
inRedis中有三大问题:缓存雪崩、缓存击穿、缓存穿透,今天我们来聊聊缓存击穿.
캐시 분해와 관련된 이론적인 글은 많이 읽어보셨을 거라 생각하지만, 특정 코드에서 어떻게 구현해야 할지, 어떻게 해결해야 할지 헷갈리실 수도 있습니다.
오늘 Lao Tian은 캐시 분석 솔루션과 코드 구현을 보여드리겠습니다.
아래 코드를 살펴보세요:
/** * @author 田维常 * @公众号 java后端技术全栈 * @date 2021/6/27 15:59 */ @Service public class UserInfoServiceImpl implements UserInfoService { @Resource private UserMapper userMapper; @Resource private RedisTemplate redisTemplate; @Override public UserInfo findById(Long id) { //查询缓存 String userInfoStr = redisTemplate.opsForValue().get(id); //如果缓存中不存在,查询数据库 //1 if (isEmpty(userInfoStr)) { UserInfo userInfo = userMapper.findById(id); //数据库中不存在 if(userInfo == null){ return null; } userInfoStr = JSON.toJSONString(userInfo); //2 //放入缓存 redisTemplate.opsForValue().set(id, userInfoStr); } return JSON.parseObject(userInfoStr, UserInfo.class); } private boolean isEmpty(String string) { return !StringUtils.hasText(string); } }
전체 과정:
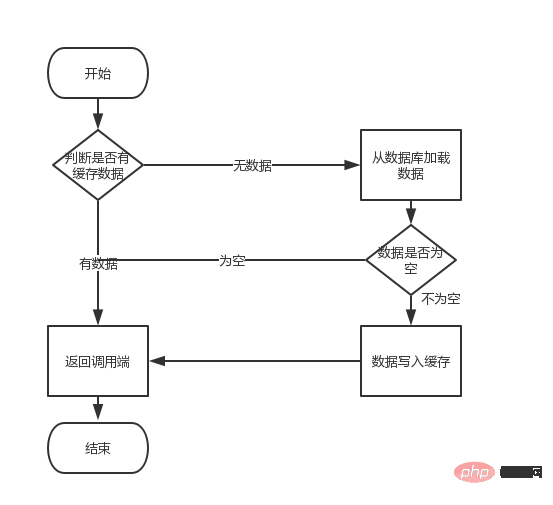
如果,在//1到//2之间耗时1.5秒,那就代表着在这1.5秒时间内所有的查询都会走查询数据库。这也就是我们所说的缓存中的“缓存击穿”。
其实,你们项目如果并发量不是很高,也不用怕,并且我见过很多项目也就差不多是这么写的,也没那么多事,毕竟只是第一次的时候可能会发生缓存击穿。
但,我们也不要抱着一个侥幸的心态去写代码,既然是多线程导致的,估计很多人会想到锁,下面我们使用锁来解决。
既然使用到锁,那么我们第一时间应该关心的是锁的粒度。
如果我们放在方法findById上,那就是所有查询都会有锁的竞争,这里我相信大家都知道我们为什么不放在方法上。
/** * @author 田维常 * @公众号 java后端技术全栈 * @date 2021/6/27 15:59 */ @Service public class UserInfoServiceImpl implements UserInfoService { @Resource private UserMapper userMapper; @Resource private RedisTemplate redisTemplate; @Override public UserInfo findById(Long id) { //查询缓存 String userInfoStr = redisTemplate.opsForValue().get(id); if (isEmpty(userInfoStr)) { //只有不存的情况存在锁 synchronized (UserInfoServiceImpl.class){ UserInfo userInfo = userMapper.findById(id); //数据库中不存在 if(userInfo == null){ return null; } userInfoStr = JSON.toJSONString(userInfo); //放入缓存 redisTemplate.opsForValue().set(id, userInfoStr); } } return JSON.parseObject(userInfoStr, UserInfo.class); } private boolean isEmpty(String string) { return !StringUtils.hasText(string); } }
看似解决问题了,其实,问题还是没得到解决,还是会缓存击穿,因为排队获取到锁后,还是会执行同步块代码,也就是还会查询数据库,完全没有解决缓存击穿。
由此,我们引入双重检查锁,我们在上的版本中进行稍微改变,在同步模块中再次校验缓存中是否存在。
/** * @author 田维常 * @公众号 java后端技术全栈 * @date 2021/6/27 15:59 */ @Service public class UserInfoServiceImpl implements UserInfoService { @Resource private UserMapper userMapper; @Resource private RedisTemplate redisTemplate; @Override public UserInfo findById(Long id) { //查缓存 String userInfoStr = redisTemplate.opsForValue().get(id); //第一次校验缓存是否存在 if (isEmpty(userInfoStr)) { //上锁 synchronized (UserInfoServiceImpl.class){ //再次查询缓存,目的是判断是否前面的线程已经set过了 userInfoStr = redisTemplate.opsForValue().get(id); //第二次校验缓存是否存在 if (isEmpty(userInfoStr)) { UserInfo userInfo = userMapper.findById(id); //数据库中不存在 if(userInfo == null){ return null; } userInfoStr = JSON.toJSONString(userInfo); //放入缓存 redisTemplate.opsForValue().set(id, userInfoStr); } } } return JSON.parseObject(userInfoStr, UserInfo.class); } private boolean isEmpty(String string) { return !StringUtils.hasText(string); } }
这样,看起来我们就解决了缓存击穿问题,大家觉得解决了吗?
回顾上面的案例,在正常的情况下是没问题,但是一旦有人恶意攻击呢?
比如说:入参id=10000000,在数据库里并没有这个id,怎么办呢?
第一步、缓存中不存在
第二步、查询数据库
第三步、由于数据库中不存在,直接返回了,并没有操作缓存
第四步、再次执行第一步.....死循环了吧
就是当缓存中和数据库中都不存在的情况下,以id为key,空对象为value。
set(id,空对象);
回到上面的四步,就变成了。
比如说:入参
id=10000000,在数据库里并没有这个id,怎么办呢?第一步、缓存中不存在
第二步、查询数据库
第三步、由于数据库中不存在,以id为
key,空对象为value放入缓存中第四步、执行第一步,此时,缓存就存在了,只是这时候只是一个空对象。
代码实现部分:
/** * @author 田维常 * @公众号 java后端技术全栈 * @date 2021/6/27 15:59 */ @Service public class UserInfoServiceImpl implements UserInfoService { @Resource private UserMapper userMapper; @Resource private RedisTemplate redisTemplate; @Override public UserInfo findById(Long id) { String userInfoStr = redisTemplate.opsForValue().get(id); //判断缓存是否存在,是否为空对象 if (isEmpty(userInfoStr)) { synchronized (UserInfoServiceImpl.class){ userInfoStr = redisTemplate.opsForValue().get(id); if (isEmpty(userInfoStr)) { UserInfo userInfo = userMapper.findById(id); if(userInfo == null){ //构建一个空对象 userInfo= new UserInfo(); } userInfoStr = JSON.toJSONString(userInfo); redisTemplate.opsForValue().set(id, userInfoStr); } } } UserInfo userInfo = JSON.parseObject(userInfoStr, UserInfo.class); //空对象处理 if(userInfo.getId() == null){ return null; } return JSON.parseObject(userInfoStr, UserInfo.class); } private boolean isEmpty(String string) { return !StringUtils.hasText(string); } }
布隆过滤器(Bloom Filter):是一种空间效率极高的概率型算法和数据结构,用于判断一个元素是否在集合中(类似Hashset)。它的核心一个很长的二进制向量和一系列hash函数,数组长度以及hash函数的个数都是动态确定的。
Hash函数:
SHA1,SHA256,MD5..
布隆过滤器的用处就是,能够迅速判断一个元素是否在一个集合中。因此他有如下三个使用场景:
URL헤비, 회피 동일한
URL주소
URL的去重,避免爬取相同的
URL地址
其内部维护一个全为0的bit数组,需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。布隆过滤器的相关理论和算法这里就不聊了,感兴趣的可以自行研究。
优势
O(k),远远超过一般的算法
劣势
내부비트 배열에서 블룸 필터에는 위양성률(false positive rate)이라는 개념이 있다는 점에 유의해야 합니다. 위양성률이 낮을수록 배열이 길어지고 차지하는 공간이 커집니다. 거짓 긍정 비율이 높을수록 어레이가 작아지고 차지하는 공간도 작아집니다. 블룸 필터의 관련 이론과 알고리즘은 여기서 논의하지 않습니다. 관심 있는 사람은 스스로 공부할 수 있습니다.
장점전체 저장이 가능하지만 요소 자체는 저장되지 않으므로 기밀 유지 요구 사항이 매우 엄격한 일부 상황에서 장점이 있습니다.높은 공간 효율성삽입/쿼리 시간이 일정함O(k), 일반 알고리즘을 훨씬 초과함
단점
False Positive),默认
0.03,随着存入的元素数量增加,误算率随之增加;
代码实现:
/** * @author 田维常 * @公众号 java后端技术全栈 * @date 2021/6/27 15:59 */ @Service public class UserInfoServiceImpl implements UserInfoService { @Resource private UserMapper userMapper; @Resource private RedisTemplate redisTemplate; private static Long size = 1000000000L; private static BloomFilter bloomFilter = BloomFilter.create(Funnels.longFunnel(), size); @Override public UserInfo findById(Long id) { String userInfoStr = redisTemplate.opsForValue().get(id); if (isEmpty(userInfoStr)) { //校验是否在布隆过滤器中 if(bloomFilter.mightContain(id)){ return null; } synchronized (UserInfoServiceImpl.class){ userInfoStr = redisTemplate.opsForValue().get(id); if (isEmpty(userInfoStr) ) { if(bloomFilter.mightContain(id)){ return null; } UserInfo userInfo = userMapper.findById(id); if(userInfo == null){ //放入布隆过滤器中 bloomFilter.put(id); return null; } userInfoStr = JSON.toJSONString(userInfo); redisTemplate.opsForValue().set(id, userInfoStr); } } } return JSON.parseObject(userInfoStr, UserInfo.class); } private boolean isEmpty(String string) { return !StringUtils.hasText(string); } }
使用Redis实现分布式的时候,有用到setnx,这里大家可以想象,我们是否可以使用这个分布式锁来解决缓存击穿的问题?
这个方案留给大家去实现,只要掌握了Redis的分布式锁,那这个实现起来就非常简单了。
搞定缓存击穿、使用双重检查锁的方式来解决,看到双重检查锁,大家肯定第一印象就会想到单例模式,这里也算是给大家复习一把双重检查锁的使用。
악의적인 공격으로 인한 캐시 고장으로 인해 적어도 직장과 면접에서는 두 가지 솔루션을 구현했습니다.
자물쇠 사용시에도 주의锁的力度,这里建议换成分布式锁(Redis或者Zookeeper实现),因为我们既然引入缓存,大部分情况下都会是部署多个节点的,同时,引入分布式锁了,我们就可以使用方法入参id사용에 주의하세요. 이렇게 하면 더 재미있지 않나요!
기술을 암기하지 않고 모두가 기사에 나온 아이디어 중 일부를 이해할 수 있기를 바랍니다.
위 내용은 캐시 분해! 코드 작성 방법도 모르시나요? ? ?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



