Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Richard Sutton membuat penilaian ini dalam "The Bitter Lesson": "Kesimpulan terbaik yang boleh dibuat daripada 70 tahun penyelidikan kecerdasan buatan ialah pengajaran penting ialah kaedah umum yang mengeksploitasi pengiraan akhirnya adalah yang paling cekap, dan kelebihannya adalah besar "Main diri adalah salah satu kaedah yang menggunakan kedua-dua carian dan pembelajaran untuk mengeksploitasi sepenuhnya dan meningkatkan pengiraan. . Pada awal tahun ini, pasukan Profesor Gu Quanquan di University of California, Los Angeles (UCLA) mencadangkan Self-Play Fine-Tuning, SPIN)
, yang tidak menggunakan data penalaan halus tambahan dan hanya bergantung pada permainan sendiri. Permainan boleh meningkatkan keupayaan LLM.
Baru-baru ini, pasukan Profesor Gu Quanquan dan pasukan Profesor Yiming Yang di Carnegie Mellon University (CMU) bekerjasama untuk membangunkan kaedah yang dipanggil "Self-Play Preference Optimization (SPPO)
" teknologi Penjajaran, kaedah baharu ini bertujuan untuk mengoptimumkan tingkah laku model bahasa besar melalui rangka kerja permainan kendiri untuk lebih sepadan dengan pilihan manusia. Lawan satu sama lain dari kiri ke kanan dan tunjukkan kuasa ajaib anda sekali lagi!
 Tajuk kertas: Pengoptimuman Keutamaan Main Kendiri untuk Penjajaran Model Bahasa
Tajuk kertas: Pengoptimuman Keutamaan Main Kendiri untuk Penjajaran Model Bahasa
- Pautan kertas: https://arxiv.org/pdf/2405.00675.00675.00675.00675 Teknologi Latar Belakang dan Cabaran
Model Bahasa Besar (LLM) menjadi daya penggerak penting dalam bidang kecerdasan buatan, berprestasi baik dalam pelbagai tugas dengan penjanaan teks yang cemerlang dan keupayaan pemahaman mereka. Walaupun keupayaan LLM mengagumkan, menjadikan gelagat output model ini lebih konsisten dengan keperluan aplikasi praktikal selalunya memerlukan penalaan halus melalui proses penjajaran.
Kunci kepada proses ini adalah untuk melaraskan model agar lebih mencerminkan keutamaan manusia dan norma tingkah laku. Kaedah biasa termasuk pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF) atau pengoptimuman keutamaan langsung (Pengoptimuman Keutamaan Langsung, DPO). Pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF) bergantung pada pengekalan model ganjaran secara eksplisit untuk melaras dan memperhalusi model bahasa yang besar. Dalam erti kata lain, sebagai contoh, InstructGPT mula-mula melatih fungsi ganjaran yang mematuhi model Bradley-Terry berdasarkan data keutamaan manusia, dan kemudian menggunakan algoritma pembelajaran pengukuhan seperti Pengoptimuman Dasar Proksimal (PPO) untuk mengoptimumkan model bahasa yang besar. Tahun lepas, penyelidik mencadangkan Pengoptimuman Keutamaan Langsung (DPO).
Tidak seperti RLHF, yang mengekalkan model ganjaran eksplisit, algoritma DPO secara tersirat mematuhi model Bradley-Terry, tetapi boleh digunakan terus untuk pengoptimuman model bahasa yang besar. Kerja sedia ada telah cuba memperhalusi model besar dengan menggunakan DPO melalui berbilang lelaran (Rajah 1).
Skor berangka. Walaupun model ini memberikan anggaran yang munasabah bagi keutamaan manusia, mereka gagal menangkap sepenuhnya kerumitan tingkah laku manusia.
Model ini sering mengandaikan bahawa hubungan keutamaan antara pilihan yang berbeza adalah monotonik dan transitif, manakala bukti empirikal sering menunjukkan ketidakkonsistenan dan ketidaklinieran dalam membuat keputusan manusia Sebagai contoh, kajian Tversky mendapati bahawa pembuatan keputusan manusia mungkin terjejas oleh Pelbagai faktor mempengaruhinya dan menunjukkan ketidakkonsistenan. 
Asas teori dan kaedah SPPO
两 Rajah 2. Dua model bahasa khayalan sering dimainkan dan dimainkan.
Dalam konteks ini, penulis mencadangkan rangka kerja permainan kendiri baharu SPPO, yang bukan sahaja mempunyai jaminan yang boleh dibuktikan untuk menyelesaikan permainan jumlah tetap dua pemain, tetapi juga memperhalusi model bahasa besar dengan cekap yang skala kepada skala besar.
Secara khusus, artikel itu dengan tegas mentakrifkan masalah RLHF sebagai permainan jumlah biasa dua pemain (Rajah 2). Matlamat kerja ini adalah untuk mengenal pasti strategi keseimbangan Nash yang, secara purata, sentiasa memberikan respons yang lebih diutamakan daripada mana-mana strategi lain.
Untuk mengenal pasti strategi keseimbangan Nash, penulis menggunakan algoritma penyesuaian dalam talian klasik dengan pemberat darab sebagai algoritma rangka kerja peringkat tinggi untuk menyelesaikan permainan dua pemain.
Dalam setiap langkah rangka kerja ini, algoritma boleh menganggarkan kemas kini berat berganda melalui mekanisme permainan kendiri, di mana dalam setiap pusingan, model bahasa besar menyesuaikan diri dengan pusingan sebelumnya, yang dihasilkan oleh model Synthesize data dan anotasi model keutamaan untuk pengoptimuman.
Secara khusus, model bahasa yang besar akan menjana beberapa respons untuk setiap gesaan dalam setiap pusingan berdasarkan anotasi model keutamaan, algoritma boleh menganggarkan kadar kemenangan setiap balasan dengan itu boleh diperhalusi model bahasa yang besar itu menjadikan balasan dengan kadar kemenangan yang tinggi mempunyai kebarangkalian yang lebih tinggi untuk muncul (Rajah 3).

Reka bentuk dan keputusan eksperimen , pasukan penyelidik mengguna pakai Mistral-7B sebagai model asas dan menggunakan 60,000 gesaan daripada dataset UltraFeedback untuk latihan tanpa pengawasan. Mereka mendapati bahawa melalui permainan sendiri, model itu dapat meningkatkan prestasinya dengan ketara pada berbilang platform penilaian, seperti AlpacaEval 2.0 dan MT-Bench. Platform ini digunakan secara meluas untuk menilai kualiti dan kaitan teks yang dijana model. . O Rajah 4. Kesan model sppo pada Alpacaeval 2.0 bertambah baik dengan ketara, dan ia lebih tinggi daripada kaedah penanda aras lain seperti ITERATIVE DPO.
Dalam ujian AlpacaEval 2.0 (Rajah 4), model yang dioptimumkan SPPO meningkatkan kadar kemenangan kawalan panjang daripada 17.11% model garis dasar kepada 28.53%, menunjukkan peningkatan yang ketara dalam pemahamannya tentang keutamaan manusia . Model yang dioptimumkan oleh tiga pusingan SPPO adalah jauh lebih baik daripada lelaran berbilang pusingan DPO, IPO dan model bahasa ganjaran diri (Self-Rewarding LM) pada AlpacaEval2.0. Selain itu, prestasi model di MT-Bench juga melebihi model tradisional yang ditala melalui maklum balas manusia. Ini menunjukkan keberkesanan SPPO dalam menyesuaikan tingkah laku model secara automatik kepada tugas yang kompleks.
Kesimpulan dan prospek masa depan
Pengoptimuman keutamaan bermain sendiri (SPPO) menyediakan laluan pengoptimuman baharu untuk model bahasa besar, yang bukan sahaja meningkatkan kualiti penjanaan model, tetapi juga meningkatkan kualiti penjanaan model yang lebih penting. kualiti model yang sesuai dengan keutamaan manusia. 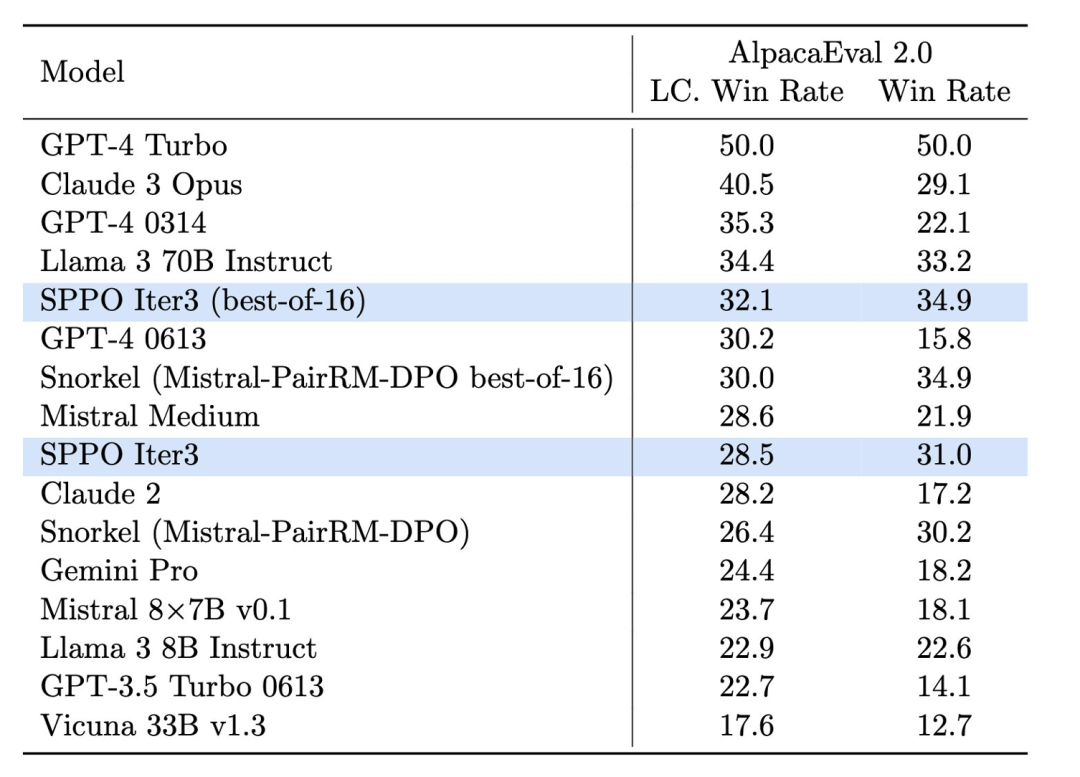 Dengan pembangunan berterusan dan pengoptimuman teknologi, diharapkan SPPO dan teknologi terbitannya akan memainkan peranan yang lebih besar dalam pembangunan mampan dan aplikasi sosial kecerdasan buatan, membuka jalan untuk membina sistem AI yang lebih pintar dan bertanggungjawab . Jalan.
Dengan pembangunan berterusan dan pengoptimuman teknologi, diharapkan SPPO dan teknologi terbitannya akan memainkan peranan yang lebih besar dalam pembangunan mampan dan aplikasi sosial kecerdasan buatan, membuka jalan untuk membina sistem AI yang lebih pintar dan bertanggungjawab . Jalan.
Atas ialah kandungan terperinci Keutamaan manusia adalah penguasa! Teknologi penjajaran SPPO membolehkan model bahasa besar bersaing antara satu sama lain dan bersaing dengan diri mereka sendiri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!




 Fungsi wizard pemacu Windows
Fungsi wizard pemacu Windows
 Kaedah pertanyaan nama domain peringkat kedua
Kaedah pertanyaan nama domain peringkat kedua
 Bagaimana untuk menyelesaikan kod ralat 8024401C
Bagaimana untuk menyelesaikan kod ralat 8024401C
 Bagaimana untuk membuka format ai dalam windows
Bagaimana untuk membuka format ai dalam windows
 Apakah yang dimaksudkan dengan rangkaian mesh?
Apakah yang dimaksudkan dengan rangkaian mesh?
 Perisian dagangan spot
Perisian dagangan spot
 Bagaimana untuk menggunakan fungsi norma dalam python
Bagaimana untuk menggunakan fungsi norma dalam python
 Bagaimana untuk memuat turun Binance
Bagaimana untuk memuat turun Binance





















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



