

대형모델 시대, 가장 중요한 것은 무엇일까요?
르쿤이 한 번 내놓은 대답은 오픈 소스입니다.
Meta의 LLaMA 코드가 GitHub에서 유출되었을 때 전 세계 개발자들이 최초의 GPT 수준 LLM에 액세스할 수 있게 되었습니다.
다음으로 다양한 LLM이 AI 모델의 오픈 소스에 다양한 각도를 제시합니다.
LLaMA는 스탠포드의 Alpac 및 Vicuna와 같은 모델을 위한 길을 닦고 무대를 마련하여 이들을 오픈 소스의 리더로 만들었습니다.
이 순간, 팔콘 "팔콘"이 다시 포위 공격에서 벗어났습니다.
"Falcon"은 아랍에미리트 아부다비에 있는 TII(Technology Innovation Institute)에서 개발한 제품으로, 성능 면에서는 LLaMA보다 Falcon이 더 뛰어납니다.
현재 "Falcon"에는 1B, 7B, 40B의 세 가지 버전이 있습니다.
TII는 Falcon이 현재까지 가장 강력한 오픈 소스 언어 모델이라고 말했습니다. 가장 큰 버전인 Falcon 40B에는 400억 개의 매개변수가 있는데, 이는 650억 개의 매개변수가 있는 LLaMA보다 여전히 규모가 약간 작습니다.
규모는 작지만 성능은 높습니다.
ATRC(첨단 기술 연구 위원회) 사무총장인 Faisal Al Bannai는 “Falcon”의 출시가 LLM의 인수 방식을 깨고 연구원과 기업가가 가장 혁신적인 사용 사례를 제안할 수 있게 해줄 것이라고 믿습니다.
FalconLM의 두 가지 버전인 Falcon 40B Instruct와 Falcon 40B는 Hugging Face OpenLLM 순위에서 상위 2위에 올랐으며 Meta의 LLaMA는 3위를 차지했습니다.
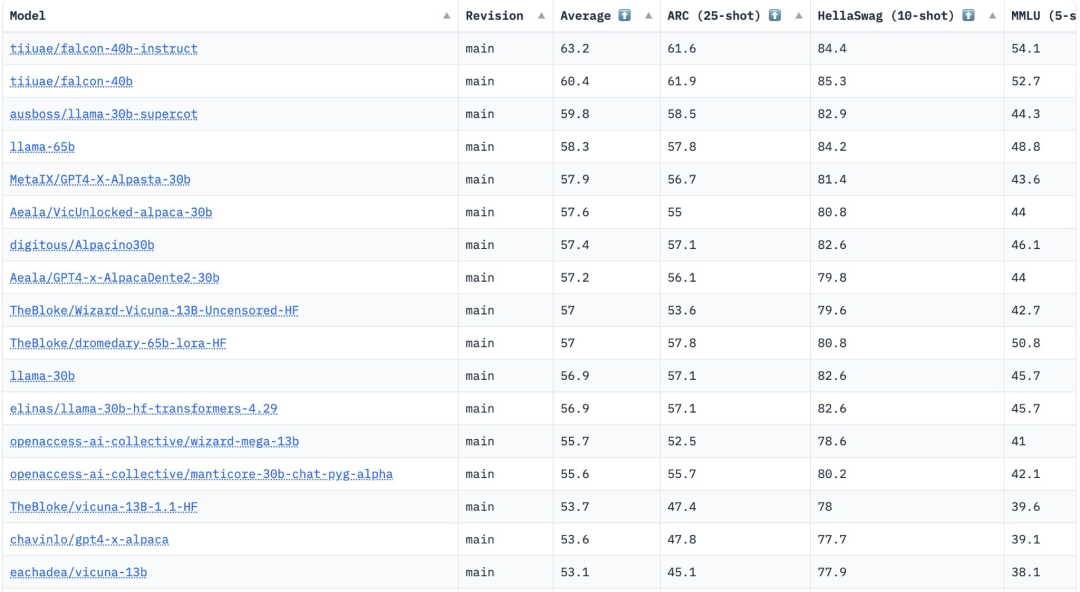
Hugging Face는 AI2 Reasoning Challenge, HellaSwag, MMLU 및 TruthfulQA 등 매니폴드 비교를 위한 4가지 현재 벤치마크를 통해 이러한 모델을 평가한다는 점을 언급할 가치가 있습니다.
"Falcon" 논문은 아직 공개되지 않았지만 Falcon 40B는 신중하게 선별된 1조 개의 토큰 네트워크 데이터 세트에 대해 광범위하게 교육을 받았습니다.
연구원들은 “Falcon”이 훈련 과정에서 대규모 데이터에 대해 높은 성능을 달성하는 것의 중요성을 매우 중요하게 여긴다고 밝혔습니다.
우리 모두 알고 있는 것은 LLM이 훈련 데이터의 품질에 매우 민감하다는 것입니다. 이것이 바로 연구자들이 수만 개의 CPU 코어에서 효율적인 처리를 수행할 수 있는 데이터 파이프라인을 구축하는 데 많은 노력을 기울이는 이유입니다.
필터링 및 중복 제거를 기반으로 인터넷에서 고품질 콘텐츠를 추출하는 것이 목적입니다.
현재 TII는 세심하게 필터링되고 중복이 제거된 데이터 세트인 세련된 네트워크 데이터 세트를 출시했습니다. 연습을 통해 그것이 매우 효과적이라는 것이 입증되었습니다.
이 데이터 세트만 사용하여 학습된 모델은 다른 LLM과 동등하거나 성능 면에서 이를 능가할 수도 있습니다. 이는 "Falcon"의 뛰어난 품질과 영향력을 입증합니다.

또한 Falcon 모델에는 다국어 기능도 있습니다.
영어, 독일어, 스페인어, 프랑스어를 이해하며 네덜란드어, 이탈리아어, 루마니아어, 포르투갈어, 체코어, 폴란드어, 스웨덴어와 같은 일부 소규모 유럽 언어도 많이 알고 있습니다.
Falcon 40B는 H2O.ai 모델 출시 이후 두 번째 진정한 오픈 소스 모델이기도 합니다. 하지만 H2O.ai는 이 순위에서 다른 모델과 벤치마킹된 적이 없기 때문에 이 두 모델은 아직 링에 진입하지 못했습니다.
LLaMA를 되돌아보면 해당 코드는 GitHub에서 사용할 수 있지만 가중치는 오픈 소스였던 적이 없습니다.
즉, 이 모델의 상업적 이용이 다소 제한된다는 의미입니다.
또한 LLaMA의 모든 버전은 원본 LLaMA 라이센스를 사용하므로 LLaMA는 소규모 상업용 응용 프로그램에 적합하지 않습니다.
이때 또 'Falcon'이 1위로 나옵니다.
Falcon은 현재 무료로 상업적으로 사용할 수 있는 유일한 오픈 소스 모델입니다.
초창기 TII에서는 Falcon을 상업적 목적으로 사용하고 귀속 소득이 100만 달러 이상인 경우 10%의 "사용세"가 부과되도록 요구했습니다.
그러나 부유한 중동의 재벌들이 이러한 제한을 해제하는 데는 오랜 시간이 걸리지 않았습니다.
적어도 현재로서는 Falcon의 모든 상업적 사용과 미세 조정이 무료입니다.
부자들은 당분간 이 모델로 돈을 벌 필요가 없다고 하더군요.
또한 TII는 전 세계에서 상용화 계획을 모집하고 있습니다.
잠재적인 과학 연구 및 상용화 솔루션을 위해 더 많은 "컴퓨팅 능력 교육 지원"을 제공하거나 추가 상용화 기회를 제공할 것입니다.

프로젝트 제출 이메일: Submissions.falconllm@tii.ae
즉, 프로젝트가 좋으면 모델을 무료로 사용할 수 있다는 뜻입니다! 컴퓨팅 파워는 충분합니다! 돈이 충분하지 않은 경우에도 저희가 모아드릴 수 있습니다!
스타트업에게 이것은 단순히 중동 재벌의 "AI 대형 모델 창업을 위한 원스톱 솔루션"입니다.
개발팀에 따르면 FalconLM의 경쟁 우위의 중요한 측면은 훈련 데이터의 선택입니다.
연구팀은 공개 크롤링된 데이터 세트에서 고품질 데이터를 추출하고 중복 데이터를 제거하는 프로세스를 개발했습니다.
중복되고 중복된 콘텐츠를 철저히 정리한 후 5조 개의 토큰이 유지되었습니다. 이는 강력한 언어 모델을 훈련하기에 충분합니다.
40B Falcon LM은 훈련에 1조 개의 토큰을 사용하며, 모델 훈련 토큰의 7B 버전은 1.5조에 이릅니다.
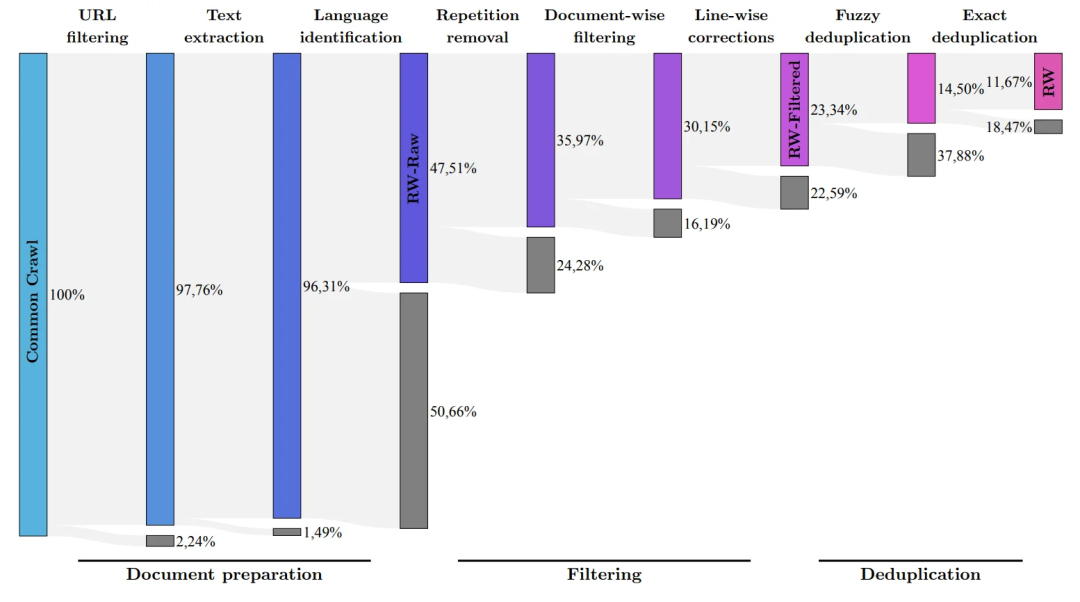
(연구 팀은 RefinedWeb 데이터 세트를 사용하여 Common Crawl에서 최고 품질의 원시 데이터만 필터링하는 것을 목표로 함)
TII 말함, GPT-3과 비교 Falcon, Falcon은 훈련 컴퓨팅 예산의 75%만 사용하면서 상당한 성능 향상을 달성했습니다.
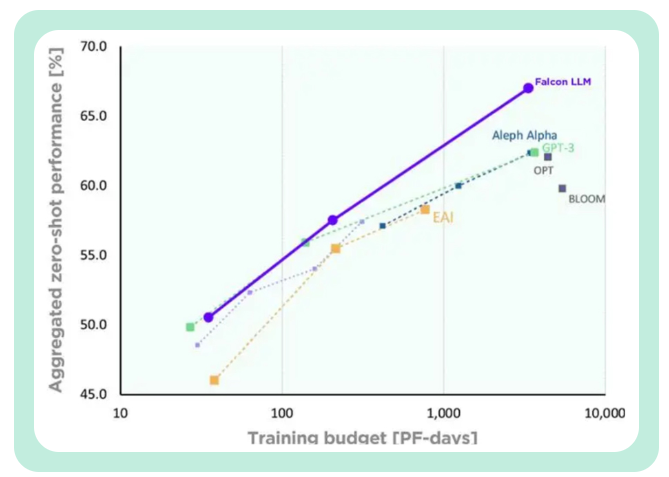
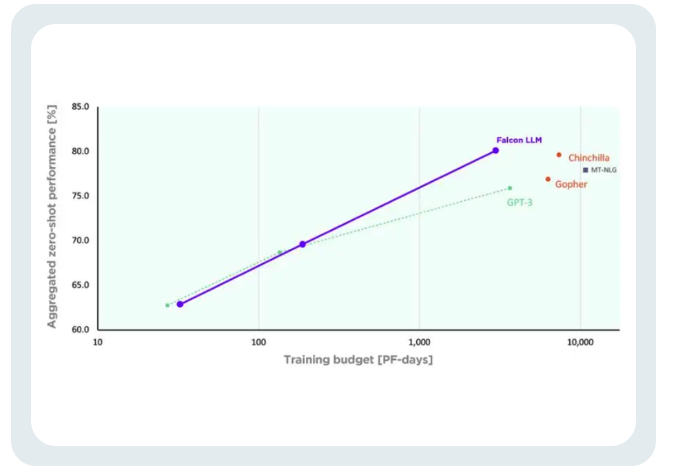
추론 중에 계산 시간의 20%만 필요합니다.
팔콘의 훈련 비용은 친칠라의 40%, PaLM-62B의 80%에 불과합니다.
컴퓨팅 리소스의 효율적인 활용을 성공적으로 달성했습니다.
위 내용은 LLaMA를 분쇄한 'Falcon'은 완전한 오픈 소스입니다! 400억 개의 매개변수, 수조 개의 토큰 훈련, Hugging Face 지배의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



