1. Rangka Kerja Keseluruhan

Tugas utama boleh dibahagikan kepada tiga kategori. Yang pertama ialah penemuan struktur sebab akibat, iaitu mengenal pasti hubungan sebab akibat antara pembolehubah daripada data. Yang kedua ialah anggaran kesan sebab akibat, iaitu membuat kesimpulan daripada data tahap pengaruh satu pembolehubah ke atas pembolehubah yang lain. Perlu diingat bahawa impak ini tidak merujuk kepada sifat relatif, tetapi kepada bagaimana nilai atau taburan pembolehubah lain berubah apabila satu pembolehubah diintervensi. Langkah terakhir ialah membetulkan bias, kerana dalam banyak tugas, pelbagai faktor boleh menyebabkan pengedaran sampel pembangunan dan sampel aplikasi berbeza. Dalam kes ini, inferens sebab boleh membantu kami membetulkan bias.
Fungsi ini sesuai untuk pelbagai senario, yang paling tipikal ialah senario membuat keputusan. Melalui inferens kausal, kami dapat memahami cara pengguna yang berbeza bertindak balas terhadap gelagat membuat keputusan kami. Kedua, dalam senario perindustrian, proses perniagaan selalunya kompleks dan panjang, yang membawa kepada bias data. Menghuraikan dengan jelas hubungan sebab-akibat penyelewengan ini melalui inferens sebab boleh membantu kita membetulkannya. Di samping itu, banyak senario meletakkan keperluan yang tinggi pada keteguhan model dan kebolehtafsiran. Model ini diharapkan dapat membuat ramalan berdasarkan hubungan sebab akibat, dan inferens sebab dapat membantu membina model penjelasan yang lebih berkuasa. Akhir sekali, penilaian kesan hasil membuat keputusan juga penting. Inferens sebab boleh membantu menganalisis dengan lebih baik kesan sebenar strategi.
Seterusnya, kami akan memperkenalkan dua isu penting dalam inferens sebab: cara menilai sama ada adegan sesuai untuk inferens sebab dan algoritma biasa dalam inferens sebab.
Pertama, adalah penting untuk menentukan sama ada senario sesuai untuk menggunakan inferens sebab-akibat. Inferens sebab-akibat biasanya digunakan untuk menyelesaikan masalah sebab-akibat, iaitu untuk membuat inferens hubungan antara sebab dan akibat melalui data yang diperhatikan. Oleh itu, apabila menilai sesuatu
2. Penilaian senario aplikasi (masalah membuat keputusan)
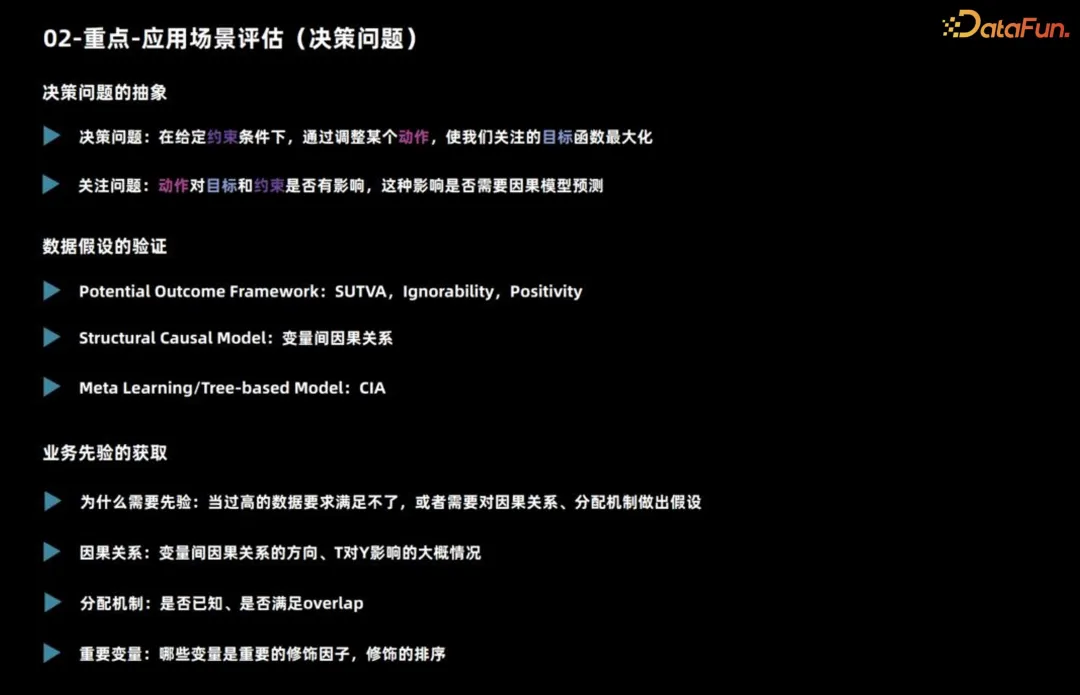
2. Penilaian senario aplikasi (masalah membuat keputusan)
🎜🎜 perkenalkan scenario adalah sesuai untuk ence terutamanya melibatkan masalah membuat keputusan. 🎜🎜🎜🎜 Berkenaan masalah membuat keputusan, anda perlu menjelaskan terlebih dahulu apa itu, iaitu tindakan yang perlu dibuat di bawah kekangan apa untuk memaksimumkan matlamat. Kemudian anda perlu mempertimbangkan sama ada tindakan ini mempunyai kesan ke atas matlamat dan kekangan, dan sama ada anda perlu menggunakan model inferens sebab untuk ramalan.
Sebagai contoh, apabila memasarkan produk, kami biasanya mempertimbangkan sama ada untuk mengeluarkan kupon atau diskaun kepada setiap pengguna berdasarkan jumlah belanjawan. Pertimbangkan memaksimumkan jualan sebagai matlamat keseluruhan. Jika tiada kekangan belanjawan, ia mungkin menjejaskan jualan akhir, tetapi selagi anda tahu bahawa ia adalah strategi ke hadapan, anda boleh memberikan diskaun kepada semua pengguna.
Dalam kes ini, walaupun tindakan keputusan memberi kesan kepada sasaran, tidak perlu menggunakan model inferens sebab untuk ramalan. 🎜🎜🎜🎜Di atas adalah analisis asas masalah membuat keputusan Selain itu, adalah perlu untuk memerhati sama ada item data berpuas hati. Untuk membina model kausal, algoritma kausal yang berbeza mempunyai keperluan yang berbeza untuk data dan andaian tugas. 🎜🎜
- Model kelas hasil yang berpotensi mempunyai tiga andaian utama. Pertama, kesan penyebab individu mestilah stabil Contohnya, apabila meneroka kesan pengeluaran kupon terhadap kebarangkalian pembelian pengguna, adalah perlu untuk memastikan bahawa tingkah laku pengguna tidak dipengaruhi oleh pengguna lain, seperti perbandingan harga luar talian atau terjejas. dengan kupon dengan diskaun berbeza. Andaian kedua ialah pemprosesan sebenar pengguna dan hasil yang berpotensi adalah bebas memandangkan keadaan ciri, yang boleh digunakan untuk menangani kekeliruan yang tidak diperhatikan. Hipotesis ketiga adalah mengenai pertindihan, iaitu, mana-mana jenis pengguna harus membuat keputusan yang berbeza, jika tidak prestasi pengguna jenis ini di bawah keputusan yang berbeza tidak dapat diperhatikan.
- Andaian utama yang dihadapi oleh model penyebab struktur ialah hubungan sebab akibat antara pembolehubah, dan andaian ini selalunya sukar untuk dibuktikan. Apabila menggunakan pembelajaran Meta dan kaedah berasaskan pokok, andaian biasanya adalah kebebasan bersyarat, iaitu, ciri yang diberikan, tindakan keputusan dan hasil yang berpotensi adalah bebas. Andaian ini sama dengan andaian kemerdekaan yang disebutkan sebelum ini.
Dalam senario perniagaan sebenar, memahami pengetahuan sedia ada adalah penting. Pertama, seseorang perlu memahami mekanisme pengagihan data pemerhatian sebenar, yang merupakan asas untuk keputusan sebelumnya. Apabila data yang paling tepat tidak tersedia, mungkin perlu bergantung pada andaian untuk membuat inferens. Kedua, pengalaman perniagaan boleh membimbing kita dalam menentukan pembolehubah yang mempunyai kesan yang ketara ke atas membezakan kesan penyebab, yang penting untuk kejuruteraan ciri. Oleh itu, apabila berurusan dengan perniagaan sebenar, digabungkan dengan mekanisme pengedaran data pemerhatian dan pengalaman perniagaan, kami dapat mengatasi cabaran dengan lebih baik dan melaksanakan pembuatan keputusan dan kejuruteraan ciri dengan lebih berkesan.
3. Algoritma penyebab biasa

Isu kedua penting ialah pemilihan algoritma inferens sebab.
Yang pertama ialah algoritma penemuan struktur sebab. Matlamat teras algoritma ini adalah untuk menentukan hubungan sebab akibat antara pembolehubah. Idea penyelidikan utama boleh dibahagikan kepada tiga kategori. Jenis kaedah pertama ialah menilai berdasarkan ciri-ciri kebebasan bersyarat bagi rangkaian nod dalam graf sebab akibat. Pendekatan lain ialah mentakrifkan fungsi pemarkahan untuk mengukur kualiti rajah sebab akibat. Contohnya, dengan mentakrifkan fungsi kemungkinan, graf akiklik terarah yang memaksimumkan fungsi dicari dan digunakan sebagai graf sebab akibat. Kaedah jenis ketiga memperkenalkan lebih banyak maklumat. Sebagai contoh, anggap bahawa proses penjanaan data sebenar untuk dua pembolehubah mengikut jenis n m, model hingar tambahan, dan kemudian selesaikan arah sebab akibat antara dua pembolehubah.
Anggaran kesan sebab melibatkan pelbagai algoritma Berikut ialah beberapa algoritma biasa:
- Yang pertama ialah kaedah pembolehubah instrumental, kaedah melakukan dan kaedah kawalan sintetik yang sering disebut dalam ekonometrik. Idea teras kaedah pembolehubah instrumental adalah untuk mencari pembolehubah yang berkaitan dengan rawatan tetapi tidak berkaitan dengan istilah ralat rawak, iaitu pembolehubah instrumental. Pada masa ini, hubungan antara pembolehubah instrumental dan pembolehubah bersandar tidak dipengaruhi oleh pengeliruan Ramalan boleh dibahagikan kepada dua peringkat: pertama, gunakan pembolehubah instrumental untuk meramal pembolehubah rawatan, dan kemudian gunakan pembolehubah rawatan yang diramalkan untuk meramal. pembolehubah bersandar. Pekali regresi yang diperoleh ialah: ialah kesan rawatan purata (ATE). Kaedah JPS dan undang-undang kawalan sintetik ialah kaedah yang direka untuk data panel, tetapi tidak akan diperkenalkan secara terperinci di sini.
- Satu lagi pendekatan biasa ialah menggunakan skor kecenderungan untuk menganggarkan kesan penyebab. Teras kaedah ini adalah untuk meramalkan mekanisme peruntukan tersembunyi, seperti kebarangkalian mengeluarkan kupon berbanding tidak mengeluarkan kupon. Jika dua pengguna mempunyai kebarangkalian yang sama untuk mengeluarkan kupon, tetapi seorang pengguna benar-benar menerima kupon dan yang lain tidak, maka kami boleh menganggap kedua-dua pengguna itu adalah setara dari segi mekanisme pengedaran, dan oleh itu kesannya boleh dibandingkan . Berdasarkan ini, satu siri kaedah boleh digeneralisasikan, termasuk kaedah padanan, kaedah hierarki, kaedah pemberat, dsb.
- Kaedah lain ialah meramalkan hasilnya secara terus. Walaupun dengan kehadiran pengacau yang tidak diperhatikan, hasilnya boleh diramalkan secara langsung melalui andaian dan diselaraskan secara automatik melalui model. Walau bagaimanapun, pendekatan ini mungkin menimbulkan persoalan: Jika meramalkan secara langsung hasilnya sudah mencukupi, adakah masalah itu hilang? Sebenarnya, tidak begitu.
- Yang keempat ialah idea menggabungkan skor kecenderungan dan hasil yang berpotensi, menggunakan kaedah pembelajaran mesin dwi teguh dan dwi mungkin lebih tepat. Dwi keteguhan dan pembelajaran mesin dwi memberikan jaminan berganda dengan menggabungkan dua kaedah, di mana ketepatan mana-mana bahagian memastikan kebolehpercayaan hasil akhir.
- Kaedah lain ialah model kausal struktur, yang membina model berdasarkan hubungan sebab-akibat, seperti rajah sebab-akibat atau persamaan berstruktur. Pendekatan ini membolehkan campur tangan langsung pembolehubah untuk mendapatkan hasil, serta inferens kontrafaktual. Walau bagaimanapun, pendekatan ini menganggap bahawa kita sudah mengetahui hubungan sebab akibat antara pembolehubah, yang selalunya merupakan andaian mewah.
- Kaedah pembelajaran meta ialah kaedah pembelajaran penting yang merangkumi pelbagai kategori. Salah satunya ialah S-learning, yang menganggap kaedah pemprosesan sebagai ciri dan menyuapkannya terus ke dalam model. Dengan melaraskan ciri ini, kita boleh melihat perubahan dalam hasil di bawah kaedah pemprosesan yang berbeza. Pendekatan ini kadangkala dipanggil pelajar model tunggal kerana kami membina model untuk setiap kumpulan eksperimen dan kawalan dan kemudian mengubah suai ciri untuk memerhatikan keputusan. Kaedah lain ialah X-learning, yang prosesnya serupa dengan S-learning, tetapi juga mempertimbangkan langkah pengesahan silang untuk menilai prestasi model dengan lebih tepat.
- Kaedah pokok ialah kaedah intuitif dan mudah yang membahagikan sampel dengan membina struktur pokok untuk memaksimumkan perbezaan kesan sebab akibat pada nod kiri dan kanan. Walau bagaimanapun, kaedah ini terdedah kepada overfitting, jadi dalam amalan kaedah seperti hutan rawak sering digunakan untuk mengurangkan risiko overfitting. Menggunakan kaedah penggalak boleh meningkatkan cabaran kerana lebih mudah untuk menapis beberapa maklumat, jadi model yang lebih kompleks perlu direka bentuk untuk mengelakkan kehilangan maklumat apabila digunakan. Kaedah pembelajaran meta dan algoritma berasaskan pokok juga sering dipanggil model Uplift.
- Perwakilan sebab merupakan salah satu bidang yang telah mencapai keputusan tertentu dalam bidang akademik sejak beberapa tahun kebelakangan ini. Kaedah ini berusaha untuk memisahkan modul yang berbeza dan mengasingkan faktor yang mempengaruhi untuk mengenal pasti faktor yang mengelirukan dengan lebih tepat. Dengan menganalisis faktor-faktor yang mempengaruhi pembolehubah bersandar y dan pembolehubah rawatan (rawatan), kita boleh mengenal pasti faktor pengacau yang boleh mempengaruhi y dan rawatan Faktor ini dipanggil faktor pengacau. Kaedah ini dijangka dapat meningkatkan kesan pembelajaran hujung ke hujung model. Ambil skor kecenderungan, sebagai contoh, yang sering melakukan kerja yang sangat baik untuk menangani faktor yang mengelirukan. Walau bagaimanapun, ketepatan skor kecenderungan yang berlebihan kadangkala tidak menguntungkan. Di bawah skor kecenderungan yang sama, mungkin terdapat situasi di mana andaian pertindihan tidak dapat dipenuhi, kerana skor kecenderungan mungkin mengandungi beberapa maklumat yang berkaitan dengan faktor yang mengelirukan tetapi tidak menjejaskan y. Apabila model belajar terlalu tepat, ia mungkin membawa kepada ralat yang lebih besar semasa padanan wajaran atau pemprosesan hierarki. Kesilapan ini sebenarnya tidak disebabkan oleh faktor yang mengelirukan dan oleh itu tidak perlu dipertimbangkan. Kaedah pembelajaran perwakilan sebab menyediakan cara untuk menyelesaikan masalah ini dan boleh mengendalikan pengenalpastian dan analisis hubungan sebab akibat dengan lebih berkesan.
4. Kesukaran dalam pelaksanaan sebenar inferens sebab
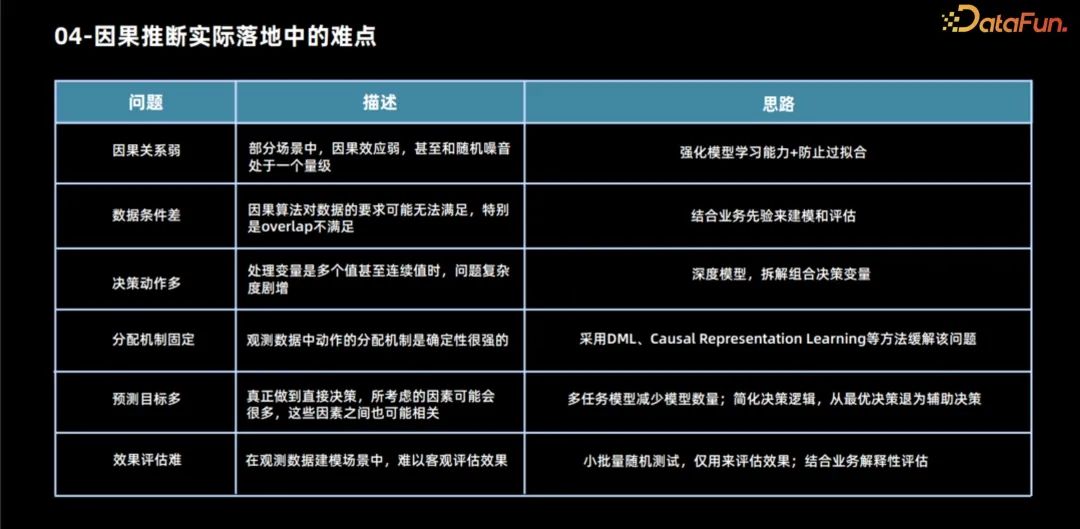
Inferens sebab menghadapi banyak cabaran dalam aplikasi praktikal.
- Lemahnya hubungan sebab musabab. Dalam banyak senario, perhubungan kausal selalunya dalam susunan yang sama seperti turun naik rawak dalam hingar, yang menimbulkan cabaran besar kepada usaha pemodelan. Dalam kes ini, faedah pemodelan agak rendah kerana hubungan sebab akibat itu sendiri tidak jelas. Walau bagaimanapun, walaupun pemodelan diperlukan, model dengan keupayaan pembelajaran yang lebih kukuh akan diperlukan untuk menangkap hubungan sebab akibat yang lemah ini dengan tepat. Pada masa yang sama, perhatian khusus perlu diberikan kepada masalah overfitting, kerana model yang mempunyai keupayaan pembelajaran yang kuat mungkin lebih terdedah kepada hingar, menyebabkan model overfit data.
- Masalah biasa kedua ialah keadaan data yang tidak mencukupi. Skop masalah ini agak luas, terutamanya kerana andaian algoritma yang kami gunakan mempunyai banyak kekurangan, terutamanya apabila menggunakan data pemerhatian untuk pemodelan, andaian kami mungkin tidak benar sepenuhnya. Masalah yang paling tipikal termasuk andaian pertindihan mungkin tidak dipenuhi dan mekanisme peruntukan kami mungkin kurang rawak. Masalah yang lebih serius ialah kami tidak mempunyai data ujian rawak yang mencukupi, yang menjadikannya sukar untuk menilai prestasi model secara objektif. Dalam kes ini, jika kami masih berkeras untuk membuat pemodelan dan prestasi model lebih baik daripada peraturan tahun ke tahun, kami boleh menggunakan beberapa pengalaman perniagaan untuk menilai sama ada keputusan model itu munasabah. Dari perspektif perniagaan, tiada penyelesaian teori yang sangat baik untuk situasi di mana beberapa andaian tidak berlaku, seperti faktor pengacau yang tidak diperhatikan Walau bagaimanapun, jika anda mesti menggunakan model, anda boleh cuba menjalankan beberapa simulasi rawak berskala kecil berdasarkan perniagaan pengalaman atau Ujian untuk menilai arah dan magnitud pengaruh faktor yang mengelirukan. Pada masa yang sama, mengambil kira faktor-faktor ini dalam model, untuk situasi di mana andaian bertindih tidak dipenuhi, walaupun ini adalah isu keempat dalam penghitungan kami kemudian, kami akan membincangkannya bersama di sini. Kami boleh menggunakan beberapa algoritma untuk mengecualikan beberapa mekanisme peruntukan.
- Apabila menangani kerumitan ini, tindakan membuat keputusan amat penting. Banyak model sedia ada memberi tumpuan kepada menyelesaikan masalah binari Walau bagaimanapun, apabila pelbagai penyelesaian pemprosesan terlibat, cara memperuntukkan sumber menjadi masalah yang lebih kompleks. Untuk menangani cabaran ini, kami boleh menguraikan berbilang penyelesaian pemprosesan kepada sub-masalah dalam bidang yang berbeza. Tambahan pula, menggunakan kaedah pembelajaran mendalam, kita boleh menganggap skim pemprosesan sebagai ciri dan menganggap bahawa terdapat beberapa hubungan fungsi antara skim pemprosesan berterusan dan hasil. Dengan mengoptimumkan parameter fungsi ini, masalah keputusan berterusan boleh diselesaikan dengan lebih baik, walau bagaimanapun, ini juga memperkenalkan beberapa andaian tambahan, seperti isu pertindihan.
- Mekanisme peruntukan ditetapkan. Lihat analisis di atas.
- Satu lagi masalah biasa ialah mempunyai banyak ramalan sasaran. Dalam sesetengah kes, ramalan sasaran dipengaruhi oleh pelbagai faktor, yang seterusnya dikaitkan dengan pilihan rawatan. Untuk menyelesaikan masalah ini, kami boleh menggunakan kaedah pembelajaran pelbagai tugas Walaupun mungkin sukar untuk menangani masalah peranan yang kompleks secara langsung, kami boleh memudahkan masalah dan hanya meramalkan penunjuk paling kritikal yang terjejas oleh pelan rawatan, secara beransur-ansur menyediakan. rujukan untuk membuat keputusan.
- Akhir sekali, kos ujian rawak dalam sesetengah senario adalah lebih tinggi, dan kitaran pemulihan kesan lebih lama. Ia amat penting untuk menilai sepenuhnya prestasi model sebelum ia ke dalam talian. Dalam kes ini, ujian rawak berskala kecil boleh digunakan untuk menilai keberkesanan. Walaupun set sampel yang diperlukan untuk menilai model adalah jauh lebih kecil daripada set sampel untuk pemodelan, jika ujian rawak berskala kecil pun tidak dapat dilakukan, maka kami mungkin hanya boleh menilai kemunasabahan keputusan keputusan model melalui kebolehtafsiran perniagaan.
5. Case - Model Had Kredit JD Teknologi Model membuat keputusan
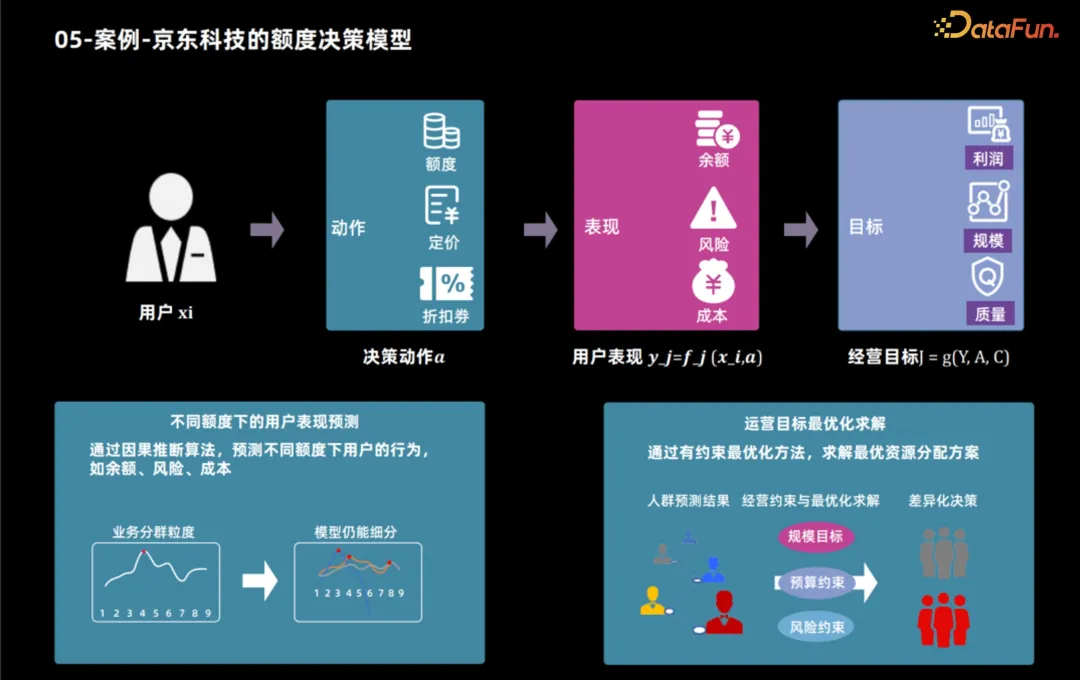
Seterusnya, kami akan mengambil aplikasi tambahan teknologi JD menggunakan teknologi kesimpulan kausal untuk merumuskan produk kredit sebagai contoh untuk menunjukkan cara menggunakan teknologi inferens sebab untuk merumuskan produk kredit Ciri-ciri pengguna dan objektif perniagaan menentukan had kredit yang optimum. Selepas matlamat perniagaan ditentukan, matlamat ini biasanya boleh dipecahkan kepada penunjuk prestasi pengguna, seperti penggunaan produk dan gelagat peminjaman pengguna. Dengan menganalisis penunjuk ini, matlamat perniagaan seperti keuntungan dan skala boleh dikira. Oleh itu, proses membuat keputusan had kredit dibahagikan kepada dua langkah: pertama, gunakan teknologi inferens sebab untuk meramal prestasi pengguna di bawah had kredit yang berbeza, dan kemudian menggunakan pelbagai kaedah untuk menentukan had kredit optimum untuk setiap pengguna berdasarkan prestasi ini dan matlamat operasi.
6. Pembangunan Masa Depan

Kami akan menghadapi beberapa siri cabaran dan peluang dalam pembangunan masa hadapan.
Pertama sekali, memandangkan kelemahan model kausal semasa, kalangan akademik umumnya percaya bahawa model berskala besar diperlukan untuk mengendalikan perhubungan tak linear yang lebih kompleks. Model kausal biasanya hanya berurusan dengan data dua dimensi, dan kebanyakan struktur model adalah agak mudah, jadi arahan penyelidikan masa depan mungkin termasuk menangani isu ini.
Kedua, penyelidik mencadangkan konsep pembelajaran perwakilan sebab, menekankan kepentingan penyahgandingan dan idea modular dalam pembelajaran perwakilan. Dengan memahami proses penjanaan data daripada perspektif kausal, model yang dibina berdasarkan undang-undang dunia sebenar berkemungkinan mempunyai keupayaan pemindahan dan generalisasi yang lebih baik.
Akhirnya, para penyelidik menegaskan bahawa andaian semasa terlalu kuat dan tidak dapat memenuhi keperluan sebenar dalam banyak kes, jadi model yang berbeza perlu diguna pakai untuk senario yang berbeza. Ini juga menghasilkan ambang yang sangat tinggi untuk pelaksanaan model. Oleh itu, adalah sangat bernilai untuk mencari algoritma minyak ular serba boleh.
Atas ialah kandungan terperinci Fokus padanya! ! Analisis dua rangka kerja algoritma utama untuk inferens sebab. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Algoritma penggantian halaman
Algoritma penggantian halaman
 kata laluan wifi
kata laluan wifi
 Bagaimana untuk memadam fail dalam linux
Bagaimana untuk memadam fail dalam linux
 Bagaimana untuk menjumlahkan tatasusunan tiga dimensi dalam php
Bagaimana untuk menjumlahkan tatasusunan tiga dimensi dalam php
 python menggabungkan dua senarai
python menggabungkan dua senarai
 Sebab mengapa skrin sentuh telefon bimbit gagal
Sebab mengapa skrin sentuh telefon bimbit gagal
 Bagaimana untuk menyelesaikan masalah yang nilai pulangan scanf diabaikan
Bagaimana untuk menyelesaikan masalah yang nilai pulangan scanf diabaikan
 Cara memuat turun dan menyimpan video tajuk hari ini
Cara memuat turun dan menyimpan video tajuk hari ini








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



