsung menilai keupayaan penaakulan berkaitan robot RoboMamba pada set data pengesahan 18k RoboVQA, meliputi tugasan robot seperti perancangan tugas, perancangan tugas yang digesa, perancangan tugas jarak jauh, pertimbangan kebolehgerakan dan penjanaan seksual, perihalan masa lalu dan ramalan masa depan, dsb. Om Jadual 1. Perbandingan Robomamba dan MLLMS sedia ada pada pelbagai penanda aras.
di mana, N mewakili bilangan sampel latihan, dan Tr (A) mewakili jejak matriks A. RoboMamba hanya meramalkan kedudukan 2D (x, y) piksel kenalan dalam imej dan kemudian menggunakan maklumat kedalaman untuk menukarnya kepada ruang 3D. Untuk menilai strategi penalaan halus ini, kami menghasilkan set data sebanyak 10,000 ramalan pose kesan akhir menggunakan simulasi SAPIEN. Selepas penalaan halus operasi, kami mendapati bahawa sebaik sahaja RoboMamba mempunyai keupayaan penaakulan yang mencukupi, ia boleh memperoleh kemahiran ramalan pose melalui penalaan halus yang sangat cekap. Disebabkan bilangan minimum parameter penalaan halus (7MB) dan reka bentuk model yang cekap, kami boleh mencapai pembelajaran kemahiran operasi baharu dalam masa 20 minit sahaja. Penemuan ini menyerlahkan kepentingan keupayaan penaakulan dalam mempelajari kemahiran operasi dan mencadangkan perspektif baharu: kita boleh memperkasakan MLLM dengan cekap dengan keupayaan operasi tanpa menjejaskan keupayaan penaakulan yang wujud. Akhir sekali, RoboMamba boleh menggunakan respons bahasa untuk akal sehat dan penaakulan berkaitan robot, dan ketua dasar untuk ramalan pose tindakan. 1. Penilaian Kebolehan Penaakulan Umum (Tanda Aras MLLM) 🎜🎜🎜🎜 yang popular. QAv2, OKVQA, GQA, OCRVQA , VizWiz, POPE, MME, MMBench dan MM-Vet.Selain itu, kami juga secara langsung menilai keupayaan penaakulan berkaitan robot RoboMamba pada set data pengesahan 18k RoboVQA, meliputi tugasan robot seperti perancangan tugas, perancangan tugas yang digesa, perancangan tugas jarak jauh, pertimbangan kebolehgerakan dan penjanaan seksual, perihalan masa lalu dan ramalan masa depan, dsb. Om Jadual 1. Perbandingan Robomamba dan MLLMS sedia ada pada pelbagai penanda aras. 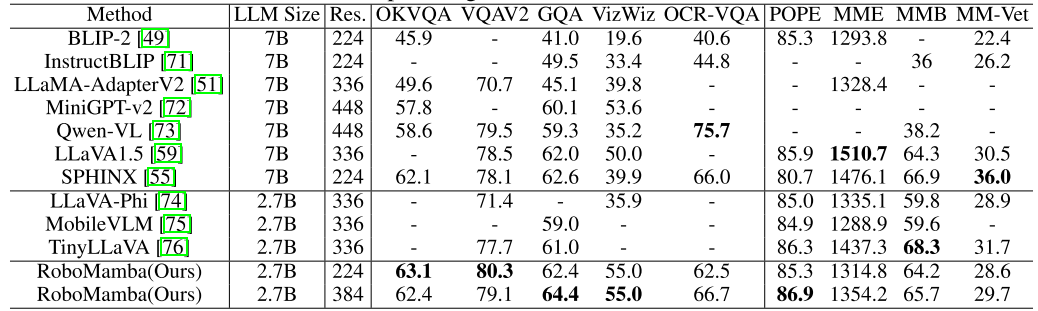 Seperti yang ditunjukkan dalam Jadual 1, kami membandingkan RoboMamba dengan MLLM terkini (SOTA) terkini pada VQA biasa dan penanda aras MLLM terkini. Pertama, kami mendapati bahawa RoboMamba mencapai hasil yang memuaskan pada semua penanda aras VQA hanya menggunakan model bahasa 2.7B. Keputusan menunjukkan bahawa reka bentuk struktur mudah adalah berkesan. Pra-latihan dan latihan bersama arahan yang diselaraskan dengan ketara meningkatkan keupayaan inferens MLLM. Sebagai contoh, prestasi pengecaman spatial RoboMamba pada penanda aras GQA dipertingkatkan disebabkan oleh pengenalan sejumlah besar data robot dalam fasa latihan kolaboratif. Sementara itu, kami juga menguji RoboMamba kami pada penanda aras MLLM yang dicadangkan baru-baru ini. Berbanding dengan MLLM sebelumnya, kami mendapati model kami mencapai keputusan yang kompetitif pada semua penanda aras. Walaupun beberapa prestasi RoboMamba masih lebih rendah daripada MLLM 7B yang canggih (cth., LLaVA1.5 dan SPHINX), kami mengutamakan Mamba-2.7B yang lebih kecil dan lebih pantas untuk mengimbangi kecekapan model robot. Pada masa hadapan, kami merancang untuk membangunkan RoboMamba-7B untuk senario tanpa kekangan sumber.
Seperti yang ditunjukkan dalam Jadual 1, kami membandingkan RoboMamba dengan MLLM terkini (SOTA) terkini pada VQA biasa dan penanda aras MLLM terkini. Pertama, kami mendapati bahawa RoboMamba mencapai hasil yang memuaskan pada semua penanda aras VQA hanya menggunakan model bahasa 2.7B. Keputusan menunjukkan bahawa reka bentuk struktur mudah adalah berkesan. Pra-latihan dan latihan bersama arahan yang diselaraskan dengan ketara meningkatkan keupayaan inferens MLLM. Sebagai contoh, prestasi pengecaman spatial RoboMamba pada penanda aras GQA dipertingkatkan disebabkan oleh pengenalan sejumlah besar data robot dalam fasa latihan kolaboratif. Sementara itu, kami juga menguji RoboMamba kami pada penanda aras MLLM yang dicadangkan baru-baru ini. Berbanding dengan MLLM sebelumnya, kami mendapati model kami mencapai keputusan yang kompetitif pada semua penanda aras. Walaupun beberapa prestasi RoboMamba masih lebih rendah daripada MLLM 7B yang canggih (cth., LLaVA1.5 dan SPHINX), kami mengutamakan Mamba-2.7B yang lebih kecil dan lebih pantas untuk mengimbangi kecekapan model robot. Pada masa hadapan, kami merancang untuk membangunkan RoboMamba-7B untuk senario tanpa kekangan sumber. 2. Penilaian keupayaan penaakulan robot (Tanda Aras RoboVQA)
Selain itu, untuk membandingkan secara menyeluruh keupayaan penaakulan berkaitan robot RoboMamba-Adaptasi Robo-LaVMA, kami menetapkan LVMA yang sah. Kami memilih LLaMA-AdapterV2 sebagai garis dasar kerana ia adalah model asas untuk MLLM robotik SOTA semasa (ManipLLM). Untuk perbandingan yang adil, kami memuatkan parameter pra-latihan LLaMA-AdapterV2 dan memperhalusinya pada set latihan RoboVQA untuk dua zaman menggunakan kaedah penalaan halus arahan rasminya. Seperti yang ditunjukkan dalam Rajah 4 a), RoboMamba mencapai prestasi unggul antara BLEU-1 hingga BLEU-4. Keputusan menunjukkan bahawa model kami mempunyai keupayaan penaakulan berkaitan robot lanjutan dan mengesahkan keberkesanan strategi latihan kami. Selain ketepatan yang lebih tinggi, model kami mencapai kelajuan inferens sehingga 7 kali lebih pantas daripada LLaMA-AdapterV2 dan ManipLLM, yang boleh dikaitkan dengan keupayaan inferens sedar kandungan dan kecekapan model bahasa Mamba. Rajah 4. Perbandingan penaakulan berkaitan robot pada RoboVQA.  3. Penilaian Keupayaan Manipulasi Robot (SAPIEN)
3. Penilaian Keupayaan Manipulasi Robot (SAPIEN)
Untuk menilai keupayaan manipulasi RoboMamba, kami membandingkan model kami dengan empat garis dasar FROMOLLBot, RoboLLbotNet. Sebelum membuat perbandingan, kami mengeluarkan semula semua garis dasar dan melatihnya pada set data yang kami kumpulkan. Untuk UMPNet, kami melakukan operasi pada titik hubungan yang diramalkan, berorientasikan serenjang dengan permukaan objek. Flowbot3D meramalkan arah gerakan pada awan titik, memilih aliran terbesar sebagai titik interaksi dan menggunakan arah aliran untuk mewakili arah efektor akhir. RoboFlamingo dan ManipLLM memuatkan parameter pra-latihan OpenFlamingo dan LLaMA-AdapterV2 masing-masing, dan ikuti strategi penalaan halus dan kemas kini model masing-masing. Seperti yang ditunjukkan dalam Jadual 2, berbanding dengan SOTA ManipLLM sebelumnya, RoboMamba kami mencapai 7.0% peningkatan pada kategori yang boleh dilihat dan 2.0% peningkatan pada kategori yang tidak kelihatan. Dari segi kecekapan, RoboFlamingo mengemas kini 35.5% (1.8B) parameter model, ManipLLM mengemas kini penyesuai dalam LLM (41.3M) yang mengandungi 0.5% parameter model, manakala kepala Polisi kami yang ditala halus (3.7M) hanya mengambil kira parameter model 0.1 %. RoboMamba mengemas kini 10x lebih sedikit parameter daripada kaedah berasaskan MLLM sebelumnya sambil membuat kesimpulan 7x lebih pantas. Keputusan menunjukkan bahawa RoboMamba kami bukan sahaja mempunyai keupayaan penaakulan yang kukuh, tetapi juga boleh mendapatkan keupayaan manipulasi dengan cara yang murah. Jadual 2. Perbandingan kadar kejayaan antara Robomamba dan garis dasar lain Hasil kualitatif

Seperti yang ditunjukkan dalam Rajah 4, kami memvisualisasikan hasil inferens RoboMamba dalam pelbagai tugas hiliran robotik. Dari segi perancangan tugas, berbanding LLaMA-AdapterV2, RoboMamba telah menunjukkan keupayaan perancangan jangka panjang yang lebih tepat dan jangka panjang kerana keupayaan penaakulannya yang kuat. Untuk perbandingan yang adil, kami juga memperhalusi garis dasar LLaMA-AdapterV2 pada set data RoboVQA. Untuk ramalan pose manipulasi, kami menggunakan lengan robot Franka Emika untuk berinteraksi dengan pelbagai objek isi rumah. Kami menayangkan pose 3D yang diramalkan oleh RoboMamba pada imej 2D, menggunakan titik merah untuk mewakili titik hubungan dan pengesan akhir untuk mewakili arah, seperti yang ditunjukkan di sudut kanan bawah rajah. 

Atas ialah kandungan terperinci Universiti Peking melancarkan model robot pelbagai mod baharu! Penaakulan dan operasi yang cekap untuk senario umum dan robotik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




 . Sebagai contoh, apabila berhadapan dengan masalah perancangan seperti "Bagaimana untuk mengosongkan jadual jawapan biasanya termasuk langkah-langkah seperti "Langkah 1: Angkat objek" dan "Langkah 2: Letakkan objek ke dalam kotak." Untuk ramalan tindakan, kami menggunakan kepala dasar yang cekap dan mudah π untuk meramalkan tindakan
. Sebagai contoh, apabila berhadapan dengan masalah perancangan seperti "Bagaimana untuk mengosongkan jadual jawapan biasanya termasuk langkah-langkah seperti "Langkah 1: Angkat objek" dan "Langkah 2: Letakkan objek ke dalam kotak." Untuk ramalan tindakan, kami menggunakan kepala dasar yang cekap dan mudah π untuk meramalkan tindakan  ppt masukkan nombor halaman
ppt masukkan nombor halaman
 arahan penutupan berjadual linux
arahan penutupan berjadual linux
 Bagaimana untuk menyimpan program yang ditulis dalam pycharm
Bagaimana untuk menyimpan program yang ditulis dalam pycharm
 Kegunaan utama sistem pengendalian Linux
Kegunaan utama sistem pengendalian Linux
 Kaedah dan amalan pemprosesan audio berasaskan Java
Kaedah dan amalan pemprosesan audio berasaskan Java
 Alat penilaian nama domain tapak web
Alat penilaian nama domain tapak web
 Bagaimana untuk melaraskan saiz teks dalam mesej teks
Bagaimana untuk melaraskan saiz teks dalam mesej teks
 Mengapa wifi mempunyai tanda seru?
Mengapa wifi mempunyai tanda seru?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



