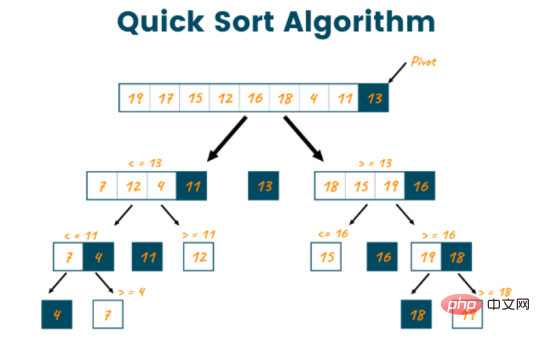
Quicksort는 다른 정렬 알고리즘에 비해 인기와 인기가 높아 자주 사용되는 정렬 알고리즘입니다. 그런 다음 배열을 두 그룹으로 분할합니다. 하나는 선택한 피벗보다 작은 요소를 포함하고 다른 하나는 피벗보다 큰 요소를 포함합니다. 그 후, 알고리즘은 전체 배열이 정렬될 때까지 각 파티션에 대해 이 프로세스를 반복합니다.
데이터베이스 애플리케이션, 과학 컴퓨팅, 웹 애플리케이션을 포함하여 정렬이 필요한 모든 상황에서 Quick Sort의 이점을 누릴 수 있습니다. 대규모 데이터 세트를 빠르고 효율적으로 정렬해야 할 때 자주 사용됩니다. 다음은 퀵 정렬이 자주 사용되는 몇 가지 구체적인 사용 사례입니다.
Python, Java 및 C와 같은 프로그래밍 언어의 배열 정렬.
데이터베이스 관리 시스템을 위한 데이터베이스 레코드 정렬.
데이터 분석 및 수치 시뮬레이션과 같은 과학 컴퓨팅 응용 프로그램을 위해 대규모 데이터 세트를 정렬합니다.
온라인 애플리케이션과 장바구니에서 검색 결과를 정리하세요.
Features
Quicksort는 피벗 요소(일반적으로 배열의 마지막 요소)를 기준으로 배열을 두 부분으로 분할합니다.
피벗보다 작은 모든 요소를 한 파티션에 배치하고 피벗보다 큰 모든 요소를 다른 파티션에 배치하여 배열을 두 개의 파티션으로 분할합니다.
알고리즘은 전체 배열이 정렬될 때까지 각 파티션에 대해 이 프로세스를 반복합니다.
데이터가 이미 정렬되어 있거나 피벗을 신중하게 선택하지 않은 경우 퀵 정렬의 최악의 시간 복잡도는 O(n2)입니다.
장점
퀵 정렬은 평균 사례 시간 복잡도가 O(nlogn)이므로 대규모 데이터 세트를 처리하는 데 매우 효과적입니다.
이것은 구현하는 데 몇 줄의 코드만 필요한 간단한 알고리즘입니다.
퀵 정렬은 병렬화가 쉽기 때문에 멀티 코어 및 분산 시스템에 사용하기에 적합합니다.
내부 정렬을 사용하므로 임시 변수나 데이터 구조를 저장하는 데 추가 메모리가 필요하지 않습니다.
단점
데이터가 정렬되었거나 피벗을 잘못 선택한 경우 퀵 정렬의 최악의 시간 복잡도는 O(n2)입니다.
정렬된 배열에서 동일한 요소의 상대적 순서는 안정적인 정렬 알고리즘이 아니기 때문에 보장할 수 없습니다.
데이터를 여러 번 통과해야 하기 때문에 Quick Sort는 메모리에 맞지 않는 대용량 데이터 세트를 정렬하는 데 적합하지 않습니다.
결론
Quicksort는 배열을 두 부분으로 나누고 전체 배열이 정렬될 때까지 각 파티션에서 프로세스를 반복적으로 수행하여 작동하는 인기 있고 효율적인 정렬 알고리즘입니다. 평균 및 최상의 경우 시간 복잡도는 O(nlogn)이고 최악의 경우 시간 복잡도는 O(n2)입니다. 다른 정렬 알고리즘에 비해 최악의 경우 시간 복잡도가 높음에도 불구하고 퀵 정렬은 성능, 단순성 및 구현 용이성 때문에 선호되는 경우가 많습니다.
위 내용은 C 언어의 퀵 정렬이란 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



