


Terdapat berpuluh-puluh penjana teks-ke-imej AI percuma dan sumber terbuka tersedia di internet yang pakar dalam jenis imej tertentu. Jadi, kami telah menapis timbunan dan menemui penjana teks-ke-imej AI sumber terbuka terbaik yang boleh anda cuba sekarang.
Craiyon ialah salah satu penjana imej AI sumber terbuka yang paling mudah diakses. Ia berdasarkan DALL-E Mini, dan semasa anda boleh mengklon repositori Github dan memasang model secara tempatan pada komputer anda, Craiyon nampaknya telah menggugurkan pendekatan ini memihak kepada tapak webnya.
Repositori Github rasmi belum dikemas kini sejak Jun 2022, tetapi model terbaharu masih tersedia secara percuma di tapak rasmi Craiyon. Tiada aplikasi Android atau iOS sama ada.
Dari segi kefungsian, anda akan melihat semua pilihan biasa yang anda jangkakan daripada penjana imej AI. Sebaik sahaja anda memasukkan gesaan anda dan mendapatkan imej, anda boleh menggunakan ciri kelas atas untuk mendapatkan salinan resolusi lebih tinggi. Terdapat tiga gaya untuk dipilih: Seni, Foto dan Lukisan. Anda juga boleh memilih pilihan "Tiada" jika anda mahu model membuat keputusan.
Selain itu, "Mod Pakar" membolehkan anda memasukkan perkataan negatif, yang memberitahu model untuk mengelakkan item tertentu. Terdapat juga ciri ramalan segera, yang menggunakan ChatGPT untuk membantu pengguna menulis gesaan yang terbaik dan paling terperinci yang mungkin. Akhir sekali, ciri alih keluar yang dikuasakan AI boleh membantu anda menjimatkan masa dan usaha memotong latar belakang daripada imej.
Dan itulah kira-kira semua yang Craiyon lakukan. Ia bukan model penjanaan imej AI yang paling canggih, tetapi ia berfungsi dengan baik sebagai model asas jika anda tidak mahu sesuatu yang terperinci atau realistik.
Model ini percuma untuk digunakan, tetapi pengguna percuma dihadkan kepada sembilan imej percuma pada satu masa dalam masa seminit. Anda boleh melanggan peringkat Penyokong atau Profesional mereka (masing-masing berharga $5 dan $20 sebulan dan dibilkan setiap tahun) untuk tidak mendapat iklan atau tera air, penjanaan lebih pantas dan pilihan untuk memastikan imej yang anda hasilkan peribadi. Peringkat langganan tersuai juga membenarkan model tersuai, penyepaduan, sokongan khusus dan pelayan peribadi.
Resapan Stabil mungkin merupakan salah satu model penjanaan teks-ke-imej sumber terbuka yang paling popular. Ia juga memberi kuasa kepada model lain, termasuk tiga penjana imej yang dinyatakan di bawah. Ia dikeluarkan pada tahun 2022 dan telah mempunyai banyak pelaksanaan sejak itu.
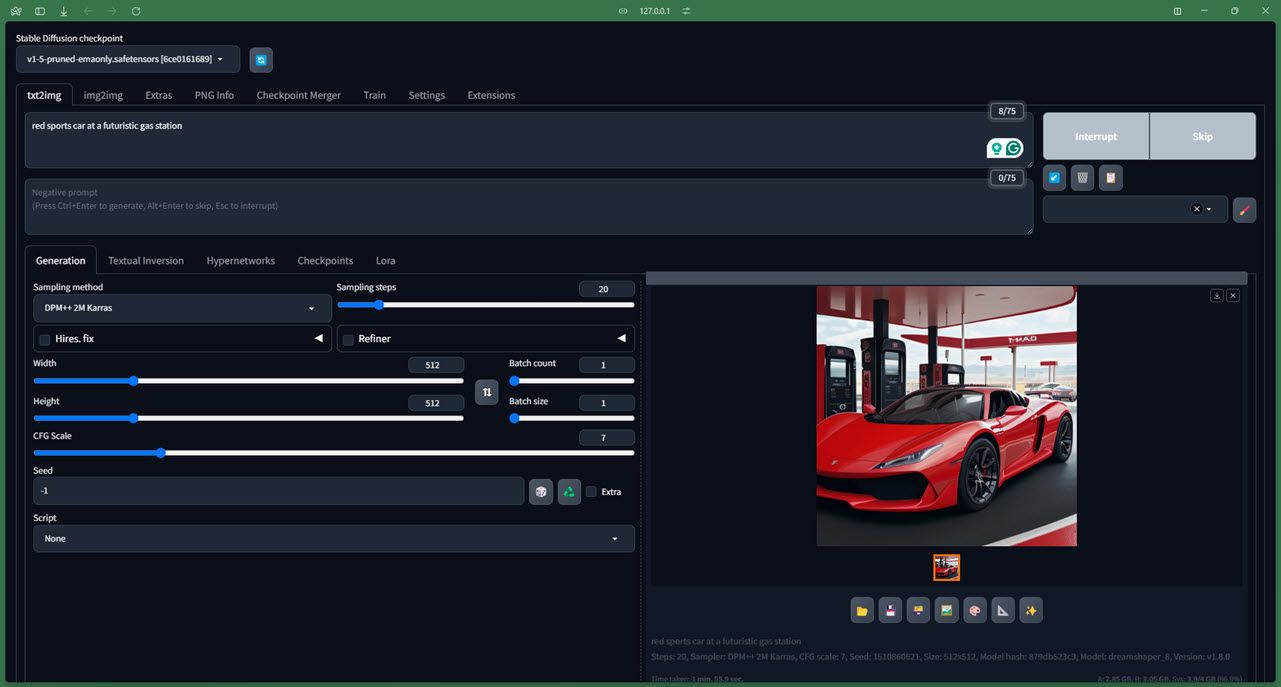
Saya akan memberikan anda butiran yang terlalu teknikal tentang cara model berfungsi (yang mana anda boleh menyemak repositori Github rasmi mereka), tetapi model ini mudah dipasang walaupun untuk pemula yang lengkap dan berfungsi dengan baik selagi anda mempunyai GPU khusus dengan sekurang-kurangnya 4GB memori. Anda juga boleh mengakses Stable Diffusion dalam talian, dan kami memberi anda perlindungan jika anda ingin menjalankan Stable Diffusion pada Mac.
Terdapat beberapa pusat pemeriksaan (anggap sebagai versi) tersedia untuk digunakan untuk Stable Diffusion. Semasa kami menguji versi 1.5, versi 2.1 juga dalam pembangunan aktif dan lebih tepat.

Menjalankan model juga agak mudah. Kami mengujinya dengan antara muka pengguna web AUTOMATIC1111 Stable Diffusion, dan semua kawalan serta parameter berfungsi dengan baik. Ia juga agak NSFW-bukti ihsan daripada pangkalan data LAION-5B yang model itu dilatih (walaupun ia tidak sempurna, maklumlah). Walaupun masa penjanaan itu sendiri berbeza-beza berdasarkan perkakasan anda, anda boleh mengharapkan imej anda terperinci dan realistik walaupun dengan gesaan asas.
DreamShaper ialah model penjanaan imej berdasarkan Stable Diffusion. Ia bertujuan sebagai alternatif sumber terbuka kepada MidJourney dan memfokuskan pada fotorealisme dalam imej yang dijana, walaupun ia boleh mengendalikan gaya anime dan lukisan dengan baik dengan beberapa tweak.
Model ini lebih berkebolehan daripada Stable Diffusion, membenarkan pengguna lebih kebebasan terhadap keluaran akhir, daripada penambahbaikan kilat kepada sekatan NSFW yang lebih longgar. Menjalankan model juga mudah, dengan versi pra-latihan yang boleh dimuat turun tersedia dalam talian untuk akses tempatan dan pelbagai tapak web, termasuk Sinkin.ai, RandomSeed dan Mage.space (memerlukan langganan asas) yang membolehkan anda menjalankan model dengan pecutan GPU.
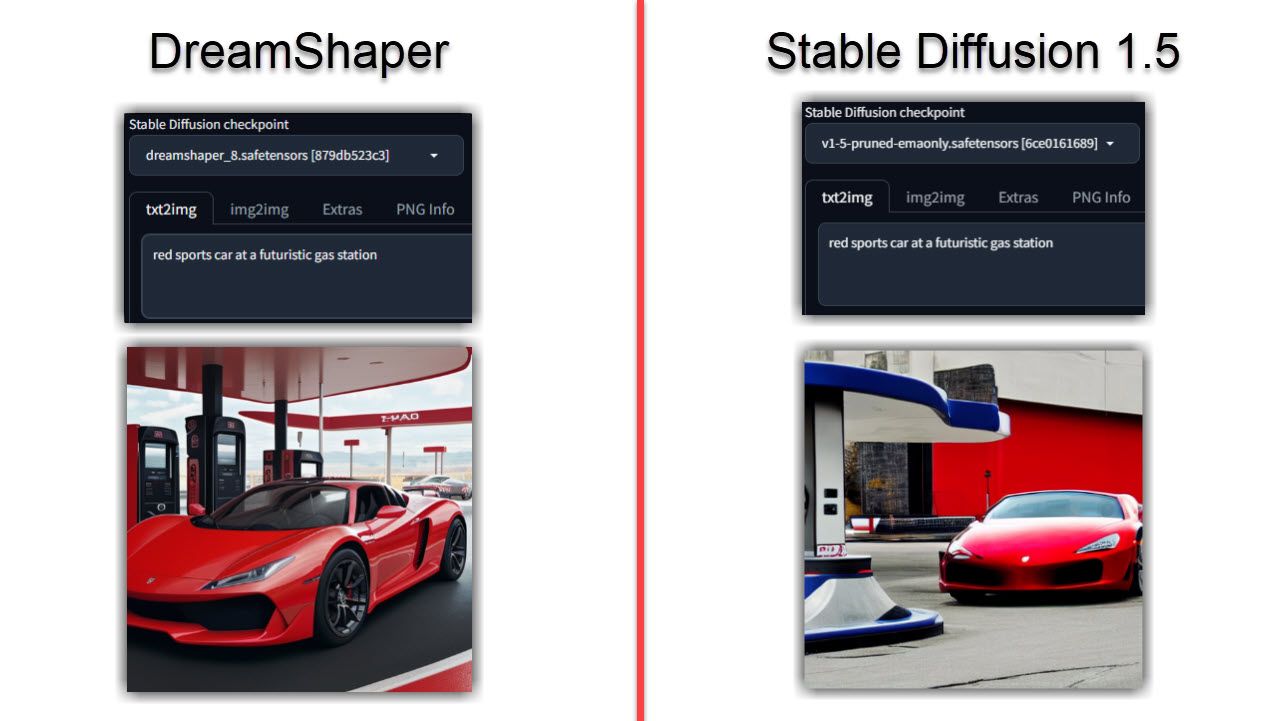
Seperti yang anda mungkin boleh meneka sekarang, imej yang dijana oleh DreamShaper cenderung kelihatan lebih realistik berbanding dengan Stable Diffusion. Walaupun anda menjalankan gesaan yang sama pada kedua-dua model, model DreamShaper mungkin akan menjadi lebih realistik, terperinci dan lebih terang.
Ini benar terutamanya untuk potret atau watak, sesuatu yang saya dapati Stable Diffusion kurang berbanding dengan gesaan yang sama. Jika imej anda menjadi terlalu realistik, berikut ialah empat cara untuk mengenal pasti imej yang dijana AI.
Anda juga tidak memerlukan PC raksasa untuk menjalankan model itu. GTX 1650Ti saya dengan 4GB VRAM menjalankan model dengan sempurna. Masa penjanaan adalah lebih lama sedikit, tetapi ia nampaknya tidak menjejaskan output sebenar. Walau bagaimanapun, anda mungkin memerlukan GPU dengan lebih banyak VRAM untuk menjalankan DreamShaper XL, yang berdasarkan model Stable Diffusion XL.
Invoke AI ialah satu lagi model penjanaan imej berasaskan AI berdasarkan Stable Diffusion, dengan versi XL berdasarkan Stable Diffusion XL. Ia juga mempunyai antara muka pengguna web dan baris arahannya sendiri, bermakna anda tidak perlu melompat dengan perkara seperti UI web Stable Diffusion.
Model ini memfokuskan pada membenarkan pengguna mencipta visual berdasarkan harta intelek mereka dengan aliran kerja tersuai. InvokeAI ialah salah satu model penjanaan imej AI sumber terbuka terbaik untuk melatih model tersuai dan bekerja dengan harta intelek.
Repositori Github rasminya menyenaraikan dua kaedah pemasangan: memasang melalui pemasang InvokeAI atau menggunakan PyPI jika anda selesa dengan terminal dan Python dan memerlukan lebih kawalan ke atas pakej yang dipasang dengan model.
Walau bagaimanapun, kawalan tambahan membawa beberapa had, terutamanya keperluan perkakasan yang lebih ketat. InvokeAI mengesyorkan GPU khusus dengan sekurang-kurangnya 4GB memori, dengan enam hingga lapan GB disyorkan untuk menjalankan varian XL. Keperluan VRAM digunakan untuk kedua-dua GPU AMD dan Nvidia. Anda juga memerlukan sekurang-kurangnya 12GB RAM dan 12GB ruang cakera kosong untuk model, kebergantungannya dan Python.

Walaupun dokumentasi tidak mengesyorkan GPU Nvidia's GTX 10 Series dan 16 Series kerana kekurangan memori video, pemasang yang disediakan berfungsi dengan baik. Walaupun perbatuan anda mungkin berbeza-beza, jika anda menggunakan GPU yang lebih rendah, jangkakan untuk menunggu lebih lama untuk melihat gesaan anda diubah menjadi imej. Akhir sekali, jika anda menggunakan Windows, anda hanya boleh menggunakan GPU Nvidia, kerana tiada sokongan untuk GPU AMD pada masa ini.
Untuk bahagian penjanaan imej, model cenderung lebih condong kepada gaya artistik berbanding fotorealisme. Sudah tentu, anda boleh melatih model pada set data anda dan memintanya menjana imej lebih dekat dengan perkara yang anda mahukan, walaupun ia melibatkan imej fotorealistik, terutamanya jika anda bekerja dalam reka bentuk produk, seni bina atau ruang runcit. Walau bagaimanapun, satu perkara penting yang perlu diingat ialah InvokeAI adalah terutamanya enjin penjanaan imej, bermakna anda mungkin perlu menggunakan model anda sendiri untuk hasil terbaik (mudah ditemui melalui pengurus model yang disediakan dalam antara muka web) sebagai lalai model agak serupa dengan Stable Diffusion itu sendiri.
Openjourney ialah model penjanaan imej AI sumber terbuka percuma lagi berdasarkan Stable Diffusion. Jika anda tertanya-tanya mengapa model itu dipanggil Openjourney, ini kerana ia dilatih pada imej Midjourney dan boleh meniru gayanya dalam imej yang dihasilkannya.
PromptHero, syarikat di belakang Openjourney, membolehkan anda menguji model bersama model lain, termasuk Stable Diffusion (versi 1.5 dan 2), DreamShaper dan Realistic Vision. Apabila mendaftar, anda mendapat 25 kredit percuma (satu kredit untuk setiap imej yang dijana), selepas itu anda perlu melanggan peringkat langganan Pro mereka, yang berharga $9 sebulan dan memberi anda akses kepada 300 kredit setiap bulan dengan ciri eksklusif lain.

Walau bagaimanapun, jika anda ingin menjalankannya secara tempatan dan secara percuma, anda boleh memuat turun fail model daripada HuggingFace dan menjalankannya menggunakan UI web Stable Diffusion. Openjourney juga merupakan model penjanaan imej AI kedua paling banyak dimuat turun di HuggingFace, betul-betul di belakang Stable Diffusion.
Openjourney tidak menyenaraikan sebarang keperluan perkakasan khusus untuk menjalankan model secara setempat di tapak webnya, tetapi anda boleh mengharapkan keperluan perkakasan yang serupa dengan Stable Diffusion. Ini bermakna GPU khusus dengan 4GB VRAM, 16GB RAM dan sekitar 12 hingga 15GB ruang kosong pada komputer anda untuk menyimpan model dan kebergantungannya.

Imej yang dijana oleh Openjourney cenderung seimbang antara fotorealisme dan seni melainkan dinyatakan sebaliknya. Jika anda mencari model serba boleh dan lebih suka rupa dan rasa Midjourney tanpa membayar langganan, Openjourney ialah salah satu pilihan terbaik.
Atas ialah kandungan terperinci 5 Penjana Imej AI Sumber Terbuka Terbaik. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 pemampatan audio
pemampatan audio
 Platform mata wang digital domestik
Platform mata wang digital domestik
 tahap pengasingan transaksi mysql
tahap pengasingan transaksi mysql
 Apakah perpustakaan pihak ketiga yang biasa digunakan dalam PHP?
Apakah perpustakaan pihak ketiga yang biasa digunakan dalam PHP?
 Peranan Serverlet dalam Java
Peranan Serverlet dalam Java
 Melengkapkan algoritma untuk nombor negatif
Melengkapkan algoritma untuk nombor negatif
 Bagaimana untuk menyelesaikan masalah yang kod js tidak boleh dijalankan selepas pemformatan
Bagaimana untuk menyelesaikan masalah yang kod js tidak boleh dijalankan selepas pemformatan
 Mana yang lebih berbaloi untuk dipelajari, bahasa c atau python?
Mana yang lebih berbaloi untuk dipelajari, bahasa c atau python?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



