
| Command | Description | |
|---|---|---|
| BLPOP 키 1,키2,... 시간 초과 | 제거 목록의 첫 번째 요소 를 가져옵니다. 목록에 요소가 없으면 대기 시간이 초과되거나 요소가 표시될 때까지 목록이 차단됩니다. | |
| BRPOP key1 [key2 ] timeout | 목록에서 마지막 요소를 가져오세요. 대기 시간이 초과되거나 팝 가능한 요소가 발견될 때까지 나열합니다. | |
| BRPOPLPUSH 소스 대상 시간 초과 | 목록에서 값을 팝하고, 팝된 요소를 다른 목록에 삽입하고, 목록에 요소가 없으면 반환합니다. 대기 시간이 초과되거나 팝업 가능한 요소가 발견될 때까지. | |
| LIndex key index | 通过索引获取列表中的元素 | |
| Linsert key before/after pivot value | 在列表的元素前或者后插入元素 | |
| LLEN key | 获取列表长度 | |
| LPOP key | 移出并获取列表的第一个元素ㅋㅋㅋ | |
| 기존 목록의 헤드에 값을 삽입합니다 | LRANGE 키 삭제 중지 | |
| 목록의 지정된 범위에 있는 요소를 가져옵니다 | LREM 키 count value | |
| 목록 요소 제거 | LSET 키 인덱스 값 | |
| 목록 요소의 값을 인덱스로 설정 | LTRIM 키 시작 중지 | 목록 정리는 목록이 지정된 범위 내의 요소만 유지하고 지정된 범위 내에 없는 모든 요소가 삭제됨을 의미합니다. 인덱스는 0부터 시작하며 범위는 0부터 시작됩니다. |
| RPOP key | 는 목록에서 마지막 요소를 제거하고 반환 값은 제거된 요소 | |
| RPOPPUSH 소스 대상 | 목록의 마지막 요소 를 제거하고 해당 요소를 다른 목록에 추가하고 | |
| RPUSH 키 값1 값2 …… | 을 반환합니다.하나 추가 또는 목록 끝에 더 많은 값 | |
| RPUSHX 키 값 | 기존 목록에 값 추가 |
차트 출처: https://www.cnblogs.com/amyzhu/p/13466311.html
redis의 목록 구현을 배우기 전에 살펴보겠습니다. 먼저 단일 연결 목록을 구현하는 방법:
각 노드에는 다음 노드를 가리키는 역방향 포인터(참조)가 있고, 마지막 노드는 끝을 나타 내기 위해 NULL을 가리키며, 노드를 가리키는 헤드 포인터가 있습니다. 시작을 나타내는 첫 번째 노드입니다.
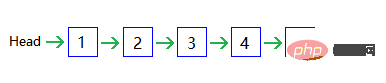
이와 유사하지만 신규 및 삭제된 항목만 필요합니다 O(1)O(1),但是查找需要 O(n), 검색에는 O(n)
시간; 역방향 검색은 불가능하며 시작해야 합니다. 놓치면 처음부터 .
🎜노드 추가: 🎜🎜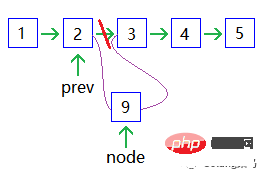
노드 삭제:
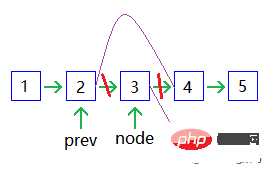
이중 연결 목록은 이중 연결 목록이라고도 합니다. 각 데이터 노드의 유형입니다. 에는 직계 후임자와 직계 전임자를 각각 가리키는 두 개의 포인터가 있습니다. 따라서 이중 연결 목록의 모든 노드에서 시작하면 이전 노드와 후속 노드에 쉽게 액세스할 수 있습니다.

특징:
노드가 삽입되거나 삭제될 때마다 2개가 아닌 4개의 노드 참조를 처리해야 합니다.
비교합니다. 단방향 연결 리스트라면 확실히 더 많은 메모리 공간을 차지하게 됩니다.
처음부터 끝까지 순회할 수 있고, 끝에서 선두까지 순회할 수도 있습니다
이는 이전과 이후 모두 구현될 수 있는 Redis의 문제를 해결한 것으로 보입니다. 이는 순회 문제입니다.
그럼 redis의 링크드 리스트 를 살펴보겠습니다. 처리 방법:
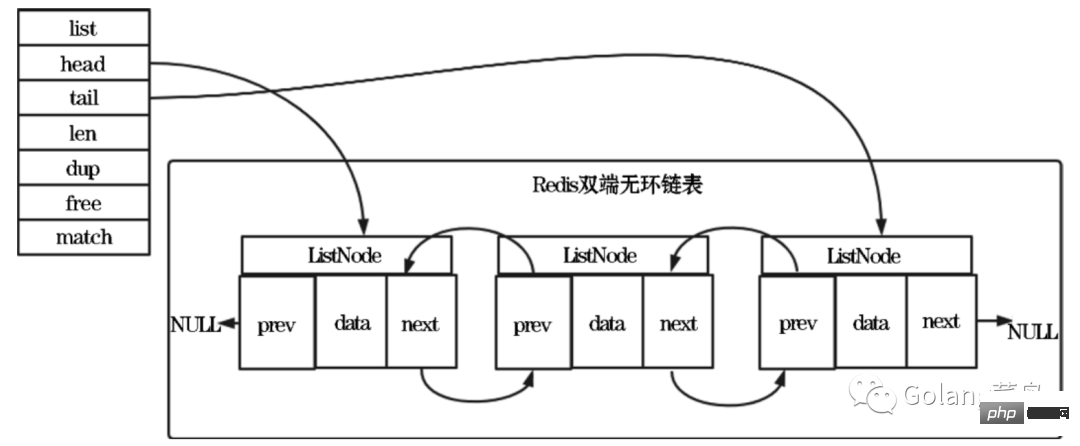
구조 정의 소스 코드를 살펴보겠습니다.
ListNode:
typedef struct listNode
{
// 前驱节点
struct listNode *prev;
// 后继节点
struct listNode *next;
// 节点的值
void *value;
} listNode;List:
typedef struct listNode
{
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 链表所包含的节点数量
unsigned long len;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void *(*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr,void *key)
} list;redis 연결 목록의 특징:
순환: 연결리스트 노드 전륜 구동의 경우 후속 포인터로 노드의 선행 노드와 후속 노드를 얻는 시간 복잡도는 O(1)입니다. 헤드 노드의 선행 포인터와 테일 노드의 후속 포인터는 모두 NULL을 가리키고 다음 노드에 액세스합니다. 연결된 목록은 NULL로 끝납니다.
Length 카운터: List 구조의 len 속성을 통해 노드 수를 얻는 시간 복잡도는 O(1)입니다.
리스트에는 여전히 불연속적인 메모리 할당과 메모리 조각화 문제가 있는데, 메모리를 최적화할 수 있는 방법이 있나요?
ZipList는 기본 데이터 구조가 아니며 Redis 자체에서 설계한 데이터 저장 구조입니다. 이는 연속적인 메모리 공간을 통해 데이터를 저장하는 배열과 다소 유사합니다.
배열과 달리 저장된 목록 요소가 다른 메모리 공간을 차지할 수 있습니다. 압축이라는 단어를 들으면 누구나 가장 먼저 생각할 수 있는 것은 메모리 절약입니다. 이 저장 구조가 메모리를 절약하는 이유는 배열과 비교되기 때문입니다.
우리 모두는 배열이 각 요소에 대해 동일한 크기의 저장 공간을 필요로 한다는 것을 알고 있습니다. 서로 다른 길이의 문자열을 저장하려면 최대 길이의 문자열이 차지하는 저장 공간을 문자열의 각 요소로 사용해야 합니다. 배열 공간의 크기입니다(50바이트인 경우).
그래서 문자수 값에 길이가 50바이트 미만인 문자열을 저장하면 저장 공간의 일부가 낭비됩니다.
array의 장점은 연속적인 공간을 차지하고 CPU 캐시를 잘 활용하여 데이터에 빠르게 액세스할 수 있다는 것입니다.
배열의 이러한 장점을 유지하고 저장 공간을 절약하려면 배열을 압축하면 됩니다.
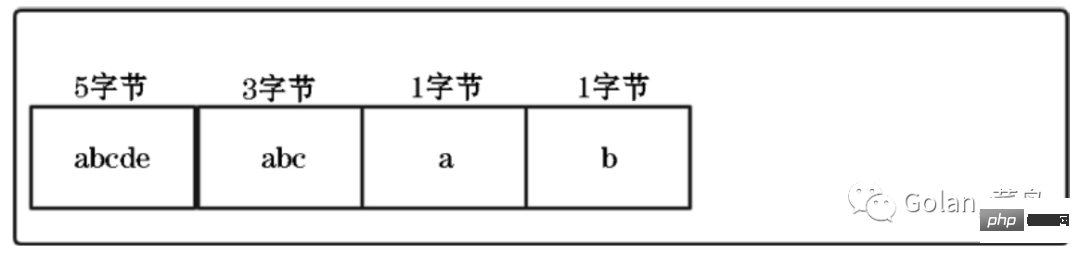
그러나 압축된 목록을 순회할 때 알 수 없는 문제가 있습니다. 각 요소가 차지하는 메모리 크기는 얼마이므로 다음 요소의 구체적인 시작 위치를 계산하는 것은 불가능합니다.
그런데 생각해보니, 각 요소에 접근하기 전에 각 요소의 길이를 알 수 있다면 이 문제가 해결되지 않을까요?

다음으로 Redis가 어떻게 배열의 장점을 유지하면서 메모리를 절약하면서 ZipList를 구현하여 이들을 결합하는지 살펴보겠습니다.
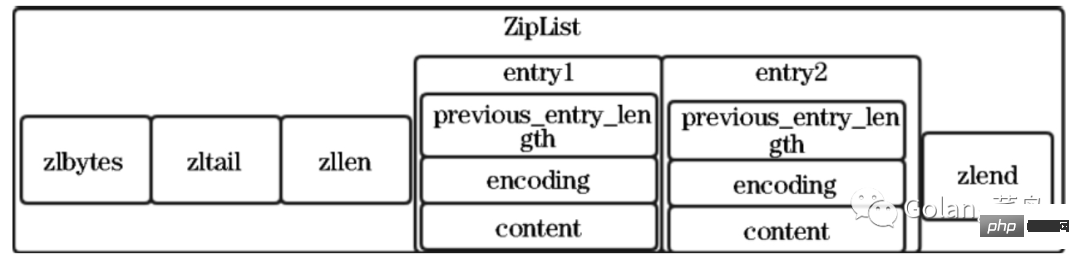
zlbytes:压缩列表的字节长度,是uint32_t类型,占4字节,因此压缩列表最多有232-1字节,可以通过该值计算zlend的位置,也可以在内存重新分配的时候使用。
zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,是uint32_t类型,占4字节,可以通过该值快速定位到列表尾元素的位置。
zllen:压缩列表元素的个数,是uint16_t类型,占2字节,表示最多存储的元素个数为216-1=65 535,如果需要计算总数量,则需要遍历整个压缩列表。
entryx:压缩列表存储的元素,既可以是字节数组,也可以是整数,长度不限。
zlend:压缩列表的结尾,是uint8_t类型,占1字节,恒为0xFF。
previous_entry_length:表示前一个元素的字节长度,占1字节或者5字节,当前元素的长度小于254时用1字节,大于等于254时用5字节,previous_entry_length 字段的第一个字节固定是0xFE,后面的4字节才是真正的前一个元素的长度。
encoding:表示元素当前的编码,有整数或者字节数。为了节省内存,encoding字段长度可变。
content:表示当前元素的内容。
ZipList变量的读取和赋值都是通过宏来实现的,代码片段如下:
//返回整个压缩列表的总字节 #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //返回压缩列表的tail_offset变量,方便获取最后一个节点的位置 #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //返回压缩列表的节点数量 #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //返回压缩列表的表头的字节数 //(内存字节数zlbytes,最后一个节点地址ztail_offset,节点总数量zllength) #define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) //返回压缩列表最后结尾的字节数 #define ZIPLIST_END_SIZE (sizeof(uint8_t)) //返回压缩列表首节点地址 #define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) //返回压缩列表尾节点地址 #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) //返回压缩列表最后结尾的地址 #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
对此,可以通过定义的结构体和对应的操作定义知道大概 redis 设计 压缩list 的思路;
这种方式虽然节约了空间,但是会存在每次插入和创建存在内存重新分配的问题。
quicklist是Redis 3.2中新引入的数据结构,能够在时间效率和空间效率间实现较好的折中。Redis中对quciklist的注释为A doubly linked list of ziplists。顾名思义,quicklist是一个双向链表,链表中的每个节点是一个ziplist结构。quicklist可以看成是用双向链表将若干小型的ziplist连接到一起组成的一种数据结构。
当ziplist节点个数过多,quicklist退化为双向链表,一个极端的情况就是每个ziplist节点只包含一个entry,即只有一个元素。当ziplist元素个数过少时,quicklist可退化为ziplist,一种极端的情况就是quicklist中只有一个ziplist节点。
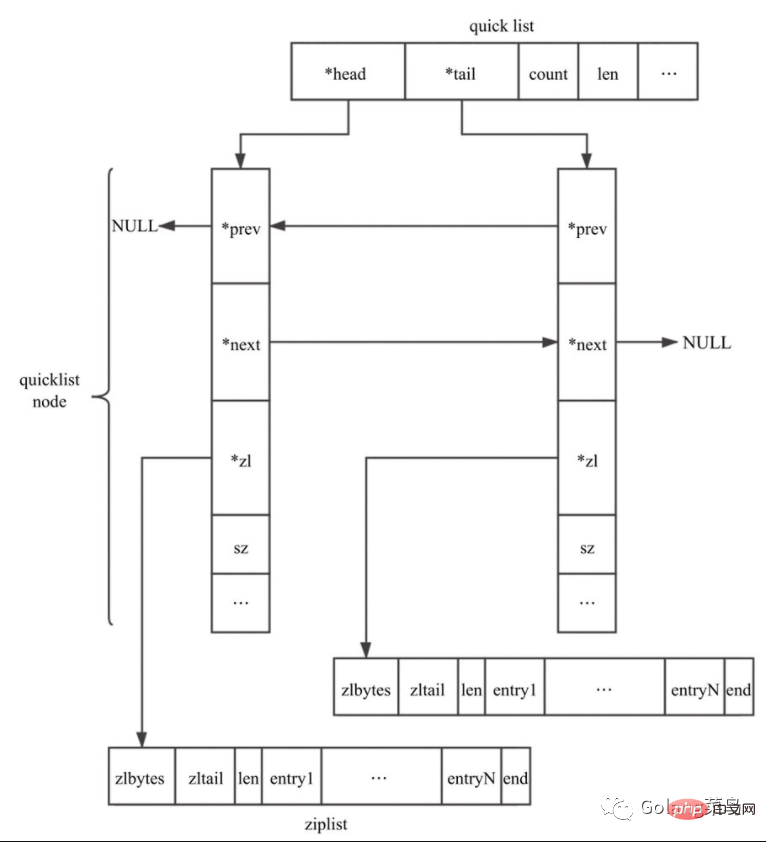
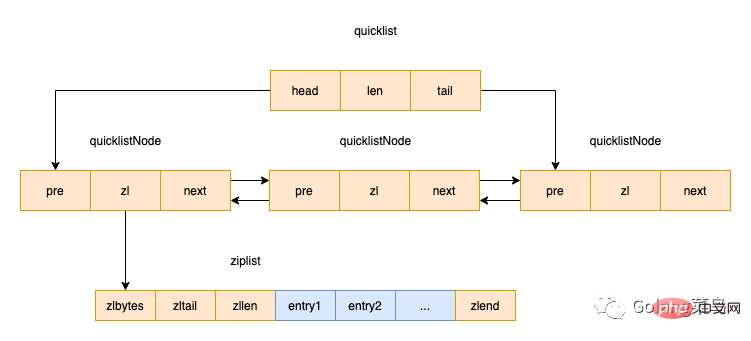
quicklist 结构定义:
typedef struct quicklist {
// 指向quicklist的首节点
quicklistNode *head;
// 指向quicklist的尾节点
quicklistNode *tail;
// quicklist中元素总数
unsigned long count; /* total count of all entries in all ziplists */
// quicklistNode节点个数
unsigned long len; /* number of quicklistNodes */
// ziplist大小设置,存放list-max-ziplist-size参数的值
int fill : 16; /* fill factor for individual nodes */
// 节点压缩深度设置,存放list-compress-depth参数的值
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: 4;
quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistBookmark {
quicklistNode *node;
char *name;
} quicklistBookmark;quicklistNode定义如下:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;redis为了节省内存空间,会将quicklist的节点用LZF压缩后存储,但这里不是全部压缩,可以配置compress的值,compress为0表示所有节点都不压缩,否则就表示从两端开始有多少个节点不压缩;compress如果是1,表示从两端开始,有1个节点不做LZF压缩。compress默认是0(不压缩),具体可以根据你们业务实际使用场景去配置。
redis 的配置文件可以配置该参数
list-compress-depth 0
| 가치 | 의미 |
|---|---|
| 0 | 특수 값은 압축이 없음을 의미합니다. |
| 1 | 퀵리스트의 각 끝에는 압축되지 않은 노드가 1개 있고, 중간 노드는 압축되어 있습니다. |
| 2 | 퀵리스트의 각 끝에는 2개의 노드가 있습니다. 압축되지 않고 중간 노드가 압축됩니다 |
| n | quicklist 퀵리스트의 각 끝에는 압축되지 않은 n개의 노드가 있으며, 중간에 있는 노드는 압축되어 있습니다. |
각 퀵노드 노드의 최대 용량을 의미하는 채우기 필드도 있습니다. 기본값은 -2입니다. ;
list-max-ziplist-size -2
값이 양수이면 QuicklistNode 노드의 ziplist 길이를 나타냅니다. 예를 들어 값이 5인 경우 각 QuicklistNode 노드의 ziplist에는 최대 5개의 데이터 항목이 포함됩니다.
값이 음수인 경우 QuicklistNode 노드의 ziplist 길이는 다음과 같습니다. 바이트 수에 따라 제한됩니다. 가능한 값은 -1 ~ -5입니다.
| 값 | 의미 |
|---|---|
| -1 | Ziplist 노드 최대 크기는 4kb |
| - 2 | 최대 ziplist 노드는 8kb |
| -3 | 최대 ziplist 노드는 16kb |
| -4 | ziplist 노드 최대 크기는 32kb입니다 |
| -5 | ziplist 노드 최대 크기는 64kb |
왜 구성이 제공되나요?
ziplist가 짧을수록 더 많은 메모리 조각이 발생하여 저장 효율성에 영향을 미칩니다. ziplist가 하나의 요소만 저장하는 경우 퀵리스트는 이중 연결 목록으로 변질됩니다. ziplist가 길수록 ziplist에 큰 연속 메모리 공간을 할당하기가 더 어려워지고 이로 인해 많은 작은 메모리 공간 블록이 차지하게 됩니다. . 낭비, 퀵리스트에 노드가 하나만 있고 모든 요소가 ziplist에 저장되면 퀵리스트는 ziplist로 변질됩니다
결론
위 내용은 redis 연구 노트 목록 원칙의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



