

소라의 기술적 분석이 전개되면서 AI 인프라의 중요성이 더욱 부각되고 있습니다.
이 시점에서 Byte와 Peking University의 새로운 논문이 주목을 받았습니다.
기사에서는 Byte가 구축한 Wanka 클러스터가 1.75일 ) 교육 내에 GPT-3 규모 모델 (175B)을 완료할 수 있다고 밝혔습니다. .
특히 Byte는 Wanka 클러스터에서 대형 모델을 훈련할 때 직면하는 효율성 및 안정성 문제를 해결하는 것을 목표로 하는 MegaScale이라는 생산 시스템을 제안했습니다.
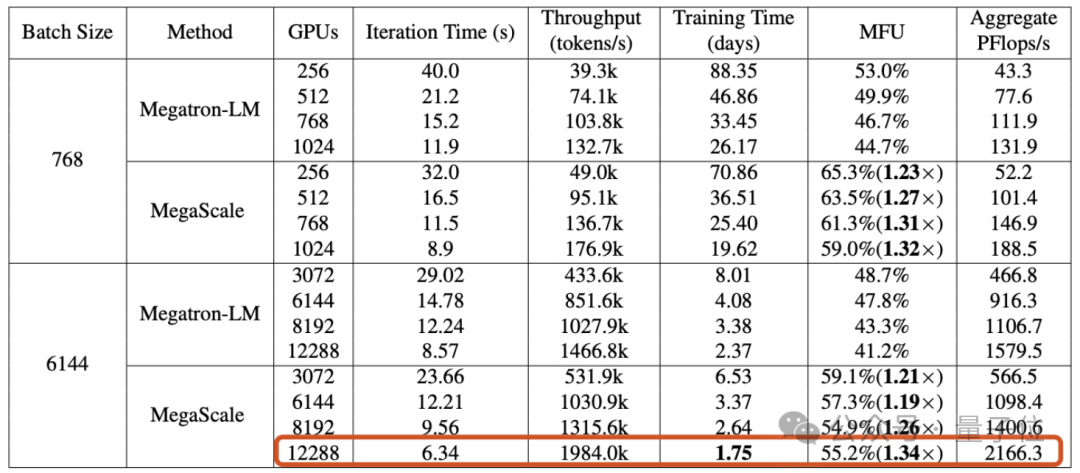
12288 GPU에서 1,750억 매개변수의 대규모 언어 모델을 훈련할 때 MegaScale은 NVIDIA Megatron-LM의 1.34배인 55.2% (MFU) 의 컴퓨팅 전력 활용률을 달성했습니다.
백서는 또한 2023년 9월 현재 바이트가 10,000개 이상의 카드를 갖춘 Ampere 아키텍처 GPU (A100/A800) 클러스터를 구축했으며 현재 대규모 Hopper 아키텍처 (H100/H800) 을 구축하고 있다고 밝혔습니다. 무리. .
대형 모델 시대에 GPU의 중요성은 더 이상 설명이 필요하지 않습니다.
그러나 카드 수가 가득 차면 대형 모델의 훈련을 직접 시작할 수 없습니다. GPU 클러스터의 규모가 "10,000" 수준에 도달하면 효율적이고 안정적인 훈련을 달성하는 방법은 그 자체로 어려운 일입니다. 엔지니어링 문제.

첫 번째 과제: 효율성.
대규모 언어 모델을 교육하는 것은 단순한 병렬 작업이 아니며 여러 GPU에 모델을 배포해야 하며 이러한 GPU는 교육 프로세스를 공동으로 진행하기 위해 빈번한 통신이 필요합니다. 통신 외에도 연산자 최적화, 데이터 전처리 및 GPU 메모리 소비와 같은 요소는 모두 훈련 효율성을 측정하는 지표인 컴퓨팅 전력 활용도 (MFU) 에 영향을 미칩니다.
MFU는 실제 처리량과 이론적 최대 처리량의 비율입니다.
두 번째 과제: 안정성.
우리는 대규모 언어 모델을 훈련하는 데 종종 매우 오랜 시간이 걸린다는 것을 알고 있습니다. 이는 또한 훈련 과정 중 실패와 지연이 드물지 않다는 것을 의미합니다.
실패하면 비용이 높기 때문에 어떻게 하면 실패 복구 시간을 단축할 수 있는지가 특히 중요해집니다.
이러한 과제를 해결하기 위해 ByteDance 연구원은 MegaScale을 구축하고 이를 Byte의 데이터 센터에 배포하여 다양한 대형 모델의 훈련을 지원했습니다.
MegaScale은 NVIDIA Megatron-LM을 기반으로 개선되었습니다.
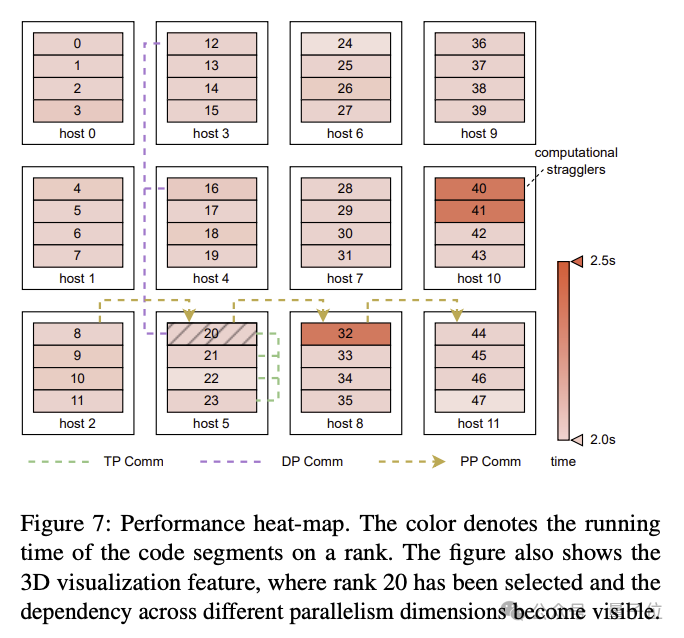
구체적인 개선 사항에는 알고리즘과 시스템 구성 요소의 공동 설계, 통신 및 컴퓨팅 중복 최적화, 운영자 최적화, 데이터 파이프라인 최적화, 네트워크 성능 튜닝 등이 포함됩니다.
백서에서는 MegaScale이 소프트웨어 및 하드웨어 오류의 90% 이상을 자동으로 감지하고 복구할 수 있다고 언급했습니다.
실험 결과 MegaScale이 12288 GPU에서 175B 대규모 언어 모델을 훈련할 때 55.2% MFU를 달성하는 것으로 나타났습니다. 이는 Megatrion-LM의 컴퓨팅 전력 활용도의 1.34배입니다.
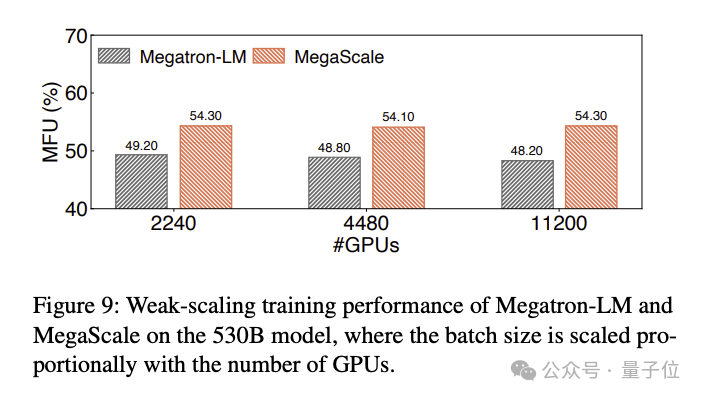
530B 대규모 언어 모델을 학습한 MFU 비교 결과는 다음과 같습니다.
이 기술 문서가 토론을 촉발한 것처럼 바이트 기반 Sora 제품에 대한 새로운 소식이 나왔습니다.
스크린샷 Sora와 유사한 AI 비디오 도구는 초대 전용 베타 테스트를 시작했습니다.

기반은 다 갖춰진 것 같은데 바이트의 대형모델 제품도 기대되시나요?
논문 주소: https://arxiv.org/abs/2402.15627
위 내용은 Byte Wanka 클러스터의 기술 세부 정보가 공개되었습니다. GPT-3 교육은 2일 만에 완료되었으며 컴퓨팅 성능 활용도는 NVIDIA Megatron-LM을 초과했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



