
더 이상 고민하지 않고 그림은 다음과 같습니다.
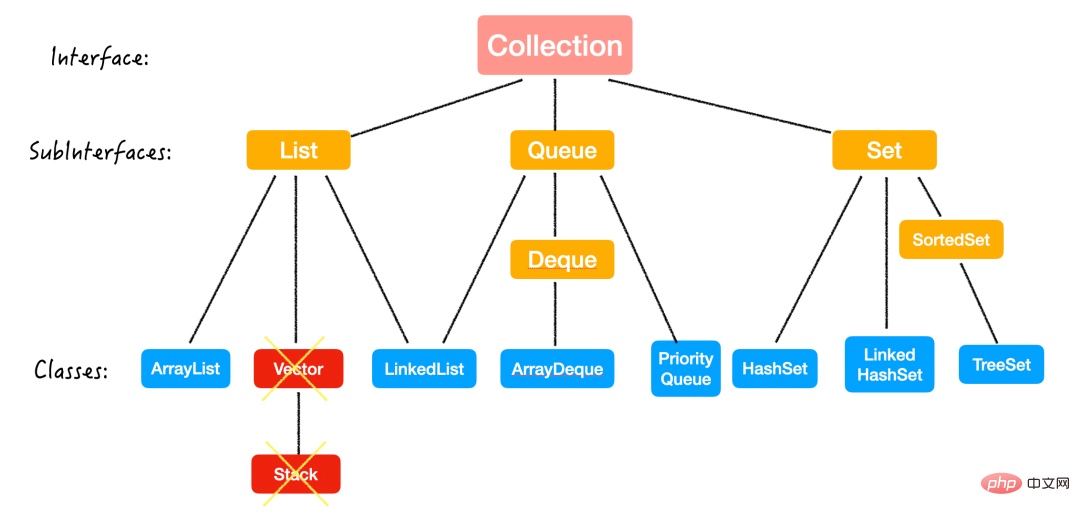
컨테이너라고도 알려진 Java 컬렉션은 주로두 가지 주요 인터페이스(인터페이스)에서 파생됨:两大接口 (Interface)派生出来的:Collection 和 Map컬렉션 및 맵
이름에서 알 수 있듯이 컨테이너 데이터를 저장하는 데 사용됩니다.
이 두 인터페이스의 차이점은 다음과 같습니다.
즉, 싱글은 컬렉션에, 커플은 맵에 배치됩니다. (그래서 당신은 어디에 속해있나요?
이러한 컬렉션 프레임워크를 배우는 데에는 4가지 목표가 있다고 생각합니다.
Collection
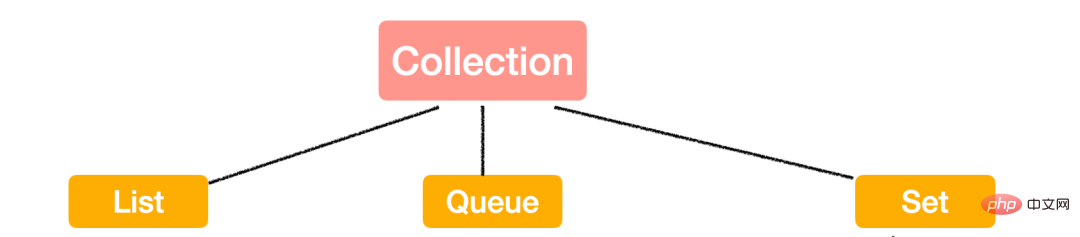
Collection은 또한 다양한 하위 인터페이스 및 구현 클래스에 상속되는 많은 메소드를 정의합니다. 이러한 API의 사용은 일상 업무 및 인터뷰에서도 흔히 사용되는 테스트이므로 먼저 이러한 메소드를 살펴보겠습니다.
작업 세트는CRUD:
Create, Read, Update 및 Delete라고도 불리는 "추가, 삭제, 수정 및 확인"의 네 가지 범주에 지나지 않습니다.
그런 다음 이러한 API를 다음과 같이 나눕니다. 네 가지 범주:
| Function | method |
|---|---|
| add | add()/addAll() |
| delete | remove()/removeAll() |
| change | 아님 컬렉션 인터페이스에서 사용 가능 |
| Check | contains()/containsAll() |
| Others | isEmpty()/size()/toArray() |
아래에서 자세히 살펴보세요.
boolean add(E e);
add()전달되는 데이터 타입은 반드시 Object 이어야 하기 때문에 기본 데이터 타입 작성 시 자동 박싱(auto-boxing)과 자동 언패킹(auto unpacking)이 이루어집니다. Box unboxing.add()方法传入的数据类型必须是 Object,所以当写入基本数据类型的时候,会做自动装箱 auto-boxing 和自动拆箱 unboxing。
还有另外一个方法addAll(),可以把另一个集合里的元素加到此集合中。
boolean addAll(Collection c);
boolean remove(Object o);
remove()是删除的指定元素。
那和addAll()对应的,
自然就有removeAll()
addAll()을 사용하면 다른 컬렉션의 요소를 이 컬렉션에 추가할 수 있습니다.boolean removeAll(Collection c);
boolean contains(Object o);
remove()는 삭제되도록 지정된 요소입니다. NaheaddAll( )이에 따라removeAll()은 세트 B의 모든 요소를 삭제하는 것입니다.
boolean containsAll(Collection c);
boolean contains(Object o);
boolean containsAll(Collection c);
boolean isEmpty();
int size();
Object[] toArray();
以上就是 Collection 中常用的 API 了。
在接口里都定义好了,子类不要也得要。
当然子类也会做一些自己的实现,这样就有了不同的数据结构。
那我们一个个来看。
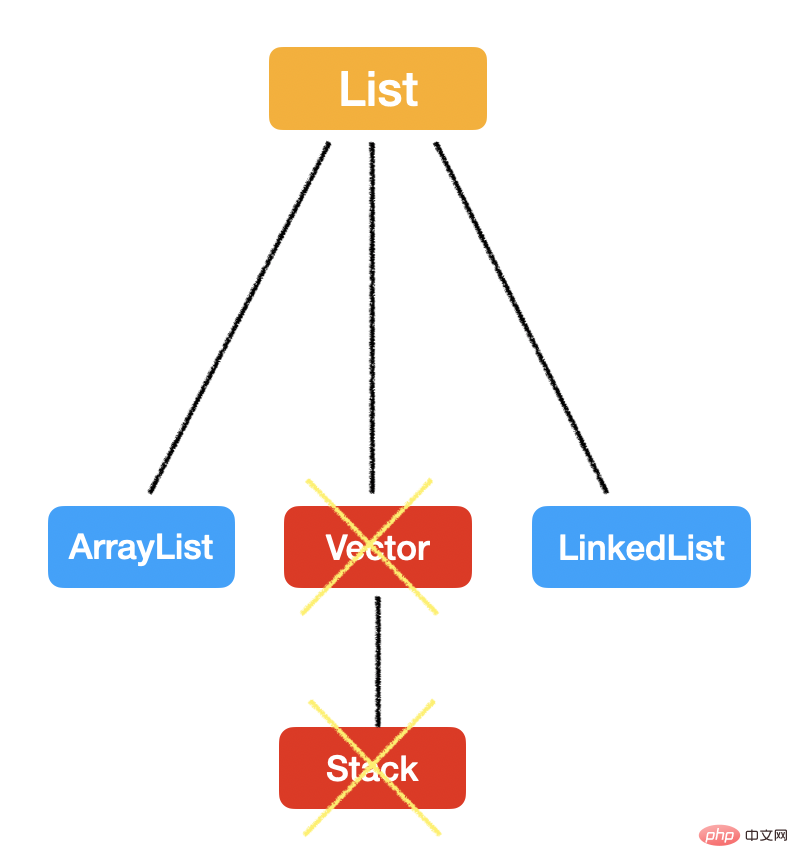
List 最大的特点就是:有序,可重复。
看官网说的:
An ordered collection (also known as a sequence).
Unlike sets, lists typically allow duplicate elements.
이번에는 Set의 특징에 대해서도 언급했습니다. 이는 List와 완전히 반대입니다.无序,不重复
먼저 데이터 구조가
필요한 기능을 완료할 수 있는지 여부를 고려하세요.완료할 수 있다면 두 번째로 어느 것이
더 효율적인지고려하세요.
| Function | Method | ArrayList | LinkedList |
|---|---|---|---|
| add | add(E e) | O(1) | O(1) |
| increase | add(int index, E e) | O(n) | O(n) |
| delete | remove(int index) | O(n) | O(n) |
| delete | remove( E e) | O(n) | O(n) |
| change | set(int index, E e) | O(1) | O(n) |
| check | get (int 인덱스) | O(1) | O(n) |
몇 가지 설명:
add(E e)는 꼬리에 요소를 추가합니다. ArrayList가 확장될 수 있지만 상각 시간 복잡도는 여전히 O(1)입니다.add(E e)是在尾巴上加元素,虽然 ArrayList 可能会有扩容的情况出现,但是均摊复杂度(amortized time complexity)还是 O(1) 的。
add(int index, E e)是在特定的位置上加元素,LinkedList 需要先找到这个位置,再加上这个元素,虽然单纯的「加」这个动作是 O(1) 的,但是要找到这个位置还是 O(n) 的。(这个有的人就认为是 O(1),和面试官解释清楚就行了,拒绝扛精。
remove(int index)是 remove 这个 index 上的元素,所以
remove(E e)
추가(int index, E e)는 특정 위치에 요소를 추가하는 것입니다. LinkedList는 이 위치를 먼저 찾은 다음 이 요소를 추가해야 합니다. 간단한 "추가" 작업은 O(1)이지만 찾아야 합니다. this 위치는 여전히 O(n)입니다. (어떤 사람들은 이것이 O(1)이라고 생각합니다. 면접관에게 명확하게 설명하고 비난을 거부하십시오.
remove(int index)는 이 인덱스에서 요소를 제거하는 것이므로
remove(E e)는 제거에 의해 표시되는 첫 번째 요소입니다. 그런 다음
:
“추가 및 삭제”는 어떻습니까?
이 요소를 찾는 시간을 고려하지 않는다면,
배열의 물리적 연속성으로 인해 요소를 추가하거나 삭제할 때 꼬리 부분에서는 괜찮지만 다른 곳에서는 후속 요소가 이동하게 되므로 효율성은 낮으며 연결된 목록은 다음 요소와의 연결을 쉽게 끊고 새 요소를 직접 삽입하거나 이전 요소를 제거할 수 있습니다.
하지만 사실 요소를 찾는 데에는 시간을 고려해야 합니다. . . 그리고 tail에서 동작하게 되면 데이터의 양이 많을수록 ArrayList가 더 빨라지게 됩니다.
그래서:
List에 대한 마지막 지식 포인트로 Vector에 대해 이야기해보겠습니다. 이것은 또한 모든 큰 사람들이 사용하는 연령 공개 게시물입니다.
그러면 Vector도 ArrayList와 마찬가지로 java.util.AbstractList
하지만...너무 많은 동기화를 추가하기 때문에 지금은 더 이상 사용되지 않습니다!
모든 이점에는 대가가 따릅니다. 효율성이 낮기 때문에 일부 시스템에서는 쉽게 병목 현상이 발생할 수 있습니다. 따라서 이제 더 이상 데이터 구조 수준에서 동기화를 추가하지 않고 이 작업을 프로그램 회원에게 전달합니다. ==
일반적인 인터뷰 질문: Vector와 ArrayList의 차이점은 무엇입니까?
스택 오버플로에 대한 투표율이 높은 답변을 살펴보겠습니다.

첫 번째는 방금 언급한 스레드 안전 문제입니다.
두 번째는 확장할 때 확장할 정도의 차이입니다.
이에 대한 소스 코드를 살펴봐야 합니다.
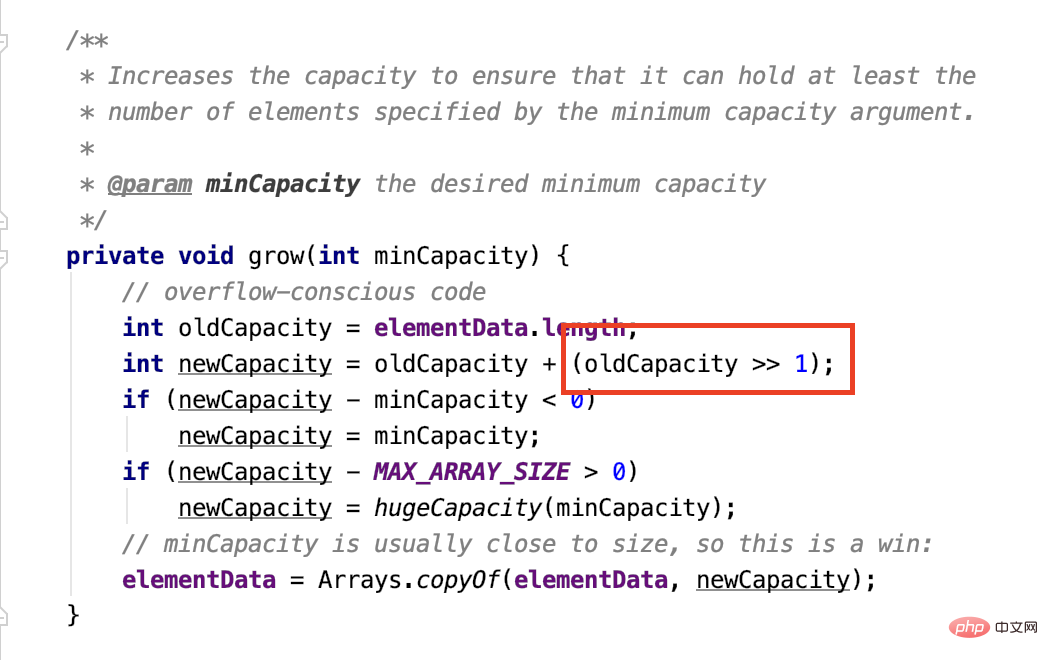
이것은 ArrayList의 확장 구현입니다. 이산술 오른쪽 이동작업은 이 숫자의 이진수를 1비트 오른쪽으로 이동하는 것입니다. 가장 왼쪽의보완 부호 비트이지만 용량에 음수가 없으므로 여전히 0을 추가합니다.
한 위치를 오른쪽으로 이동하면 2로 나누는 효과가 있으므로 정의된 새 용량은1.5입니다. 원래 용량의 2배입니다.
Vector를 다시 살펴보겠습니다.

보통 용량 증가는 우리가 정의하지 않기 때문에 기본적으로두 번 확장됩니다.
이 두 가지 사항에 답하시면 분명 괜찮을 겁니다.
Queue는 한쪽 끝에서 들어가고 다른 쪽 끝에서 나오는 반면 Deque는 양쪽 끝에서 들어오고 나갈 수 있는 선형 데이터 구조입니다.
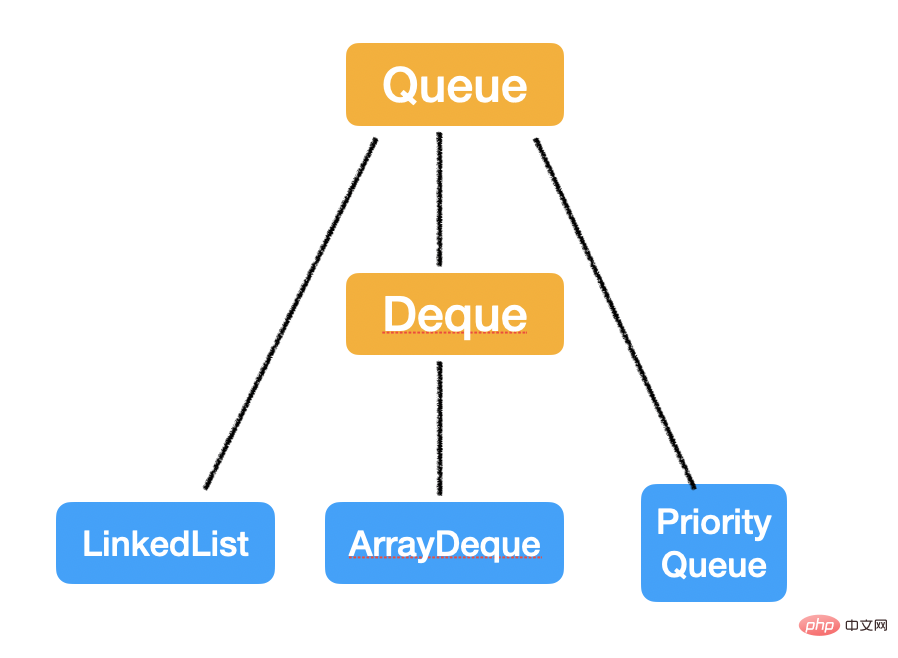
Java의 Queue 인터페이스는 약간 혼란스럽습니다. 일반적으로 대기열의 의미는선입선출(FIFO)입니다.
하지만 여기서 예외가 있는데, 힙이라고도 불리는 PriorityQueue는 진입 시간 순서대로 나오지 않고 지정된 우선 순위에 따라 나가며 연산이 O(1)이 아니라는 계산입니다. 시간복잡도는 조금 복잡하므로 나중에 별도의 글에서 다루겠습니다.
큐 메소드공식 웹사이트[1]를 요약했습니다. 두 가지 API 세트가 있으며 기본 기능은 동일하지만:
| Function | 예외 발생 | 반환 값 |
|---|---|---|
| Add | add(e) | offer(e) |
| 삭제 | 제거() | 설문조사() |
| Look | element() | peek() |
왜 예외가 발생하나요?
어떻게 add(e)가 예외를 발생시킵니까?
일부 대기열에는BlockingQueue와 같은 용량 제한이 있습니다. 최대 용량에 도달하여 확장되지 않으면 예외가 발생하지만 Offer(e)인 경우 false를 반환합니다.
그래서 어떻게 선택하나요? :
우선 사용하려면동일한 API 세트를 사용하고, 앞면과 뒷면을 통일해야 합니다.
둘째, 필요에 따라. 예외를 발생시키기 위해 필요한 경우에는 예외를 발생시키는 것을 사용하지만, 알고리즘 문제를 풀 때는 기본적으로 사용되지 않으므로 특별한 값을 반환하는 것을 선택하세요.
Deque는 양쪽 끝에서 들어오고 나갈 수 있습니다. 당연히 첫 번째 쪽 작업과 마지막 쪽 작업이 있고, 각 끝 부분에 한 그룹이 있습니다. 예외 및 다른 그룹 특수 값 반환:
| 함수 | 예외 발생 | 반환 값 |
|---|---|---|
| add | addFirst(e)/ addLast(e) | offerFirst(e)/ OfferLast(e) |
| Delete | removeFirst()/ RemoveLast() | pollFirst()/ pollLast() |
| Look | getFirst()/ getLast() | peekFirst()/ peekLast() |
사용시에도 동일하게 적용됩니다.
이러한 Queue 및 Deque API의 시간 복잡도는 O(1)입니다. 정확히 말하면 상각 시간 복잡도입니다.
세 가지 구현 클래스가 있습니다:

그래서,
하나씩 살펴보겠습니다.
공통 큐를 구현할 때LinkedList 또는 ArrayDeque 중에서 선택하는 방법은 무엇입니까?
StackOverflow[2]에서 투표율이 높은 답변을 살펴보겠습니다.

요약하면 효율성이 높기 때문에 ArrayDeque를 사용하는 것이 좋지만 LinkedList에는 다른 추가 오버헤드가 있습니다. (간접비).
ArrayDeque와 LinkedList의 차이점은 무엇인가요?

지금도 같은 질문이 있지만 이것이 내 생각에 가장 좋은 요약입니다.
따라서 null 값을 저장할 필요가 없다면 ArrayDeque를 선택하세요!
그럼 선배 면접관이 물어보면 어떤 상황에서 LinkedList를 사용해야 할까요?
为了版本兼容的问题,实际工作中我们不得不做一些妥协。。
那最后一个问题,就是关于 Stack 了。
Stack 在语义上是后进先出(LIFO)的线性数据结构。
有很多高频面试题都是要用到栈的,比如接水问题,虽然最优解是用双指针,但是用栈是最直观的解法也是需要了解的,之后有机会再专门写吧。
那在 Java 中是怎么实现栈的呢?
虽然 Java 中有 Stack 这个类,但是呢,官方文档都说不让用了!

原因也很简单,因为 Vector 已经过被弃用了,而 Stack 是继承 Vector 的。
那么想实现 Stack 的语义,就用 ArrayDeque 吧:
Dequestack = new ArrayDeque<>();
最后一个 Set,刚才已经说过了 Set 的特定是无序,不重复的。
就和数学里学的「集合」的概念一致。
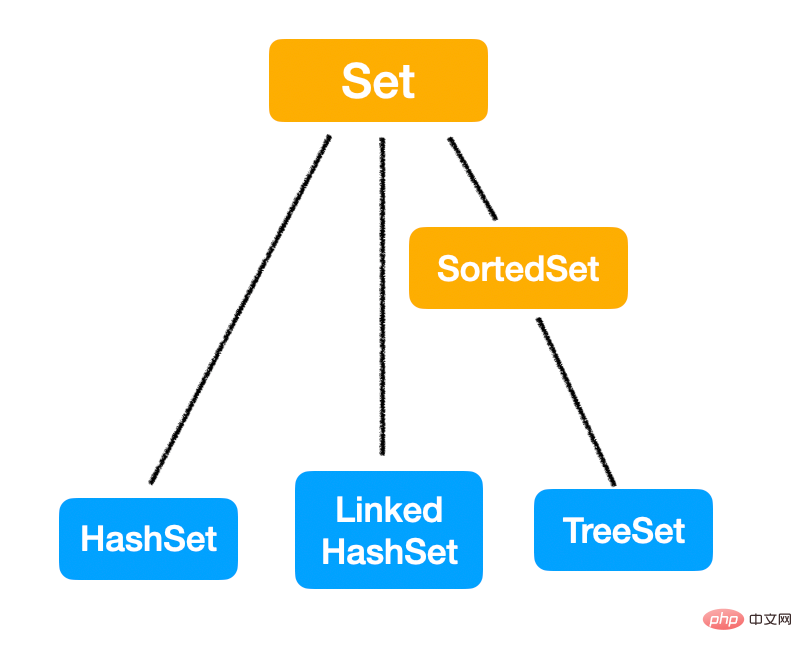
Set 的常用实现类有三个:
HashSet: 采用 Hashmap 的 key 来储存元素,主要特点是无序的,基本操作都是 O(1) 的时间复杂度,很快。
LinkedHashSet: 这个是一个 HashSet + LinkedList 的结构,特点就是既拥有了 O(1) 的时间复杂度,又能够保留插入的顺序。
TreeSet: 采用红黑树结构,特点是可以有序,可以用自然排序或者自定义比较器来排序;缺点就是查询速度没有 HashSet 快。
那每个 Set 的底层实现其实就是对应的 Map:
값은 지도의 키에 배치되고 PRESENT는 자리 표시자와 동일한 정적 객체이며 각 키는 이 객체를 가리킵니다.
특정구현 원칙,추가, 삭제, 수정, 확인4가지 작업과해시 충돌,hashCode()/equals()및 기타 문제는 모두 HashMap 기사에서 논의되었습니다. , 여기서 자세한 내용은 다루지 않겠습니다. 아직 읽지 않은 친구들은 공식 계정 백그라운드에서 "HashMap"에 답글을 달면 기사를 얻을 수 있습니다~
처음의 사진으로 돌아가세요. 좀 이해가 되시나요?
PriorityQueue와 같은 각 데이터 구조에는 실제로 많은 내용이 있습니다. 이 사람에 대해 이야기하는 데 시간이 오래 걸리기 때문에 이 기사에서는 자세히 설명하지 않습니다. .
글이 좋다고 생각하시면 글 끝의 좋아요가 또 돌아오네요"좋아요"와 "읽기"를 꼭 눌러주세요~
마지막으로 많은 독자님들께서 소통에 관해 질문을 많이 주셨는데요~ 그룹, 생각해보니 시차도 있고 관리도 힘들어서 아직 안 해본 것 같아요.
하지만 이제 저와 함께 관리해 줄 전문 관리자를 구하게 되어서 "치자매의 비밀 기지"를 준비 중이고, 국내외 유명 인사들을 초대해 여러분께 색다른 시각을 선사해 드릴 예정입니다.
1단계 교류회는 7월 중순~초에 오픈할 예정이니 그때 친구들에게 초대장을 보내드릴 예정이니 기대해주세요!
위 내용은 Java 컬렉션 프레임워크에 대한 이 기사를 읽는 것으로 충분합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!
































![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



