
해싱 방법의 주요 아이디어는 노드의 키 코드 값을 기반으로 저장 주소를 결정하는 것입니다. 특정 함수 관계 h(K )(해시 함수라고 함)를 사용하여 해당 함수 값을 계산하고 이 값을 노드의 저장 주소로 해석하고 이 저장 장치에 노드를 저장합니다. 검색할 때에도 동일한 방법으로 주소를 계산한 후 해당 유닛으로 이동하여 원하는 노드를 가져옵니다. 해싱을 통해 노드를 빠르게 검색할 수 있습니다. 해시("해시"라고도 함)는 중요한 저장 방법이자 일반적인 검색 방법입니다.
해시 저장 방식에 따라 구성된 저장 구조를 해시 테이블이라고 합니다. 해시 테이블의 위치를 슬롯이라고 합니다. 해싱 기술의 핵심은 해시 함수입니다. 주어진 동적 조회 테이블 DL에 대해 "이상적인" 해시 함수 h와 해당 해시 테이블 HT가 선택되면 DL의 각 데이터 요소 X에 대해 선택됩니다. 함수 값 h(X.key)는 해시 테이블 HT에서 X의 저장 위치입니다. 데이터 요소 X는 삽입(또는 테이블 생성) 시 이 위치에 배치되고, X를 검색할 때도 이 위치에서 검색됩니다. 해시 함수에 의해 결정된 저장 위치를 해시 주소라고 합니다. 따라서 해싱의 핵심은 해시 함수가 키 코드 값(X.key)과 해시 주소 h(X.key) 간의 대응 관계를 결정하는 것입니다. 이 관계를 통해 조직적인 저장 및 검색이 실현됩니다.
일반적으로 해시 테이블의 저장 공간은 1차원 배열 HT[M]이며, 해시 주소는 배열의 첨자입니다. 해싱 방법을 설계하는 목적은 키 값 K에 대해 특정 해시 함수 h, 0
다음 논의에서는 값이 정수인 키 코드를 다룬다고 가정합니다. 그렇지 않으면 키 코드와 양의 정수 사이에 항상 일대일 대응이 가능합니다. 키 검색을 해당 양의 정수 검색으로 동시에 변환하려면 해시 함수의 값이 0과 M-1 사이에 있다고 가정합니다. 해시 함수를 선택하는 원칙은 다음과 같습니다. 작업은 가능한 한 간단합니다. 함수의 값 범위는 해시 테이블의 범위 내에 있어야 합니다. 즉, 노드를 최대한 균등하게 분산해야 합니다. 키에는 서로 다른 해시 함수 값이 있습니다. 키 길이, 해시 테이블 크기, 키 분포, 레코드 검색 빈도 등 다양한 요소를 고려해야 합니다. 아래에서는 일반적으로 사용되는 몇 가지 해시 함수를 소개합니다.
이름에서 알 수 있듯이 나머지 방법은 키 코드 x를 M(종종 해시 테이블의 길이를 취함)으로 나누고 나머지를 해시 주소로 사용하는 것입니다. 나머지 방법은 거의 가장 간단한 해싱 방법이며 해시 함수는 h(x) = x mod M입니다.
이 방법을 사용하는 경우 먼저 키 코드에 상수 A(0< A < 1)를 곱한 후 제품의 소수 부분을 추출합니다. 그런 다음 이 값에 정수 n을 곱하고 그 결과를 반올림하여 해시 주소로 사용합니다. 해시 함수는 다음과 같습니다. hash (key) = _LOW(n × (A × key % 1)). 그 중 "A × 키 % 1"은 A × 키의 소수 부분을 취한다는 의미입니다. 즉, A × 키 % 1 = A × 키 - _LOW(A × 키), _LOW(X)는 정수 부분을 취한다는 의미입니다. of X
정수 나누기는 일반적으로 곱셈보다 느리게 실행되므로 의식적으로 나머지 연산의 사용을 피하면 해시 알고리즘의 실행 시간이 향상될 수 있습니다. square-middle 방법의 구체적인 구현은 먼저 키 코드의 제곱 값을 찾아 유사한 숫자 간의 차이를 확장한 다음 테이블 길이에 따라 중간 숫자(종종 이진 비트)를 해시 함수로 취하는 것입니다. 값. 제품의 중간 숫자는 승수의 각 숫자와 관련되어 있으므로 결과 해시 주소가 더 균일합니다.
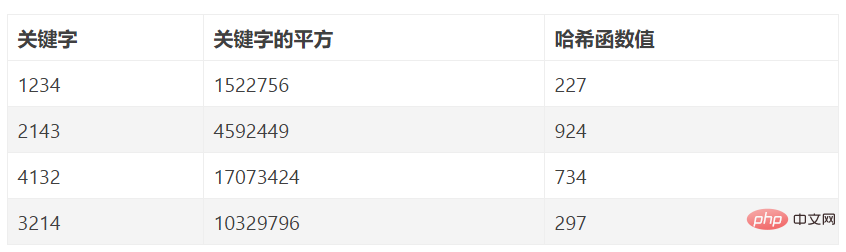
키워드 집합의 각 키워드는 s자리(u1, u2, …, us)로 구성되어 있다고 가정하고, 전체 키워드 집합을 분석하고, 균등하게 분포된 여러 개를 추출합니다. 비트 또는 그 조합을 주소로 사용합니다. 디지털 분석 방법은 데이터 요소 키워드 중 상대적으로 균일한 값을 갖는 일부 디지털 비트를 해시 주소로 취하는 방법이다. 즉, 키워드의 자릿수가 많은 경우 키워드의 비트를 분석하여 불균등하게 분포된 비트를 해시 값으로 버릴 수 있습니다. 키워드 값을 모두 알고 있는 경우에만 적합합니다. 분포를 분석하면 키워드 값 범위가 더 작은 키워드 값 범위로 변환됩니다.
예: 데이터 요소 수 n=80, 해시 길이 m=100으로 해시 테이블을 구성합니다. 일반성을 잃지 않고 여기서는 분석을 위해 8개의 키워드만 제공합니다. 8개의 키워드는 다음과 같습니다. 1394220
위 8개 키워드를 분석한 결과, 키워드의 왼쪽부터 1, 2, 3, 6번째 숫자의 값이 상대적으로 밀집되어 있어 나머지 4, 5번째, 7번째, 8비트 값은 상대적으로 짝수이고, 그 중 2개를 해시 주소로 선택할 수 있다. 마지막 두 자리가 해시 주소로 선택되었다고 가정하면 이 8개 키워드의 해시 주소는 2, 75, 28, 34, 15, 38, 62, 20입니다.
이 방법은 다음과 같은 경우에 적합합니다. 모든 키워드의 각 숫자에서 다양한 숫자의 발생 빈도를 미리 예측할 수 있습니다.
5. 베이스 변환 방법
6. 접는 방법
이동 중첩: 나누어진 부분의 낮은 비트를 정렬하고 추가합니다.
위 내용은 매일 사용하세요! HASH가 무엇인지 아시나요?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



