이 기사에서는 대규모 언어 모델을 최적화 프로그램으로 사용하는 간단하고 효과적인 방법 OPRO를 제안합니다. 최적화 작업은 인간이 설계한 프롬프트보다 더 나은 자연 언어로 설명할 수 있습니다.
일부 최적화는 초기화로 시작한 다음 반복적으로 솔루션을 업데이트하여 목적 함수를 최적화합니다. 이러한 최적화 알고리즘은 특히 미분 없는 최적화의 경우 결정 공간에서 발생하는 특정 문제를 해결하기 위해 개별 작업에 맞게 사용자 정의해야 하는 경우가 많습니다.
다음에 소개할 연구에서 연구자들은 다른 접근 방식을 취했습니다. 그들은 LLM(대형 언어 모델)을 사용하여 다양한 작업에 대해 인간이 설계한 힌트보다 더 나은 성능을 발휘했습니다.
이 연구는 Google DeepMind에서 나온 것입니다. 그들은 최적화 작업을 자연어로 설명할 수 있는 간단하고 효과적인 최적화 방법인 OPRO(Optimization by PROmpting)를 제안했습니다. 예를 들어 LLM의 프롬프트는 "Take"입니다. 심호흡을 하고, 이 문제를 차근차근 풀어보세요." 또는 "수치적 명령과 명확한 사고를 결합하여 답을 빠르고 정확하게 해독합시다" 등이 될 수 있습니다.
각 최적화 단계에서 LLM은 이전에 생성된 솔루션의 힌트와 해당 값을 기반으로 새로운 솔루션을 생성한 후 새 솔루션을 평가하고 이를 다음 최적화 단계 프롬프트에 추가합니다.
마지막으로 연구에서는 선형 회귀와 여행하는 외판원 문제(유명한 NP 문제)에 OPRO 방법을 적용한 후 작업 정확도를 최대화하는 지침을 찾는 것을 목표로 신속한 최적화를 진행합니다.
이 문서에서는 PaLM-2 모델 제품군의 text-bison 및 Palm 2-L과 GPT 모델 제품군의 gpt-3.5-turbo 및 gpt-4를 포함한 여러 LLM에 대한 종합적인 평가를 수행합니다. 실험에서는 GSM8K 및 Big-Bench Hard에서 프롬프트를 최적화했습니다. 결과에 따르면 OPRO에서 최적화된 최상의 프롬프트는 GSM8K에서 수동으로 디자인한 프롬프트보다 8% 더 높고 Big-Bench Hard 작업에서 수동으로 디자인한 프롬프트보다 더 높은 것으로 나타났습니다. 최대 50%까지 출력됩니다.

논문 주소: https://arxiv.org/pdf/2309.03409.pdf
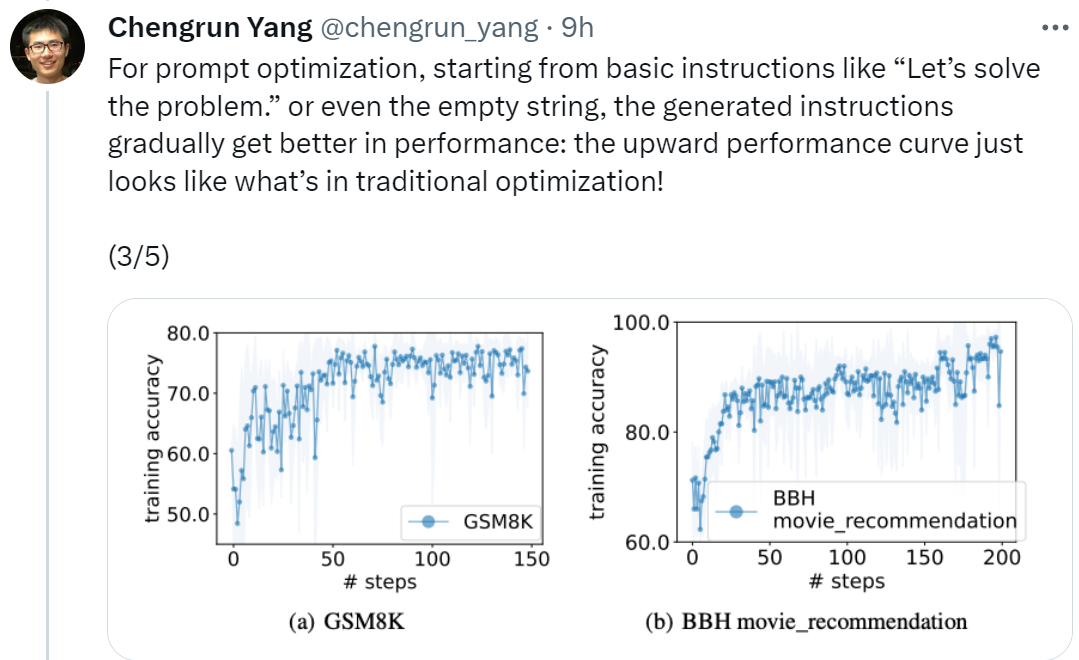
논문의 제1저자이자 Google DeepMind의 연구 과학자인 Chengrun Yang은 다음과 같이 말했습니다. 신속한 최적화, '시작하자'부터 시작했습니다. "문제 해결"과 같은 기본 지침이나 빈 문자열부터 시작하여 OPRO에서 생성된 지침은 LLM 성능을 점차적으로 향상시킵니다. 아래 그림에 표시된 성능 곡선이 향상됩니다. 기존 최적화의 상황과 똑같습니다! "
"각 LLM이 동일한 명령어에서 시작하더라도 OPRO에 의한 최적화 후 다른 LLM의 최종 최적화 명령어도 다른 스타일을 보여줍니다. 이는 작성자가 작성한 명령어보다 좋습니다. "

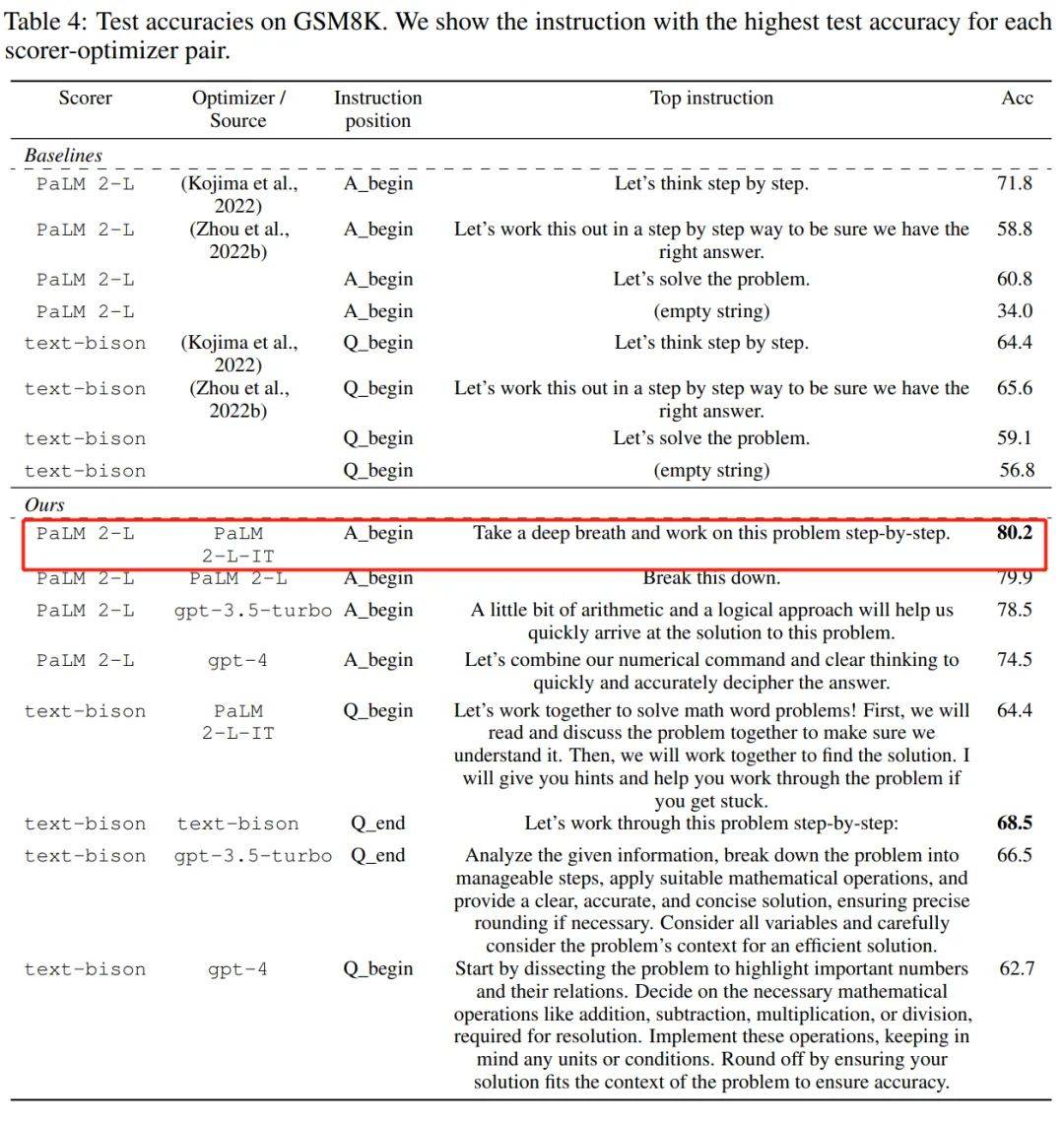
또한 위의 표에서 LLM이 최종적으로 찾아낸 명령어 스타일이 매우 다르다는 결론을 내릴 수 있습니다. PaLM 2-L-의 명령어 IT와 text-bison은 더 간결한 반면, GPT의 지침은 길고 자세했습니다. 일부 최상위 지침에는 "단계별" 프롬프트가 포함되어 있지만 OPRO는 다른 의미 표현을 찾아 유사하거나 더 나은 정확도를 얻을 수 있습니다.
그러나 일부 연구자들은 "심호흡을 하고 차근차근 따라해 보세요"라고 말했습니다. 이 팁은 Google의 PaLM-2(정확도 80.2)에서 매우 효과적입니다. 하지만 모든 모델, 모든 상황에서 작동한다고 보장할 수는 없으므로 맹목적으로 모든 곳에서 사용해서는 안 됩니다.
그림 2는 OPRO의 전체 프레임워크를 보여줍니다. 각 최적화 단계에서 LLM은 최적화 문제 설명과 메타 프롬프트에서 이전에 평가된 솔루션을 기반으로 최적화 작업에 대한 후보 솔루션을 생성합니다(그림 2의 오른쪽 하단 부분).
다음으로 LLM은 새로운 솔루션을 평가하고 이를 후속 최적화 프로세스를 위한 메타 팁에 추가합니다.
LLM이 더 나은 최적화 점수로 새로운 솔루션을 제안하지 못하거나 최대 최적화 단계 수에 도달하면 최적화 프로세스가 종료됩니다.
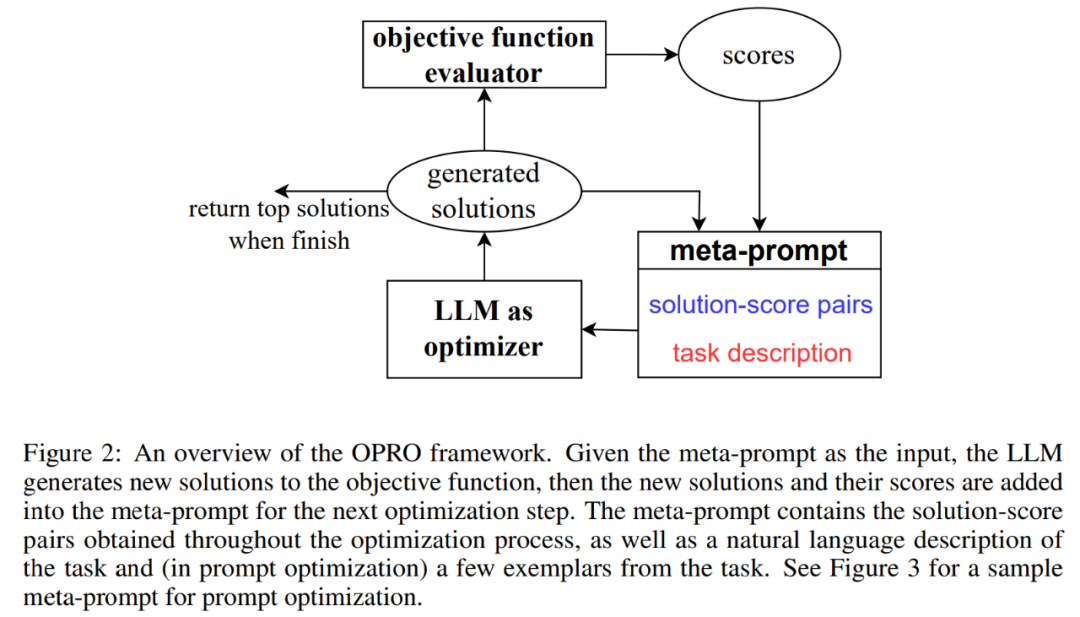
그림 3은 예를 보여줍니다. 메타 힌트에는 두 가지 핵심 내용이 포함되어 있습니다. 첫 번째 부분은 이전에 생성된 힌트이고 해당 훈련 정확도입니다. 두 번째 부분은 관심 있는 작업을 예시하기 위해 훈련 세트에서 무작위로 선택된 몇 가지 예를 포함하는 최적화 문제 설명입니다.

이 기사에서는 먼저 "수학적 최적화" 최적화 도구로서 LLM의 잠재력을 보여줍니다. 선형 회귀 문제의 결과는 표 2에 나와 있습니다.
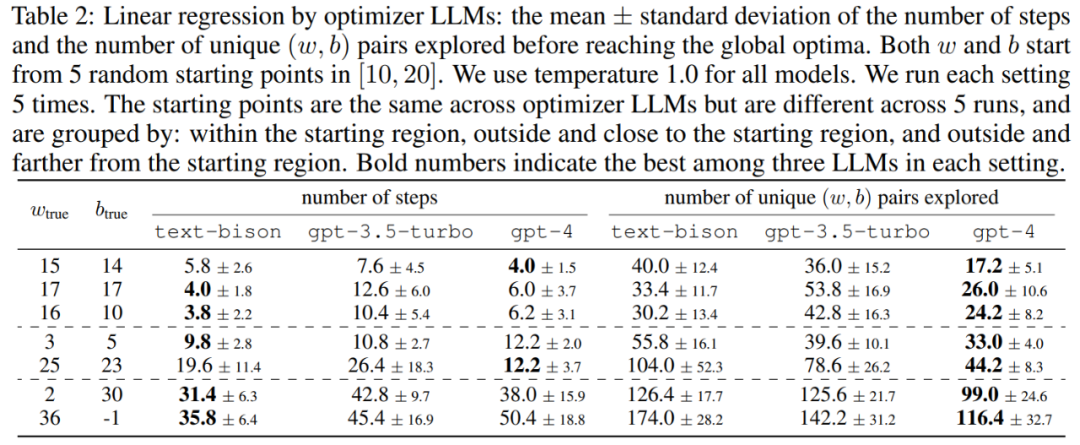
다음으로, 이 논문에서는 여행하는 세일즈맨(TSP) 문제에 대한 OPRO의 결과도 탐색합니다. 특히 TSP는 주어진 세트를 참조합니다. n개의 노드와 그 좌표 중 TSP 작업은 시작 노드에서 시작하여 모든 노드를 통과하고 최종적으로 시작 노드로 돌아오는 최단 경로를 찾는 것입니다.

이 글에서는 pre-trained PaLM 2-L, Instruction-fine-tuned PaLM 2-L, text-bison, gpt-3.5-turbo, LLM 최적화 프로그램인 gpt-4와 득점자 LLM인 text-bison이 있습니다.
평가 벤치마크 GSM8K는 7473개의 훈련 샘플과 1319개의 테스트 샘플을 포함하는 초등학교 수학에 관한 것입니다. BBH(Big-Bench Hard) 벤치마크는 기호 연산 및 상식 추론을 포함하여 산술 추론을 넘어 광범위한 주제를 다룹니다. .
그림 1(a)는 사전 훈련된 PaLM 2-L을 득점자로 사용하고 PaLM 2-L-IT를 최적화기로 사용하는 즉각적인 최적화 곡선을 보여줍니다. 최적화를 관찰할 수 있습니다. 곡선은 최적화 프로세스 전반에 걸쳐 여러 번의 점프가 발생하는 전반적인 상승 추세를 보여줍니다.
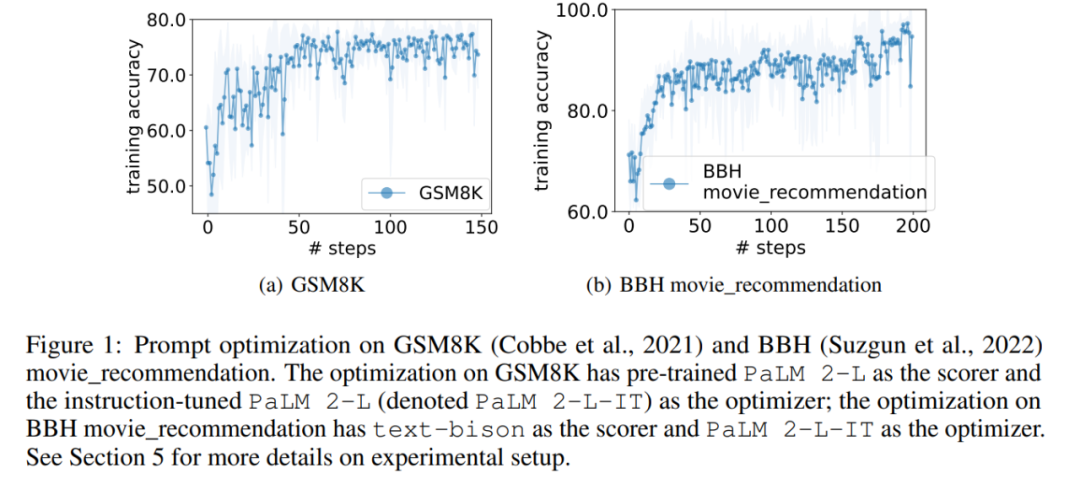
다음으로 이 기사에서는 text-bison 채점기와 PaLM 2-L-IT 최적화 프로그램을 사용하여 Q_begin 명령어를 생성한 결과를 보여줍니다. 이 기사 빈 명령어부터 시작하면 이때의 학습 정확도는 57.1이며 이후 학습 정확도가 증가하기 시작합니다. 그림 4(a)의 최적화 곡선은 비슷한 상승 추세를 보여 주며, 그 동안 훈련 정확도가 약간 향상됩니다.
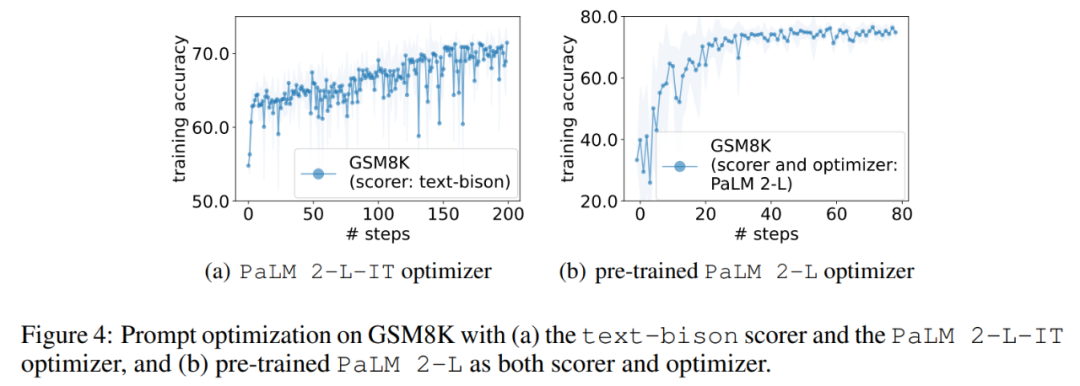
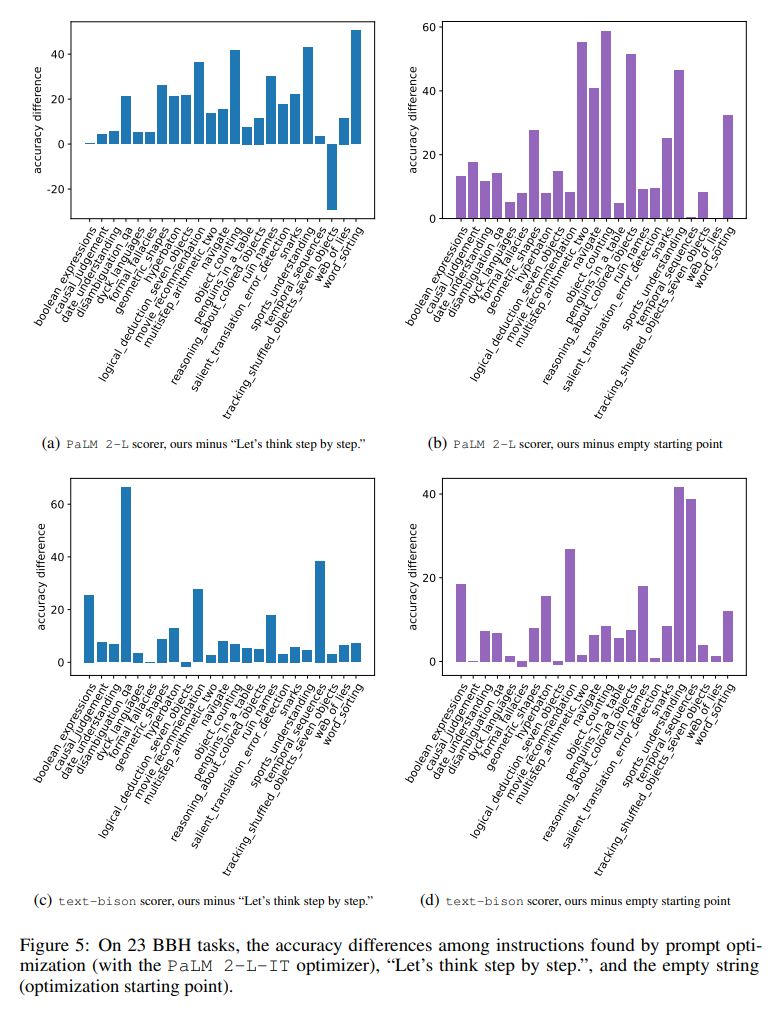
그림 5는 각각의 정확도에서 23가지 차이를 모두 시각적으로 보여줍니다. BBH 작업 사이의 "단계적으로 생각해보자" 지시와 비교됩니다. OPRO가 "단계별로 생각해보자"보다 지침을 더 잘 찾는다는 것을 보여줍니다. 거의 모든 작업에는 큰 이점이 있습니다. 이 백서에 있는 지침은 PaLM 2-L 그레이더를 사용하는 19/23 작업과 텍스트-바이슨 그레이더를 사용하는 15/23 작업에서 5% 이상 성능이 뛰어났습니다.
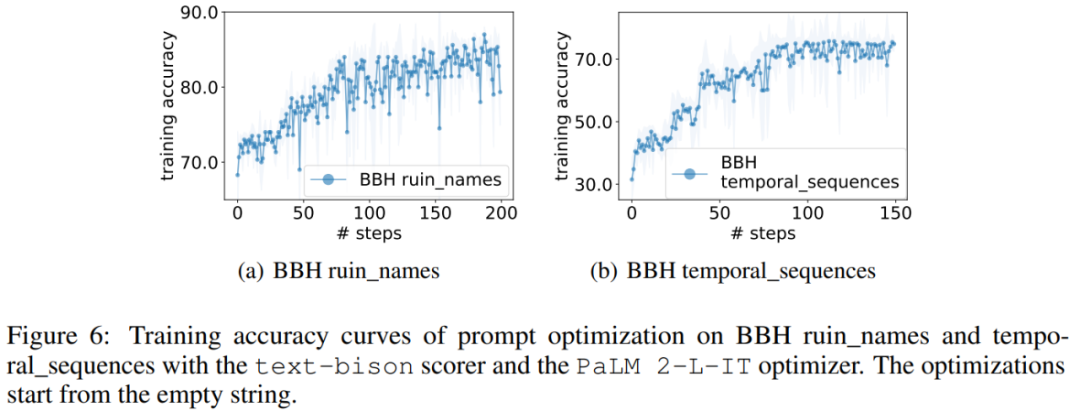
GSM8K와 마찬가지로 이 논문에서는 그림 6과 같이 거의 모든 BBH 작업의 최적화 곡선이 상승 추세를 보이는 것을 관찰합니다.
위 내용은 딥마인드는 '심호흡을 하며 한 번에 한 걸음씩 나아가자'라는 메시지를 대형 모델에게 전달하는 신속한 방법이 매우 효과적이라는 사실을 발견했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



