



目前的一个明显趋势是致力于构建更大更复杂的模型,这些模型拥有数百/数千亿个参数,能够生成令人印象深刻的语言输出
然而,现有的大型语言模型主要集中在文本信息上,无法理解视觉信息。
因此多模态大型语言模型(MLLMs)领域的进展旨在解决这一限制,MLLMs将视觉和文本信息融合到一个基于Transformer的单一模型中,使该模型能够根据这两种模态学习和生成内容。
MLLMs在各种实际应用中显示出潜力,包括自然图像理解和文本图像理解。这些模型利用语言建模作为处理多模态问题的通用接口,使其能够根据文本和视觉输入处理和生成响应
然而,目前主要关注分辨率较低的自然图像的MLLMs,对于文本密集图像的研究还相对较少。因此,充分利用大规模多模态预训练来处理文本图像成为MLLM研究的一个重要方向
通过将文本图像纳入训练过程并开发基于文本和视觉信息的模型,我们可以开辟涉及高分辨率文本密集图像的多模态应用的新可能性。
 图片
图片
论文地址:https://arxiv.org/abs/2309.11419
KOSMOS-2.5是一个基于文本密集图像的多模态大型语言模型,它是在KOSMOS-2的基础上发展而来的,突出了对于文本密集图像的多模态阅读和理解能力(Multimodal Literate Model)。
该模型的提出凸显了其在理解文本密集型图像方面的卓越性能,弥合了视觉和文本之间的差距
同时,这也标志着任务范式的演变,从以前的编码器-解码器架构转变为纯解码器架构
KOSMOS-2.5的目标是在文本丰富的图像中实现无缝的视觉和文本数据处理,以便理解图像内容并生成结构化文本描述。
 图1:KOSMOS-2.5概览图
图1:KOSMOS-2.5概览图
KOSMOS-2.5是一个多模态模型,如图1所示,它的目标是使用统一的框架来处理两个紧密相关的任务
第一个任务涉及生成具有空间感知的文本块,即同时生成文本块的内容与坐标框。 需要被改写的内容是:第一个任务涉及生成具有空间感知的文本块,即同时生成文本块的内容与坐标框
第二项任务涉及使用Markdown格式生成结构化的文本输出,并捕捉各种样式和结构
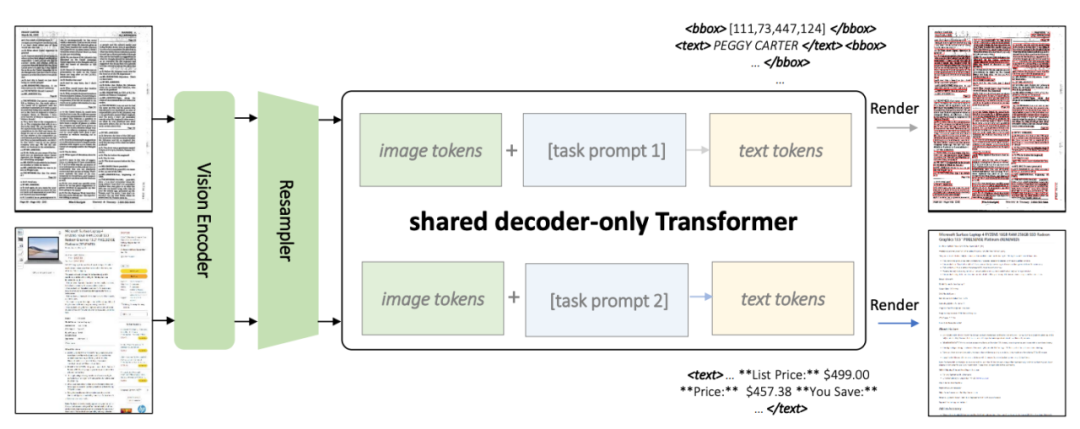 图2:KOSMOS-2.5架构图
图2:KOSMOS-2.5架构图
根据图2所示,两个任务都使用了共享的Transformer架构和任务特定的提示
KOSMOS-2.5将基于ViT(Vision Transformer)的视觉编码器与基于Transformer架构的解码器相结合,通过一个重采样模块连接起来。
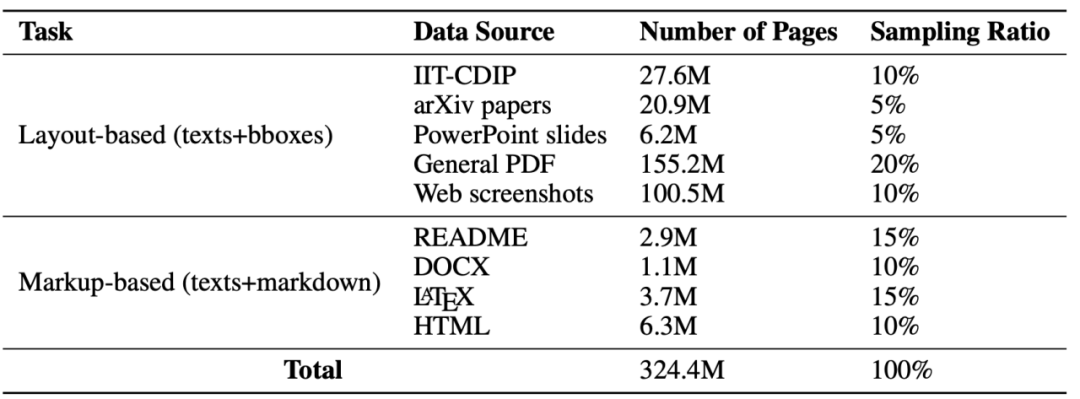 图3:预训练数据集
图3:预训练数据集
为了训练这个模型,作者准备了一个庞大的数据集,其大小达到了324.4M,如图3所示
 图4:带有边界框的文本行的训练样本示例
图4:带有边界框的文本行的训练样本示例
 图5:Markdown格式的训练样本示例
图5:Markdown格式的训练样本示例
该数据集包含各种类型的文本密集图像,其中包括带有边界框的文本行和纯文本的Markdown格式,图4和图5为训练样本示例可视化。
这种多任务训练方法提高了KOSMOS-2.5在整体上的多模态能力
 [图6] 端到端的文档级文本识别实验
[图6] 端到端的文档级文本识别实验
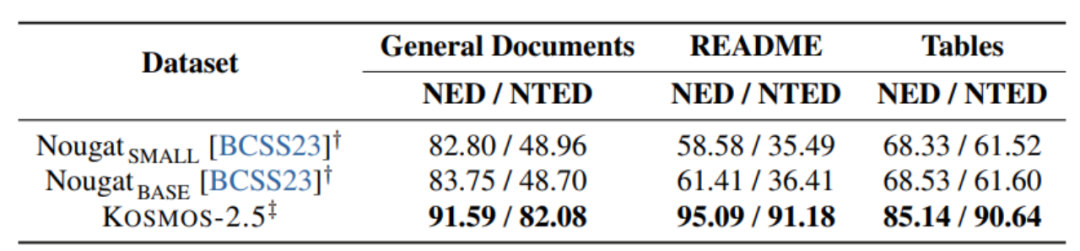 图7:从图像中生成Markdown格式文本实验
图7:从图像中生成Markdown格式文本实验
如图6和图7所示,KOSMOS-2.5在两个任务上进行评估:端到端的文档级文本识别和从图像中生成Markdown格式文本。
KOSMOS-2.5在处理文本密集的图像任务方面表现出色,实验结果展示了这一点
 图8:KOSMOS-2.5的输入和输出样例展示
图8:KOSMOS-2.5的输入和输出样例展示
KOSMOS-2.5在少样本学习和零样本学习的场景中展现了有前景的能力,使其成为处理文本丰富图像的实际应用的多功能工具。可以将其视为一种多功能工具,能够有效处理文本丰富的图像,并在少样本学习和零样本学习的情况下展现出有前景的能力
作者指出,指令微调是一个很有前景的方法,可以实现模型更广泛的应用能力。
在更广泛的研究领域中,一个重要的方向在于进一步发展模型参数的扩展能力。
随着任务范围的不断扩大和复杂性的不断提高,扩展模型以处理更大量的数据对于文字密集的多模态模型的发展至关重要。
最终目标是开发出一种能有效解释视觉和文本数据的模型,并在更多文本密集型多模态任务中顺利推广。
重写内容时,需要将其改写成中文,不需要出现原句
https://arxiv.org/abs/2309.11419
以上就是文档字越多,模型越兴奋!KOSMOS-2.5:阅读「文本密集图像」的多模态大语言模型的详细内容,更多请关注php中文网其它相关文章!