


DiT boleh digunakan untuk menjana video tanpa kehilangan kualiti dan latihan tidak diperlukan.
Penjanaan video AI masa nyata ada di sini!
Pada hari Rabu, pasukan You Yang dari Universiti Nasional Singapura mencadangkan kaedah penjanaan video berasaskan DiT pertama dalam industri yang boleh dikeluarkan dalam masa nyata.

Teknologi ini dipanggil Pyramid Attention Broadcast (PAB). Dengan mengurangkan pengiraan perhatian yang berlebihan, PAB mencapai kadar bingkai sehingga 21.6 FPS dan kelajuan 10.6x tanpa mengorbankan faedah model penjanaan video berasaskan DiT yang popular termasuk kualiti Open-Sora, Open-Sora-Plan dan Latte. Perlu diingat bahawa sebagai kaedah yang tidak memerlukan latihan, PAB boleh memberikan pecutan untuk mana-mana model penjanaan video berasaskan DiT masa hadapan, memberikannya keupayaan untuk menjana video masa nyata.
Sejak tahun ini, Sora OpenAI dan model penjanaan video berasaskan DiT lain telah menyebabkan gelombang lain dalam bidang AI. Walau bagaimanapun, berbanding dengan penjanaan imej, tumpuan orang ramai pada penjanaan video pada asasnya adalah pada kualiti, dan beberapa kajian menumpukan pada penerokaan cara mempercepatkan inferens model DiT. Mempercepatkan inferens model generatif video sudah menjadi keutamaan untuk aplikasi AI generatif.
Kemunculan kaedah PAB telah membuka jalan kepada kita. Perbandingan kaedah asal dan kelajuan penjanaan video PAB. Pengarang menguji 5 4s (192 bingkai) video resolusi 480p pada Open-Sora. 
pyramid attention broadcast
Baru-baru ini, Sora dan model penjanaan video berasaskan DiT lain telah menarik perhatian meluas. Walau bagaimanapun, berbanding dengan penjanaan imej, beberapa kajian telah menumpukan pada mempercepatkan inferens model penjanaan video berasaskan DiT. Tambahan pula, kos inferens untuk menghasilkan satu video boleh menjadi tinggi.散 Rajah 1: Perbezaan antara langkah resapan semasa dan langkah resapan sebelumnya, dan ralat pembezaan (MSE) dikira.Pelaksanaan
Kajian ini mendedahkan dua pemerhatian utama mekanisme perhatian dalam pengubah resapan video: Pertama, perbezaan perhatian pada langkah masa yang berbeza menunjukkan corak berbentuk U, pada 15 awal dan terakhir % langkah berubah dengan ketara, manakala bahagian tengah 70% langkah sangat stabil dengan perbezaan kecil.
Pertama, perbezaan perhatian pada langkah masa yang berbeza menunjukkan corak berbentuk U, pada 15 awal dan terakhir % langkah berubah dengan ketara, manakala bahagian tengah 70% langkah sangat stabil dengan perbezaan kecil.
Kedua, dalam segmen tengah yang stabil, terdapat perbezaan antara jenis perhatian: perhatian spatial paling banyak berubah, melibatkan elemen frekuensi tinggi seperti tepi dan tekstur menunjukkan perubahan frekuensi pertengahan yang berkaitan dengan gerakan dan dinamik dalam video; Perhatian silang modal ialah teks yang paling stabil, menghubungkan teks dengan kandungan video, serupa dengan isyarat frekuensi rendah yang mencerminkan semantik teks. Berdasarkan ini, pasukan penyelidik mencadangkan penyiaran perhatian piramid untuk mengurangkan pengiraan perhatian yang tidak perlu. Di bahagian tengah, perhatian menunjukkan perbezaan kecil, dan kajian menyiarkan output perhatian satu langkah resapan ke beberapa langkah seterusnya, dengan itu mengurangkan kos pengiraan dengan ketara. Selain itu, untuk pengiraan yang lebih cekap dan kehilangan kualiti yang minimum, pengarang menetapkan julat siaran yang berbeza mengikut kestabilan dan perbezaan perhatian yang berbeza. Walaupun tanpa latihan selepas, strategi mudah namun berkesan ini mencapai kelajuan sehingga 35% dengan kehilangan kualiti yang boleh diabaikan dalam kandungan yang dijana.
Rajah 2: Kajian ini mencadangkan siaran perhatian piramid, di mana julat siaran berbeza ditetapkan untuk tiga perhatian berdasarkan perbezaan perhatian. Lebih kecil perubahan perhatian, lebih luas julat siaran. Pada masa jalanan, kaedah ini menyiarkan hasil perhatian kepada beberapa langkah seterusnya untuk mengelakkan pengiraan perhatian yang berlebihan. x_t merujuk kepada ciri pada langkah masa t.
Sejajar
Rajah 3 di bawah menunjukkan perbandingan antara kaedah dalam artikel ini dan Paralle Jujukan Dinamik (DSP) asal. Apabila perhatian duniawi disebarkan, maka semua komunikasi dapat dielakkan.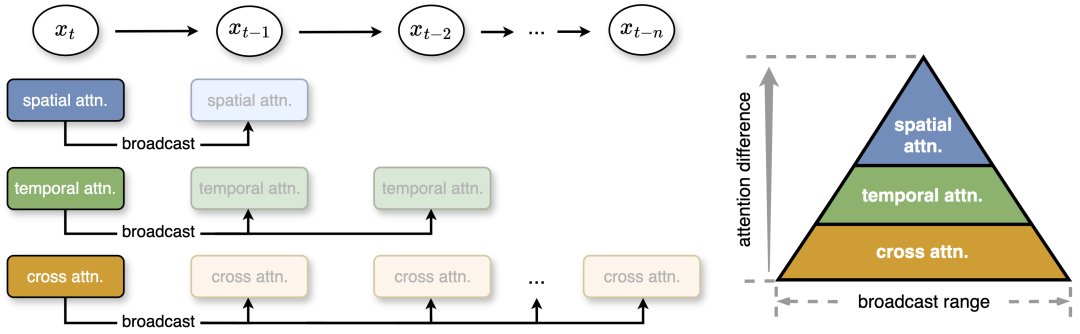
Untuk meningkatkan lagi kelajuan penjanaan video, artikel ini menggunakan DSP untuk meningkatkan keselarian jujukan. Sequence Parallel membahagikan video kepada bahagian berbeza merentas berbilang GPU, mengurangkan beban kerja pada setiap GPU dan menurunkan kependaman binaan. Walau bagaimanapun, DSP memperkenalkan sejumlah besar overhed komunikasi, memerlukan masa dan perhatian untuk menyediakan dua komunikasi Semua-ke-Semua.
Dengan menyebarkan perhatian temporal dalam PAB, artikel ini tidak lagi perlu mengira perhatian temporal, sekali gus mengurangkan komunikasi. Sejajar dengan itu, overhed komunikasi dikurangkan dengan ketara sebanyak lebih daripada 50%, membolehkan inferens teragih yang lebih cekap untuk penjanaan video masa nyata.
Hasil penilaian
Pecutan
Angka berikut menunjukkan jumlah kependaman PAB yang diukur oleh model berbeza apabila menjana satu video pada 8 NVIDIA H100 GPU. Apabila menggunakan GPU tunggal, pengarang mencapai kelajuan 1.26 hingga 1.32x dan kekal stabil merentas penjadual yang berbeza.
Apabila dilanjutkan kepada berbilang GPU, kaedah ini mencapai pecutan 10.6x dan mendapat manfaat daripada peningkatan selari berjujukan yang cekap untuk mencapai pengembangan hampir linear dengan bilangan GPU.

Hasil kualitatif
Tiga video berikut masing-masing adalah Open-Sora, Open-Sora-Plan dan Latte menggunakan kaedah asal untuk membandingkan kesan kaedah dalam artikel ini. Ia boleh dilihat bahawa kaedah dalam artikel ini mencapai darjah pecutan FPS yang berbeza di bawah bilangan GPU yang berbeza. . dan Latte ) keputusan penunjuk. 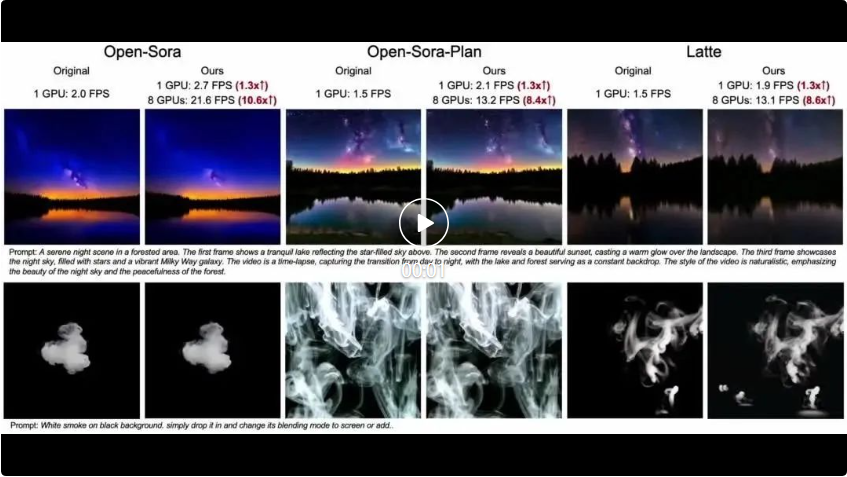
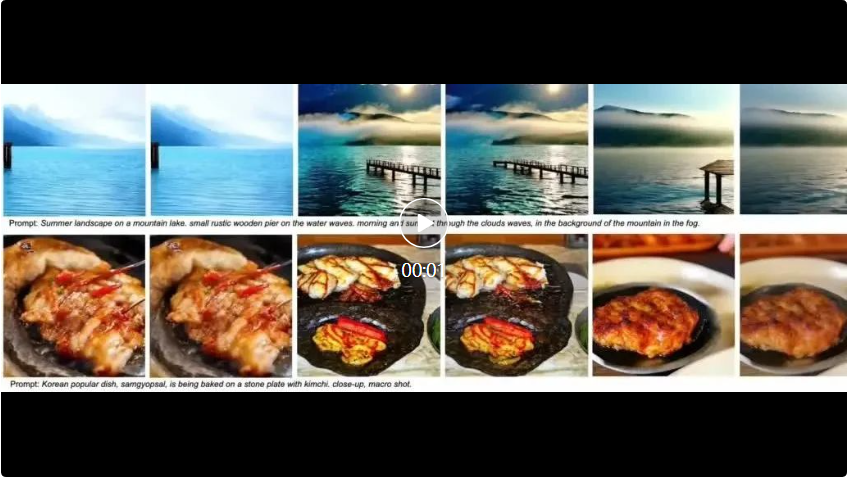 Lebih banyak butiran teknikal dan keputusan penilaian boleh didapati dalam kertas akan datang. Alamat projek: https://oahzxl.github.io/PAB/
Lebih banyak butiran teknikal dan keputusan penilaian boleh didapati dalam kertas akan datang. Alamat projek: https://oahzxl.github.io/PAB/
Pautan rujukan:
https://oahzxl.github.io/PAB/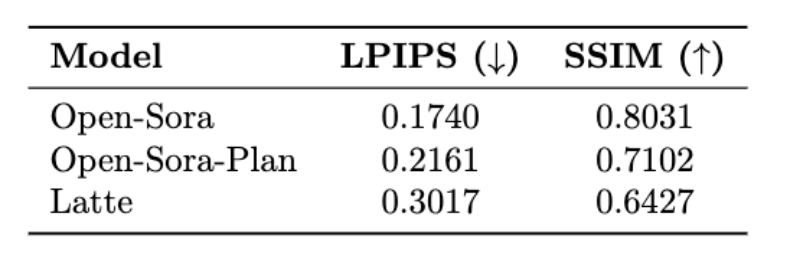
Atas ialah kandungan terperinci Teknologi penjanaan video AI masa nyata pertama dalam sejarah: DiT universal, 10.6 kali lebih pantas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menjadi kawan rapat di TikTok
Bagaimana untuk menjadi kawan rapat di TikTok
 Cara menyediakan Douyin untuk menghalang semua orang daripada melihat hasil kerja
Cara menyediakan Douyin untuk menghalang semua orang daripada melihat hasil kerja
 Pengenalan kepada arahan biasa postgresql
Pengenalan kepada arahan biasa postgresql
 penggunaan transactionscope
penggunaan transactionscope
 Cara menyemak plagiarisme pada CNKI Langkah terperinci untuk menyemak plagiarisme pada CNKI
Cara menyemak plagiarisme pada CNKI Langkah terperinci untuk menyemak plagiarisme pada CNKI
 Apakah maksud konsep metaverse?
Apakah maksud konsep metaverse?
 Jadual perbandingan kod ASCII
Jadual perbandingan kod ASCII
 Bagaimana untuk membuka python selepas ia dipasang
Bagaimana untuk membuka python selepas ia dipasang








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



