

환상은 LLM(대형 언어 모델)을 사용할 때 흔히 발생하는 문제입니다. LLM은 매끄럽고 일관된 텍스트를 생성할 수 있지만 생성되는 정보는 부정확하거나 일관성이 없는 경우가 많습니다. LLM의 환각을 방지하기 위해 데이터베이스나 지식 그래프와 같은 외부 지식 소스를 사용하여 사실 정보를 제공할 수 있습니다. 이러한 방식으로 LLM은 신뢰할 수 있는 데이터 소스를 활용하여 보다 정확하고 신뢰할 수 있는 텍스트 콘텐츠를 얻을 수 있습니다.
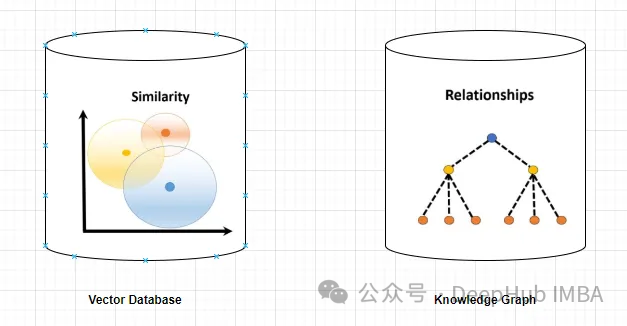
벡터 데이터베이스는 개체나 개념을 나타내는 고차원 벡터 집합입니다. 이는 벡터 표현을 통해 계산된 다양한 엔터티 또는 개념 간의 유사성 또는 상관 관계를 측정하는 데 사용할 수 있습니다.
벡터 데이터베이스는 벡터 거리를 기반으로 "파리"와 "프랑스"가 "파리"와 "독일"보다 더 관련이 있음을 알려줄 수 있습니다.
벡터 데이터베이스 쿼리에는 일반적으로 유사한 벡터를 검색하거나 특정 기준에 따라 벡터를 검색하는 작업이 포함됩니다. 다음은 벡터 데이터베이스를 쿼리하는 간단한 예입니다.
고객 프로필을 저장하는 고차원 벡터 데이터베이스가 있다고 가정해 보겠습니다. 특정 참조 고객과 유사한 고객을 찾고 싶습니다.
먼저 고객을 벡터 표현으로 정의하기 위해 관련 특징이나 속성을 추출하여 벡터 형식으로 변환할 수 있습니다.
가장 유사한 이웃을 식별하기 위해 k-최근접 이웃 또는 코사인 유사성과 같은 적절한 알고리즘을 사용하여 벡터 데이터베이스에서 유사성 검색을 수행할 수 있습니다.
정의된 유사성 척도에 따라 참조 고객과 유사한 고객을 나타내는 결정된 가장 가까운 이웃 벡터에 해당하는 고객 프로필을 검색합니다.
검색된 고객 프로필이나 이름, 인구통계 데이터, 구매 내역 등 관련 정보를 사용자에게 표시합니다.
지식 그래프는 엔터티나 개념 및 그 관계(예: 사실, 속성 또는 범주)를 나타내는 노드와 에지의 모음입니다. 노드 및 에지 속성을 기반으로 다양한 엔터티 또는 개념에 대한 사실 정보를 쿼리하거나 추론하는 데 사용할 수 있습니다.
예를 들어 지식 그래프는 에지 라벨을 기반으로 '파리'가 '프랑스'의 수도임을 알려줄 수 있습니다.
그래프 데이터베이스 쿼리에는 그래프 구조를 탐색하고 특정 기준에 따라 노드, 관계 또는 패턴을 검색하는 작업이 포함됩니다.
사용자가 노드이고 관계가 노드를 연결하는 가장자리로 표시되는 소셜 네트워크를 나타내는 그래프 데이터베이스가 있다고 가정합니다. 특정 사용자에 대해 친구의 친구(공통 연결)가 발견되면 다음을 수행해야 합니다.
1. 그래프 데이터베이스에서 참조 사용자를 나타내는 노드를 식별합니다. 이는 특정 사용자 식별자 또는 기타 관련 기준을 쿼리하여 수행할 수 있습니다.
2. Cypher(Neo4j에서 사용됨) 또는 Gremlin과 같은 그래프 쿼리 언어를 사용하여 참조 사용자 노드에서 그래프를 탐색합니다. 탐색할 패턴이나 관계를 지정하세요.
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User) RETURN fof이 쿼리는 참조 사용자로 시작하여 FRIEND 관계를 따라 다른 노드(FRIEND)를 찾은 다음 또 다른 FRIEND 관계를 따라 친구의 친구(fof)를 찾습니다.
3. 그래프 데이터베이스에서 쿼리를 실행하고 쿼리 모드에 따라 결과 노드(친구의 친구)를 검색하고 검색된 노드에 대한 특정 속성이나 기타 정보를 얻습니다.
그래프 데이터베이스는 필터링, 집계, 복잡한 패턴 일치를 포함한 고급 쿼리 기능을 제공할 수 있습니다. 특정 쿼리 언어와 구문은 다를 수 있지만 일반적인 프로세스에는 필요한 기준을 충족하는 노드와 관계를 검색하기 위해 그래프 구조를 탐색하는 작업이 포함됩니다.
지식 그래프는 벡터 데이터베이스보다 더 정확하고 구체적인 정보를 제공합니다. 벡터 데이터베이스는 두 엔터티 또는 개념 간의 유사성 또는 상관 관계를 나타내는 반면, 지식 그래프를 사용하면 둘 사이의 관계를 더 잘 이해할 수 있습니다. 예를 들어 지식 그래프는 '에펠탑'이 '파리'의 랜드마크임을 알려줄 수 있는 반면, 벡터 데이터베이스는 두 개념의 유사성만 보여줄 뿐, 어떻게 연관되어 있는지는 설명하지 못한다.
지식 그래프는 벡터 데이터베이스보다 더 다양하고 복잡한 쿼리를 지원합니다. 벡터 데이터베이스는 주로 벡터 거리, 유사성 또는 직접적인 유사성 측정으로 제한되는 가장 가까운 이웃을 기반으로 쿼리에 응답할 수 있습니다. 그리고 지식 그래프는 "속성 Z를 가진 모든 엔터티는 무엇입니까?" 또는 "W와 V의 공통 범주는 무엇입니까?"와 같은 논리 연산자를 기반으로 하는 쿼리를 처리할 수 있습니다. 이는 LLM이 더욱 다양하고 흥미로운 텍스트를 생성하는 데 도움이 될 수 있습니다.
지식 그래프는 벡터 데이터베이스보다 추론과 추론에 더 좋습니다. 벡터 데이터베이스는 데이터베이스에 저장된 직접적인 정보만 제공할 수 있습니다. 지식 그래프는 엔터티나 개념 간의 관계에서 파생된 간접적인 정보를 제공할 수 있습니다. 예를 들어 지식 그래프는 '파리는 프랑스의 수도이다'와 '프랑스는 유럽에 위치한다'라는 두 가지 사실을 바탕으로 '에펠탑은 유럽에 위치한다'라고 추론할 수 있다. 이는 LLM이 보다 논리적이고 일관된 텍스트를 생성하는 데 도움이 될 수 있습니다.
그래서 지식 그래프는 벡터 데이터베이스보다 더 나은 솔루션입니다. 이를 통해 LLM은 더욱 정확하고, 관련성이 높으며, 다양하고, 흥미롭고, 논리적이며 일관된 정보를 제공하여 정확하고 신뢰할 수 있는 텍스트를 생성하는 데 있어 더욱 신뢰할 수 있습니다. 하지만 여기서 핵심은 문서 문서 간에 명확한 관계가 있어야 한다는 것입니다. 그렇지 않으면 지식 그래프가 이를 포착할 수 없습니다.
但是,知识图谱的使用并没有向量数据库那么直接简单,不仅在内容的梳理(数据),应用部署,查询生成等方面都没有向量数据库那么方便,这也影响了它在实际应用中的使用频率。所以下面我们使用一个简单的例子来介绍如何使用知识图谱构建RAG。
我们需要使用3个主要工具/组件:
1、LlamaIndex是一个编排框架,它简化了私有数据与公共数据的集成,它提供了数据摄取、索引和查询的工具,使其成为生成式人工智能需求的通用解决方案。
2、嵌入模型将文本转换为文本所提供的一条信息的数字表示形式。这种表示捕获了所嵌入内容的语义含义,使其对于许多行业应用程序都很健壮。这里使用“thenlper/gte-large”模型。
3、需要大型语言模型来根据所提供的问题和上下文生成响应。这里使用Zephyr 7B beta模型
下面我们开始进行代码编写,首先安装包
%%capture pip install llama_index pyvis Ipython langchain pypdf
启用日志Logging Level设置为“INFO”,我们可以输出有助于监视应用程序操作流的消息
import logging import sys # logging.basicConfig(stream=sys.stdout, level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
导入依赖项
from llama_index import (SimpleDirectoryReader,LLMPredictor,ServiceContext,KnowledgeGraphIndex) # from llama_index.graph_stores import SimpleGraphStore from llama_index.storage.storage_context import StorageContext from llama_index.llms import HuggingFaceInferenceAPI from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings from llama_index.embeddings import LangchainEmbedding from pyvis.network import Network
我们使用Huggingface推理api端点载入LLM
HF_TOKEN = "api key DEEPHUB 123456" llm = HuggingFaceInferenceAPI(model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN )
首先载入嵌入模型:
embed_model = LangchainEmbedding(HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name="thenlper/gte-large") )
加载数据集
documents = SimpleDirectoryReader("/content/Documents").load_data() print(len(documents)) ####Output### 44构建知识图谱索引
创建知识图谱通常涉及专业和复杂的任务。通过利用Llama Index (LLM)、KnowledgeGraphIndex和GraphStore,可以方便地任何数据源创建一个相对有效的知识图谱。
#setup the service context service_context = ServiceContext.from_defaults(chunk_size=256,llm=llm,embed_model=embed_model ) #setup the storage context graph_store = SimpleGraphStore() storage_context = StorageContext.from_defaults(graph_store=graph_store) #Construct the Knowlege Graph Undex index = KnowledgeGraphIndex.from_documents( documents=documents,max_triplets_per_chunk=3,service_context=service_context,storage_context=storage_context,include_embeddings=True)
Max_triplets_per_chunk:它控制每个数据块处理的关系三元组的数量
Include_embeddings:切换在索引中包含嵌入以进行高级分析。
通过构建查询引擎对知识图谱进行查询
query = "What is ESOP?" query_engine = index.as_query_engine(include_text=True,response_mode ="tree_summarize",embedding_mode="hybrid",similarity_top_k=5,) # message_template =f"""Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer. Question: {query} Helpful Answer: """ # response = query_engine.query(message_template) # print(response.response.split("")[-1].strip()) #####OUTPUT ##################### ESOP stands for Employee Stock Ownership Plan. It is a retirement plan that allows employees to receive company stock or stock options as part of their compensation. In simpler terms, it is a plan that allows employees to own a portion of the company they work for. This can be a motivating factor for employees as they have a direct stake in the company's success. ESOPs can also be a tax-efficient way for companies to provide retirement benefits to their employees.可以看到,输出的结果已经很好了,可以说与向量数据库的结果非常一致。
最后还可以可视化我们生成的图谱,使用Pyvis库进行可视化展示
from pyvis.network import Network from IPython.display import display g = index.get_networkx_graph() net = Network(notebook=True,cdn_resources="in_line",directed=True) net.from_nx(g) net.show("graph.html") net.save_graph("Knowledge_graph.html") # import IPython IPython.display.HTML(filename="/content/Knowledge_graph.html")

通过上面的代码我们可以直接通过LLM生成知识图谱,这样简化了我们非常多的人工操作。如果需要更精准更完整的知识图谱,还需要人工手动检查,这里就不细说了。
数据存储,通过持久化数据,可以将结果保存到硬盘中,供以后使用。
storage_context.persist()
存储的结果如下:

向量数据库和知识图谱的区别在于它们存储和表示数据的方法。向量数据库擅长基于相似性的操作,依靠数值向量来测量实体之间的距离。知识图谱通过节点和边缘捕获复杂的关系和依赖关系,促进语义分析和高级推理。
对于语言模型(LLM)幻觉,知识图被证明优于向量数据库。知识图谱提供了更准确、多样、有趣、有逻辑性和一致性的信息,减少了LLM产生幻觉的可能性。这种优势源于它们能够提供实体之间关系的精确细节,而不仅仅是表明相似性,从而支持更复杂的查询和逻辑推理。
在以前知识图谱的应用难点在于图谱的构建,但是现在LLM的出现简化了这个过程,使得我们可以轻松的构建出可用的知识图谱,这使得他在应用方面又向前迈出了一大步。对于RAG,知识图谱是一个非常好的应用方向。
위 내용은 지식 그래프를 활용하여 RAG 모델의 기능을 향상하고 대형 모델의 잘못된 인상을 완화합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



