

정량화, 가지치기, 증류 등 대규모 언어 모델에 자주 주의를 기울이면 이러한 단어를 확실히 볼 수 있습니다. 이 단어만 보면 무엇을 하는지 이해하기 어렵지만 이 단어는 특히 중요합니다. 이 단계에서 대규모 언어 모델을 개발하는 데 도움이 됩니다. 이 기사는 당신이 그것들을 알고 그 원리를 이해하는 데 도움이 될 것입니다.
양자화, 가지치기, 증류는 실제로 일반적인 신경망 모델 압축 기술이며 대규모 언어 모델에만 국한되지 않습니다.
압축 후 모델 파일이 작아지고, 사용되는 하드 디스크 공간도 작아지며, 메모리에 로드하거나 표시할 때 사용되는 캐시 공간도 작아지고, 모델의 실행도 작아질 수 있으며 일부 속도도 향상될 수 있습니다. ㅋㅋㅋ
압축이란 무엇인가요?
현재 머신러닝이 신경망 모델을 사용한다는 말을 들어보셨을 것입니다. 신경망 모델은 인간 두뇌의 신경망을 시뮬레이션합니다.
여기에 간단한 다이어그램을 그렸으니 한 번 살펴보세요.
Pictures
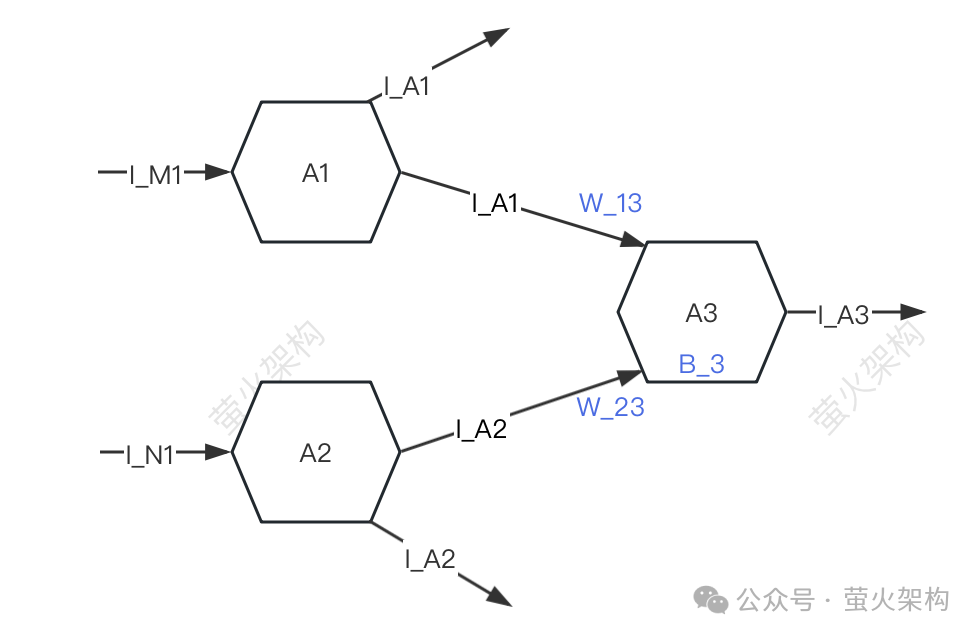 단순화를 위해 A1, A2, A3의 세 가지 뉴런만 설명합니다. 각 뉴런은 다른 뉴런으로부터 신호를 받고 다른 뉴런으로 신호를 전달합니다.
단순화를 위해 A1, A2, A3의 세 가지 뉴런만 설명합니다. 각 뉴런은 다른 뉴런으로부터 신호를 받고 다른 뉴런으로 신호를 전달합니다.
A3은 A1과 A2로부터 I_A1과 I_A2 신호를 수신하지만 A1과 A2로부터 A3이 수신한 신호의 강도는 다릅니다(이 강도를 "무게"라고 함). 여기서 강도는 W_13이고 W_23, A3은 수신된 신호 데이터를 각각 처리합니다.
먼저 신호의 가중 합산, 즉 I_A1*W_13+I_A2*W_23을 수행합니다.
대규모 언어 모델을 사용하여 텍스트를 생성하는 경우 이러한 매개변수는 이미 사전 훈련되어 있으므로 수정할 수 없습니다. 이는 수학에서 알 수 없는 xyz만 전달하고 출력 결과를 얻을 수 있는 것과 같습니다. .
모델 압축은 모델의 이러한 매개 변수를 압축하는 것입니다. 주요 고려 사항은 가중치와 편향입니다. 사용되는 구체적인 방법은 이 기사의 초점입니다.
Quantization
레시피를 따르는 것과 같습니다. 각 재료의 무게를 결정해야 합니다. 0.01그램까지 정확한 전자저울을 사용할 수 있는데, 각 재료의 무게를 매우 정확하게 알 수 있어 좋습니다. 하지만 단지 포트럭 식사를 할 뿐이고 실제로 그렇게 높은 정확도가 필요하지 않다면 최소 1그램의 저울로 간단하고 저렴한 저울을 사용할 수 있는데, 이는 정확하지는 않지만 맛있는 식사를 만들기에는 충분합니다. 저녁.
Pictures
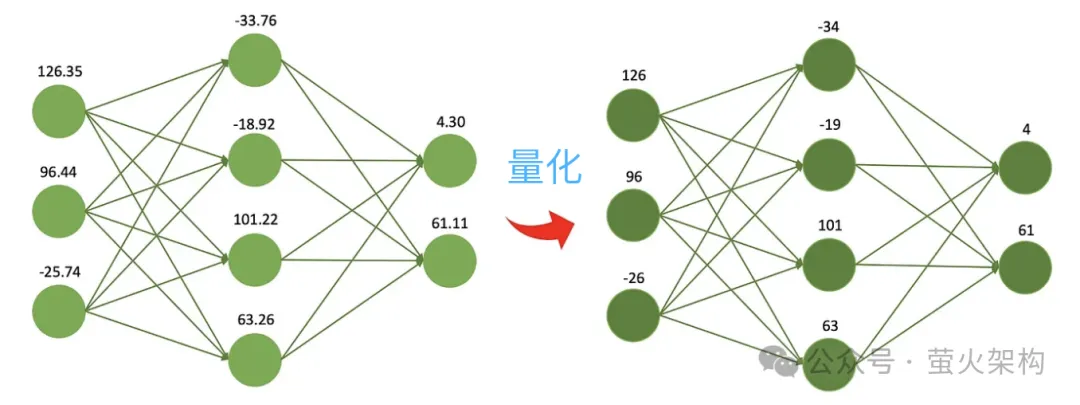 양자화의 또 다른 이점은 계산 속도가 더 빠르다는 것입니다. 최신 프로세서에는 일반적으로 정밀도가 낮은 벡터 계산 장치가 많이 포함되어 있습니다. 모델은 이러한 하드웨어 기능을 최대한 활용하여 더 많은 병렬 작업을 수행할 수 있으며 일반적으로 정밀도가 낮은 작업이 고정밀 작업보다 빠릅니다. 단일 곱셈과 덧셈의 소비는 시간이 더 짧습니다. 이러한 이점을 통해 모델은 고성능 GPU가 없는 일반 사무실이나 가정용 컴퓨터, 휴대폰 및 기타 모바일 단말기와 같은 낮은 구성의 컴퓨터에서도 실행할 수 있습니다.
양자화의 또 다른 이점은 계산 속도가 더 빠르다는 것입니다. 최신 프로세서에는 일반적으로 정밀도가 낮은 벡터 계산 장치가 많이 포함되어 있습니다. 모델은 이러한 하드웨어 기능을 최대한 활용하여 더 많은 병렬 작업을 수행할 수 있으며 일반적으로 정밀도가 낮은 작업이 고정밀 작업보다 빠릅니다. 단일 곱셈과 덧셈의 소비는 시간이 더 짧습니다. 이러한 이점을 통해 모델은 고성능 GPU가 없는 일반 사무실이나 가정용 컴퓨터, 휴대폰 및 기타 모바일 단말기와 같은 낮은 구성의 컴퓨터에서도 실행할 수 있습니다.
이 아이디어에 따라 사람들은 크기가 더 작고 컴퓨팅 리소스를 덜 사용하는 8비트, 4비트, 2비트 모델을 계속해서 압축합니다. 그러나 가중치의 정확도가 감소함에 따라 서로 다른 가중치의 값이 더 가까워지거나 심지어 동일해지며, 이로 인해 모델 출력의 정확성과 정밀도가 감소하고 모델의 성능도 다양한 정도로 저하됩니다.
양자화 기술에는 동적 양자화, 정적 양자화, 대칭 양자화, 비대칭 양자화 등과 같은 다양한 전략과 기술적 세부 사항이 있습니다. 대규모 언어 모델의 경우 일반적으로 모델 훈련이 완료된 후 정적 양자화 전략이 사용됩니다. 매개변수는 한 번 정량화되며, 모델 실행 시 더 이상 정량적 계산이 필요하지 않아 배포 및 배포가 쉽습니다.
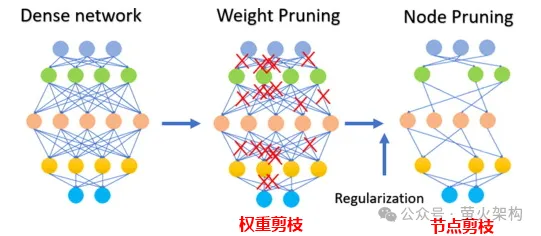
Pruning은 모델에서 중요하지 않거나 거의 사용되지 않는 가중치를 제거하는 작업입니다. 이러한 가중치의 값은 일반적으로 0에 가깝습니다. 일부 모델의 경우 가지치기를 통해 압축률이 높아져 모델이 더 작고 효율적으로 만들어질 수 있습니다. 이는 리소스가 제한된 장치에 모델을 배포하거나 메모리와 저장 공간이 제한된 경우에 특히 유용합니다.
가지치기는 모델의 해석 가능성도 향상시킵니다. 불필요한 구성요소를 제거함으로써 프루닝은 모델의 기본 구조를 더욱 투명하고 분석하기 쉽게 만듭니다. 이는 신경망과 같은 복잡한 모델의 의사결정 과정을 이해하는 데 중요합니다.
가지치기에는 가중치 매개변수 가지치기뿐만 아니라 다음 그림과 같이 특정 뉴런 노드 가지치기도 포함됩니다.
 Picture
Picture
가지치기는 모든 모델에 적합하지 않으며 일부 희소한 경우에는 적합하지 않습니다. 모델(대부분의 매개변수는 0이거나 0에 가까움), 가지치기는 상대적으로 적은 수의 매개변수를 갖는 일부 작은 모델의 경우 효과가 없을 수 있으며, 가지치기는 일부 고정밀 작업이나 응용 프로그램에 대해 모델 성능이 크게 저하될 수 있습니다. 의학적 진단과 같이 생사가 걸린 모델을 잘라내는 데는 적합하지 않습니다.
실제로 가지치기 기술을 적용할 때에는 일반적으로 모델 실행 속도의 향상과 가지치기가 모델 성능에 미치는 부정적인 영향을 종합적으로 고려하고 모델의 각 매개변수에 점수를 매기는 등 몇 가지 전략을 채택해야 합니다. 매개변수를 평가합니다. 모델 성능에 얼마나 기여합니까? 점수가 높은 항목은 잘라서는 안 되는 중요한 매개변수이고, 점수가 낮은 항목은 그다지 중요하지 않아 잘라낼 수 있는 항목입니다. 이 점수는 매개변수의 크기(절대값이 클수록 더 중요함)를 확인하는 등 다양한 방법을 통해 계산하거나 좀 더 복잡한 통계 분석 방법을 통해 결정할 수 있습니다.
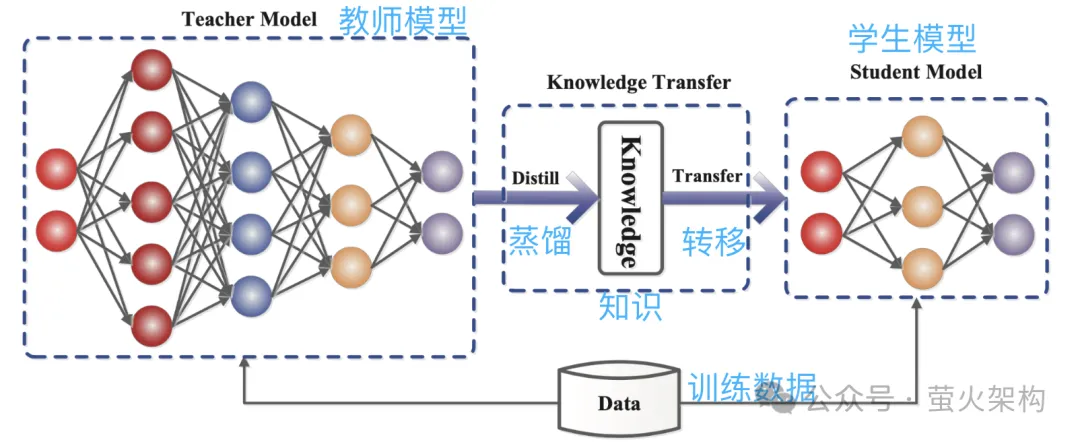
Distillation은 대형 모델에서 학습한 확률 분포를 소형 모델에 직접 복사하는 것입니다. 복사된 모델을 교사 모델이라고 하며 일반적으로 매개변수 수가 많고 성능이 뛰어난 우수한 모델입니다. 새 모델은 일반적으로 매개변수가 상대적으로 적은 작은 모델입니다.
증류 중에 교사 모델은 입력을 기반으로 여러 가능한 출력의 확률 분포를 생성한 다음 학생 모델은 이 입력 및 출력의 확률 분포를 학습합니다. 광범위한 훈련을 거친 후 학생 모델은 교사 모델의 행동을 모방하거나 교사 모델의 지식을 배울 수 있습니다.
예를 들어, 이미지 분류 작업에서 사진이 주어지면 교사 모델은 다음과 유사한 확률 분포를 출력할 수 있습니다.
이 그림과 출력 확률 분포 정보를 모방 학습을 위한 학생 모델에 제출합니다.
 Pictures
Pictures
증류는 교사 모델의 지식을 더 작고 단순한 학생 모델로 압축하기 때문에 새 모델은 일부 정보를 잃을 수도 있습니다. 또한 학생 모델은 교사 모델에 너무 많이 의존할 수 있습니다. 모델의 일반화 능력이 저하됩니다.
학생 모델의 학습 효과를 더 좋게 만들기 위해 몇 가지 방법과 전략을 사용할 수 있습니다.
온도 매개변수 소개: 매우 빠르게 가르치는 교사가 있고 정보 밀도가 매우 높다고 가정하면 학생들이 따라가기가 조금 어려울 수 있습니다. 이때 교사가 속도를 늦추고 정보를 단순화하면 학생들이 이해하기 더 쉬울 것입니다. 모델 증류에서 온도 매개변수는 학생 모델(소형 모델)이 교사 모델(대형 모델)의 지식을 더 잘 이해하고 학습할 수 있도록 '강의 속도 조정'과 유사한 역할을 합니다. 전문적으로 말하자면, 모델 출력을 보다 매끄러운 확률 분포로 만들어 학생 모델이 교사 모델의 출력 세부 사항을 더 쉽게 캡처하고 학습할 수 있도록 하는 것입니다.
교사 모델과 학생 모델의 구조 조정: 학생이 전문가로부터 무언가를 배우기가 어려울 수 있습니다. 전문가 사이의 지식 격차가 너무 커서 직접 학습이 이해되지 않을 수 있기 때문입니다. 전문가의 말을 이해하고 학생들이 이해할 수 있는 언어로 번역할 수 있는 교사를 중간에 추가하세요. 중간에 추가된 교사는 일부 중간 계층 또는 보조 신경망일 수 있으며, 교사는 교사 모델의 출력과 더 잘 일치할 수 있도록 학생 모델을 일부 조정할 수 있습니다.
위에서 세 가지 주요 모델 압축 기술을 소개했습니다. 사실 여기에는 아직 세부적인 내용이 많이 있지만, 하위 순위 분해와 같은 다른 모델 압축 기술도 거의 이해하기 충분합니다. 및 매개변수 공유, 희소 연결 등 관심 있는 학생들은 더 많은 관련 콘텐츠를 확인할 수 있습니다.
또한 모델을 압축한 후에는 성능이 크게 저하될 수 있습니다. 이때 특히 의료 진단, 재정적 위험과 같이 높은 모델 정확도가 필요한 작업의 경우 모델을 미세 조정할 수 있습니다. 제어, 자동 주행 등의 미세 조정을 통해 모델의 성능을 어느 정도 복원하고 특정 측면에서 정확도와 정밀도를 안정화할 수 있습니다.
모델 미세 조정에 관해 최근 AutoDL에서 Text Generation WebUI 이미지를 공유했습니다. Text Generation WebUI는 Gradio를 사용하여 작성된 웹 프로그램으로, 대규모 언어 모델의 추론 및 미세 조정을 쉽게 수행할 수 있으며 이를 지원합니다. Transformers, llama.cpp(GGUF), GPTQ, AWQ, EXL2 및 기타 다양한 형식의 모델을 포함한 다양한 유형의 대형 언어 모델 최신 이미지에는 최근 Meta에서 오픈소스로 공개된 Llama3 대형 모델이 내장되어 있습니다. . 관심 있는 학생 시도해 보고 사용 방법을 확인하세요. 10분 안에 대규모 언어 모델을 미세 조정하는 방법 알아보기
 Pictures
Pictures
참고 기사:
https:/ /m.sbmmt.com/link/d7852cd2408d9d3205dc75b59 a6ce22e
//m.sbmmt.com/link/f204aab71691a8e18c3f6f00872db63b
//m.sbmmt.com/link/b31f0c758bb498b5d56b5fea80 f313a7 ㅋㅋㅋ 7c59f92
위 내용은 정량화, 가지치기, 증류 등 이러한 대형 모델 속어는 정확히 무엇을 말합니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



